はじめに
ユビーでエンジニアをしているおおいしつかさです。
これは、Ubie Engineering Advent Calendar 2023の12月7日の記事になります。
何を書こうかなー、最近はユビーの根幹システムのリアーキテクチャをやっているのでその辺かなーと思ったのですが、まだ仕掛かり中だということと具体な業務に直結しそうな内容なので抽象化して書くのが面倒そうだなーと思ってたところに軽いトピックが飛び込んできたので、そのことを書くことにしました。
ChatGPTはみなさん使われていると思いますが、ぼくも別の業務でOpenAI関連の機能開発に携わっています(ユビーで働くといろんな業務に携われるのがいいところです) 。
その仕事の中で、Node.js環境でメモリ肥大化の事象に遭遇したので、それをどのように発見して改善したかについてお話します。
ぼくは今も昔もRubyが大好きですが、ふだんはTypeScriptを触ることが多くなってきました。
ひとつひとつ知らないことが出てきて、その度に勉強ができるので楽しいですね。
メモリの問題に気づく
OpenAI関連のプロダクトでは、ライブラリとして langchain を使っています。Node.jsで実装するなら使っている人は多いのかなと思います。
このプロダクト、ローカルでの動作はまったく問題なかったのですが、QA環境を確認すると以下のようなエラーが出ていました。
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
このメッセージは、ヒープ領域が足らなくなって新しいメモリを確保できなくなったことを示しています。
V8 Engine (Node.js の Javascriptエンジン) はスタック領域とヒープ領域のふたつのメモリ領域を持っています。オブジェクトのような動的にサイズが決まるようなものは、ヒープ領域のメモリが割り当てられます。
つまり、新しいオブジェクトを生成しようとしてヒープ領域のメモリを使おうとしたけど、もう空きがないよと言われてしまった状態です。
QA環境はKubernetesで構築されていて、Podには500MBのメモリを割り当てていました。
うーん、500MBもあるのに枯渇したのかな?
ローカルでは問題ないんですよね。プロセスのメモリを確認しても65MB程度なんです。
お掃除されたことを疑う
ローカル環境はMacbook Proなのですが、メモリは64GBもあります。
プロセスのメモリ使用量が500MBになっていないのは、GCが走って不要なオブジェクトが掃除されたからだとすると辻褄が合います。
一時的に大量にメモリを消費して500MBくらい使ったけど、GCが走ってお掃除されたので ps コマンドで確認したタイミングでは問題ないように見えている。ローカル環境のメモリは潤沢にあるので多少乱暴なことが起きても問題にならない。
一方、K8s環境だとメモリがそこまでないのでGCが走る前にヒープ領域が枯渇してしまった。
ありそうだなー。
GCで掃除されるということは、ずっと誰かに参照されているオブジェクトじゃないということです。
例えばループ処理内でのみ使われるオブジェクトなんかは怪しいです。
ヒープ領域を増やしてみる
ちなみにこの段階でNode.jsのヒープ領域のデフォルトのサイズを調べてみたのですが、使用可能な総メモリ量の半分が割り当てられるようです。
つまり、500MBのメモリを割り当てたPodの場合、ヒープ領域はデフォルトで250MBになるということです。
ヒープ領域はプロセス起動時のオプション、 --max-old-space-size でも設定できます。
ローカルでも --max-old-space-size=250 と指定して実行すると、QA環境と同じエラーが出ることが確認できました。
脱線するけど、V8 EngineのGCを調べてみる
なんで、 --max-old-space-size って old なんだろう。
気になったので、V8 Engine のメモリ構造、GCまわりの挙動を簡単ですが調べてみました。
ヒープ領域自体が実はいくつかの領域に分けられているのですが、その中で今回関係ありそうなのは New Space と Old Space です。
V8 Engine は世代別GCを採用していて、minorGCを2回生き延びたオブジェクトが Old Spaceに移ります。それまでは New Spaceで管理されます。
どうして --max-old-space-size が old なのかはこれでわかりました。正確にはヒープ領域ではなく、ヒープ内の Old Space のサイズを指定するオプションということなんですね。
New Space で実行されるのは minorGC です。
New Space はさらにふたつの領域に分けられていて、それぞれ from-space と to-space と呼ばれています。
オブジェクトが生成されるとそれは from-space に割り当てられます。
もし from-space に空きがない場合、minorGC が発動します。
from-space 内のオブジェクトを探査して、生きているものは to-space に移動させます(2回のminorGCを生き延びたものは Old Spaceへ行く)。生きてないものは解放されます。
この処理が終わると to-space が from-space になり、 from-space が to-spaceになります。
こうして新しいオブジェクトを from-space に入れる余地が生まれるわけです。
ちなみに New Space のサイズを指定するオプションは --max-semi-space-size ですが、これは New Spaceではなくて from-space(またはto-space)のサイズになるようです。
Old Space の GCアルゴリズムは マーク&スイープにプラスしてコンパクションも行われます。
メインスレッドでGCを走らせるといわゆる Stop the world が発動しちゃうので、並列作業できるところは別スレッドで処理をするようです。
参考: https://v8.dev/blog/trash-talk
テストコードを用意
GCとかメモリ構造がなんとなくわかったところでメモリ肥大化問題に戻ります。
現象をシンプルに理解するために、業務用のコードではなくて擬似的なシンプルなコードで試してみます。
langchainのリポジトリにサンプルコードがたくさんあるので、そのうちのひとつ を使います。
このコードの中の chatPrompt という変数の中身を以下のように変更してみます。
const chatPrompt = ChatPromptTemplate.fromMessages([
[
"system",
"You are a helpful assistant that translates {input_language} to {output_language}.",
],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
["human", "{text}"],
]);
このように chatPromptのプロンプト数を増やしてみると、ヒープ領域の空きがないというエラーが発生しました。
どうもプロンプト数とメモリ肥大化現象は関係がありそうです。ループ処理で使われてそうなオブジェクトという推察にも近い感じがします。
このコードのまま、試しにヒープ領域のサイズを750MBにして実行するとエラーはでません。
プロンプトを増やしながら実行してみると、20程度のプロンプト数になったところで同じエラーが発生しました。
プロンプト数と関係があるのは確かなようです。
ヒープ領域の使用状況を確認する一番簡単な方法
Node.jsでは、 process.memoryUsage() でヒープ領域の状態を確認できます。
memoryCheck() {
const heap = process.memoryUsage();
const msg = [];
for (const key in heap) {
msg.push(`${key}: ${Math.round(heap[key] / 1024 / 1024)} MB`);
}
console.log(msg.join(', '));
}
こんな関数を定義しておいて、要所要所で古(いにしえ)のprintfデバッグをすれば、問題の箇所にたどり着けるはずです。
ただし相当な時間がかかります。最後の最後の確認に使うくらいがよさそうです。
ちなみにプロンプト数を20にしたテストコードの最初と最後でヒープ領域を見てみました。
start
rss: 164 MB, heapTotal: 31 MB, heapUsed: 28 MB, external: 2 MB, arrayBuffers: 0 MB
end
rss: 1137 MB, heapTotal: 999 MB, heapUsed: 959 MB, external: 3 MB, arrayBuffers: 0 MB
かなりヒープ領域を使っていますね。
VSCodeのデバッガーを使う
copilotも使える現代においてvimを使っている場合じゃないということで、15歳の頃から使っていたviを卒業してぼくもとうとうVSCodeを使っています(vimでもcopilot使えそうではあるけど)。
デバッガーを使えばどこでヒープを大量に消費したのかわかるのでやってみます。
デバッガーを実行するためには、Node.jsをdebugモードで起動する必要があります。
package.json で以下のようにスクリプトを用意しておきます。
"start:debug": "nest start --debug --watch"
.vscode/launch.json がなければそれも用意しておきます。
envファイルの場所など、自分のプロジェクトにあったものに修正しておきましょう。
{
version: 0.2.0,
configurations: [
{
type: pwa-node,
name: Launch debugger,
request: launch,
runtimeArgs: [
run,
start:debug
],
runtimeExecutable: npm,
skipFiles: [
<node_internals>/**
],
sourceMaps: true,
envFile: ${workspaceFolder}/.env.local,
cwd: ${workspaceRoot},
console: integratedTerminal,
protocol: inspector
},
]
}
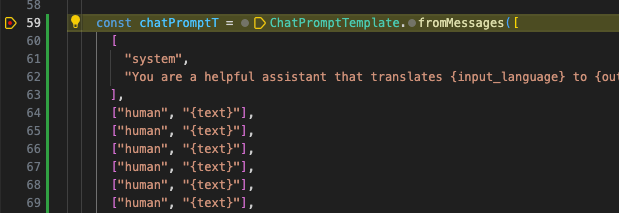
テストコードの最初と最後の部分にブレークポイントを設定して、あとはメニューの「実行」 -> 「デバッグの開始」を選択するとデバッガーが起動します。
最初のブレークポイントで処理が止まったら、左側にあるコールスタックの二重丸みたいなアイコンをクリックします。
プロファイルの種類の選択メニューが現れるので、「Heap Profile」 を選択します。ヒープ領域を調べたいですもんね。
プロファイルの実行期間のメニューは、「ブレークポイントの選択」を選びます。

ブレークポイントの選択メニューが出ますが、チェックボックスはオンのままOKボタンを押します。
すると以下のような画面になります。

processTicksAndRejections というところで235MBくらい使っていていかにも怪しいですね。サイズの大きいところを開いていきます。

langchainの getEncoding という関数で呼ばれている js-tiktokenの _Tiktoken という関数がヒープを大量に使っているようです。
右のファイル名のところをクリックするとそのコードにジャンプすることができます。
js-tiktokenの _Tiktokenはconstructorでした。その前の getEncoding でオブジェクトを生成しています。
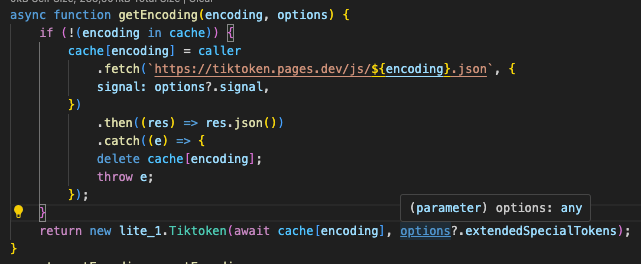
この getEncoding が呼ばれる度に Tiktokenオブジェクトが生成されているようです。
langchainのリポジトリ上の対象のコードは以下になります。
export async function getEncoding(
encoding: TiktokenEncoding,
options?: {
signal?: AbortSignal;
extendedSpecialTokens?: Record<string, number>;
}
) {
if (!(encoding in cache)) {
cache[encoding] = caller
.fetch(`https://tiktoken.pages.dev/js/${encoding}.json`, {
signal: options?.signal,
})
.then((res) => res.json())
.catch((e) => {
delete cache[encoding];
throw e;
});
}
return new Tiktoken(await cache[encoding], options?.extendedSpecialTokens);
}
https://github.com/langchain-ai/langchainjs/blob/cc09d151d6712ab9326ddc6d0fb4986a63dc5708/langchain-core/src/utils/tiktoken.ts#L14-L34
(ネットからjsonファイルを拾っていることはいったん見なかったことにします...)
プロンプトごとにこの getEncoding が呼ばれていました。
getEncoding関数では new Tiktoken が実行されて Tiktokenオブジェクトが生成されるわけですが、このTiktokenオブジェクトがかなりヘヴィなお方で50MBくらいあったりします。
つまりプロンプトが20あると、20*50MB=1000MB くらいヒープを喰う可能性があるということです...!
修正してPullRequestを送る
修正は簡単です。
もともとネットからjsonファイルを取得した結果はキャッシュとして保持していたのですが、jsonファイルではなくてTiktokenオブジェクトをキャッシュするように変更しました。
これで何度 getEncoding が呼ばれても、encodingが同じならTiktokenオブジェクトの生成が走らないようになります。
その内容で修正してPullRequestを送りました。
https://github.com/langchain-ai/langchainjs/pull/3519
PRはすぐにマージされてリリースされました。
バージョン 0.0.201 以降を使うとこの修正が適用されています。langchainを使っていてメモリの問題にぶつかっていたみなさん、ぜひ使ってみてください。
ちなみに修正後のlangchainでテストコードを走らせるとヒープ領域の状況は以下のようになりました。大丈夫ですね!
start
rss: 110 MB, heapTotal: 58 MB, heapUsed: 34 MB, external: 1 MB, arrayBuffers: 1 MB
end
rss: 231 MB, heapTotal: 116 MB, heapUsed: 93 MB, external: 2 MB, arrayBuffers: 0 MB
さいごに
今回は、Node.jsの開発中に遭遇したメモリ肥大化問題についてお話しました。
Node.jsでメモリプロファイリングする際の参考にしていただけたら幸いです。
明日のアドベントカレンダーは弊社のSREエンジニア、@kamina_zzz の記事になります。
楽しみにしていてください!

Discussion