始めに
Ubieでプラットフォームエンジニア兼SREをしているonoteruです。
前々回の記事では、テンプレーティングツール「ubieform」を使ったプラットフォームエンジニアリングと、マルチクラスタ構成への移行について紹介しました。続く前回の記事では、Argo WorkflowからCloud Workflowsへの移行について紹介しました。そして今回は連載の最後として、「CloudSQLからAlloyDBへの移行」について紹介しようと思います。
この移行は、前回までのマルチクラスタ化やワークフローの移行と同様、Ubieのプラットフォームをより信頼性が高く、運用負荷の少ないものへと進化させるための重要な取り組みでした。特に、データベース基盤をより柔軟でスケーラブルなものに刷新することで、今後の事業成長に備えることを目指しました。
本記事では、CloudSQLを使用する中で直面していた課題から、AlloyDBを選択した理由、そして移行によって得られた効果までを紹介していきます。
背景:データベース基盤が抱える課題
マイクロサービスとワークフローを新しいプロジェクトに移行し終えた一方で、データベース基盤にはまだ課題が残されていました。Ubieでは全てのデータベースにCloudSQLを使用していましたが、以下のような制約に直面していました。
CloudSQLの構造的な制約
CloudSQLの特徴として、コンピュートリソースとストレージが結合している点が挙げられます。これは基本的にVMにPersistent Diskをアタッチする方式で実現されており、個別のスケーリングや管理が難しい構造となっています。内部的にはフェイルオーバー時にVMのコピーを使うなど工夫がされているようですが、コンピュートリソースとストレージが分離されたデータベースと比較していくつか機能の制約がありました。
まず一番大きいものは、インスタンスサイズの変更やDBエンジンのアップグレード時に数分間のダウンタイムが発生していた(現在は条件による、後述)という点です。UbieではPostgreSQLを使っているため、定期的にバージョンアップのためのメンテナンス通知が降ってきます。アップグレードのメンテナンス時は数分間DBがオフラインになるため、そのDBの利用者である医療機関への事前通達と深夜メンテナンスの調整が必要となり、運用面での負担となっていました。
他にも、インスタンスとバックアップが密結合しており、インスタンスを削除するとそのバックアップも同時に削除されてしまうため、データの保持とインスタンス管理の柔軟性が制限される、という課題も抱えていました。
プロジェクト構成とデータベース管理の課題
CloudSQLの制約以外にも、以下のような課題を抱えていました。
-
シングルプロジェクト
これまでの記事で説明してきた通り、マイクロサービスやワークフローはそれぞれが扱う事業ドメインごとにプロジェクトやクラスタが分離されました(この分離の単位を社内ではセグメントと呼んでいます)。一方、データベースは依然として単一のプロジェクトに集約されていたため、新しいアーキテクチャの方針と整合性が取れていない状態でした。この状態だと、将来的にセグメント単位でVPC Service Controlを適用するといった、さらなるセキュリティ施策の実施が困難になります。
-
手作業による管理の限界
データベース内部の管理に関しても課題がありました。スキーマの作成やロールの付与などの細かな設定は、そもそもGoogle Cloud APIが存在しないため、他のクラウドリソース管理に使っているTerraformのGoogle Cloud providerを使うことができません。
そのため、これらの操作は手作業で行う必要があり、変更履歴の追跡が困難になっていました。また、ユーザーのパーミッション管理も適切に行えない状況が生まれ、必要以上に強い権限を持ったユーザーでの操作が常態化してしまうなど、セキュリティ面での懸念も抱えていました。
これらの課題を解決するため、データベース基盤をAlloyDBへと移行すると共に、プロジェクトの分離やデータベース内部の設定のコード化も実施することにしました。AlloyDBを選択した理由は以下の通りです。
- アップグレードやインスタンスサイズ変更時、DBへの接続は瞬断で済む(near-zero downtime upgrade)。そのためリトライを工夫することで夜間メンテナンスを計画する必要がなくなる
- CloudSQLと比較して優れたパフォーマンスと拡張性を持つ
- Geminiを活用したAI機能の将来的な活用が期待できる
- PostgreSQLとの高い互換性があり、移行が容易
1つ目と2つ目の理由は、コンピュートリソースとストレージが分離されているというAlloyDBのアーキテクチャ上の特性に起因するものです。それぞれが独立してスケールすることにより、高いパフォーマンスとメンテナビリティを獲得しています。
なお、このデータベース移行プロジェクトの最中である2024年の後半には、CloudSQL Enterprise Plus editionの機能としてnear-zero downtimeでのインスタンスサイズ変更やアップグレードがサポートされました。そのため、この機能に限っていえばAlloyDBの優位は無くなりました。一方でCloudSQL Enterprise Plus editionとAlloyDBを比較した場合、AlloyDBの方がコア数あたりのコスパが良い点や、アーキテクチャレベルで優れており今後の発展が期待できる点などを鑑みてこちらを選択しました。
新しいデータベースアーキテクチャ
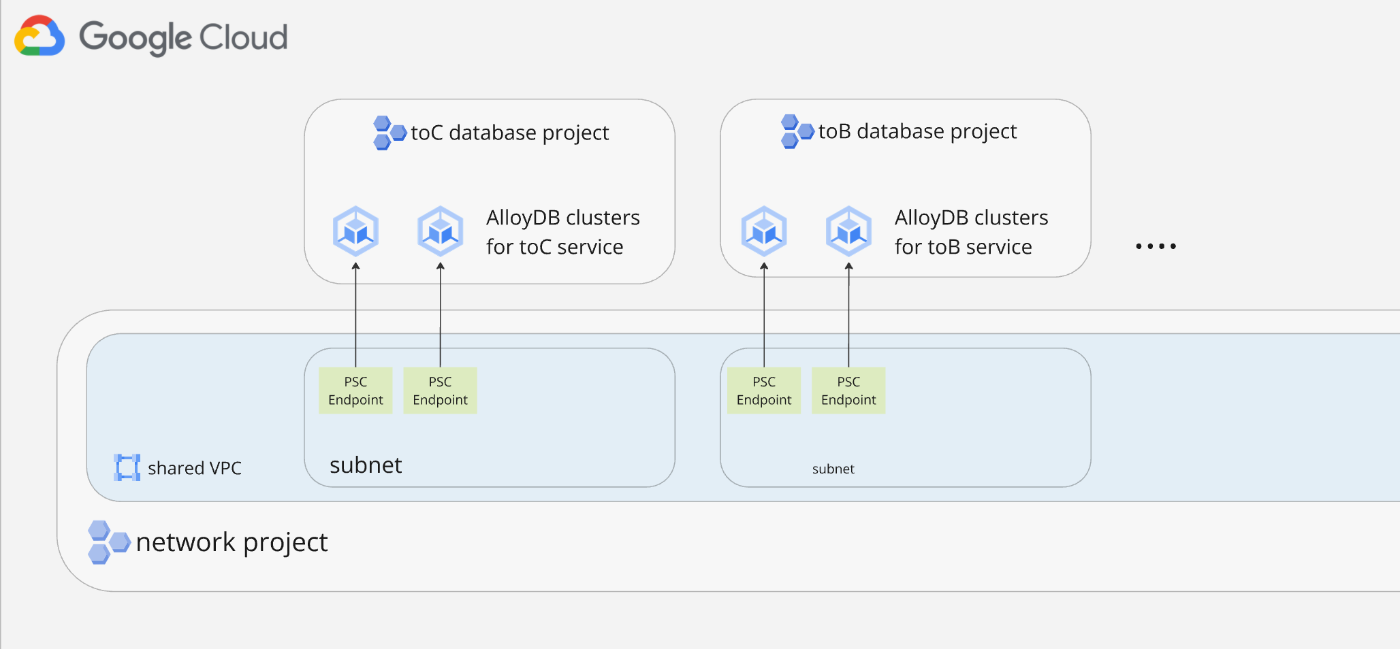
既存のCloudSQLインスタンスを、AlloyDBを用いて適切に分離されたプロジェクトに再構築しました。プロジェクトの分割単位は、前回までに説明したGKEクラスタの分割(セグメント)と同様としましたが、コンピュートリソースとは別のプロジェクトとして構築しています。
この移行に際して、以下のような改善を実施しました。
ネットワーク接続の改善
データベースへの接続方式として、Private Service Connect(PSC)を採用しました。以前はPrivate services access(PSA)を使用していましたが、PSCの方がより安全な接続を実現できます。PSAがVPCピアリングを使用するのに対し、PSCはターゲットとなるサービスに直接接続される方式を取るためです。詳細な比較については公式ドキュメントを参照してください。
ユーザー管理の刷新
AlloyDBでは、IAMベースのユーザー管理が可能です。これを活用し、従来のパスワードベースのユーザーをIAM-based AlloyDBユーザーに置き換えました。この変更によって、パスワード管理の手間から解放されました。また、IAM-based AlloyDBユーザーを利用するため、AlloyDB Auth ProxyをPodのサイドカーコンテナとして導入しました。これにより、アプリケーションからのデータベース接続時にIAM認証を透過的に行うことができます。
GKEからの利用
GKEで動作するアプリケーションからAlloyDBを利用する場合は、以下のような流れになります。
- アプリケーションのPodで使用するKubernetesサービスアカウント(例:
my-service-app)を作成 - このKubernetesサービスアカウントに、AlloyDB用のGoogleサービスアカウント(
my-database@example-db.iam.gserviceaccount.com)へのroles/iam.serviceAccountTokenCreatorロールをWorkload Identity for GKEを使って付与 - アプリケーションのサイドカーコンテナであるAlloyDB Auth Proxyは、PodのKubernetesサービスアカウントを使いAlloyDB用Googleサービスアカウントに対してimpersonationする
- アプリケーションは、
my-database@example-db.iamというIAM-based AlloyDBユーザを使いサイドカーを経由してPostgreSQLにログインする
この方式により、アプリケーションごとに適切な権限を持つサービスアカウントを割り当てることができ、最小権限の原則に従った運用が可能になります。
データベース設定のコード管理
データベース内部の設定(スキーマやユーザー権限など)は、cyrilgdn/postgresql Terraformプロバイダーを使用してコード管理しています。ただし、AlloyDBインスタンスはPSC経由での接続のみを許可しているため、Terraformの実行環境(GitHub Actions)からPSCエンドポイントのあるVPC内部へ到達できる必要があります。
この課題に対しては以下のようなCIを作成することで解決しました。
- TerraformのCI実行時のみ、AlloyDB Auth ProxyのPodをGKEに一時的に作成
- CIからそのPodへポートフォワードを行い、Podを経由することでDBへの疎通を確保
- 処理完了後にPodを削除
PostgreSQLリソースを管理するTerraformコードでは、スキーマやユーザ権限設定をするため強い権限を持つDBユーザーでの実行が必要です。そのため、常時起動の踏み台VMを経由してVPCへと接続する方式は避け、一時的なPodを使用する方式を選択しました。なお、GitHub Actionsのself hosted runnerやCloud BuildのPrivate Poolを使用してAlloyDBへの疎通性を確保する方法も考えられますが、既存の実行環境の変更を避けたかったためこのようになりました。
実装
ここでは、新しいアーキテクチャにおける具体的な実装方法について説明します。
アプリケーションからの接続
アプリケーションからAlloyDBへの接続は、これまでと同様にubieformを使って設定を行います。以下に基本的な設定例を示します。
name: "sample-service"
env: ["qa", "stg", "prd"]
segment: "sample-segment"
service_config: {
manifest: {
app: {
main_container: {
image_path: "asia-northeast1-docker.pkg.dev/example/{{.Env}}/sample-service"
...
}
sidecars: [_alloydb_proxy_app]
}
}
}
...
_alloydb_proxy_app: {}
この例のように、AlloyDB Auth ProxyはPodのサイドカーコンテナとしてubieformに追加することができます。ubieform内部でAlloyDB Auth Proxyサイドカーのimage_pathやcommandのデフォルト値が生成されるため、利用者は特別な設定を意識する必要がありません。ただし、必要に応じてこれらの値を上書きすることも可能です。
なおubieformの設定にAlloyDBへの接続設定を書くと、AlloyDBクラスタのGoogle CloudコンソールURLがUbieHubのサービス詳細ページに対して自動で追加されます。
PostgreSQLリソース設定
データベースやスキーマ、権限などのPostgreSQLリソースの設定は、cyrilgdn/postgresql providerを使ったTerraformモジュールとして提供しています。以下に使用例を示します:
module "my_database" {
...
database = {
name = "my_database"
owner = {
name = "my-owner@example.iam"
}
}
schemas = {
"my_schema" = {
owner = {
name = "my-owner@example.iam"
}
grant_ddl_users = [
{
name = "my-migration-user@example.iam"
},
...
]
grant_dml_users = [
{
name = "my-app-user@example.iam"
},
...
]
grant_ro_users = [
{
name = "my-readonly-user@example.iam"
},
...
]
}
}
}
このモジュールでは、権限セットを以下の3レベルに大別することで、権限管理の利便性を向上させています。
- DDL権限(
grant_ddl_users)-
CREATEなどのスキーマ変更権限 - マイグレーション用ユーザーに付与
-
- DML権限(
grant_dml_users)-
INSERT、SELECT、UPDATE、DELETEなどのデータ操作権限 - アプリケーション用ユーザーに付与
-
- 読み取り専用権限(
grant_ro_users)-
SELECTのみの権限 - 分析用ユーザーなどに付与
-
上のサンプルコードでは、以下のような権限設定が自動的に行われます。これらは以前まで踏み台となるGCEインスタンスにログインし、データベースに接続してから手動で設定していたものですが、今となってはTerraformを書くだけで簡単に扱うことができます。
-
my_databaseデータベースの作成 -
my_schemaスキーマの作成 -
my-migration-user@example.iamに対するDDL権限の付与 -
my-app-user@example.iamに対するDML権限の付与 -
my-readonly-user@example.iamに対する読み取り専用権限の付与
移行
これまでのGKEやワークフローの移行とは異なり、データベースの移行は深夜の停止メンテナンスを利用して実施しました。移行方式や実施方法について、以下で詳しく説明します。
データ移行方式の選択
データの移行には、pg_dumpとpg_restoreを使用したダンプ&リストア方式を採用しました。レプリケーションではなくこの方式を選んだ理由は、データ量とユーザー管理の2つの観点からでした。
まず、データ量については、深夜メンテナンスの数時間で移行が完了できる程度でした。これは、Ubieでは大規模なデータを扱うサービスはCloud Spannerを使用しており、CloudSQLには比較的小規模なデータベースのみが存在していたためです。
また、今回の移行ではパスワードユーザーからIAM-basedユーザーへの移行も同時に行う必要がありました。レプリケーション方式を採用した場合、データの書き込み先を切り替えた後に別途ユーザー変更のステップが必要になります。一方、ダンプ&リストア方式であれば、リストア時に新しいユーザーをテーブルオーナーとして指定できるため、データ移行とユーザー切り替えを同時に実施できるという利点がありました。
移行ジョブの実装
データ移行作業の実行基盤として、Google Cloud Batchを採用しました。Batchを選択した理由は、ローカルストレージの利用と実行の容易さにあります。
前回の記事で紹介したワークフローシステムでデータを移行しようとすると、ワーカーとなるCloud Run jobsでは大きなローカルストレージを扱えず、GCSをマウントするなどの追加の対応が必要になってしまいます。
一方でBatchはVMで実行されるためSSDをアタッチすることでローカルストレージを利用できるため、pg_dumpとpg_restoreのステップ間でローカルのディレクトリを使い、ダンプデータを効率的に受け渡すことができます。
また、他のジョブ実行基盤では一般的にジョブ定義と実行が分かれていますが、Batchの場合は1つのコマンド(gcloud batch jobs submit)でジョブ定義と実行を同時に行えます。さらに、コンテナイメージを作成せずともbashスクリプトをそのまま実行することも可能です。1回きりの移行作業には、このシンプルな実行フローが適していました。
移行ジョブの実行フローは、CloudSQLからのデータダンプ(pg_dump)に始まり、ダンプファイルをローカルのSSDに保存し、AlloyDBへのリストア(pg_restore)を行うという流れで実施しました。
移行後の成果
移行完了後、データベース周りのプラットフォームは大きく改善され、いくつかの具体的な成果が得られました。
まず、マルチプロジェクト化の取り組みが完了し、GKE、ワークフロー、そしてデータベースの全てが適切に分割された状態となりました。これにより、セグメントごとの境界が明確になり、より高度で安全な運用に向けた体制が整いました。
さらにデータベースのセットアップがコード化されたことで、以前のような「踏み台サーバーにログインしてDBを手作業で設定する」といった作業がほとんど不要になりました。Terraformを使った宣言的な設定により、データベースの構成管理が効率化され、開発者の生産性が向上しています。
また、Geminiと統合されたAlloyDB Studioは、開発者から特に好評を得ています。QAやSTG環境において、ブラウザ上で直接データを確認できる機能は、デバッグ作業を大幅に効率化しました(ただしセキュリティ上の理由から、本番環境でのAlloyDB Studioの利用は禁止としています)。
さらに、AlloyDBへの移行後、一部のサービスではパフォーマンスが向上し、CloudSQL時代と比較してCPUコア数を削減することができました。これは、AlloyDBの優れたパフォーマンス特性を活かせた結果といえます。
AlloyDBを使って感じた課題など
ここではAlloyDBに移行して感じた点をいくつか紹介します。
PSCの設定が複雑
課題というほどのものでもないですが、AlloyDBインスタンスに対してPSCエンドポイントを設定するのはやや大変で、以下の4つのTerraformリソースが必要になります。
- google_compute_address: PSCエンドポイントとなるIPアドレス
- google_compute_forwarding_rule: PSCエンドポイントからAlloyDBインスタンスへの転送ルール
- google_dns_managed_zone: AlloyDBインスタンスのDNS zone
- google_dns_record_set: AlloyDBインスタンスのDNS record
これらのリソースはAlloyDBインスタンスごとに必要となるため、リードレプリカを作成する際はその数だけ必要になります。AlloyDB用のTerraformモジュールで隠蔽しているため利用者がこれらのリソースと関係性を把握する必要はありませんが、モジュール内の実装は若干複雑になりました。
なおCloudSQLの方はservice connection policyを使うことで、自動的にインスタンスに対してPSCのセットアップができるようです。AlloyDBにもこの機能がやってくることを期待しています。
IAM-based AlloyDBユーザが使えないケースがある
ユーザ管理のセクションで紹介した通り、UbieではPostgreSQLのユーザとして基本的にIAM-based AlloyDBユーザを利用しており、パスワードユーザを発行するのは原則禁止となっています。
しかし、現時点では以下のツールやサービスでIAM-based AlloyDBユーザーがサポートされていないため、これらの用途に限ってパスワードユーザーを発行しています。
- AlloyDB Studio(データベース管理用WebUI)
- BigQueryのfederated query
こちらも将来的にIAM-based AlloyDBユーザが利用できるようになることを期待しています。その時が来たら、順次ユーザを置き換えていく予定です。
まとめと今後について
この記事では、UbieのデータベースプラットフォームをCloudSQLからAlloyDBへ移行した取り組みについて紹介しました。この移行は、単なるデータベースエンジンの置き換えではなく、以下のような多面的な改善を実現するものでした。
- マルチプロジェクト化によるセグメント単位での分離
- IAMベースの認証による統一的なアクセス制御
- データベース設定のコード管理による運用効率の向上
- AlloyDB Studioによる開発者体験の改善
前々回の記事で紹介したマルチクラスタ化、前回の記事で紹介したワークフローの移行、そして今回のデータベース基盤の刷新により、Ubieのプラットフォームは1年で大きく進化しました。
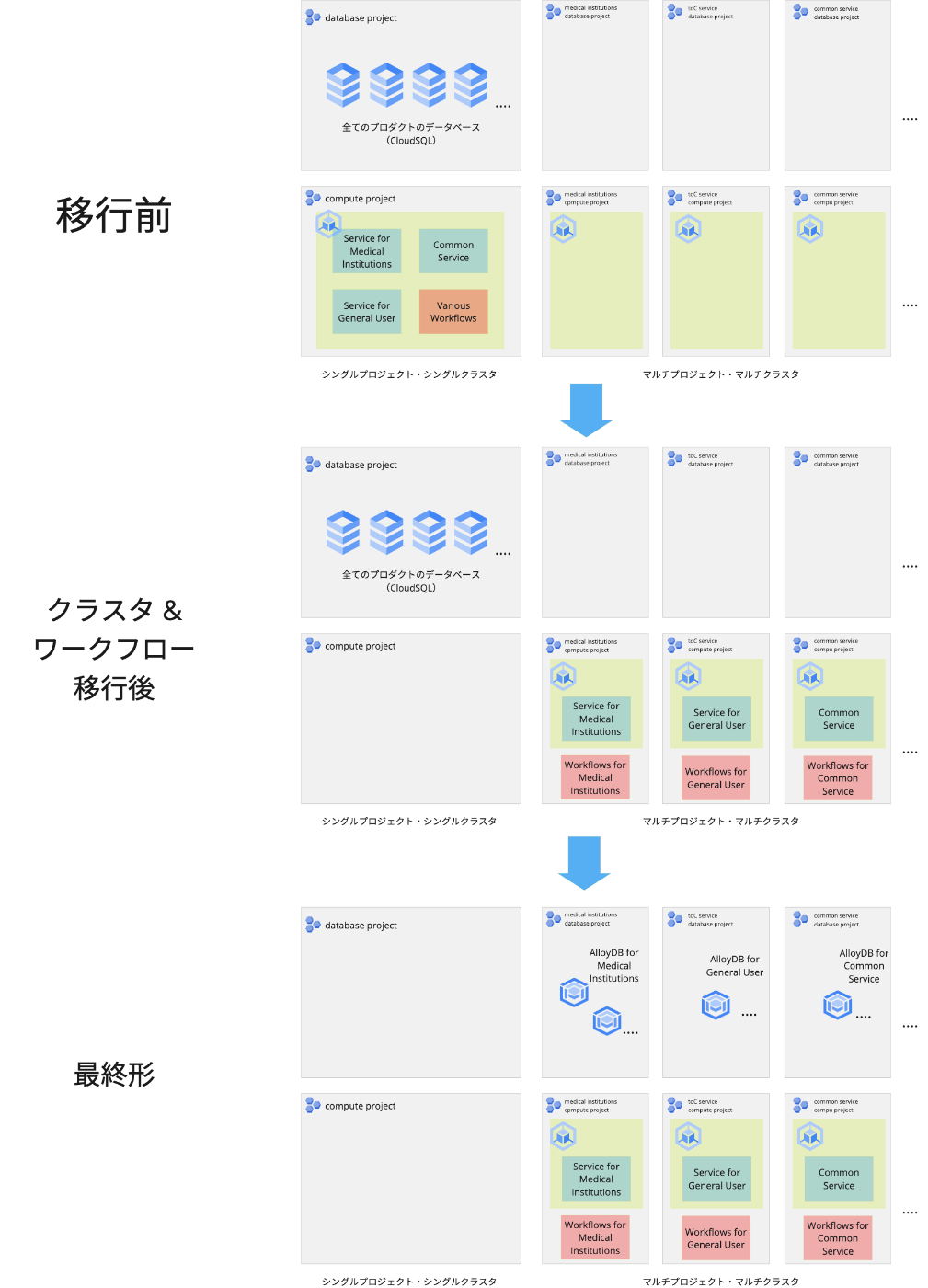
これらの一連の移行プロジェクトでキーワードとなったのは、「標準化」です。ubieformやUbieHubといった社内エコシステムを整備し、全てのサービスをその上で統一的に運用できる状態を目指して移行が進められました。
この標準化により、どのチームのどのサービスであってもインフラ部分は同様の方法で扱えるようになり、サービス立ち上げやトラブルシューティングの効率が向上しました。特に、多数のマイクロサービスを運用しているUbieにおいて、この効果は顕著に表れています。
今後は、生成AIを活用した問い合わせの自動応答システムの構築や、高度なモニタリングの自動化など、さらなる運用効率の向上に向けた取り組みなどが計画されています。
Ubieでは今後もプラットフォームエンジニアリングを通した開発者体験の向上に取り組んでいく予定です。

Discussion