これはU-ZERO Advent Calendar 2025の6日目の記事です。前日の記事はこちら。
はじめに:AIが書いたドキュメント、なぜ頭に入らない?
普段Claude Codeを使って開発を進めていますが、調査をさせたり設計のたたき台を作らせたりして、人間の認知負荷はかなり下がってきたはず・・・なのですが、どうにもAIが出力するアウトプットが頭に入ってこない、、、ということがよく起こります。
例えば、新機能を実装するために既存コードの調査をAIに依頼したとします。「この機能を追加したいんだけど、関連する既存の実装を調べて」と指示すると、数秒後には詳細な調査レポートが出力されます。関連するクラス、メソッド、データの流れ、依存関係——情報としては申し分ない。さっそく上から読み始める。しかし、読んでいるそばから内容が頭をすり抜けていく。一つ一つの文は理解できる。でも、全体として何がどう繋がっているのかが見えてこない。最後まで読み終えても「で、結局どこから手をつければいいんだ?」という状態になる。
なぜAIの出力は頭に入りにくいのか
理由1:情報過多と視覚化の欠如
AIの出力するドキュメントは単純に物量が多く、図解をあまりしてくれない。パッと見で理解できない。つまり、情報過多で人間が理解しやすいようなドキュメントの作りをしていないからだ、というのは一つの理由だと思います。
長文のテキストを順番に読み解くよりも、図やダイアグラムで全体像を俯瞰する方が、情報の構造を素早く把握できます。AIは(指示しない限り)テキストベースで出力する傾向があり、この点で人間の認知特性と相性が悪いと言えます。
理由2:「調べる」と「理解する」の違い
しかし、それだけではなくもう少し別の要因もあるように思います。
自分で調査を進める時には、自分の理解できる量を自分の理解しやすいまとめ方をして少しずつ取り込んでいくことで、一つ一つを理解した上で自分の頭に詰め込んでいきます。そのため、少しずつ自分の理解している範囲を広げていくことが可能なわけです。
その際には、「理解する→必要な情報のみに削り落とす→記憶化する」という行為をしているため、必要な情報を必要な時に記憶から取り出せるわけです。
しかし、その行為が行われていない場合(AIの書いたアウトプットを読み下した場合)、記憶から取り出す行為はドキュメントから探し出す行為に変わります。「理解する」という行為をしているのではなく、「読む」という行為をしているため、記憶に残らなくなってしまっている可能性もあります。
これは認知心理学でいう「生成効果(Generation Effect)」と関連しています。人は情報を受動的に受け取るよりも、自分で生成・再構築した情報の方がよく記憶できるのです。自分で調査する過程では、情報を取捨選択し、自分の言葉で再構成するという「生成」の行為が自然と行われています。一方、AIの出力を読むだけでは、この生成プロセスがスキップされてしまいます。
AIは「調査」を代替するが、「理解」は代替しない
AIが代替するのはあくまで「調査」という行為であって理解ではないので、人間は改めて自分の中で情報を再構築して理解する必要があります。
ここで重要なのは、AIを使うことが悪いわけではないということです。むしろ、調査という時間のかかる作業を効率化できるのは大きなメリットです。問題は、AIの出力をそのまま「理解した」と錯覚してしまうことにあります。
AIとの協働において、役割分担を明確にする必要があります:
- AIの役割:情報収集、整理、構造化
- 人間の役割:理解、判断、応用
人間の認知的限界を理解する
しかし、一度に大量の情報を処理するのは人間に向いている行為とは言い難いため、情報をチャンク化する必要があります。
チャンクとは情報の塊のことで、認知心理学では「人間が一度に記憶できることの単位」のことを意味します。ミラーの法則(マジカルナンバー7±2)を耳にしたことのある人もいると思いますが、人間のワーキングメモリは限界があります。
より最近の研究では、この数はさらに少なく4±1程度とも言われています(Cowan, 2001)。つまり、私たちが一度に意識的に処理できる情報の塊は、せいぜい3〜5個程度なのです。
AIが出力する長大なドキュメントには、この限界をはるかに超える情報が含まれています。だからこそ、情報を適切なサイズに分割し、関係性を視覚化することが重要になります。
実践:JsonCanvasで情報を再構築する
そこで、JsonCanvasを使って情報をチャンク化して情報の再構築を行います。ここではObsidianを使うのが良いと思います。Mermaidを使えるのでUMLの視覚化が綺麗にされます。(IntellijIDEAでもUML表示は可能ですが、個人的にあれは見難いです。)
なぜJsonCanvas(Obsidian Canvas)なのか
JsonCanvasは、情報を「カード」として空間的に配置し、それらの関係性を線で結ぶことができるフォーマットです。これには以下のメリットがあります:
-
空間的記憶の活用:人間の脳は空間的な配置を記憶するのが得意です。情報を2次元空間に配置することで、「あの情報は左上にあった」という形で記憶に残りやすくなります。
-
関係性の可視化:概念間のつながりを矢印で表現できるため、情報の構造を直感的に理解できます。
-
段階的な詳細化:全体像を俯瞰しながら、必要に応じて各カードの詳細に潜っていけます。
-
Markdownとの統合:ObsidianではCanvas内にMarkdownファイルを埋め込めるため、既存のノートを再利用できます。Mermaidによるシーケンス図やER図も描画可能です。
-
AIが直接読み書きできる:FigJamやMiroなどのホワイトボードツールと異なり、JsonCanvasはその名の通りJSON形式のテキストファイルです。そのため、Claude Codeなどのコーディングエージェントが直接ファイルを読み書きできます。AIに調査結果のたたき台をCanvas形式で出力させ、それを人間が編集・再構築するというワークフローが可能になります。
具体的なワークフロー
-
AIに調査を依頼する
- 通常通り、Claude Codeなどに調査を依頼
- 出力されたドキュメントを一度ざっと眺める
-
核となる概念を抽出する
- 最も重要なキーワードや概念を3〜5個ピックアップ
- これがCanvas上の主要なカードになる
-
Canvasに配置する
- 抽出した概念をカードとして配置
- 中心に最も重要な概念、周辺に関連概念を配置
-
関係性を描く
- カード間を矢印で結び、関係性を明示
- 必要に応じてラベルを追加
-
詳細を追記する
- 各カードに、自分の言葉で説明を追加
- AIの出力をそのままコピペしない(これが重要!)
-
見直しと調整
- 全体を俯瞰して、抜け漏れがないか確認
- 必要に応じて配置を調整
JsonCanvasの例
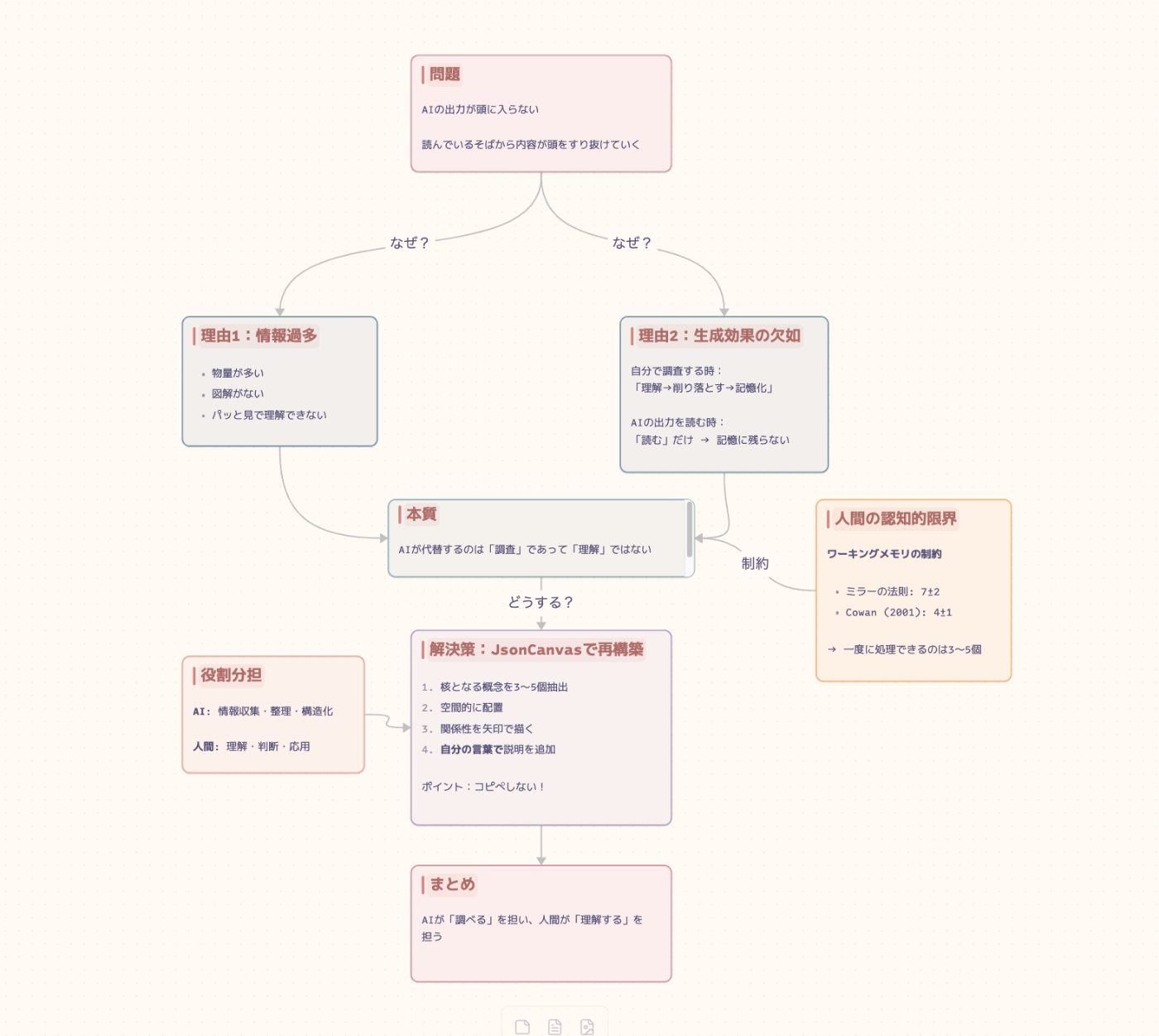
ポイント:自分の言葉で書き直す
このワークフローで最も重要なのは、「自分の言葉で書き直す」というステップです。AIの出力をそのままコピー&ペーストするのではなく、自分なりに咀嚼して再表現する。この過程こそが、先述した「生成効果」を発動させ、記憶への定着を促します。
面倒に感じるかもしれませんが、結局のところ、後で何度もドキュメントを読み返す時間を考えれば、最初に理解のための時間を投資した方が効率的です。
まとめ:AIと人間の最適な協働のために
AI時代において、情報へのアクセスはかつてないほど容易になりました。しかし、「情報を得ること」と「理解すること」は別物です。
AIは調査や情報収集という「インプットの効率化」には絶大な力を発揮します。しかし、その情報を自分のものにするには、人間側での「再構築」というプロセスが不可欠です。
JsonCanvasのようなツールを活用し、情報をチャンク化・視覚化することで、人間の認知特性に合った形で情報を再構築できます。それは一見遠回りに見えて、実は最も確実に知識を自分のものにする方法なのです。
AIが「調べる」を担い、人間が「理解する」を担う。この役割分担を意識することで、AI時代においても深い理解と確かな記憶を手に入れることができるのではないでしょうか。

Discussion