Bedrock+サーバレスでSlackボットを作成してみた
Amazon Bedrock Advent Calendar 2023の21日目の記事です。
概要
今回は、Amazon Bedrockとサーバレス構成で、Slackボットを作成しました。以下のような構成です。
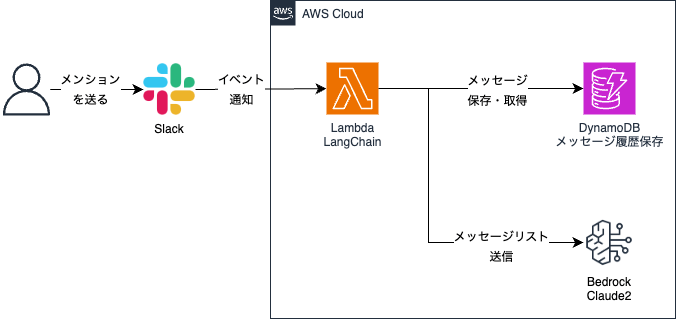
技術的な要素は以下のとおりです。
- Amazon Bedrock: Claude2を使用します
- Lambda: Slackからのリクエストを受け取り、LangChainを使用したアプリを実行するために使用します
- DynamoDB: 会話履歴を保存するために使用します
- Serverless Framework: LambdaやDynamoDBのデプロイをするために使用します
実装については「ChatGPT/LangChainによるチャットシステム構築[実践]入門」の第7章を大いに参考にしています。とても勉強になるので、おすすめです。
今回のソースコードは、以下のリポジトリにあります。
Macでデプロイをすると、うまく動作しないことを確認しています。Cloud9などでデプロイすることをおすすめします。
LangChainとは
LangChainは、大規模言語モデル(LLMs)を使用してアプリケーションを作成するためのフレームワークです。このフレームワークは、言語モデル統合のために設計されており、文書分析、要約、チャットボット、コード分析などのユースケースをカバーしています。
今回は、Slackチャットボットを作成するために使用しています。具体的には、以下のような処理を実装するために使用しています。
- BedrockにホスティングされているClaude2にアクセス
- DynamoDBにメッセージ履歴を保存・取得
- ストリーミングメッセージ処理
LangChainを使用したSlackチャットボットの実装
LangChainを使用して、以下のような実装を行います。
DynamoDBを使用したメッセージ履歴の管理
# DynamoDB - メッセージ履歴
history = DynamoDBChatMessageHistory(
table_name=os.environ["DYNAMO_TABLE"],
session_id=id_ts
)
このコードは、環境変数からDynamoDBのテーブル名を取得し、指定されたセッションIDでチャットメッセージの履歴を管理します。これにより、Slackスレッド内の会話の流れを追跡し、ユーザーの過去のメッセージに基づいて応答を調整することが可能になります。
Bedrock上のClaude2モデルの設定
# Bedrockの設定(Claude2を使用する)
llm = BedrockChat(
model_id="anthropic.claude-v2",
streaming=True,
callbacks=[callback],
region_name="us-east-1",
model_kwargs={
"max_tokens_to_sample": 4000
}
)
ここでは、Bedrock上のClaude2モデルにアクセスするための設定を行います。ストリーミング処理の有無、リージョン名、モデルの追加引数などを指定して、AIモデルの応答品質とカスタマイズを実現します。
AIメッセージの処理とDynamoDBへの保存
# Claude2にメッセージリストを渡す
ai_message = llm(messages)
# Claude2のメッセージを保存
history.add_message(ai_message)
ユーザーからのメッセージリストをClaude2モデルに渡し、生成されたAIの応答を取得します。その後、この応答をDynamoDBに保存して、会話の文脈を維持します。
Slack関連の実装
Slackから受け取ったメッセージを扱うためのライブラリが用意されています。これを利用し、Slack関連の実装を行います。
Slack Appインスタンスの生成
# Slack Appインスタンスを生成
app = App(
signing_secret=os.environ["SLACK_SIGNING_SECRET"],
token=os.environ.get("SLACK_BOT_TOKEN"),
process_before_response=True
)
このコードは、Slack Appインスタンスを生成します。環境変数からSlackの署名秘密鍵とぼっとトークンを取得し、Slackからのリクエストを処理するための基礎を設定します。 process_before_response=True は、レスポンスを送信する前にリクエストを処理するための設定です。
イベントハンドラの設定
def just_ack(ack):
ack()
app.event("app_mention")(ack=just_ack, lazy=[handle_mention])
ここでは、Slack Appインスタンスにイベントハンドラを設定しています。アプリがメンションされたとき( app_mention イベント)に、 just_ack 関数を呼び出してリクエストを確認します。 lazyパラメータを使用して、実際のイベント処理を後で行う ( handle_mention )ことを指定します。
重複処理の防止
# リトライ時は重複処理しないようにする
if "x-slack-retry-num" in header:
logging.info("SKIP > x-slack-retry-num: %s", header["x-slack-retry-num"])
return 200
slack_handler = SlackRequestHandler(app=app)
return slack_handler.handle(event, context)
このセクションでは、リトライ時の重複処理を回避するためのロジックが実装されています。リクエストヘッダーに x-slack-retry-num が含まれている場合、そのリクエストはスキップされ、処理が中断されます。これにより、同じイベントに対する重複した処理を防ぎます。
最後に、 SlackRequestHandler を用いてSlackからのリクエストを適切に処理し、応答を返します。これらの実装により、Slackチャットボットは効率的にSlackイベントを処理し、ユーザーのメンションに対応することが可能になります。
Slackアプリの設定
SlackのメンションイベントをLambdaで受け取るためには、Slack側で設定が必要となります。
以下のページにアクセスし、アプリを作成します。
アプリの設定は、「マニフェストから作成する」を選択し、以下の内容を貼り付けます。

{
"display_information": {
"name": "assistant_bot",
"description": "assistant_bot",
"background_color": "#3b9c3b"
},
"features": {
"bot_user": {
"display_name": "assistant_bot",
"always_online": true
}
},
"oauth_config": {
"scopes": {
"user": [
"chat:write"
],
"bot": [
"chat:write",
"app_mentions:read"
]
}
},
"settings": {
"event_subscriptions": {
"request_url": "https://xxxxxxxxx.lambda-url.ap-northeast-1.on.aws/",
"bot_events": [
"app_mention"
]
},
"org_deploy_enabled": false,
"socket_mode_enabled": false,
"token_rotation_enabled": false
}
}
作成したアプリは、ワークスペースにインストールします。
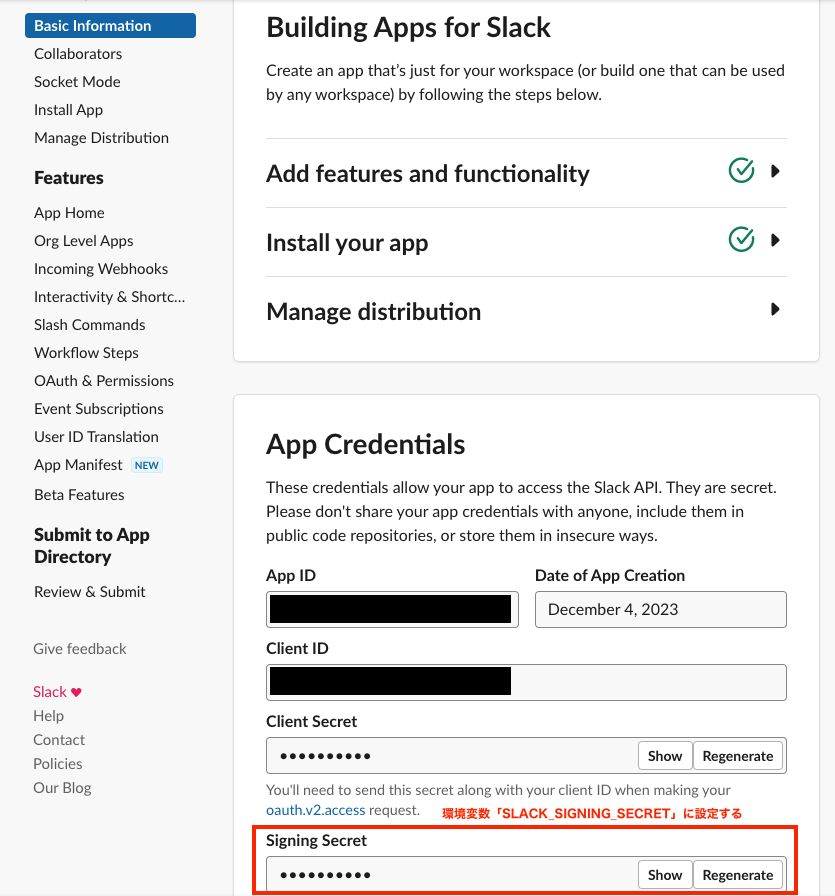
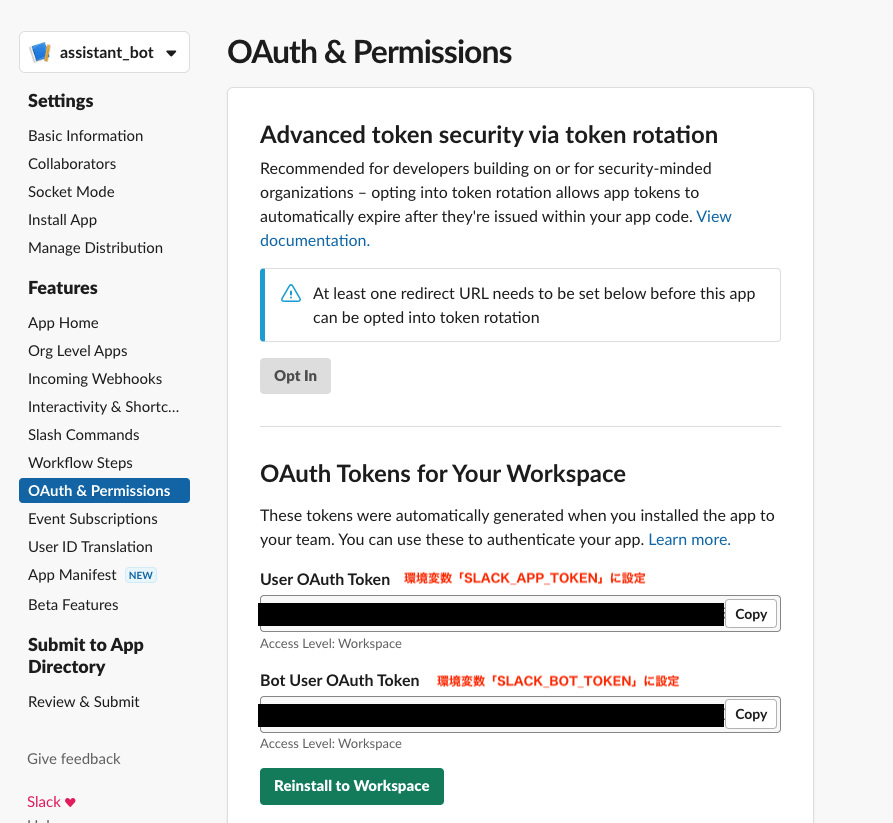
アプリをインストールすると、必要なトークンがすべて表示されるようになるので、確認して .env ファイルに環境変数として記述していきます。
SLACK_SIGNING_SECRET=
SLACK_BOT_TOKEN=
SLACK_APP_TOKEN=
DYNAMO_TABLE=ChatHistory
Serverless Frameworkの設定とデプロイ
Serverless Frameworkを使用して、AWSにコードをデプロイするプロセスは次のようになります。
DynamoDBテーブルの設定
resources:
Resources:
ChatHistory:
Type: AWS::DynamoDB::Table
Properties:
TableName: ChatHistory
AttributeDefinitions:
- AttributeName: SessionId
AttributeType: S
KeySchema:
- AttributeName: SessionId
KeyType: HASH
BillingMode: PAY_PER_REQUEST
このYAML設定は、DynamoDBに ChatHistory という名前のテーブルを作成します。このテーブルは SessionId をキーとして使用し、料金はリクエストごとに発生します (PAY_PER_REQUEST)。これは、チャットボットのセッション情報を効率的に保存するための設定です。
Serverless Frameworkのプラグインのインストールとデプロイ
$ serverless plugin install -n serverless-dotenv-plugin
$ serverless plugin install -n serverless-python-requirements
$ serverless deploy
ここでは、まず serverless-dotenv-plugin と serverless-python-requirements プラグインをインストールします。これらのプラグインは環境変数の管理とPythonの依存関係の処理を助けます。その後、 serverless deploy コマンドで、AWSにアプリケーションをデプロイします。
このプロセスにより、SlackチャットボットのバックエンドがAWSに設定され、動作する状態になります。
Slackアプリのエンドポイント検証
Slackアプリのエンドポイントを検証するには、AWS Lambdaで提供されたURLをSlackアプリのイベントサブスクリプション設定の「Request URL」フィールドに入力します。

AWS Lambdaコンソールにアクセスし、APIエンドポイントのURLをコピーします。

Slackアプリの設定ページに移動し、「Event Subscriptions」をサイドバーから選択し、「Enable Events」を「On」に切り替えます。コピーしたLambda関数のURLを「Request URL」フィールドに貼り付けます。
Slackは自動的にそのURLにチャレンジリクエストを送り、所有権とSlackイベントに対する応答能力を検証します。
URLが正常に検証されると、Slackアプリの設定画面で「Request URL」フィールドの隣に緑色の「Verified」インジケータが表示されます。これにより、SlackアプリがSlackからのイベントを受け取り、AWS Lambda関数を使用して処理するよう正しく設定されていることが確認できます。
動作確認
Slackボットの動作確認をします。
アプリをSlackチャンネルに追加

Slackのチャットボックスに /addapp コマンドを入力します。
アプリの名前(ここでは assistant_bot )を検索し、追加します。これで、チャンネルにボットが追加されました。
メンションを飛ばす

チャンネル内でボット (assistant_bot)にメンションを送り、ボットが応答することを確認します。応答が返ってきたら、無事に実装できていることが検証できます。
おわりに
この記事では、LangChainを用いてSlackチャットボットを開発する方法について説明しました。AWS Lambda、DynamoDB、BedrockとClaude2を組み合わせたサーバレスアーキテクチャを基に、効率的なチャットシステムを実装するプロセスを解説しました。Serverless Frameworkを使用してAWSへのデプロイを行い、Slackでのエンドポイント検証を通じてアプリケーションの設定を完了しました。最後に、実際のSlackチャンネルにボットを追加し、メンションに対する応答を通じて機能を確認しました。この記事が、Slackボット開発の基礎を理解し、実際に適用する際の参考になれば幸いです。
Discussion