【BPLS4】チームレジャーランドを支える技術
はじめに
プロe-Sportsチーム、チームレジャーランド所属のU76NER(うなむね)です。昨年まではプレイヤーとして活動しており、今年からは監督として引き続きチーム運営に携わっています。
現在開催されているBEMANI PRO LEAGUE -SEASON4- beatmania IIDX部門において、チームレジャーランドはレギュラーステージで負けなしの5勝1分の成績を残しており、最終的にレギュラーステージを1位で突破することができました。
シーズンを戦っていく上で監督の業務は様々ありますが、その中のひとつとして、本業のソフトウェアエンジニアの知識や経験を活かして、戦略立案のためのデータ分析の効率化に取り組みました。
本記事では、その成果をご紹介します。
(余談ですが、私がプロゲーマーの世界に足を踏み入れた経緯はこちらの記事をご覧ください。)
BEMANI PRO LEAGUE -SEASON 4-
BEMANI PRO LEAGUE(BPL) は、音楽ゲームブランドの代表格であるBEMANIシリーズのタイトルで争われるe-Sportsのプロリーグです。4年目である今年は BEMANI PRO LEAGUE -SEASON 4-(BPLS4) が開催されています。初年度はbeatmania IIDX部門のみでしたが、2年目からは開催機種が増え、これまで3タイトルでリーグが開催されています。
チームレジャーランドは初年度からBPLに参加しており、私も最初のシーズンから継続してチームレジャーランドのbeatmania IIDX部門に所属しています。
BPLにおける戦略とスコア分析
試合は個人競技スポーツの団体戦に近く、リーグ戦においては対戦する2チームがそれぞれ3人のプレイヤーを選出し、その3回の対戦で出場するプレイヤーがお互いに選んだ楽曲をプレーする形式で試合が行われます。
チームレジャーランドではチームオーナーの株式会社山崎屋さまのご協力のもと、チームアドバイザーのABEARさんが中心となり、オーダーや選曲を予想するために対戦相手の課題曲全てのスコアを収集、分析を行っています。私も今年からこのデータ分析に携わることになりました。
(具体的な戦略については、ABEARさんの記事をご覧ください。)
しかし、対戦相手のスコアを知るには、事前にbeatmania IIDXのWebページで対戦相手をライバルプレイヤーとして登録した上で、アミューズメント施設にある筐体で実際にプレーしてスコアを確認する必要があります。昨年までは、プレー画面を配信機器を利用して録画した上で、下図のような表に手作業で起こしていました。この作業は一度に数百曲程度扱うこともあり、非常に時間のかかる作業でした。
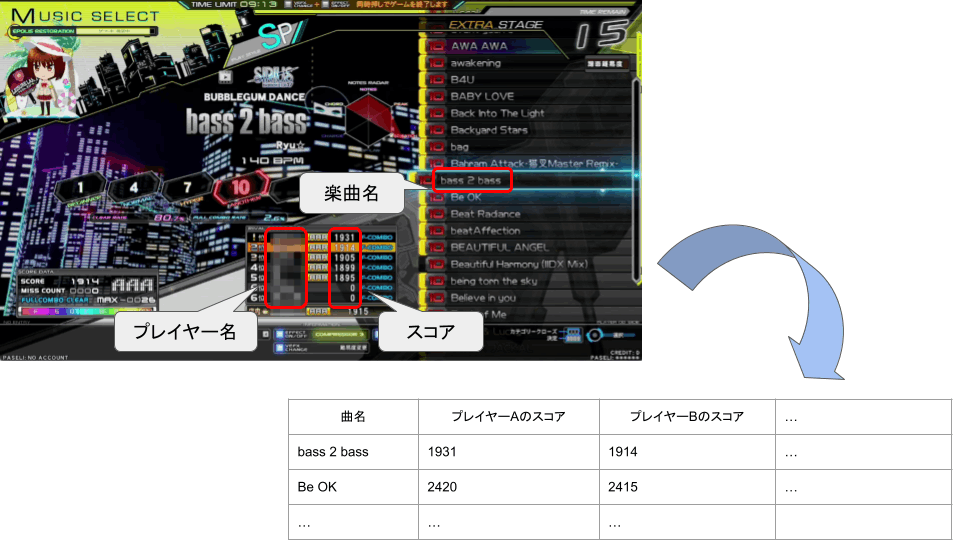
スコア集計作業(プレー画面は一部加工しています)
データの品質を上げるにはスコア収集の頻度を高めることが必要ですが、動画からスコアを集計する作業にかかる手間が大きなボトルネックとなっていました。
そこで、スコア集計の自動化を図ることで、 データ分析の効率化 に取り組むことにしました。
設計思想とシステムの概要
設計思想
動画からのスコア集計を自動化しようとすると、
- 動画からの画像の加工・切り出し
- 動画から各楽曲のスコアが表示されている画像を集計しやすい形に加工して切り出す
- 画像の文字認識
- 画像から楽曲名、プレイヤー名、スコアを文字認識してデータを取り出す
- データ集計
- マスターデータ(正しい曲名やプレイヤー名のリスト)と出力結果を突き合わせて、各プレイヤーごとにスコアを整理する
という工程に分解できます。
理想を言えば「動画を入力したら自動的に全てのスコアが出力される」のが望ましいですが、今まで画像認識についての経験が全くなかったこともあり、監督就任から試合まで約1ヶ月の期間で本業や他の監督業務と並行して、スコア集計を完璧に自動化できるようなシステムを開発するのは難しいと判断しました。
よって、トータルである程度効率化が達成できていればよく、 最悪ほとんど自動化できない工程があってもよい として、まずは最後まで動くシステムを作り切ることをゴールに設定しました。
システムの概要
詳細は各工程で説明しますが、最終的には以下のフレームワークを採用し実装を行いました。
- 動画からの画像の加工・切り出し: Python + OpenCV
- 画像処理で一般的に使われていて、技術記事も多い
- 画像の文字認識: Google Cloud Vision API
- 日本語を認識することができる
- デモがあり、本格的な実装を始める前に機能を検証することができた
- データ集計: Google Apps Script + TypeScript + clasp
- 現状スコア分析をスプレッドシート上で行っているため、Google Apps Scriptによるデータ操作がほぼ必須
- 最終的にソースコードをGitHub上で公開するのを見越して、ローカルからデプロイできる環境にしたい
画像の加工・切り出し
技術選定
画像の切り出しは、動画や画像の処理で一般的に使われていて、かつ技術記事も豊富な OpenCV を利用することに決めたところからスタートしました。
OpenCVによる開発を行うにあたって言語にはいくつか選択肢がありますが、当初は Tesseract により自前で文字認識を実装するつもりであり、こちらもTesseractによる開発の技術記事が多いPythonを選択しました。
しかし、
- 二値化等による画像処理を事前にしないと性能がでないが、そのような知識がほとんどない
- 読み取る対象の言語を事前に設定しておく必要があり、特に曲名は日本語とアルファベットが混在しているため、言語の都度切り替えが必要
等の理由により、 文字認識の自前実装は早々に諦め 、素直にクラウドサービスを頼ることとしました。
Python自体はほとんど触ったことがなかったので、あまり効率のよい開発はできませんでしたが、文字認識の自前実装を諦めた時点で画像の切り出し部分は概ね完成していたため、画像の切り出し部分はPython + OpenCVで作り切りました。
実装
機能としては、以下の2点を実装しました。
1. 手動でキーフレームを打つと、そのフレームが画像に出力される
動画は楽曲1つ1つに手でカーソルを合わせることで撮影しています。よって、カーソルの切り替わるタイミングは一定でなく、また誤操作も発生する可能性があるため、画像を切り出したいフレームを選ぶのは手作業を許容することとしました。
最終的には、最低限の早送り/巻き戻しとキーフレームを打つ機能を持たせた簡易的な動画プレイヤーを作成しました。
また、最後に出力した画像を別ウィンドウで表示できるようにし、意図しないフレームであった場合は直前の操作をキャンセルできるようにしました。
2. 画像出力の際、必要な情報だけを抜き出して新たに1枚の画像に並べて集約する
クラウドサービスを利用した文字認識を行うには、(確認した限りですが)以下のことに留意する必要があります。
- 画像にある文字列はすべて抽出する
- 不要なものも全部出力されてしまう
- 特定の領域のみ文字認識したくても、領域を指定するのは難しい
- 出力結果は配列で返されるが、要素の並び順の制御が難しい
- 文字列を検出した座標は取得可能だが、それをもとに更に並び替えるのは手間がかかる
- ただし、1列に文字列を配置した場合は、(自分が試した限りでは)その並びの通りに文字列を並べてくれる
- どのサービスでも、基本的に画像の枚数に対して課金される
- 極力1つの画像に多くの文字列を集約させたい
以上により、出力画像には曲名、プレイヤー名、スコアを縦1列に並べることとしました。このとき、曲名は画面上で2箇所表示されますが、大きく表示される曲名には様々なフォント(中にはカリグラフィーのようなものもある)が用いられていて文字認識の精度が低下する懸念があったため、右の曲リストに表示されているものを切り出しています。
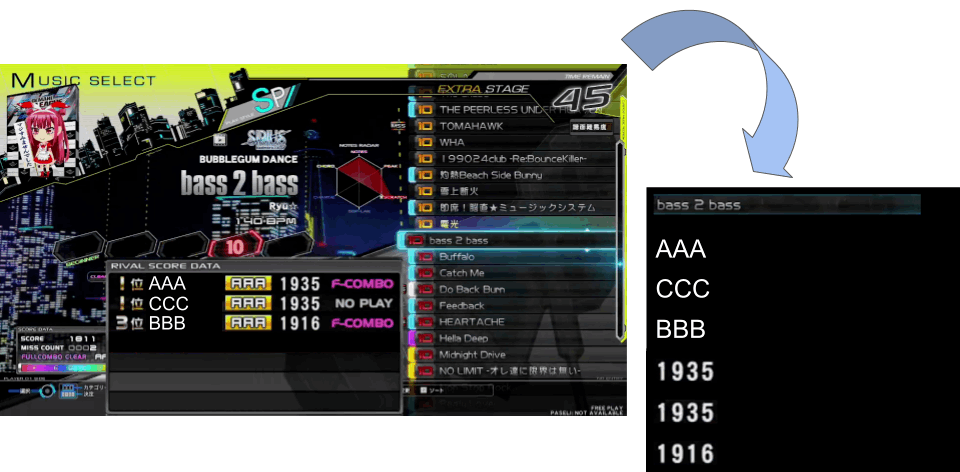
画像の切り出し(わかりやすいようにスコアの部分を拡大しています)
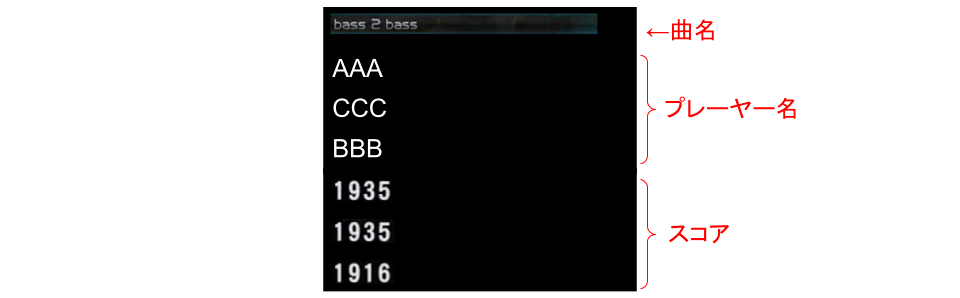
切り出した画像の内容
文字認識
技術選定
前述の通り、文字認識にはクラウドサービスを頼ることとしました。文字認識の機能は各種クラウドサービスで提供されていますが、以下の理由により、 Google Cloud Vision API を利用することにしました。
まず、 日本語を認識することができる というのが一番大きな理由でした。beatmania IIDXでは曲名が日本語を含む楽曲が多数あるので、日本語を読み取れることは必須となります。
また、 プロダクトの紹介ページ上でAPIを試せる ことも利点でした。これにより、文字認識処理を本格的に実装を始める前に、どのような画像を用意すれば望んだ形で出力が得られるか、機能を検証することができました。
なお、Vision APIは各種言語でクライアントが用意されていますが、今回は「APIを叩く→返り値を整形してファイルに出力する」機能のみを実装すればよいため、言語による有利不利はほとんどありません。そこで、普段からTypeScriptを利用して開発する機会が多く慣れているため、TypeScriptの型が提供されているNode.jsのクライアントを選択しました。
コスト
Vision APIの利用は課金制のため、事前にどの程度料金がかかるかを検討しました。
料金表によると、(各月の無料分を除いて)画像1,000枚に対して$1.50の料金がかかりますが、月々の画像処理枚数は高々数千枚程度であり、アカウント開設時に付与される無料クレジットで十分賄える金額であることがわかりました。よって、 金額面での懸念は当面発生しない ことがわかった上で実装を進めることができました。
実装
機能としては、画像を1枚ずつVision APIに送り、その返り値をファイルに出力するという非常に単純なものです。最終的にスプレッドシートでデータを加工できるようにしたいので、ファイルの出力形式はCSVとしました。
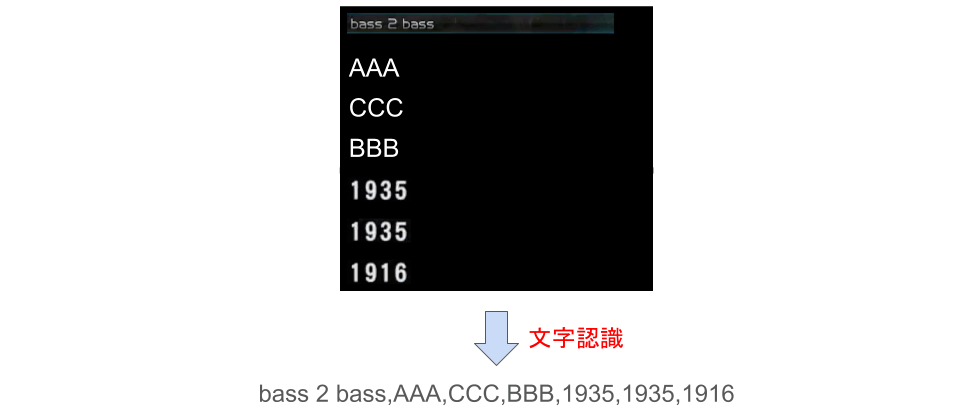
文字認識処理
この際、文字認識の結果には誤りがある程度含まれてしまいます。幸い、様々な画像で検証することにより、データが欠損するといったような集計に大きく影響する誤りはほぼ特定の条件下で発生し、発生頻度は手作業による補正を許容できる程度に低いことがわかりました。そこで、文字の誤認識は一旦無視してデータ集計時に考慮することとし、 欠損などの大きな誤りのみ手作業でデータの補正 を行いました。
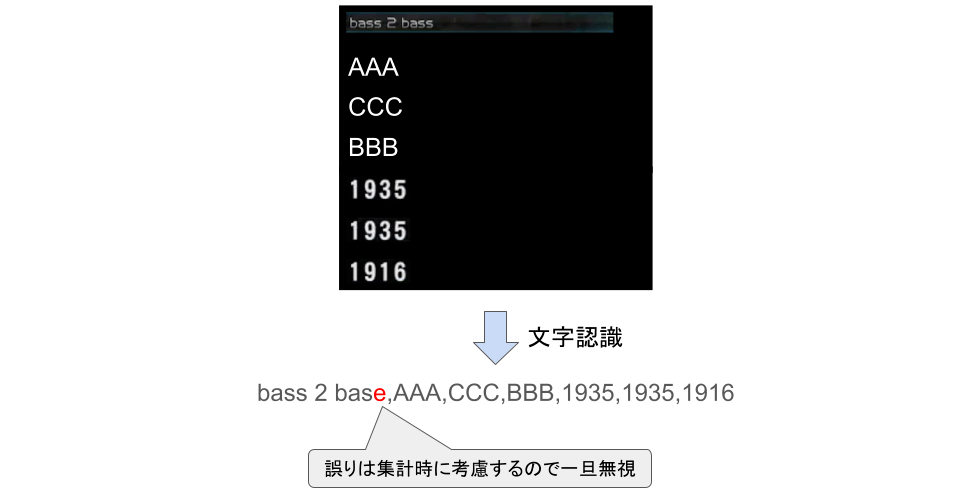
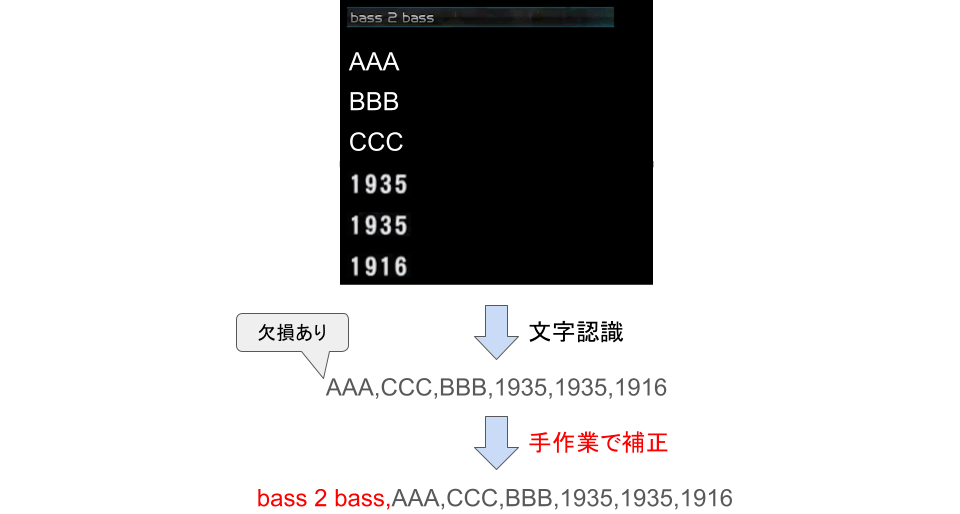
文字認識の誤りの扱い
なお、検証により得られた様々や知見や具体例は、今後別途記事にて紹介する予定です。
データ集計
技術選定
最終的なデータ分析はスプレッドシート上で行うため、データ操作のために Google Apps Script(GAS) はほぼ必須となります。
また、GASは実装・実行ともにGoogle Workspace上で行いますが、最終的にソースコードをGitHub上で公開して誰でも使えるようにする目標があったため、実装をローカル環境上で行えるようにする必要がありました。そこで、 clasp を導入することで、ローカル環境上で実装したGASのソースコードをGoogle Workspaceにデプロイできるようにしました。
実装
最終的に、事前に用意したマスターデータと文字認識結果を突き合わせて、各曲・各プレイヤーのスコアを表形式で出力することがゴールとなります。
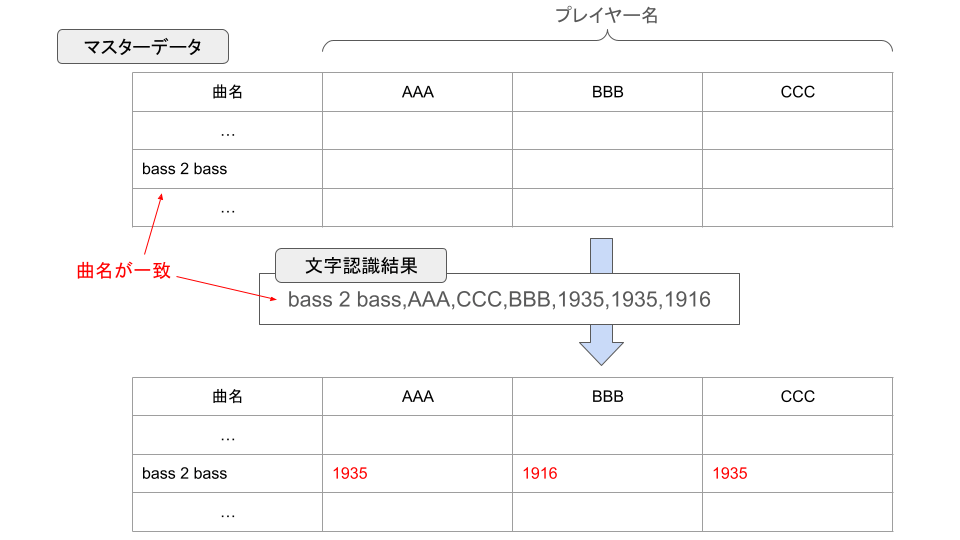
表への入力
しかし、文字認識結果にはしばしば誤認識が含まれるため、単に曲名やプレイヤー名が完全一致するかどうかで突き合わせることは困難です。
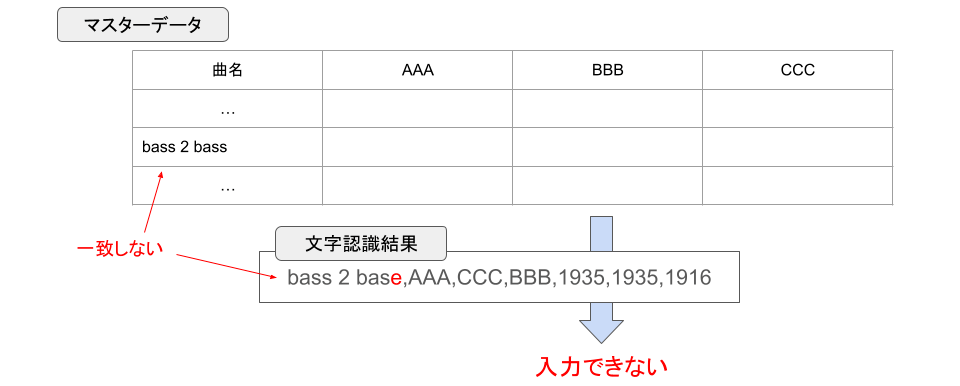
表への入力不可
そこで、曲名やプレイヤー名をマスターデータに基づいて整理するために、 レーベンシュタイン距離 によって文字列の一致度を判定することとしました。
2つの文字列のレーベンシュタイン距離が小さいほどそれらが近い文字列(0であれば完全一致)であるため、マスターデータと文字認識結果との全ての組み合わせについてレーベンシュタイン距離を計算し、最も値が小さいものを一致したデータとみなすこととしました。
(図では省略していますが、プレイヤー名についても同様にレーベンシュタイン距離を計算しています)
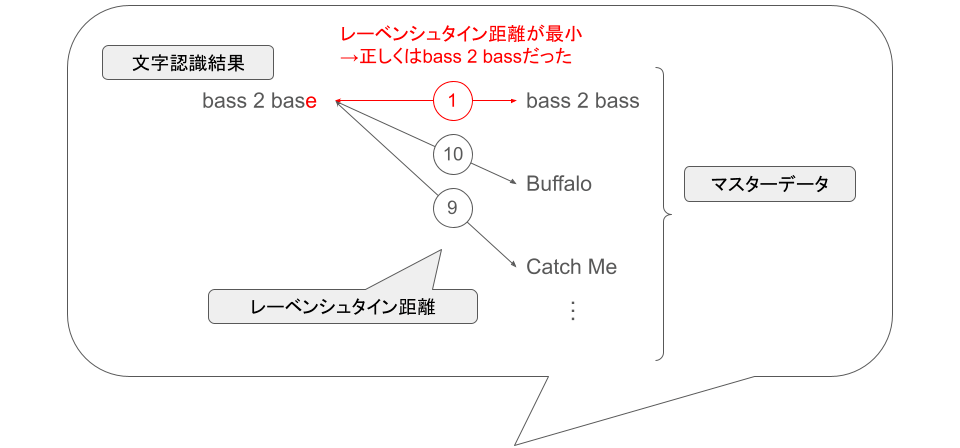
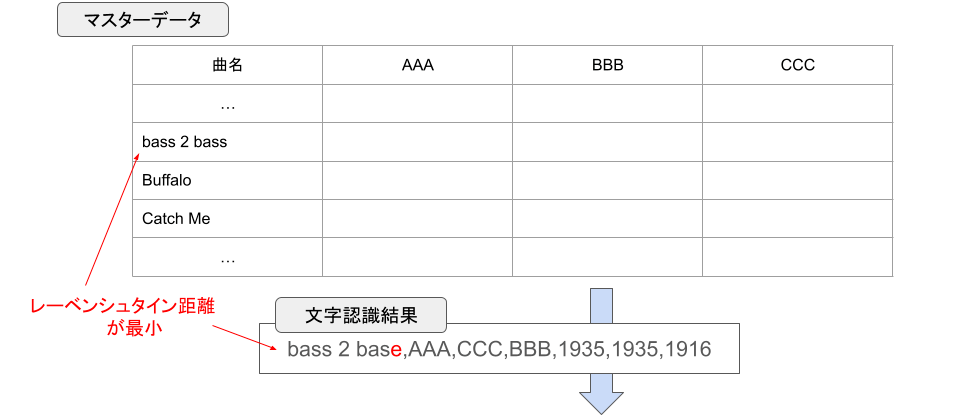
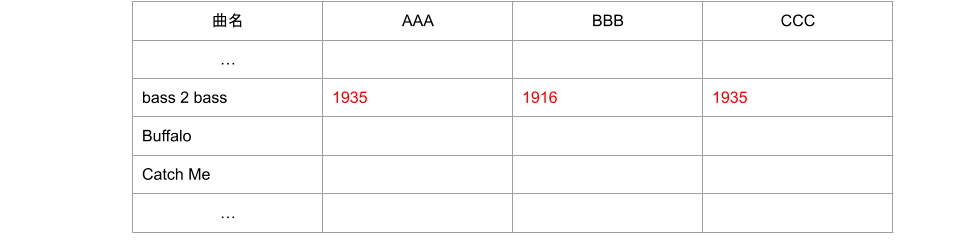
レーベンシュタイン距離によるデータの突き合わせ
なお、実装を進めるにあたって注意すべきこととして、上記の処理は全探索を行うため、今回実装した処理の中では一番計算に時間がかかることが予想されました。そこで、処理時間が現実的に実行可能な範囲に収まるかの検討を事前に行った結果、一度に処理する曲数を100曲程度に抑えれば十分実行可能である ことがわかりました。よって、課題曲はテーマやレベルで分類されていることを利用して、テーマやレベルごとに分割して処理ができるような形で実装を行いました。
処理時間の検討
2つの文字列A, Bのレーベンシュタイン距離の計算量は、それぞれの文字列の長さを
また、各曲について曲名やプレイヤー名を突き合わせる処理の計算量は、処理する曲数を
ここで、プレイヤー名は高々6文字なのに対して曲名は数十文字のオーダーとなるため、レーベンシュタイン距離の算出にかかる計算量は2つの文字列の長さの積になることを考えると、処理時間を考える上では曲名のみについて考えれば十分。
よって、一度に処理する曲数を100曲程度に抑えれば、
- 曲名の長さ
l < 10^2 - 一度に処理する曲数
n \approx 10^2
として、全体の計算量は
また、簡単に実装できる範囲で、
- 文字列から事前に空白文字を除く
- レーベンシュタイン距離の算出過程で、すでに一致度が他の文字列より低いとわかった時点で途中で計算を打ち切る
といった計算量を削減する工夫を施しています。
なお、文字認識の誤りの度合いが大きく、そのデータが適切に割り当てられないケースが発生することが考えられます。そこで、文字列が短いほど1字誤認識したときの影響が多いと考え、最終的な結果に (レーベンシュタイン距離 / 文字列の長さ) の値を併せて出力することとしました。この値が大きいほど異常なデータである可能性が高いため、最終的にこの値を基に目視で出力結果を確認し、異常なデータが見つかれば手で文字認識結果を修正し再度処理を実行するようにしています。

文字認識結果の修正
実装期間と改善効果
実装期間としては、技術的な検討からスコア集計システムを実際に実装するまでを約1ヶ月に収めることができ、BPLS4のシーズン序盤に間に合わせることができました。実際に、シーズンが本格的に開始した6月の初めごろからこのスコア集計システムの運用を行っています。
そしてシステム導入の結果、多いときには一度に800曲程度のスコアを集計する必要がありますが、 全ての工程を1時間以内 に収めることができました。手作業で集計する場合、1曲あたり30秒で集計できるとしてものべ400分とほぼ半日費やしてしまうような作業量になってしまいますが、これを平日の空き時間で終わらせることができる程度に削減することができました。
結果、作業時間を圧縮できたことでデータの収集頻度を上げることができ、データの品質も大きく向上しました。特に、試合のギリギリまでスコア集計ができるようになり、直前期にも 最新のデータに基づいて議論ができる ようになったという大きな恩恵を受けることができました。今シーズンのチームレジャーランドはオーダー提出期限の直前にオーダーを当初の予定から大きく組み替えることをしばしば行ってきましたが、結果的にオーダー変更はかなりの部分で的中し、チームの勝利に結びつけられています。
本システムの実装は作業時間を減らしたいというところからスタートしましたが、チームの勝利にも目に見える形で貢献することができ、予想より大きな成果を得られたと感じています。
今後の取り組み
今回のスコア集計システムによって作業量を大幅に削減することができましたが、更に以下のような改善ができないか検討しています。
- カメラで直撮りした映像からもデータを抽出できるようにする
- 画像の切り出しを完全自動化する
- 画像分類モデルを使って曲名検出の精度を向上させる
- ソート情報を利用するなどして一度に処理できる曲数を1,000曲程度まで増やす
他の業務に転用できる可能性もあるため、技術的に可能かどうかはまだ勝算がない段階ですが、必要があれば今後も開発を続けていきたいです。
また、先程も述べた通りGitHubでソースコードを公開して、 誰でも利用できるようにしたり、コード上で具体的に改善の議論ができる ようにならないか、ということを考えています。今はまだ可読性が著しく低い状態ですが、近い内にリポジトリを公開できるように整理したいと思っています。
おわりに
本記事では、 ソフトウェア技術によるe-Sportsチーム運営の業務改善成果 をご紹介しました。私は以前にもソフラン曲(曲中にテンポが変化する曲)のプレー支援ツールなどを開発してきましたが、今回実際にチームの業務改善に貢献できたことは大きな達成感があります。
チームレジャーランドは2024年10月5日(土)に開催される BPLS4 IIDX FINAL に出場し、優勝まであと2勝のところまで迫っています。
私自身、2年前のBEMANI PRO LEAGUE -SEASON 2- ファイナルに選手として出場し、あと一歩で優勝を逃す経験をしました。今シーズンのFINALまで残された時間はあとわずかですが、今度こそ優勝を勝ち取るべくチームに貢献していきたいと思います。
ここまでお読みいただき、ありがとうございました。今後ともチームレジャーランドの応援をよろしくお願いいたします。
Discussion