こんにちはUbie Discoveryに入って早5ヶ月目の @shikajiro です。(月日は早いな。。。)医療業界は何もわからない状態でしたが、最近はちょっとずつドメイン知識や組織周りも見えるようになり、がむしゃらに働いてます。プロダクト開発以外にも前職で培ったGCPやkubernetesの経験を活かし、開発環境のインフラ周りの整備なんかもやってます。
僕のいるスクラムチームには医師も参加していますが、エンジニアリングには不慣れな部分もあり、インフラ面の都合などで開発や検証に困る場面がありました。積極的に助力していく中で、「マイクロサービスを簡単に試せる開発環境が無い」のが大きな問題であると分かってきました。Ubie Discoveryでは以前から dev-n環境 というものがあり、それを再構築することでその問題を解決したのでご紹介します。
またこの内容はdevchat.fm • A podcast on AnchorというUbieのpodcastでも配信してますので、一緒にお楽しみください。
※この記事ではわかりやすくマイクロサービスと表現してますが、Kubernetesに構築したサービス群の事を指してます。
dev-nとは
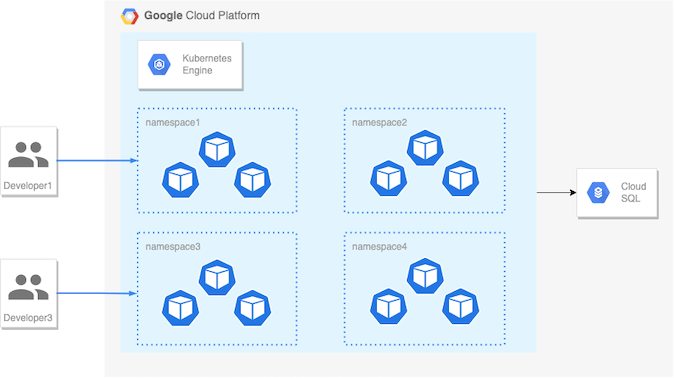
Ubie社内で呼んでいるdev-nとは「クラウド上にあるn個のマイクロサービスの開発環境」のことです。もっと砕けて言うと 「クラウド上のKubernetesに作ったサービスをポンポン構築したいんじゃ〜」 です。弊社ではクラウドにGCPを採用しており、development, qa, staging, production、4つのGCPプロジェクトを作って開発・検証・本番提供を行い、GKEクラスターに各サービスをデプロイしています。 このdevelopment環境のGKEクラスター内に自由にサービスを立てて開発メンバーの開発効率を向上するのがdev-nという仕組みです。
以前から単独サービスをGKE上に構築する仕組みは合ったのですが、Ubieで開発している沢山あるマイクロサービスの一部をまとめて構築できるようにしました。
開発時の問題点
dev-nが出来上がる前には次のような問題がありました。
医師の開発環境準備が大変
Ubieはみんな大好きマイクロサービスで開発しています。エンジニアは主にlocalでバリバリとコード書いて動作検証して開発を進めてるのですが、医師は「マスターデータ」と呼ばれるUbieの根幹部分の開発をしており、それはマイクロサービスを統合して動作確認する必要があります。
以前は医師の方もlocalにdocker-composeなどを使って開発環境を構築していたのですが、どうしても構築が難しく時間がかかったり、トラブルシューティングのときにエンジニアが医師のlocal環境に触れないため解決できないなど、医師の開発の悩みでした。
マイクロサービスを組み合わせた開発・検証環境が足りない
開発者はlocalでマイクロサービスを構築して動作させていると書きましたが、色々サービスを立ち上げるとどんどんマシンが重くなり開発効率が下がっていきます。また、local環境だと開発途中のものをチームメンバーに見せたり触ってもらうことができません。なんだかんだでエンジニアもマイクロサービス全部動かした状態の環境がほしいのです。development環境は1つしかないので利用行列待ちなり、気軽に使えません。
PR段階のマイクロサービスを組み合わせた検証環境がない
複数にまたがるサービスを同時に開発していく場合、PR時点でのコードをデプロイして検証したいときがあります。development環境はdevelopブランチにmergeされたタイミングでデプロイしているので使えません。
development環境をたくさん作ると費用がかかる
GCPのdevelopmentプロジェクトをたくさん作れば解決だ。と一瞬考えましたが、GKEクラスターだけならまだしも、GCPプロジェクト上にはredisなどそれなりにコストが掛かるサービスを利用しているため、GCP環境をたくさん作ると費用がとんでもないことになってしまいます。
dev-nの仕組み
上記の問題を解決したdev-nの仕組みは 「development環境で動いているGKEクラスターをnamespaceで区切り、開発・検証に必要なImageをまとめてデプロイするk8sファイル群とその自動化」 です。dev-nリポジトリを作り、その中で管理しています。
(上記と同じ画像)
development環境の資源を共有するGKEクラスター
前述したように、development環境と同等の環境を作ると費用がかかります。ので、development環境のリソースを間借りすることにしました。redisやDBインスタンスなどはみんなで共有します。GKEクラスターの中に dev-shikajiro のようにnamespaceで区切って雑に領域を分け、そこに検証したいImageをデプロイします。
こうすることで最小限の費用(GCEインスタンス代)でクラウド上に開発環境を準備することができました。
kustomizeでdev-n環境ごとにカスタマイズする
k8sのDeploymentやService、ConfigMapはkustomizeで管理しています。namespace毎にディレクトリを作り、環境変数やimageのtagなどを個別に管理しています。

shellscriptである程度構築は自動化
上記のnamespace毎のディレクトリやkustomize.yamlを作成する処理はShellSctiptで作成できるようになっています。kustomize.yamlのImageTagなどは放置していると陳腐化してしまいますが、これもGCPのAPIを叩いて最新を取得するShellSctiptを作っているので簡単に更新できます。
PRにコメントするとデプロイできる
各サービスのリポジトリに コメントするとdev-nにデプロイできるGithubAction を仕込んでいます。
/deploy shikajiro
とPRにコメントするとPR時点でのDockerBuild, GCRへのPush、dev-nリポジトリにあるコードの変更とPR、そのマージを行い、最終的にdev-shikajiroのImageTag反映までやります。

ArgoCDで自動構築
dev-nリポジトリのコードをGKEに反映させる役割はArgoCDが監視・実行しています。開発者はクラスターへのデプロイを意識せずGithubのコードだけに集中できます。 ここはSREの @kamina_zzz がぱぱっと作ってくれました!
今後の展望
telepresenceを使って直接開発する
dev-nはあくまで検証環境であり、開発環境としては使えません。しかし、telepresenceを使えばクラウド上のk8sクラスターにdeployされたマイクロサービスを直接開発が可能になります。
メルカリさんは早くからこの仕組を導入しており参考になるのでぜひご覧ください。 マイクロサービスのTelepresenceを使ったローカル開発環境の話 | メルカリエンジニアリング
圧倒的自動化!リリース単位毎に自動で構築、リリースしたら自動で削除
今はまだDBの初期化や環境の新規作成などはエンジニアが手動で管理しています。ゆくゆくはコマンド一発で全て構築され、更新作業も自動化してエンジニアが介在しなくても運用できるようにしたいと思っています。
まとめ
簡単に環境が作れる仕組みは圧倒的開発速度を生む
dev-nの仕組みは本当に作ってよかったです。医師の方の開発体験は改善され、皆さん喜んで貰っています(要出典)。今までは医師が作ったデータを元にエンジニアがlocalで動作検証したりする手間がありましたが、今では医師だけで完結するようになりました。
意外だったのはエンジニアにも好評だったことで、「面白い機能追加したから皆に触ってもらって意見を聞こう」がPR段階で気軽にできるようになったことです。「作って試す」がとても容易になりました。
まだ自動化が不完全だったり、開発環境として使うには貧弱な部分がありますが、これからも改善を続けていきます。
一人で作ってても形ができるとみんなが集まってさらに改善していく
当初は一人で空いた時間(そんなものはない)にコツコツと作っていたのですが、ある程度できてやりたいことや動きを皆に見せれると「よし!自動化はまかせろ!」「あ、僕もサービス追加したいから協力するね」と沢山の人が集まってきて改善が一気に進みました。理想形をいろいろ考えて「あったらいいね〜」と語るよりも、作って出して触ってもらうのが大事ですね。

おいでよ

Discussion