概要
YANSシンポジウムで最近の取り組みの1つをポスター発表してきました。YANSシンポジウムは言語処理学会の若手支援事業の1つで、自然言語処理の周辺分野に参加して間も無い研究者の発表を奨励している研究シンポジウムです。NLPに取り組んでいる研究者の方々と議論することができ、様々な知見が得られました。
発表タイトル・著者
[S3-P15] 大規模言語モデルによって医療テキストの固有表現処理はどこまで簡単になったか
西林 孝 (Ubie), 横井 祥 (東北大/理研)
背景
LLMの性能向上により様々な自然言語処理タスクに手軽に取り組めるようになりました。ただNLPの経験ゼロの状態でLLMの波に飲み込まれた私の様なエンジニアはLLM登場以前の手法の肌感が無く、LLMだとそれなりに動かせるが本当にLLMに全てを任せれば良いのか判断がつきません。そこで最近取り組んでいたメディカルエンティティリンキング(Medical Entity Linking)のタスクをポスターにまとめて識者のコメントを頂戴しに参加しました。具体的には病歴テキストに含まれる症状・既往歴・生活習慣を抽出し自社の医学知識ベース上のエンティティに紐付けるタスクです。これをLLMとBERTベースの手法で比較実験をしました。
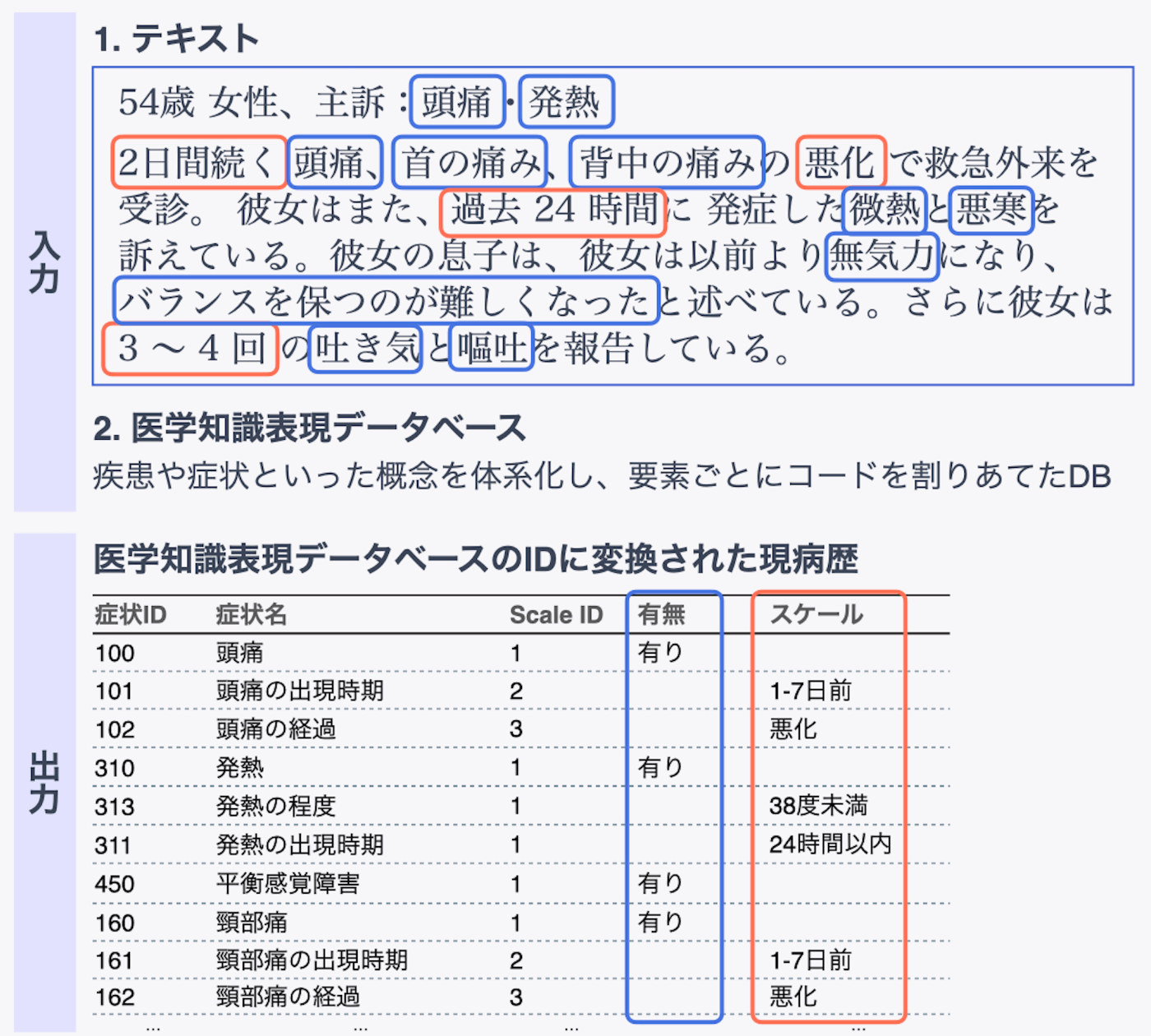
病歴テキストから症状を抽出してデータベース上のエンティティに紐つける例
幸いにして発表当日は写真を取る時間も無い程に質問意見を頂けました。
議論
1〜2単語の簡単なエンティティの抽出とLinkingはBERTベースで十分な性能が出せそうで、LUKEなどの既存の高性能なモデルを教えていただきました。関係抽出はスタンダードと言える既存手法はないがT5などのモデルがベースラインになりそうなこと。ただしBERTモデルファインチューニングのための訓練データは数百から数千のオーダーで必要そうで、独自の知識ベースが対象になる場合、つまり学習済みモデルが世に無いときはLLMがファーストラインで良さそうです。実際に固有表現抽出、関係抽出、エンティティリンキングと3つの処理の学習データを準備し訓練・推論処理を実装したらそれだけで週末が溶けたので、まずはLLMにすべてを任せてから問題を分割してBERTが得意な部分は切り出すといった方針が良さそうです。実験に使ったLLMのGemini 1.5 Proではfew-shotで20程度の例示を与えれば実用的な性能になったので準備に1日もかかりません。
一方で「寒さに晒されると手の色が青くなりその後白から赤くなる」といった説明文から症状を連想する[1]のは既存の類似タスクが無いのでデータセットを作って医療NLPの研究者を巻き込む余地がありそうでした。頭痛の説明文の後に「コーヒーを飲む前に悪化する」から「匂いによる頭痛の誘引」を引き当てるのはやはりLLMでないと難しいだろうという議論もできました。
おわりに
普段の取り組みを言語化して発表し、フィードバックを得ることで見えていなかった部分が明らかになりました。どの部分に取り組めば性能向上リターンが大きいか、外部の研究者を巻きこんで進めると早いテーマは何か。また他の方の発表も良い刺激になりました。業務の合間にポスターを作るぐらいなら何とかなるので、別のテーマでまた発表したいと思います。
ポスター


Discussion