TwHIN を理解したい


まとめ
- TwHIN で埋め込みを学習し、Ad のパーソナライズ、フォロー推薦、有害コンテンツ検出、検索ランキングに用いている。
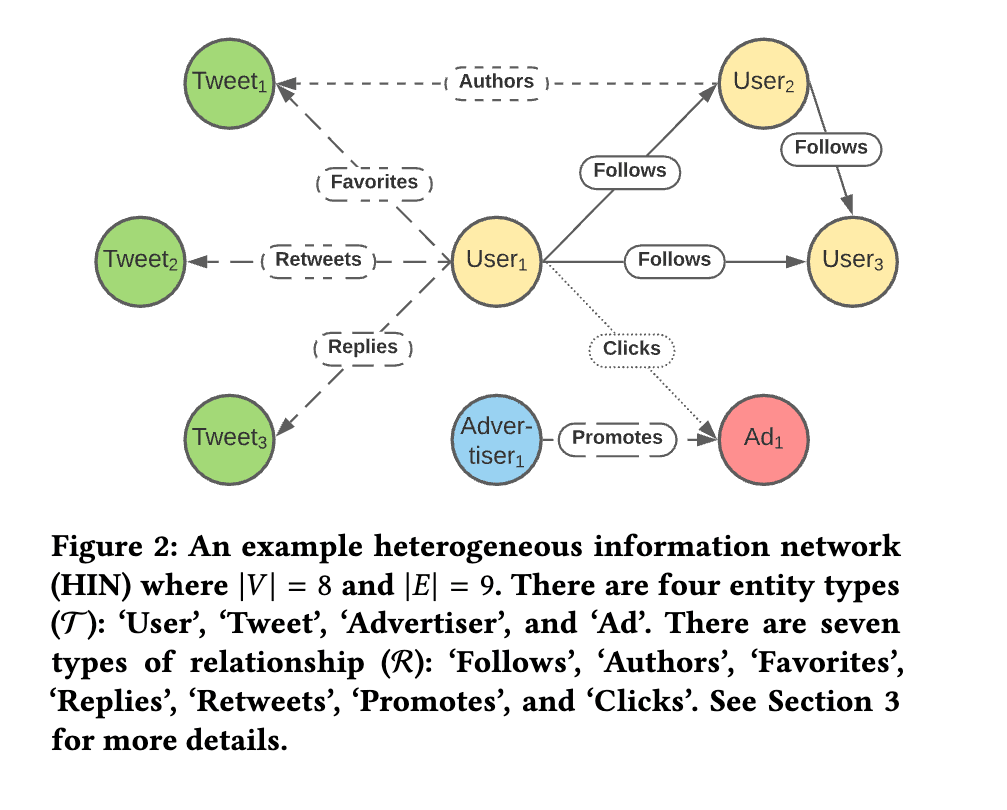
- TwHIN は複数のタイプのノード x 複数のタイプの関係(エッジ)のグラフである。
- 実装はほぼ PyTorch-Biggraph を用いているが、一部工夫したところがある。
導入
多くの事例では、user-item のインタラクションから埋め込みを学習しているが、それ以外の「関係」も利用した方が良いはず。
- Data Supplementation
- Task Reusability
なので、TwHIN では複数のタイプのノード x 複数のタイプの関係(エッジ)のグラフを構築。
学習もスケーラブルにしないとだめ。(
TwHIN における埋め込み
traslating embedding (TransE) を用いて、エッジ
とする。
学習は、エッジがあるかどうかの予測問題として学習を行う。すなわち、
という最適化問題を扱う。ただし、
実装
巨大なグラフを扱うために PyTorch-Biggraph を用いた。気持ちとしては、グラフのノードをパーティションに分け、ソースのパーティション x ターゲットのパーティションごとにプロセス(bucket と論文では呼ばれる)に割り当て学習を行う。

マルチモーダル埋め込み
上記の埋め込みには以下の2つの課題が存在する。
- entity が1つの埋め込みで表現されるため、複雑な趣味嗜好や行動を捉えきれない
- 埋め込みは "transductive" であり学習時に存在する entity のみ、新しい entity を予測するためには再学習するしかない
- 特に Twitter にとってはこちらが大きな問題となる
そのため次のような後処理を入れる。
- clustering を行う
- ノードが "engage" したクラスターを集約する
後続タスクのカテゴリ
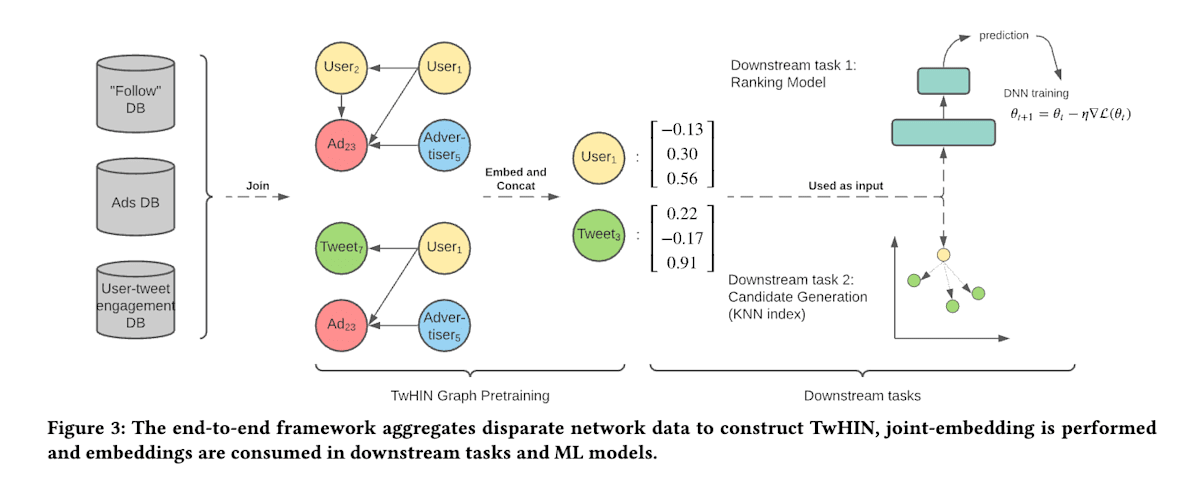
- candidate generation
- recommendation や prediciton のための特徴量(特徴量としての利用)
実験
後続タスクでの評価が行われている。
candidate generation (Who to Follow)
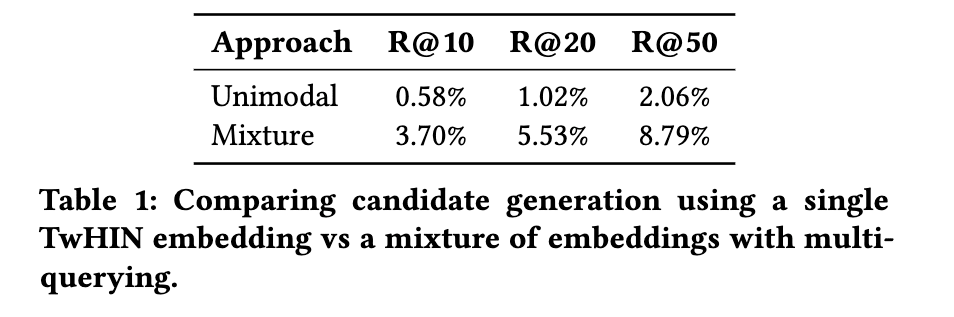
マルチモーダル埋め込みを利用することで、recall が 3倍以上になり candidate generation に対して非常に有効である。
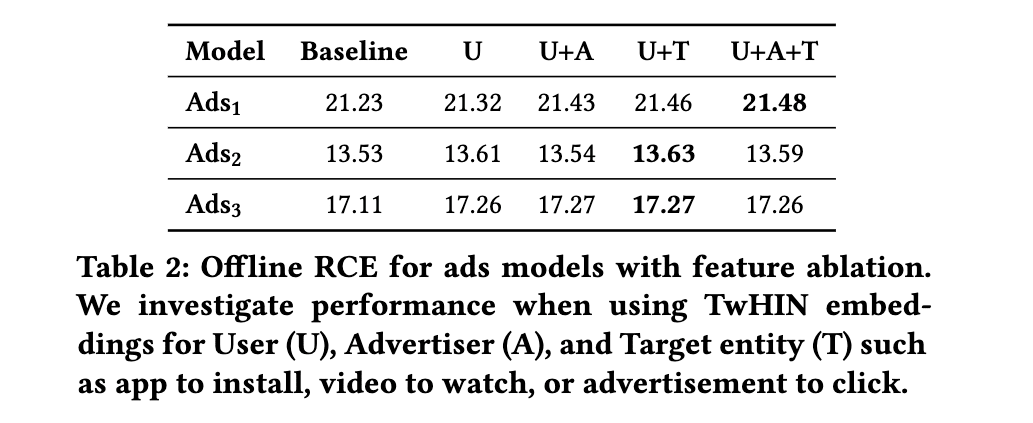
特徴量としての利用 (Ad Ranking)
モデルかやAB テスト実施日の詳細は非公開。評価には Relative Cross Entoroy (RCE) を利用。
TwHIN を追加することで 2.38 RCE gain(つまり、10.3% cost-per-conversion の減少)があった模様。さらに Heterogeneity の有効性を検証したのが以下。 (これはおそらく TwHIN の学習時の話で、TwHIN のモデル自体は同じで後続のモデルに特徴量を足すかどうかではない)
特徴量としての利用(Search Ranking)
Our baseline ranking system takes as input a large set of
hand-crafted features that represent the underlying user, query and
candidate Tweets. In addition, the input features also include the
outputs of an mBERT [9 ] variant fine-tuned on in-domain queryTweet engagements to encode the textual content of queries and
Tweets. The hand-crafted and contextual features are fed into an
MLP, where the training objective is to predict whether a Tweet
triggers searcher engagement or not.

これはオフライン結果のみ。
特徴量としての利用(Detecting Offensive Content)
このタスク自体は、Tweet が攻撃的かどうかを判定するタスクであり、その Tweet 自体によるところが大きいが、社会的なコンテキストやツイート主のコミュニティも使えるのかを検証したもの。

実用のための工夫
latency を小さくするために
埋め込みの次元と latency には trade-off が存在する。次元を大きくすると後続タスクのパフォーマンスが向上するが latency が増加する。 そのため、product quantization という方法で圧縮を行っている。

パラメタの急激なシフトを防ぐために
warm start または正則化によって防ぐ。
warm start
既存の entity に関しては前回のモデルの埋め込みで初期化する。新規 entity に関しては、
正則化
前の埋め込みとの L2 norm を導入するが、これはメモリが2倍必要になるという欠点がある。
検証結果
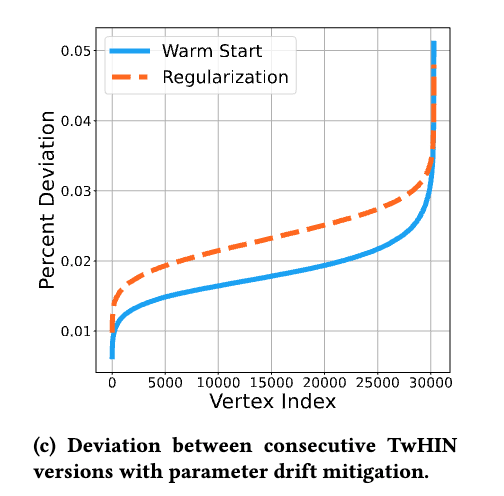
warm start の方がパラメタシフトを小さく抑えられていることがわかる。
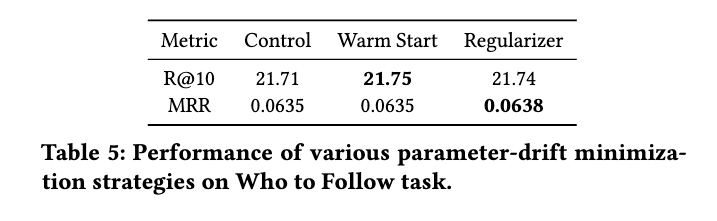
また後続タスク(Who to Follow)についても制度面で問題ないことが確認できる。実際には、warm start のみを採用しているらしい。
公開されたコード
小規模なデータで動かすためのだけのコードのようです。PyTorch-Biggraph を使ったようなコードはない。
TwHIN が使われてそうな場所はこちらですね。cr-mixer, home-mixer で使われていることが確認できます。pushservice というものでも一部使われているようです。
参考
コードメモ
config まで基本全部 Scala で書かれていて汎用性よりも柔軟性を重視している印象。サービスの数が比較的少ないので面別に最適化やチューニングを突き詰めようとする気概が感じられる。
Scala を愛する Twitter といえど流石に ML モデルは Python で書かれている。
Discussion