[機械学習] FiLMとは?
はじめに
FiLMは様々な場所で用いられている基本的な技術の一つです。それだけでなく、元論文が比較的古いこと(2017)から、いろいろなモデルのベースラインとしても使われています。今回はそのFiLMの解説を作ってみました。
初投稿です
自分も未だ未熟者ですから、間違いやその他何かあれば、ぜひご指摘お願いします。
元論文とか参考文献とか
英語行けるのなら、こちらもぜひ 特にこれは色々情報が詰まっていておすすめです。
概要

FiLMのざっくりとした流れ
FiLM(Feature-wise Linear Modulation; 特徴量的線型変調)とは、ニューラルネットワークの特徴量に線形変換を行うことで、ニューラルネットワークの出力に意図的な変調(Modulation)を加える手法を指します。
使い道としては例えば、あるテキストに対応する画像を生成したいときに、FiLMを用いてテキストから抽出したデータをもとにニューラルネットワークを意図的に変調(Modulate)して、出力画像をテキストの指示に沿ったものにします。
具体的には、まず二種類の入力
元論文のように、画像とそれについての質問(テキストデータ)が与えられたり、拡散モデルの場合は、プロンプト(テキストデータ)と画像の種となるノイズが与えられたりします。

FiLMの大まかな構造
この時、
FiLMジェネレータ
FiLMジェネレータは、この後の線形変換に必要なスケール

FiLMジェネレータの大まかな構造
理論上は、スケールとシフトで別々のネットワークを作っても大丈夫なのですが、実用では計算コストの問題と情報共有の観点から、基本的には一つのネットワークで二つとも一気に出力して、後で二つに分ける方が一般的です。
FiLMレイヤー
FiLMジェネレータで生成したスケール
FiLMレイヤーでは、特徴量の線形変換を行います。線形変換いうのは、要はある変数に対して、ある値をかけたり(スケール)、ある値を足したり(シフト)して、その変数を別の変数に変換することを指します。
なお、スケールにおいては、要素ごとの積となるアダマール積を用います。
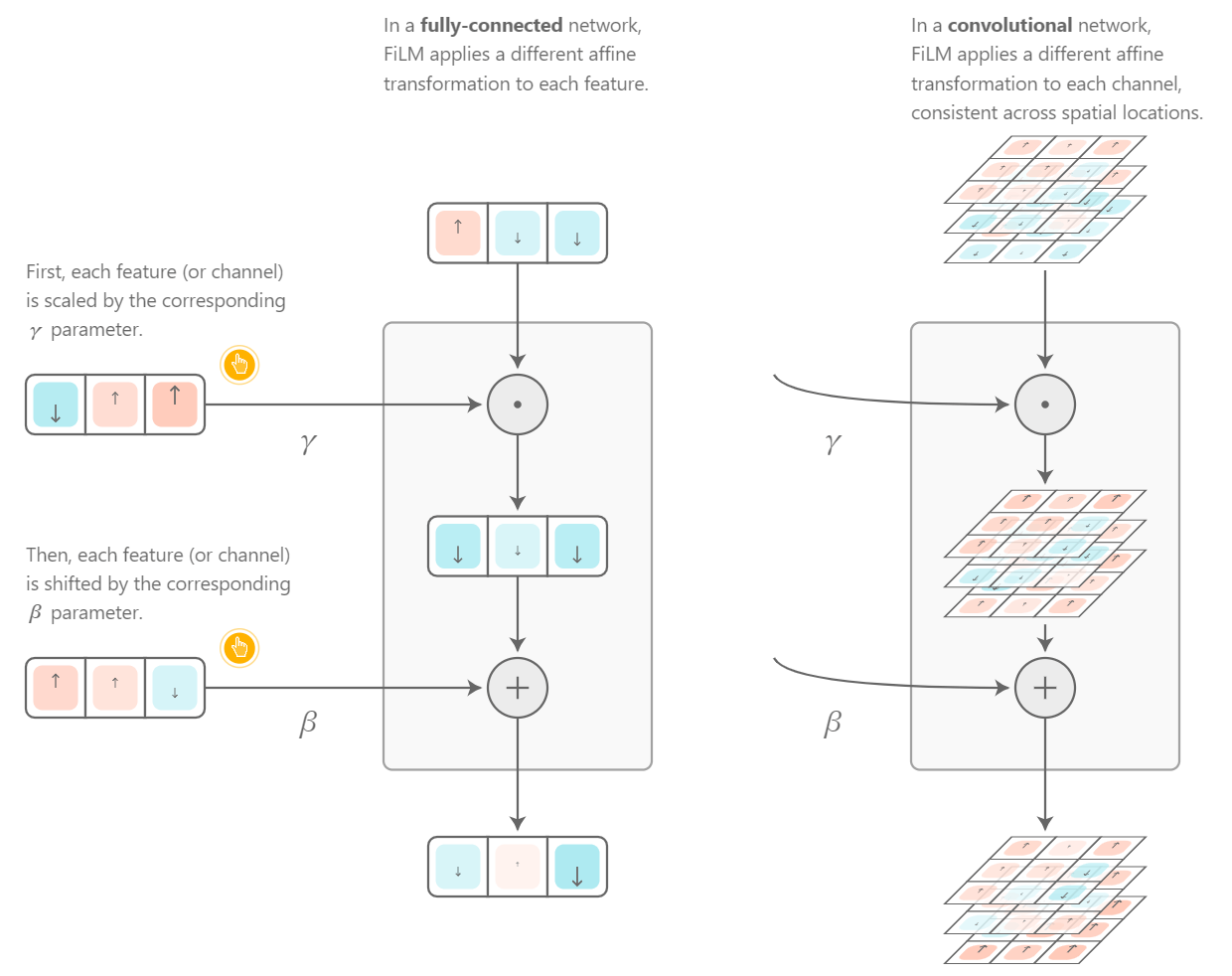
引用:Feature-wise transformations
非常にざっくりとしていますが、この変換を随所で行うことで、ニューラルネットワークの出力に入力
使用例
Visual question-answering (元論文の例)

引用:Feature-wise transformations
元論文に記載されている例ですが、ここでは画像をFiLM-edネットワークに渡して、その画像に関する質問をFiLMジェネレータに渡すことで、質問に対する答えを出力させるモデルを構築しています。
上図の通り、FiLM-edネットワークはResnetブロックの中にFiLMレイヤーを入れ込んでいます。一方で、FiLMジェネレータはGRUを通して、質問を処理して、最後はLinear層に渡しています。

引用:FiLM: Visual Reasoning with a General Conditioning Layer
Diffusion Transformer(DiT)

引用:Scalable Diffusion Models with Transformers
Diffusion Transformerが採用するadaLNには、FiLMもどき(というかAdaINもどき)の技術が使われており、
その他、
- BigGANにおける生成画像の条件付け
- 二つの画像間のstyle transfer(一方のスタイルをもとに、もう一方の画像を改変)
- RT-1やDiffusion Policyにおいて、観測画像に基づいたロボットの軌道の条件付け
などにも使われています。
FiLMがうまくいく理由
上の応用例の他にも、音声認識・強化学習・自然言語処理などの様々な分野でFiLMを適用することができます。なぜこれ程までにFiLMは汎用性が高いのでしょうか?
一つ目は、FiLMがスケール(掛け算)とシフト(加減算)の二つの長所を合体させた点にあります。
このサイトによると、スケールのメリットは、入力間の関係を取り込むことができることです。Attentionの内部構造から見て取れるように、二つの異なるベクトルの類似度を見る際に、乗算はよく用いられます。
一方で、シフトのメリットは、二つの入力の関係にあまり注目する必要がない場合においては、加減算を用いたほうが自然であるということです。(ここはよくわからないので有識者の方教えてください)
二つ目に、FiLMは効果が限定された帰納バイアスしか使わないので、様々なタスクにおいて多種多様な表現をすることが可能になります。これによって、ほかのより強力な帰納バイアスに比べて広い範囲に応用することができるのです。
FiLMの問題点
帰納バイアスがあまり強くない
先ほどメリットとして述べたことの裏返しで、FiLMは帰納バイアスがあまり強くないために、特定のタスクに特化した帰納バイアスと比べてしまうと、性能に劣ってしまう場面もあります。例えば、CLEVR(画像とそれに対応する質問が入ったデータセット)においては、多段階推論に特化した帰納バイアスを用いたMACネットワークがFiLMよりも高い性能をたたき出しました。
データ効率があまりよくない
FiLMは汎用性が高い代わりに、特定のタスクに特化した帰納バイアスと比べると、学習により多くのデータが必要になります。先ほどのMACネットワークとFiLMを比較しても、MACの方が少ないデータ数でも比較的高い推論精度を出し、早く収束していることがわかります。

引用:A Retrospective for "FiLM- Visual Reasoning with a General Conditioning Layer"
慎重な正則化が必要である
FiLMはそのままでは簡単に過学習してしまうため、様々な正則化を通さねばなりません。例えば、一つ代表的な正則化にWeight Decayがありますが、これをFiLMに適用しなければ、ネットワークの精度が10%ほど落ちてしまうことがあります。また、β, γを出力する層は複雑なものよりも、単純な線形層にすることで、精度が上がることが知られています。
類似技術1(Cross Attention)
Cross AttentionはFiLMと同様、第二の入力によって、出力の条件付けを行います。しかしながら、FiLMとは異なり、Attentionのqueryには第一の入力からの情報、key & valueには第二の入力からの情報を含めることで、第二の入力の情報を抽出しています。例えばStable diffusionにおける条件付けに使われています。これ以上の説明は、、もっと良いものが日本語で沢山転がっているので、ぜひそっちを参照してください。
類似技術2(Concatenation-based Conditioning)
Concatenation-based Conditioningとは、名前の通り、そもそもの入力データに条件を結合(Concatenate)することによって、出力の条件付けを行うもののことを指します。この方法の場合、データがモデルを通る中で、条件の内容が失われてしまう場合もありますが、一方でこの方法が有効な場合もあります。かなりいろいろな場所で用いられています。(例:GradTTS)
類似技術3(AdaIN; Adaptive Instance Normalization)
AdaINは、主にstyle transferにおいて、コンテンツ画像のチャンネルごとの平均と分散を、スタイル画像の平均と分散に置き換えることで、コンテンツ画像のコントラストに影響されずに正規化して、style transferするという技術になります。xがコンテンツ画像、yがスタイル画像だとすると、次のような表式になります。
ここで、外側の
まとめ
- FiLMは線形変換を通じて、出力の条件付けを行うことのできる技術である。
- FiLMはFiLMジェネレータから出力される
\beta \gamma - 汎用性は高いが、あるタスクに特化したものと比べると少し見劣りすることもある
- 類似技術として、Cross Attention, Concatenation-based Conditioning, AdaINが存在する
Discussion