SQLite を使ってマスターデータの環境間 id 差異をなくした
こんにちは、 Ubie で バックエンドエンジニア をしている @__Attsun__ です。
しばらくデータエンジニアとして分析基盤構築などをしていましたが、最近はマスターデータ管理を中心に、バックエンドエンジニアとデータエンジニアの狭間のような仕事をしています。
今回は、マスターデータの id 管理の負債について、久しぶりに SQLite を使って解消したお話です。泥臭いやつです。
本記事は Ubie Tech Advent Calendar 2025 12日目の記事となります。
Ubie でのマスターデータ管理
Ubie の事業は医療ドメインに属しているため、多くの医学関連知識をマスターデータとして管理しています。疾患、症状、アレルギー、検査などなど・・。
Ubie でのマスターデータ管理の歴史は非常に長く、創業(2017年)とほぼ同時くらいにマスターデータの扱いも始まり、その後も徐々に拡張し続けています。その中で、時間の経過や事業の変化やガバナンスの変化など多くの要因により負債も溜まりつつあります。
管理方法
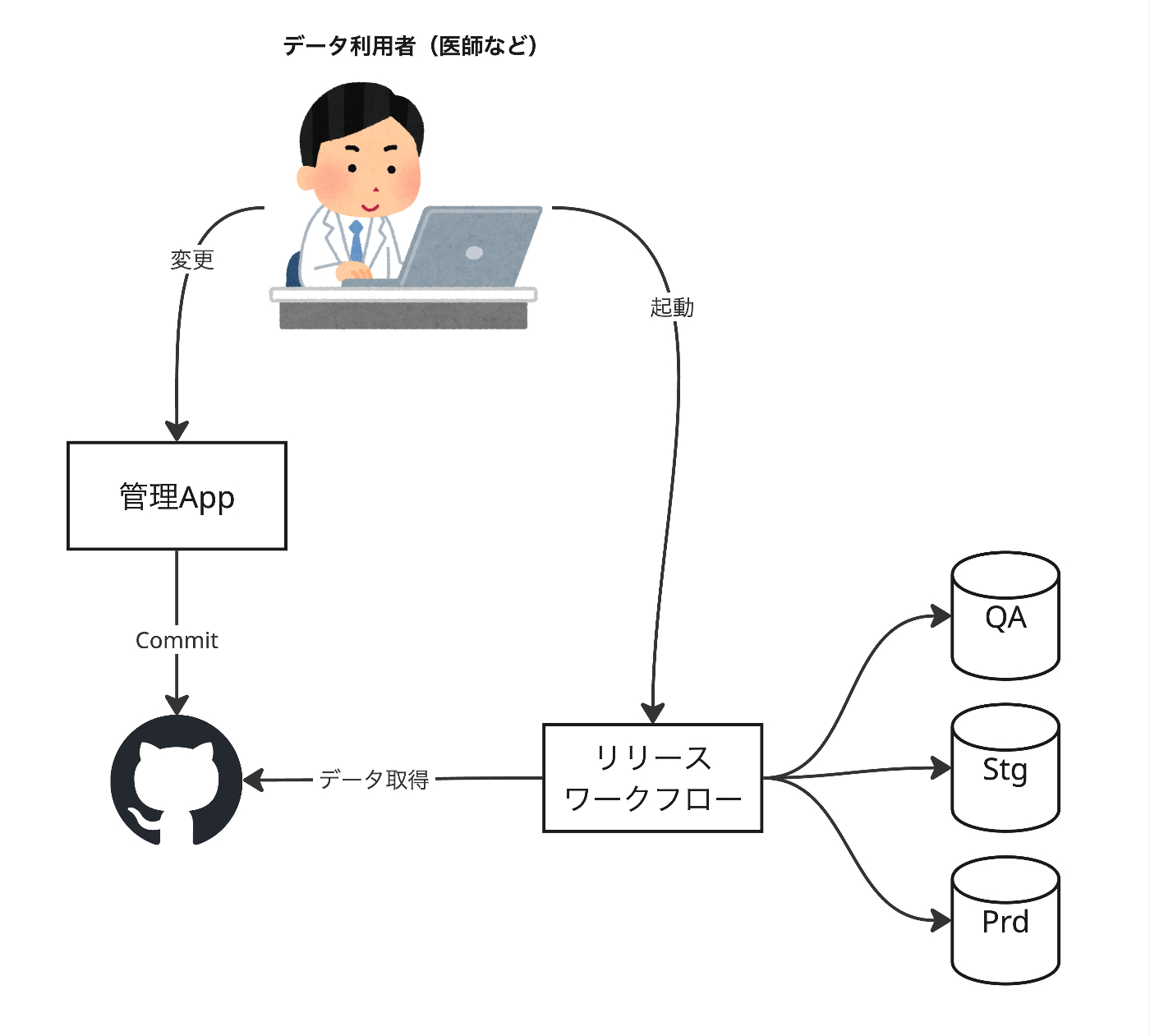
データが GitHub でバージョン管理されており、管理画面を通して変更を積んでいく方式です。リリース時に専用のワークフローによりデータだけがリリースされます。リリースは、QA環境、ステージング環境、本番環境の DB (AlloyDB for PostgreSQL) に対してそれぞれ行われます。
データは、マスターデータを GraphQL としてサーブする API サービスに投入されます。
(このあたりも課題がたくさんある/あったんですが、また別の話・・)
マスターデータの id と長年にわたる問題
マスターデータには二種類の id が存在しています。
- uuid
- データ生成時に付与されるユニークな id です
- シーケンシャル id (以降
sid)- データがリリースされ DB にインサートされるときに、AUTO INCREMENT により採番される数値の id です
先に存在していたのは sid です。しかし、sid には下記の問題があるので uuid があとから導入されました。
sid の問題
「環境間で id がズレる可能性がある」という目を覆いたくなるような問題があります。
QA、ステージング、本番環境にそれぞれリリースをするのですが、当然それぞれに別の DB があります。 sid は AUTO INCREMENT を使って採番されているので、インポート順序がズレたり切り戻しなどが発生したりすると、容易にズレてしまいます。
マスターデータは至るところで利用されています。データはもちろん、ハードコードされたものや、人間や AI との会話の中でも。そのため、 id がズレていると様々な考慮をしながら慎重に扱う必要がでてきてしまいます。
uuid はデータが生成されるタイミングで生成されるので、ズレる可能性はありません。
sid の存在意義
この負債の話を聞いたとき、じゃあ uuid だけでええやん!と思ったんですが、そうもいきませんでした。現実は厳しい。理由は2つあります。
理由1: sid は人間にとって認知しやすく、コミュニケーションの基盤となっている
「疾患」を例にあげると、似ている名前の疾患が実はたくさんあります。例えば「肺癌」と一口に言っても多くの分類があります。
- 中葉肺癌
- 非小細胞肺癌
- 原発性肺癌
これは抜粋です。疾患の国際的な体系である ICD10 に対応した標準病名マスターでは、「気管支及び肺の悪性新生物」という分類で54個の疾患が登録されています。
このため、名前を口頭でやりとりしていると齟齬のリスクがあります。一方、数字が決まっている sid であれば、齟齬が発生しづらいです。社内では、sid と名前の組み合わせでコミュニケーションが取られることが多いです。
uuid も一意に特定することができますが、人間が記憶するのも、発声するのも、記載するのも現実的ではありません。
理由2: へばりつきすぎた負債
sid は上記の取り回しの良さや uuid が無い頃の名残から、コードやドキュメントやデータに深く刻まれてしまっています。
特にデータは厄介で、過去ログのアップデートは現実的ではないため、 sid はある意味一生残り続けることがほぼ確定している状態です。
このような存在意義や負債があるため、ただ消すシンプルな方法は取れませんでした。
解決の方向性
これらの問題を踏まえて、以下条件を満たせる解決の方向性を探りました。
- 影響範囲を限定的にするため、本番環境の既存の
sidは維持する - 各環境の
sidが結果的には整合する状態にする - 今後のデータでは
sidのズレが根本的には起きない仕組みにする
SQLite を使った、 sid 事前採番の仕組みを導入
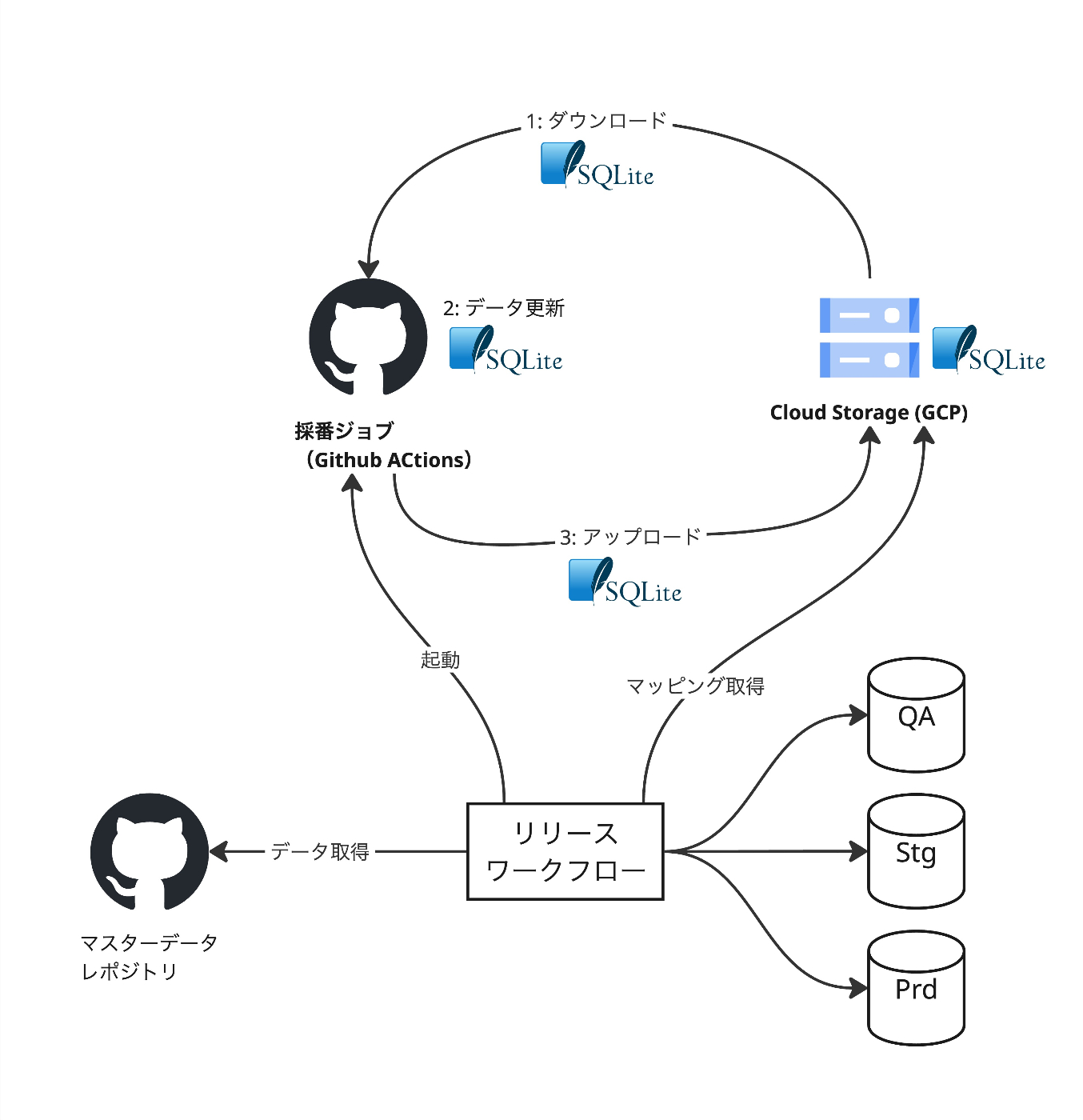
SQLite に uuid と sid のマッピングを持ち、事前に sid を採番する「採番ジョブ」を実装し、リリース時に起動して更新するようにしました。
ポイント1: SQLite による sid 採番
sid は uuid のように一意な id をサクッと生成することができないので工夫が入ります。
そこで、 SQLite を使って AUTO INCREMENT による採番を行うことにしました。 SQLite は PostgreSQL のような通常の RDB と異なり、ファイルシステムさえあれば簡単に動きます。ステートもファイルに保存しておくことができます。
SQLite ファイルを GCS に置いたうえで、 Github Actions でダウンロードし、更新し、アップロードするという仕組みにしました。
AlloyDB などの DB を稼働させるとなると、ランニングコストや接続のためのネットワークや権限の管理などがあり、やりたいことに対して実装と運用の「重さ」を感じます。SQLite により、圧倒的に低コストで手軽に実現することができました。
※ 利用している SQLite のメジャーバージョンは 3 です。
ポイント2: 並行性の制御
この仕組みは単一の Github Actions ジョブしか動かない前提では問題ないのですが、複数の GitHub Actions ジョブが同時に実行されてしまう場合、ファイルを共有しているわけではないため、不整合が生じてしまいます。
- ジョブ A が SQLite データを更新
- ジョブ B が SQLite データを更新
- ジョブ A が GCS にアップロード
- ジョブ B が GCS にアップロード
この場合、ジョブ A の更新が吹き飛んでしまいますね。
実利用上は「リリースは同時に一つしか動かない」という制約を作ってしまっても問題はないので、二種類の方法でこれを担保しました。
(1) GitHub Actions の同時実行制御
これは簡単で、 concurrency の設定で実現できます。
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: false
cancel-in-progress: false により、後で実行されたものは待機するようになります。 true にすると先に実行しているものが中断されます。
sid の採番には GitHub Actions しか使わないので、実用的にはほぼ十分です。ただ、当然ながら GitHub Actions の外ではこの設定は無効なのでやや不安があります。
(2) GCS の Request precondition
GCS には、 Request preconditions という、リソースの適用前にリソースの状態が想定した状態になっているかのチェックを行う仕組みがあります。主に、今回のような race condition を解決する手段として使われることがドキュメントに記載されています。
バケットの設定で Object Versioning を有効にするとバージョンが振られるようになるので、このバージョンを使って、「アップロードするときに、ダウンロードしたときのバージョンと一致しない場合はエラーとする」という挙動が実現できます。
# 1. 現在のオブジェクトバージョンを取得
latest_version="$(gcloud storage objects describe "${sqlite_path}" --format="get(generation)")"
# 2. バージョン指定でダウンロード
gcloud storage cp "${sqlite_path}#${latest_version}" "${local_sqlite_path}"
# 3. SQLite のデータを操作
sqlite3 "${local_sqlite_path}" "INSERT INTO ..."
# 4. 整合性をチェックしつつアップロード
gcloud storage cp --if-generation-match="${latest_version}" "${local_sqlite_path}" "${sqlite_path}"
アップロード時の --if-generation-match がポイントです。今の GCS にあるファイルのバージョンが一致しない場合、以下のようなエラーが発生します。
ERROR: HTTPError 412: At least one of the pre-conditions you specified did not hold.
これで、万が一競合状態が発生した場合でも安全になりました。
導入後
この仕組みを導入して1ヶ月ほど経ちましたが、特に問題なく動いてくれています。SQLite は調査やテストが非常に簡単な点も優れていますね。
念には念をということで、 dbt を使った sid ズレの監視も行っています。
おわりに
SQLite を使った泥臭い事例の紹介でした。SQLite のようなライトウェイトなツールはやれることが限られている分、ユースケースがハマるとかなり有用な選択肢となりますので、頭の片隅に置いておくと助かることもあるかもしれません。

Discussion