本稿は Ubie Engineering Advent Calender の6日目の記事です。Ubieで機械学習エンジニアをやっている @hagino3000 です。今回はなんらかの予測を行なうWebAPIのテストについて書きます。
背景
ユーザーの入力を受けとってなんらかの予測を行なうWebAPIをマイクロサービスとして日々運用していると、予測結果自体には影響の無い修正をリリースすることが度々あります。ライブラリのバージョンアップが最も多く、他にはリファクタリング、予測モデルのデプロイパイプラインの変更や前処理・予測アルゴリズムの高速化などです。これらの変更をリリースする際に確認したいのが、変更が意図せず予測結果に影響を与えていないかどうかです。
入力と予測結果のペアを持つEnd-To-Endのテストを書いておくのが1つの方策として考えられます。しかし入力が高次元であったり、カーディナリティの高いカテゴリ値が存在すると入力パターンを網羅するのは現実的ではありません。予測モデルが変わると結果も変わるのでテスト用の予測モデルを用意しておく必要もあり、テストの維持コストは高いです。また実際の予測対象は時間経過に共なって変化していく [1] ため、固定の値で動作確認をしつづけるのはやや不安です。
他には予測精度のメトリクス変化を確認する方策も考えられます。しかし予測結果が変わっていない事を確認するために予測対象空間をまんべんなくカバーするラベル付きデータを用意するのは割に合いません。よってシンプルに「多様な入力に対して個々の予測結果が変わっていない事を確認する」仕組みを導入しました。これにより予測結果に影響を与えない変更のリリース可否を迅速に判断できます。
手法
実際のAPIリクエストに基づいてリグレッションテストを行ないます。本番環境における予測対象の分布を保ったままテスト用のデータセットを構築するので、レアケースは抜け落ちますが効率良く出現頻度の高いリクエストをカバーできます。以下に概要を示します。
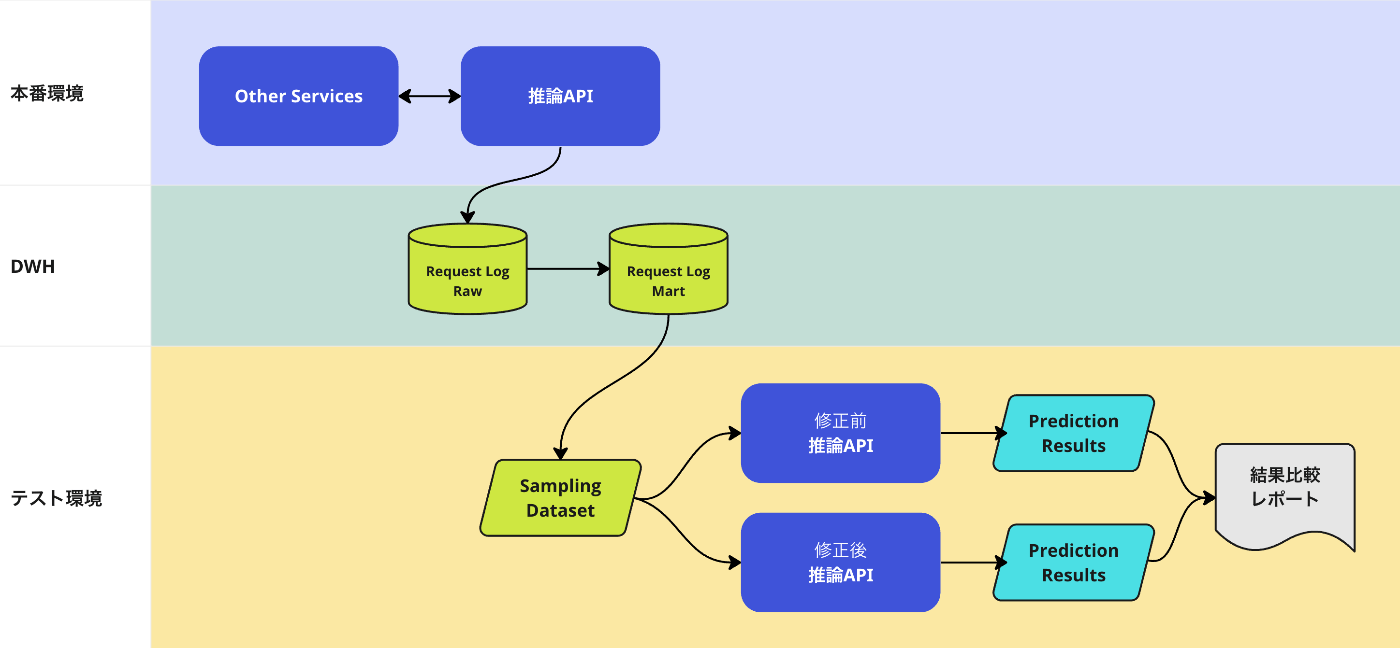
- 直近数日のAPIリクエストから層化サンプリングしてテストデータセットを作成
- 修正前の推論APIで予測を行ない予測結果を保存
- 修正後の推論APIで同様に予測結果を保存
- 予測結果を全件比較
サンプリングデータセットの件数は推論WebAPIのスループットとの兼ね合いで決めます(例:エンドポイント毎に5,000件)。サンプリング方法は層化抽出により偏りを回避。この仕組みの開発と同時に推論WebAPIまで予測モデルとソースコードのrevisionを引き回して、動作時点のソースコードとモデルのバージョンを出力可能にしました。これにより「差が出なかったのは全く同じ構成で動かして比較していたから」というミスにもすぐ気づけます。
まとめ
推論WebAPIの変更を安全にリリースするための仕組みとしてのリグレッションテストを紹介しました。修正内容によっては小数点以下の僅かな誤差が現われる時もあるので、致命的なケースで誤りをしないかのテストや予測精度のメトリクスと組みあわせてリリース可否の判断をしています。
採用情報
医療ドメインにチャレンジしたい方、メンバー募集中です
-
ドメインシフト(domain shift)として知られる問題。ヘルスケア領域であれば感染症の流行や医療政策の変更などの影響を受ける。 ↩︎

Discussion