AI動画解析サービスを試してみる
AmazonのAmazon Rekognition VideoとGoogleのVideo AI(Video Intelligence API)の解析を使用してみて、それぞれどのような結果が得られるのか確認したいと思います。
今回は1回目ということでAmazon Rekognitionを使うまでの設定とPythonスクリプトを使用した解析を実行して結果をJSONで取得してみます。
Amazon Rekognitionとは?
詳しくは公式Webサイト見ていただくのが一番ですが、簡単に言えばAWSのS3に保存してある画像や動画に対して顔検出、テキスト検出、ラベル検出などの解析が行えるサービスです。
検出について細かいカスタマイズはできませんが、手元に解析するハード・ソフト含めた環境や知識がない場合でも手軽にAI動画解析を試すことができます。
アカウント設定の手順について
基本的には下記のURLの手順に沿って進めれば準備が完了しますが、Pythonのスクリプトで解析の実行と結果の取得をしたいのでPython用のSDKが動くところまでの設定をします。
SDKを使用する場合は下記ページのステップ3~8は必要ありません。
また、以下の説明は下記ページのステップの数字に合わせています。
アカウント設定の参考ページ:
1. アカウント作成
-
ユーザーページ から「ユーザーの作成」クリック

-
次のページで 「ユーザー名」を入力し「次へ」
今回は「ai-test」というユーザー名で進めます

-
許可のオプションについて
許可についてはステップ3で設定します。
ここではそのまま進めて「次へ」をクリックします。

-
確認画面
「ユーザーを作成」をクリックで作成完了です。

2. SDKから使用するアクセスキーの設定
-
ユーザーの設定を表示
ユーザーページでユーザー名の「ai-test」をクリックしユーザーのごと設定ページを開きます

-
アクセスキーの作成の開始
「アクセスキー 1」(末尾の数字は作成したキーの数により変動) の下にある「アクセスキーを作成」をクリックして 「アクセスキーの設定」を表示します

-
アクセスキーの作成
「ユースケース」で「ローカルコード」を選択し、画面下部にチェックボックスにチェックを入れ「次へ」をクリック

必要な場合に説明を入れ「アクセスキーを作成」で作成完了します

-
シークレットキーの保存
この画面でシークレットキーを保存する最後のタイミングなので「.csvファイルをダウンロード」でcsvファイルを忘れずにダウンロードしてください
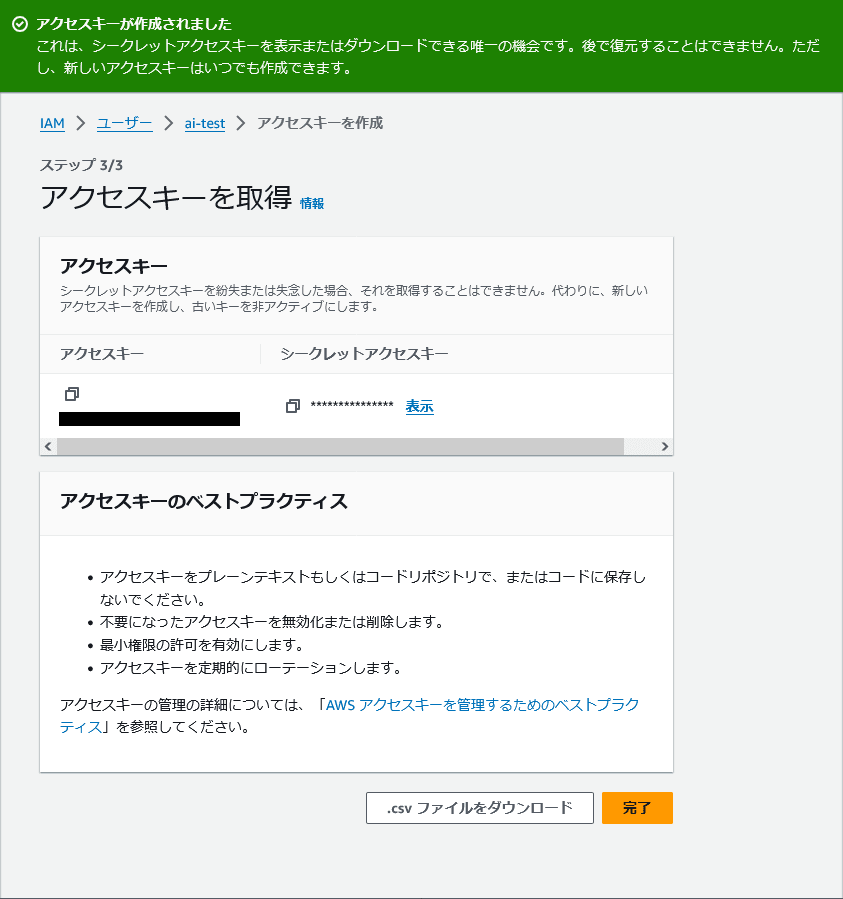
もし、シークレットキーを保存し忘れた場合は今回作成したアクセスキーを削除し、再度作り直してcsvファイルのダウンロードを忘れずに行ってください。 -
シークレットキーの設定
各プラットフォームのユーザーのホームディレクトリ直下の「.aws」というディレクトリの「credentials」というファイル名に下記の所定のフォーマットでファイルを作成してください- Linux の場合
~/.aws/credentials - Windows の場合
%HOMEPATH%\.aws\credentials - フォーマット
[default] aws_access_key_id = アクセスキー aws_secret_access_key = シークレットキー[default]はprofile名でSDKやCLIなどでprofileを指定する際に使用する名前です。defaultは名前の通りデフォルトで使用されるprofile名となります
- Linux の場合
3. ユーザーに許可ポリシーの追加
-
ユーザーページでユーザー名の「ai-test」をクリックしユーザーのごと設定ページを開きます。

-
「許可の追加」をクリックし、更に「許可の追加」をクリック
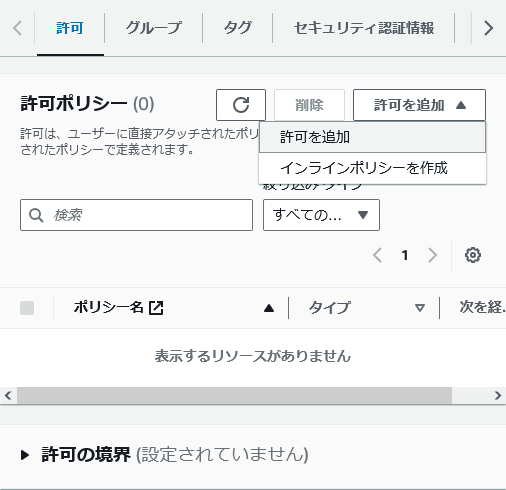
-
「許可のオプション」から「ポリシーを直接アタッチする」を選択。
検索欄が出てくるので下記を許可ポリシー検索し、それぞれチェックをして最後に画面下部の「次へ」をクリック- AmazonRekognitionFullAccess
- AmazonSNSFullAccess
- AmazonSQSFullAccess
- AmazonS3FullAccess

-
次に確認画面が出るので「許可を追加」をクリックして完了

4. Amazon SNS の設定
SDKを使用する場合は必要ないのでスキップ
5. Amazon SQS の設定
SDKを使用する場合は必要ないのでスキップ
6. SNSトピックのサブスクライブ
SDKを使用する場合は必要ないのでスキップ
7. SNSトピックからSQSへメッセージを送る許可設定
SDKを使用する場合は必要ないのでスキップ
8. Amazon Rekognitionにアクセスするロールを作成
-
ロールページから「ロールを作成」をクリック

-
「信頼されたエンティティタイプ」で「AWS のサービス」を選択

-
「ユースケース」から「Rekognition」を検索し選択し「次へ」

-
「許可を追加」のページで、そのまま「次へ」をクリック

-
「ロールの詳細」で「ロール名」を指定します
今回は「ai-demo-role」としました。
このロールのARNをステップ9,10と、後ほどのSDKを使用したスクリプトで使用します

-
画面下部の「ロールを作成」をクリックして完了

9. 上記ロールの信頼関係を編集
-
ロールページからステップ8で作成した「ai-test-role」をクリック

-
「信頼関係」タブで下記の様にPincipalとConditionに値を追加
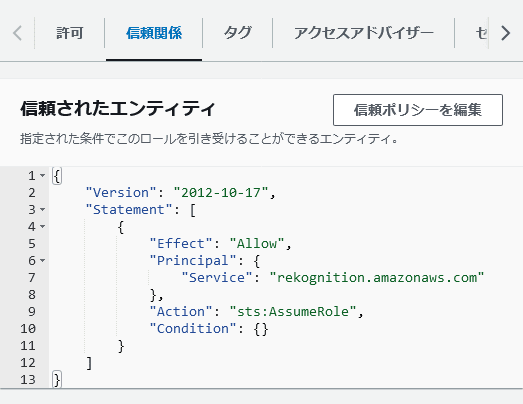
<user-arn> は作成されたユーザーのARNです。ARNは ユーザーページからユーザー名の「ai-test」をクリックしユーザーの詳細ページで確認できます。
<user-number> は、ユーザーのARNにある数値を使用します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "rekognition.amazonaws.com",
"AWS": "<user-arn>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<user-number>"
}
}
}
]
}
10. ユーザーにインラインポリシーの追加
-
ユーザーページでユーザー名の「ai-test」をクリックしユーザーのごと設定ページを開きます

-
「許可」タブの「許可を追加」クリックして、「インラインポリシーを作成」をクリック

-
「ポリシーエディタ」で「JSON」を選択し、下記のように変更します。
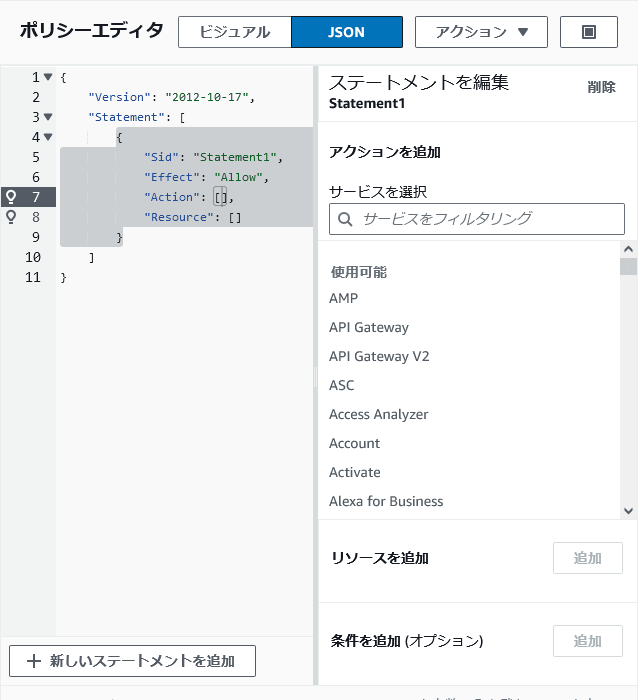
<user-arn>をステップ8で追加したロールのARNを使用します。
ARNの確認方法はステップ9を参照してください
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MySid",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "<user-arn>"
}
]
}
:::note info
アカウント設定の参考ページのJSONの例にはSTEP 7のARNと書いてありますがSTEP 8の間違いだと思われます
:::
11. 暗号化と復号
今回は暗号化/復号の設定は行いません。
12. SDKの準備
-
boto3 のインストール
Python3の実行環境に pip で boto3 をインストールします。
その他、足りないライブラリがあれば pip install をしてください$ pip install boto3
参考: https://boto3.amazonaws.com/v1/documentation/api/latest/guide/quickstart.html
ラベル解析の実行
S3にアップロードした動画ファイルに対して、ラベル解析を行い、その結果をJSONファイルとして保存するPythonスクリプトについて解説します。
S3に動画ファイルのアップロード
事前にAWSのS3に解析を行う動画をアップロードしておきます。
参考: https://aws.amazon.com/jp/s3/getting-started/?nc=sn&loc=6&dn=1
Python スクリプト
ここでは複数ある解析の種類からラベルの検出をして、その結果をJSONとしてファイルに保存します。
Amazon Rekognitionで動画の解析を実行するとJobIdが与えられます。今回は実行結果の出力として表示するだけですが、このJobIdを用いて解析を実行すると、解析実行結果が保存されている間は解析の再実行を行わず、解析結果だけを再取得することもできます。
Amazon Rekognitionの解析結果は、解析結果の項目(今回はラベル)が1000件ごとに分割されます。
その場合、結果のJSONに NextToken という残りの結果を取得するための値が返ってきます。
今回のスクリプトでは下記の参考ページのスクリプトを元に NextToken がある限り繰り返し実行し、NextToken がある場合は1000件ごとに分割したJSONファイルをその都度保存し、最後に残りのデータと、全て結果をデータ構造が壊れないように整形しながらまとめたJSONファイルを保存します。
参考: https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/video-analyzing-with-sqs.html
設定項目
スクリプトファイルの下部にあるmain関数の中に、ユーザーと解析対象の動画ファイルに関する設定項目があります。
-
<profile-name>
デフォルトのままの場合はdefaultと指定してください -
<user-role-arn>
ロールページからステップ8で作成した「ai-test-role」をクリックして表示されるroleのARNを指定してください -
<bucket-name>
動画ファイルを保存しているS3のバケット名を指定してください -
<file-name>
上記バケットに保存している動画ファイル名を指定してください
出力結果 (例)
$ ./run-detection.py
Start JobId: 99dfef36...snip...757d530485
.........
Matching JobId found: 99dfef36...snip...757d530485
-> Status: SUCCEEDED
ai-test.mp4-label-1.json
ai-test.mp4-label-2.json
ai-test.mp4-label-3.json
ai-test.mp4-label-4.json
ai-test.mp4-label-5.json
ai-test.mp4-label-all.json
スクリプト全体
以下、スクリプト全体です。
各APIの細かい仕様については以下のBoto3のリファレンスを参照してください。
Boto3 APIリファレンス:
import boto3
import json
import sys
import time
class VideoDetect:
def __init__(self, role, bucket, video, client, rek, sqs, sns):
self.jobtype = 'label'
self.roleArn = role
self.bucket = bucket
self.video = video
self.client = client
self.rek = rek
self.sqs = sqs
self.sns = sns
def GetSQSMessageSuccess(self):
jobFound = False
succeeded = False
dotLine = 0
while jobFound == False:
sqsResponse = self.sqs.receive_message(
QueueUrl=self.sqsQueueUrl,
MessageAttributeNames=['ALL'],
MaxNumberOfMessages=10,
)
if sqsResponse:
if 'Messages' not in sqsResponse:
if dotLine < 40:
print('.', end='')
dotLine = dotLine + 1
else:
print()
dotLine = 0
sys.stdout.flush()
time.sleep(3)
continue
print()
for message in sqsResponse['Messages']:
notification = json.loads(message['Body'])
rekMessage = json.loads(notification['Message'])
if rekMessage['JobId'] == self.startJobId:
print('Matching JobId found: ' + rekMessage['JobId'])
jobFound = True
if (rekMessage['Status'] == 'SUCCEEDED'):
print('-> Status: ' + rekMessage['Status'])
succeeded = True
self.sqs.delete_message(QueueUrl=self.sqsQueueUrl,
ReceiptHandle=message['ReceiptHandle'])
else:
print("JobId didn't match: " +
str(rekMessage['JobId']) + ' : ' + self.startJobId)
# Delete the unknown message. Consider sending to dead letter queue
self.sqs.delete_message(QueueUrl=self.sqsQueueUrl,
ReceiptHandle=message['ReceiptHandle'])
return succeeded
def CreateTopicandQueue(self):
millis = str(int(round(time.time() * 1000)))
# Create SNS topic
snsTopicName = "AmazonRekognitionExample" + millis
topicResponse = self.sns.create_topic(Name=snsTopicName)
self.snsTopicArn = topicResponse['TopicArn']
# create SQS queue
sqsQueueName = "AmazonRekognitionQueue" + millis
self.sqs.create_queue(QueueName=sqsQueueName)
self.sqsQueueUrl = self.sqs.get_queue_url(QueueName=sqsQueueName)['QueueUrl']
attribs = self.sqs.get_queue_attributes(
QueueUrl=self.sqsQueueUrl,
AttributeNames=['QueueArn']
)['Attributes']
sqsQueueArn = attribs['QueueArn']
# Subscribe SQS queue to SNS topic
self.sns.subscribe(
TopicArn=self.snsTopicArn,
Protocol='sqs',
Endpoint=sqsQueueArn)
# Authorize SNS to write SQS queue
policy = """
{{
"Version":"2012-10-17",
"Statement":[{{
"Sid":"MyPolicy",
"Effect":"Allow",
"Principal" : {{"AWS" : "*"}},
"Action":"SQS:SendMessage",
"Resource": "{}",
"Condition":{{
"ArnEquals":{{
"aws:SourceArn": "{}"
}}}}}}]
}}""".format(sqsQueueArn, self.snsTopicArn)
response = self.sqs.set_queue_attributes(
QueueUrl=self.sqsQueueUrl,
Attributes={
'Policy': policy
})
def DeleteTopicandQueue(self):
self.sqs.delete_queue(QueueUrl=self.sqsQueueUrl)
self.sns.delete_topic(TopicArn=self.snsTopicArn)
def WriteJsonFile(self, name, data):
print(name)
with open(name, mode="wt", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def StartDetection(self):
self.StartLabelDetection()
def GetDetectionResults(self):
try:
self.GetLabelDetectionResults()
except Exception as e:
print(e)
return
# LabelDetection
def StartLabelDetection(self):
response = self.rek.start_label_detection(
Video={'S3Object': {'Bucket': self.bucket, 'Name': self.video}},
NotificationChannel={'RoleArn': self.roleArn, 'SNSTopicArn': self.snsTopicArn},
)
self.startJobId = response['JobId']
print('Start JobId: ' + self.startJobId)
def GetLabelDetectionResults(self):
maxResults = 1000
paginationToken = ''
finished = False
loopCount = 1
responseAll = None
while finished == False:
response = self.rek.get_label_detection(
JobId=self.startJobId,
MaxResults=maxResults,
NextToken=paginationToken,
SortBy='TIMESTAMP',
AggregateBy="TIMESTAMPS"
)
json_name = '{}-{}-{}.json'.format(self.video, self.jobtype, loopCount)
self.WriteJsonFile(json_name, response)
if 'NextToken' in response:
paginationToken = response['NextToken']
loopCount += 1
if responseAll == None:
responseAll = response
else:
responseAll['Labels'] += response['Labels']
else:
if responseAll != None:
responseAll['Labels'] += response['Labels']
finished = True
if responseAll != None:
json_name = '{}-{}-all.json'.format(self.video, self.jobtype)
responseAll.pop('NextToken')
self.WriteJsonFile(json_name, responseAll)
def main():
profile = '<profile-name>'
role_arn = '<user-role-arn>'
bucket = '<bucket-name>'
video = '<file-name>'
session = boto3.Session(profile_name=profile)
client = session.client('rekognition')
rek = boto3.client('rekognition')
sqs = boto3.client('sqs')
sns = boto3.client('sns')
analyzer = VideoDetect(role_arn, bucket, video, client, rek, sqs, sns)
analyzer.CreateTopicandQueue()
analyzer.StartDetection()
if analyzer.GetSQSMessageSuccess() == True:
analyzer.GetDetectionResults()
analyzer.DeleteTopicandQueue()
if __name__ == "__main__":
main()
Discussion