Polars Expression Plugins
概要
Polars に最近追加された機能である Expression Plugins についてお話しできればと思います.
まとめ
「Polars に標準でない機能を追加したい、速度を爆速にしたい、Rust で開発したい。」Expression Plugins ならできます。
Expression とは
Expression とは何なのでしょう。公式の docs をみると以下のように書いてあります。
Polars expressions are a mapping from a series to a series (or mathematically Fn(Series) -> Series).
どうやら、Series から Series への mapping のようです。抽象的なので、具体例をみると、
- taking a sample of rows from a column
- multiplying values in a column
- taking the mean of a group in a group_by operation
- calculating the size of groups in a group_by operation
column から数行取り出したり、column の値に何かをかけたり変換したり、また group_by して平均を取ったり、などなど、どうやらデータに対する operation のことのようですね!
注意点としては、row 単位で 1 対 1 の mapping ではなく、mean なども含めた全般を指すようです。
Expression Plugins とは
Expression Plugins とは、2023/9 月ごろに追加されたもので、Expression を user が独自に定義し拡張できる機能です。ただ、Python 側で拡張するのでなく Rust で拡張します!
もちろん、Pandas のように、Python 側で apply や map_elements 関数を使って、user が独自の処理を実装することができるます。では、何が嬉しいのか?以下の3つです!
- Optimization
Polars の Runtime で直接動作させることができるので、最適化を行いやすいようです。例えば、Common subplan elimination (CSE)というある計算結果を cache し再利用するような最適化を最大限利用することができるようになります。
また、apply 関数などでは、データを polars から Python で扱えるように変換して処理が終わったら再度 polars で扱えるように再度変換する必要がありますが、Plugin では必要ありません。
- Parallelism
並列に動作させれます!それ Python でもできると思われるかもしれませんが、Python には GIL が存在し、thread 並列のつもりで書いたプログラムが並列に動作していないということは有名だと思います[2]。そのため、Rust で書くことで Python の GIL を回避しながら最大限並列の恩恵を受けることができます。
- Rust native performance
これはいうまでもなさそうですが、Rust で書くことで速度の恩恵を受けれます!
逆にデメリットはあるのでしょうか?自分が思うデメリットは以下です。
- Rust で書く必要があるので、そもそも Rust に入門する必要がある。
これを読んでるみなさんはきっと勉強熱心なので、Rust に入門済みの方も多いはずです。ただ、Rust を実際に使うところがなくてほぼ忘れかけてるなんてことないですか?使い所見つかりましたね! - 書き捨てるコードにはコストが大きい。
notebook でサッと書いて共有したいみたいな時は notebook 以外に Rust のコードがある repository も共有する必要があり面倒かもしれません。何度も使う + 処理速度が必要な場合に、Plugin にするくらいかくらいの気持ちでいいかもしれません。逆に、Polars で汎用的に使えるような library を作りたい人にはおすすめです。 - まだ Document や使用例が少ない。
これは仕方ないですが、公式の docs の他にも community で作成されている Plugin も多くはないですがいくつかありそれらが参考になります! - 他の DataFrame では使えない。
最近は DataFrame もたくさんあるので、共通の DataFrame API に沿って、Polars や Pandas などをまとめて対応しようとしている Library が多いですが、そのようなことはできません。
どんな場合におすすめ?
以上の点からおすすめできる局面は限られいるかもしれません。ですが、圧倒的な速さが必要な処理がある場合には非常に強い味方になりそうです。
使ってみよう
習うより慣れろ、です。早速使ってみましょう!
まだ Expression Plugins 自体新しく出たばかりなのですが、community でいくつか library があり今回は以下の 2 つ触ってみます!
polars-business
ちなみに、この作者である MarcoGorelli 氏は、Polars のコア開発メンバーの1人です。
この Plugin は 営業日を考慮した日付操作が可能になります。
まずは、polars と polars-business のインストール[3]から
pip install polars polars-business
簡単ですね! Plugin も python の package として配布できるので、このように簡単に install できます!
libary の import は既に終わっているとします。
from datetime import date
import polars as pl
import polars_business as plb
import jpholiday
では、次に、ユースケースを想定して使ってみます。
土日と(日本の)祝日を除いて 5 営業日先の日付を取得したい
df = pl.DataFrame(
{"date": [date(2023, 5, 2), date(2023, 9, 17), date(2024, 1, 4)]}
)
jp_holidays = [dt for (dt, _) in jpholiday.between(date(2023, 1, 1), date(2024, 4, 1))]
result = df.with_columns(
date_shifted=plb.col("date").bdt.offset_by(
'5bd',
weekend=('Sat', 'Sun'),
holidays=jp_holidays,
roll='backward',
)
)
print(result)
こちらを実行すると、
shape: (3, 2)
┌────────────┬──────────────┐
│ date ┆ date_shifted │
│ --- ┆ --- │
│ date ┆ date │
╞════════════╪══════════════╡
│ 2023-05-02 ┆ 2023-05-12 │
│ 2023-09-17 ┆ 2023-09-25 │
│ 2024-01-04 ┆ 2024-01-12 │
└────────────┴──────────────┘
です。日本の祝日も考慮されていることがわかります。
ちなみに、引数の一つである roll は基準となる日付(今回の場合だと date column)が営業日ではなかった場合にどうするかを指定できます。default は "raise" で営業日でなかった場合に例外が投げられます。今回の例だと 2023-09-17 が日曜日のため、roll を指定しないと落ちてしまうことに注意してください。
また、5bd とあまり見れない単位が用いられてますが、単に 5 b(usiness) d(ay) のことです。
polars_ds
こちらの Plugin はかなり色々な機能があるようです。ここでは3つほど取り上げてみます。
使い方の example はこちらにあります。
install は先ほどと同様。
pip install polars polars_ds
import は既に済んでいるものとします。
import polars_ds
import polars as pl
import numpy as np
Least Square (Linear Regression)
dataframe 上で線形回帰が簡単にできます。しかも超高速。
size = 100_000
df = pl.DataFrame({
"dummy": ["a"] * (size // 2) + ["b"] * (size // 2)
, "x1" : range(size)
, "x2" : range(size, size + size)
, "y": range(-size, 0)
})
print(df)
res_df = df.lazy().select(
pl.col("y").num_ext.lstsq(pl.col("x1"), pl.col("x2"), add_bias=False)
).collect()
print(res_df)
結果は以下。
shape: (100_000, 4)
┌───────┬───────┬────────┬─────────┐
│ dummy ┆ x1 ┆ x2 ┆ y │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ i64 ┆ i64 │
╞═══════╪═══════╪════════╪═════════╡
│ a ┆ 0 ┆ 100000 ┆ -100000 │
│ a ┆ 1 ┆ 100001 ┆ -99999 │
│ a ┆ 2 ┆ 100002 ┆ -99998 │
│ a ┆ 3 ┆ 100003 ┆ -99997 │
│ … ┆ … ┆ … ┆ … │
│ b ┆ 99996 ┆ 199996 ┆ -4 │
│ b ┆ 99997 ┆ 199997 ┆ -3 │
│ b ┆ 99998 ┆ 199998 ┆ -2 │
│ b ┆ 99999 ┆ 199999 ┆ -1 │
└───────┴───────┴────────┴─────────┘
shape: (1, 1)
┌─────────────┐
│ y │
│ --- │
│ list[f64] │
╞═════════════╡
│ [2.0, -1.0] │
└─────────────┘
ちゃんと、y = a * x1 + b * x2 として線形回帰した場合の係数 (a, b) が得られています。
なんと、ある column の値ごと(group by や over)の線形回帰もできます。
res_df = df.group_by("dummy").agg(
pl.col("y").num_ext.lstsq(pl.col("x1"), pl.col("x2"), add_bias=False)
)
結果は以下。
shape: (2, 2)
┌───────┬─────────────┐
│ dummy ┆ list_float │
│ --- ┆ --- │
│ str ┆ list[f64] │
╞═══════╪═════════════╡
│ b ┆ [2.0, -1.0] │
│ a ┆ [2.0, -1.0] │
└───────┴─────────────┘
他にも FFT なども簡単にできるのでぜひ試して見てください。
tokenize
string に対する処理もできます。tokenize してみましょう。
size = 100_000
df = pl.DataFrame({
"sen":["Hello, world! I'm going to church."] * size,
"word":["words", "word"] * (size //2)
})
print(df)
res_df = df.select(
pl.col("sen").str.to_lowercase().str_ext.tokenize().explode().unique()
)
print(res_df)
結果は以下。
shape: (100_000, 2)
┌───────────────────────────────────┬───────┐
│ sen ┆ word │
│ --- ┆ --- │
│ str ┆ str │
╞═══════════════════════════════════╪═══════╡
│ Hello, world! I'm going to churc… ┆ words │
│ Hello, world! I'm going to churc… ┆ word │
│ Hello, world! I'm going to churc… ┆ words │
│ Hello, world! I'm going to churc… ┆ word │
│ … ┆ … │
│ Hello, world! I'm going to churc… ┆ words │
│ Hello, world! I'm going to churc… ┆ word │
│ Hello, world! I'm going to churc… ┆ words │
│ Hello, world! I'm going to churc… ┆ word │
└───────────────────────────────────┴───────┘
shape: (5, 1)
┌────────┐
│ sen │
│ --- │
│ str │
╞════════╡
│ hello │
│ to │
│ going │
│ church │
│ world │
└────────┘
原型のみを取得したりもできますが、現状は英語のみの対応のようです。
他にも例えば hamming 距離や levenshtein 距離も簡単にできます。
Stats
ある分布からサンプリングしたり、t 検定などもできてしまうようです。ぜひ、上であげた example を見てみてください。
df.with_columns(
pl.col("a").stats_ext.sample_normal(mean = 0.5, std = 1.).alias("test1")
, pl.col("a").stats_ext.sample_normal(mean = 0.5, std = 2.).alias("test2")
).select(
pl.col("test1").stats_ext.ttest_ind(pl.col("test2"), equal_var = False).alias("t-test")
, pl.col("test1").stats_ext.normal_test().alias("normality_test")
).select(
pl.col("t-test").struct.field("statistic").alias("t-tests: statistics")
, pl.col("t-test").struct.field("pvalue").alias("t-tests: pvalue")
, pl.col("normality_test").struct.field("statistic").alias("normality_test: statistics")
, pl.col("normality_test").struct.field("pvalue").alias("normality_test: pvalue")
)
作ってみよう
(2024/01/13 追記)MarcoGorelli 氏が tutorial を用意してくれています。
では、自分で Plugin を作成してみます。今回は、地図データに関する特徴量を作る際に活躍することが多い(?)、Uber の h3 index を扱えるものを作ってみます。 h3 の説明は省略しますが、簡単にいうと、地図を5角形と6角形を用いて適切に区切る方法です。
h3 を自力で実装するのは厳しいので、h3 の Rust 実装を使います。(本家は、C で実装されてたはず。)これは C への依存なしでゼロから Rust で実装されています!
Plugin を実装するにあたって、上で紹介した library や以下を参考にしています。
まだほぼ何も実装してないですが、latitude と longitude を受け取って、resolution = 3 における 64bit の index を返すところだけ書いてみました。
メインの部分はこちら。
使ってみましょう。
import polars as pl
from polars_h3 import H3
data = {"lat": [34.6432], "lng": [134.9976]}
df = pl.DataFrame(data, schema=[("lat", pl.Float64), ("lng", pl.Float64)])
print(
df.with_columns(
h3=pl.col("lat").h3.geo_to_h3("lng"),
)
)
実行結果。できてそう...?ちなみに、用いた (lat, lng) は兵庫県明石市の緯度軽度をググって出てきたものです。
shape: (1, 3)
┌─────────┬──────────┬────────────────────┐
│ lat ┆ lng ┆ h3 │
│ --- ┆ --- ┆ --- │
│ f64 ┆ f64 ┆ u64 │
╞═════════╪══════════╪════════════════════╡
│ 34.6432 ┆ 134.9976 ┆ 590788282166542335 │
└─────────┴──────────┴────────────────────┘
一応確認してみます。 590788282166542335 を hex に変換すると 832E6CFFFFFFFFF です。これを
でみてみましょう。
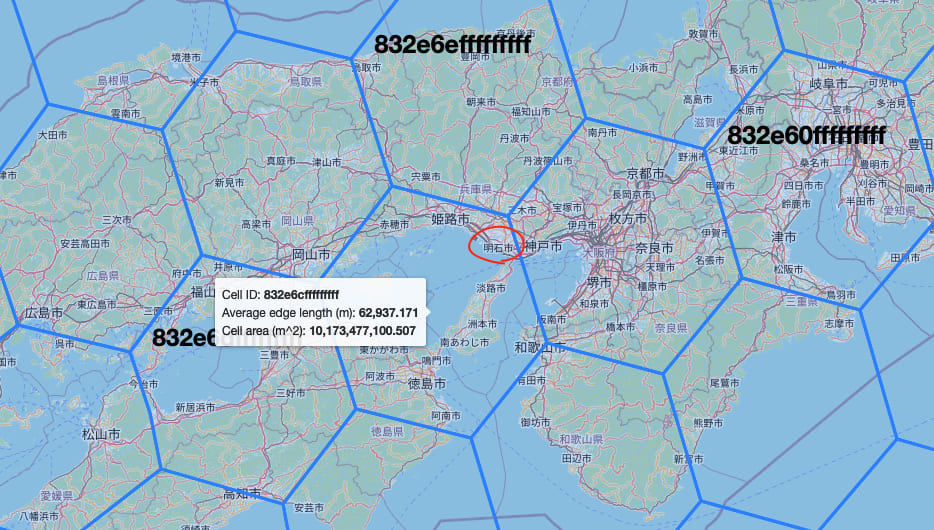
お、よさそうです!
本来ならば、ここで https://github.com/uber/h3-py + apply を使った実装と速度比較したいところですが、ちょっと力尽きたので余力ができたら追記しようと思います。
最後に
Polars の作者である Ritchie Vink が PyData で発表した動画が上がってました。Plugin についても話しています。非常に参考になるので、ぜひ観てみてください!
Discussion