こんにちは。Ubieでアナリティクスエンジニアをやってますおきゆきです。自己紹介ページはこちらです。
この記事は Ubie Engineering Advent Calendar 2023 の11日目の記事です。
Ubieは「テクノロジーで人々を適切な医療に案内する」をミッションにしたヘルステックスタートアップで、AIやデータをコア価値とした事業を展開しています。この記事ではそんなUbieで行っているデータ信頼性の取り組みについて紹介します。データ信頼性は新しい概念なこともあり、我々も日々手探りで進めている中での事例を紹介できればと思います。
Ubieはなぜデータ信頼性を重視しているのか?
データ品質・データ信頼性というワードは「大事そう!だけど、リターンってなに?どれくらいやるべきなの?データエンジニアだけがやること?」のような問いがいつも出てくるかなと思います。いわゆるROIを証明することも難しく、データ信頼性に取り組むこと自体が難しいかもしれません。
そんな中、事業上の特性もあってUbieではデータ信頼性を以下大きく3つの観点から非常に重視しています。
Data is Product
Ubieは明確にデータをコアとした事業を展開しており、データ無くして我々の事業は成り立ちません。日々蓄積されたデータを社内向け・社外向けに分析・利活用しており、Nが非常に少ない珍しい病気を対象とすることもあります。また、患者の時系列情報を適切につなぎあわせ、解像度高く患者を理解し、患者を適切な医療に案内することが我々のミッションです。すでにそのような事例がどんどん出てきています。

上記のとおり、データをつなぎ合わせることができなかったり、誤ったつなぎ合わせをしてしまうと、当然ながら誤った解釈を引き起こし様々なリスクに繋がります。解像度高く患者の状態を理解できるUbieが保有するデータこそがプロダクトであり、データ信頼性なくしてUbieの事業は成り立ちません。
データ負債のインパクトは想像以上に大きい
技術的負債という言葉もあるように、データ負債という言葉もあります。以下の記事では、データの管理・活用が適切に行われていないことにより、「負の遺産」として重く伸し掛かってくることを解説しています。信頼性の低いデータが蓄積されていくと、利活用時の機会損失や将来的なコストも増大します。
また、以下の記事では、データ負債を解消する工数は読みづらく、安定しないことを紹介していました。データが参照されている数によって解消にかかる時間が大きく変わること、ユーザーへのコミュニケーションのリードタイムがかかること、またデータ負債は大きくなるスピードが早い(日々データが蓄積されていくため)ことがわかり、技術的負債同様にデータの負債解消は早期対処が特に必要です。
アナリティクスエンジニア視点でも、新旧でログやデータのマイグレーションを行うときは利活用者へのケア、マート内での新旧ログをどう吸収していくかの設計と実装は、結構エネルギーを使うと感じているため、Qごとに計画的に実行していくことが重要と感じます。
また、昔からから取得したデータは未来永劫利活用していきたいし、捨てたり、新しく作り直すことはしたくない・できないことが多いです。その点で、データは取得したら一生管理・運用していく気持ちが必要であり、データを取得すればするほど、基本的に運用コストは増え続けます。
データ利活用時の価値を掴み損ねる
DMBOK2第1章に記載されているデータライフサイクルを参考にいうと、長い工程(人的リソースを含むインベスト)を経て、データ利活用フェーズでやっとデータは価値を生みます。しかし、そのタイミングで「あれ、なんかデータおかしそう?このデータは使えない...」 となることは、長い工程に投下した人的リソースの無駄遣いになりかねません。
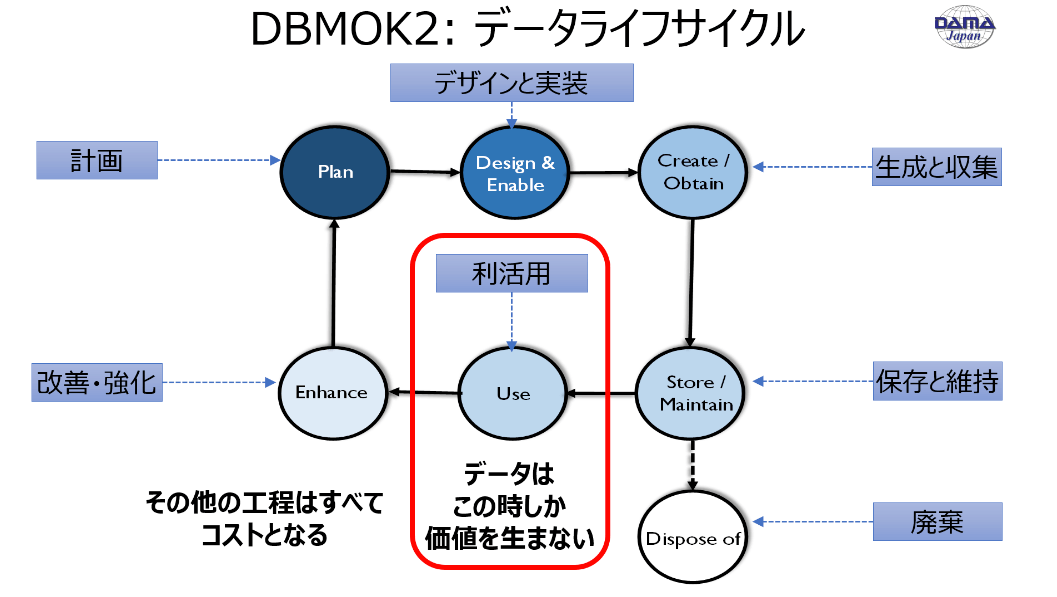
Ubieの事例で言いますと、武田薬品工業株式会社と連携している遺伝性血管性浮腫という希少疾患では、発症から治療開始まで平均13.8年かかると言われています。信頼性の高いデータを最初から取得できていないと、長い年月を投資したにも関わらず、誤ったデータが蓄積され続けていたことになりかねません。
Ubieではデータ信頼性を4つに分類している
上記のように様々な観点でデータ信頼性の重要性が認識できたあと、続いてデータ信頼性を向上させるためにはどのように手をつけていくべきでしょうか?「データエンジニアやアナリティクスエンジニアだけが行うものなのか?」「データウェアハウスやデータマート内だけで対応すればいいのか?」など問われることがありますが、UbieではいずれもNoと考えています。
データの発生から利用までのプロセス、つまり 「データの入力 ~ 蓄積 ~ データマート化 ~ 利活用」における全プロセスで関係すべきと考えています。アナリティクスエンジニアの代表的な守備範囲としてデータマート化の部分での工夫はよく取り上げられますが、そこのプロセスだけを考えていてもこれからさらに多様なデータを取得・蓄積していくUbieにとっては全くスケールせず、アナリティクスエンジニアのデータマート整備工数が爆発・利用者の利用時の認知負荷が爆発します。
そのためUbieでは、データ信頼性を向上させるために以下4つに分類して、データのプロセスに渡ってそれぞれの信頼性を定義しています。

①入力データ信頼性
入力データ信頼性が高いと、生活者(患者)が正しいデータを入力してくれる確率が高まります。これは患者以外にもその他医療従事者を含む様々なソースから手に入るデータも同様です。信頼性を高めるには、正しいデータを入力したくなるユーザ体験・ユーザインタフェースが必要です。この信頼性が毀損していると、期待したデータが入力されない・間違ったデータが入力されることになり、下流の信頼性も同時に毀損されます。
②データ自体の信頼性
データ自体の信頼性が高いと、真となる情報と実際に保存されるデータの一致度が高まります。信頼性を高めるには、ロギング実装の精度/開発チームのデータ監視や早期検知/ログ開発の標準化などが必要になります。この信頼性が毀損していると、違うデータが入る・重複して入る・欠損して入るなどが起こってしまい、下流のデータマート内で異常を弾くようなロジックの実装を積み重ねる必要がでてきます。これはデータ負債に繋がります。
③データマート・ダッシュボードの信頼性
データマート・ダッシュボードの信頼性が高いと、データ利活用者が正しく・早く・安全にデータを使える確率が高まります。ここは典型的なアナリティクスエンジニアの仕事として、データパイプライン・データマート・データテストの実装等が必要になります。この信頼性が毀損していると、間違ったデータを集計してしまう可能性が高まります。
④利活用・レポーティングの信頼性
最後に、実際の利活用・レポーティングの信頼性です。この信頼性が高いと、正しい意思決定ができる確率が高まります。この信頼性が毀損していると、逆に誤った意思決定してしまうリスクが高まります。③と類似する部分もありますが、Ubieは病気のデータを扱うからこそ、医療ドメイン観点で不自然なものだったり、解釈が難しいものをバリデーションすることが必要になる場面があります。
データ信頼性向上の取り組み
ここ最近は②データ自体の信頼性向上に力を入れているので、これに関する部分について今日は紹介したいと思います。
まずはじめに、先ほど紹介したThe True Cost of Data Debtの記事にとても興味深い図があり、とても参考になりました。
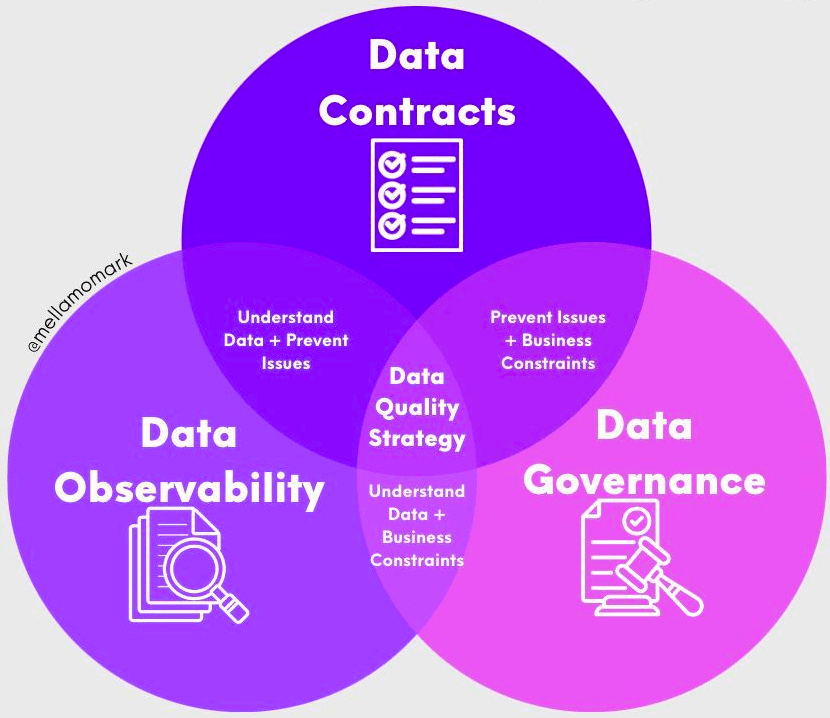
データガバナンス / データコントラクト / データオブザーバビリティの3要素の中央にデータ品質戦略が位置しており、まさにUbieでもこの3つに近い形でデータ信頼性を向上する取り組みを行っていたので、この図をそのまま引用させてもらいます。
データガバナンスの整備とデータオーナーシップの醸成
先ほど説明したとおり、データ信頼性はデータに関わる全てのプロセスで必要なため、組織として重要性を認識し、浸透させていく必要があります。Ubieの課題感としては、データガバナンスが効いておらず、データの所在は把握できるが、オーナーが不明瞭だったり、オーナーが決まっていたとしてもどんな役割を果たすべきなのかが曖昧でした。そのためデータの異常が起こっても、データ基盤チームがケアしてる部分が多い状態でした。
そこで、データ信頼性の重要性を組織に発信し、データオーナーシップの定義および役割についてドキュメントにまとめました。そこから、各チームが管理すべきデータを丁寧に洗い出し、データオーナーのグループ定義や特定を進めていきました。これにより、データオーナーをdbt model上で表現し、データオーナーごとにどのようなdbt modelを保有しているかを明確にしていきました。現在はdbt testの実装浸透やdbt testのエラーを直接データオーナーに紐づくチームが対処するなどの移譲を進めています。
一方、各チームでデータ信頼性を向上させるためのcanが不足していることもあるため、イネイブラーとしてチームに入りこむことも必要です。ペアワークを行ったり、ヒアリングを行うなどしてチームとしてのcan向上にも関心を持って進めています。
ログ開発ドキュメントや信頼性チェックリストの装着
先ほどの図でいうとデータコントラクトにあたる部分です。Ubieではまだデータコントラクトというほど、ガチガチのテンプレート運用はしていませんが、まずログ開発における方針をドキュメント化しました。たとえば、高い品質が求められるデータはこの方式で取得する・データ利用者と事前にアラインメントを行うなどの基本的なログ開発ガイドです。
新しいデータを取得するようなシステム開発を伴うときは、社内ではテンプレートに沿ってTechレビュー行いますが、その際にデータ信頼性をチェックリストをテンプレートに装着しています。たとえば、「データの保存の失敗に気付けるようになっている」「チーム外から見て構造が分かるスキーマで定義されている」などの満たすべき要件を整理しています。
データオブザーバビリティの整備
UbieではdbtとLightdashを中心としたデータ分析基盤を構築しており、それを中心とした運用開発可能な仕組みを進化させています。Lightdash導入背景は以下で紹介しています。
直近ではdbt elementaryを導入し、データ件数チェックの実装やLightdashによる品質の高いダッシュボードの整理を進めています。これらを各チームが運用監視できるように整備を進めています。
データオブザーバビリティにも関係する③データマート・ダッシュボードの信頼性を向上する取り組みについては、データ基盤管理の考え方で話しましたので以下ご参考ください。
共にデータ信頼性に向き合うメンバーを募集しています
この記事では、「Ubieはなぜデータ信頼性を重視しているのか?」について以下3点ででまとめました。
- Data is Product
- データ負債のインパクトは想像以上に大きい
- データ利活用時の価値を掴み損ねる
また、Ubieではデータ信頼性を4つに分類し、とくにデータ自体の信頼性をあげていくために、以下3点について今取り組んでいます。
- データガバナンスの整備とデータオーナーシップの醸成・イネーブルメント
- ログ開発ドキュメントや信頼性チェックリストの装着
- データオブザーバビリティの整備
理想的な姿への道のりはまだまだ先ですが、引き続きUbieではこれらのデータ信頼性の向上・浸透を進めるアナリティクスエンジニアやデータエンジニアの採用をOpenしています。また、その他エンジニア系職種も広く募集しているので、少しでも興味を持ちましたら直接応募していただいてもかまいませんし、一度カジュアルにお話したい方は私までX(Twitter) DMお待ちしております!
また、明日の Ubie Engineering Advent Calendar 2023では Isseiさんがお話してくれますのでお楽しみに!

Discussion