ChatGPTを使って簡単なコードを書いてみる
やりたいことは、読みたいWebの記事を音声データにして散歩中に聴くことで、塩漬けになる記事の量を減らしたい
Rebuildで聴いた気がするやつ、をChatGPTに頼って作ってみる
まず、URLから本文データを抽出して、GoogleのText-to-Speechに投げる部分
こんな全体像の真ん中と右側のイメージ
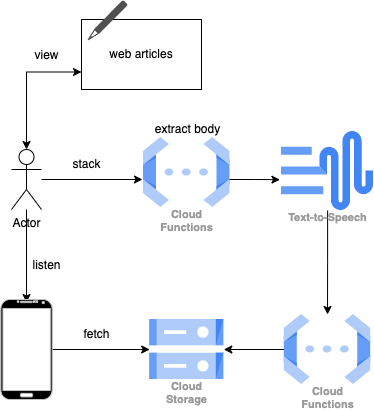
これをみると、Cloud FunctionsがCloud SQLに接続するときにCloud Runをデプロイしておいてその接続情報を利用する・・・??
後で考える
まず最初にChatGPTをアップグレード
Hey, ChatGPT! ブログの本文を抜き出したい!
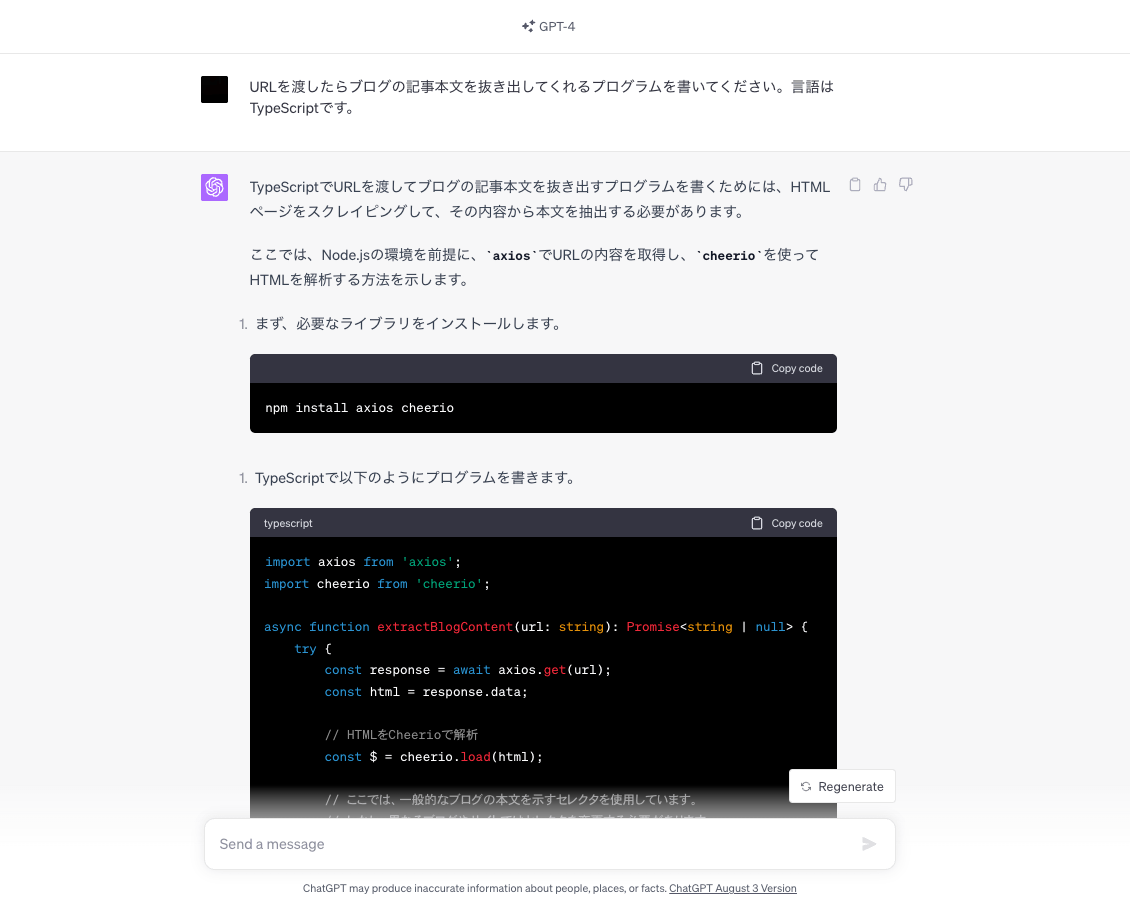
とりあえずライブラリとコードの検証する
axiosもいいけど、(jsdom)[https://github.com/jsdom/jsdom]がちょうど良さそうな気配なので、やり直してもらう
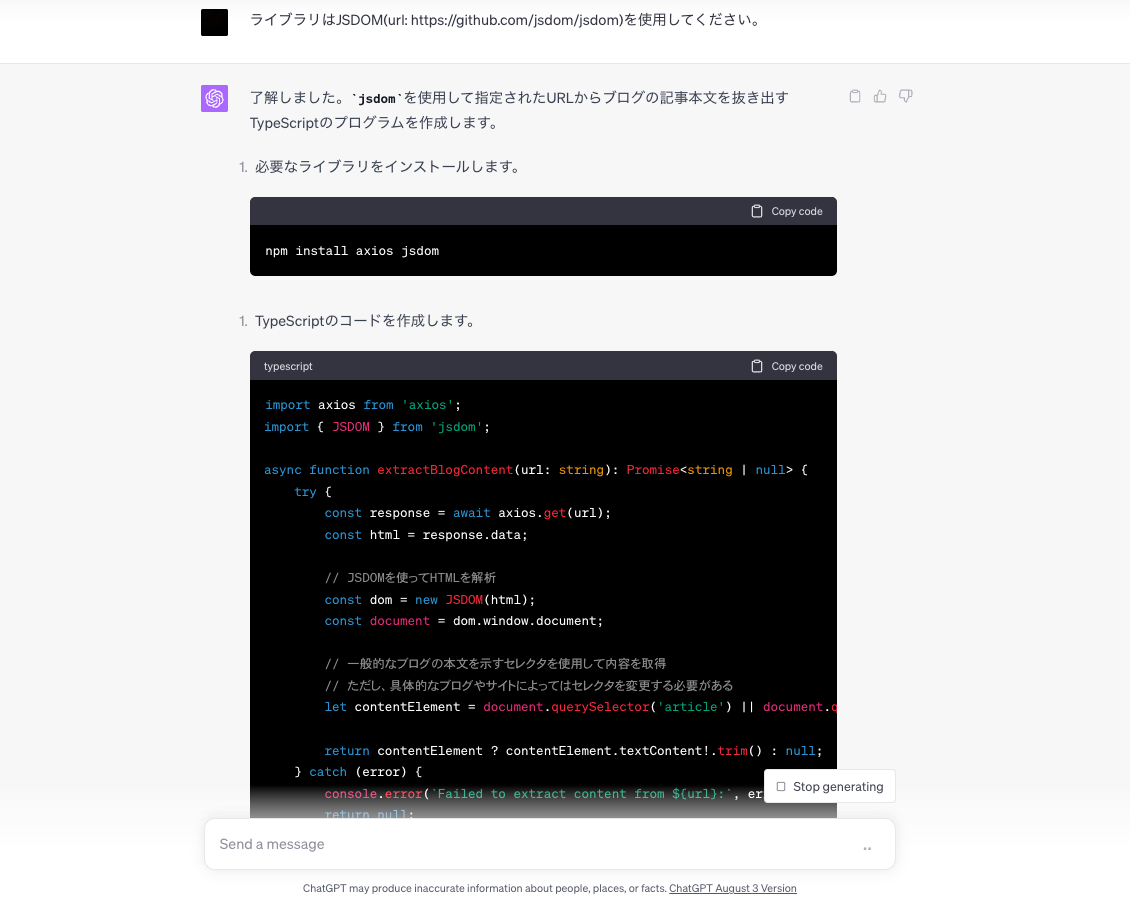
と思ったら、まだaxiosを使っている
urlを引数に使えると教えてみる
素晴らしい!
今度は install 的な親切文がなくなった。axiosはinstallから載せられている記事が多いのだろうか
今回はこのURLを対象にして実行してみる
型チェックはとりあえず通っているっぽい、すごい
こんな感じの文章が出力されたらすごい
Clean Frontend Architecture
Exploring the Frontend Architecture: An overview of some of the principles associated with a clean frontend architecture (SOLID, KISS, DRY, DDD, and more).
実行する
$ npx ts-node sample-extract-article-from-url.ts
Clean Frontend ArchitectureExploring the Frontend Architecture: An overview of some of the principles associated with a clean frontend architecture (SOLID, KISS, D
RY, DDD, and more).Robert Maier-Silldorff·FollowPublished inBits and Pieces·6 min read·Jul 14--10ListenShareIn one of my previous posts, I talked about Signals and
what’s still missing [1]. Now, I want to talk about a more generic topic, namely Clean Frontend Architecture. There are a lot of principles around this topic:SOLI
D, KISS (Keep it short and simple), DRY (Don’t repeat yourself),
......
出力されてる!すごい!
ドキュメント何も見ないで完成した、すごい
改行に句読点的なのがないと単語が連続してしまうので、新単語が生まれてしまったがそれでもすごい
続いてText-to-Speechに投げる部分を作ってもらいます。
Hey, ChatGPT!
Webコンソールの操作から載っている、とても丁寧
呼び出し部分はこんな感じ
async function textToSpeech(text: string, outputFilename: string): Promise<void> {
try {
// リクエストの設定
const request = {
input: { text },
voice: { languageCode: 'en-US', ssmlGender: 'NEUTRAL' },
audioConfig: { audioEncoding: 'MP3' }
};
// Text-to-Speech APIを呼び出し
const [response] = await client.synthesizeSpeech(request);
// 音声をファイルとして保存
fs.writeFileSync(outputFilename, response.audioContent, 'binary'); // ここが型エラー
console.log(`Audio content written to file: ${outputFilename}`);
} catch (error) {
console.error('Error:', error);
}
}
こっちは型チェックに引っかかってしまった、が response.audioContent が undefined になりうるところくらいなので、手元でパパッと修正
response.audioContent ? fs.writeFileSync(outputFilename, response.audioContent, 'binary') : undefined;
textToSpeech2("Your lengthy text here...", "output.mp3");
出力されているこれを実行してみるとファイル生成された!すごい!
しかもちゃんと聞ける感じのが!(zennが音声ファイル未対応のため添付はなし)
Text-to-Speechのドキュメント何もみてないのに!大丈夫かな!
日本語も試してみたいので、適当にlanguageCodeを触ってみる languageCode: 'ja-JP'
英語と比較し日本語は少しゆっくりな印象だけどそれでもちゃんと聞ける、良さそう
多分細かいピッチとかスピードとか調整できたはずだし
日々のWeb積読ちゃんと聞けそう
最後にarticle抜き出す部分とAPI投げる部分を適当に結合して試してみると、5000bytesまでしか1回のリクエストで受け取れない的なエラーが返ってきた
なるほど、ChatGPTさんお願いします
すぐに対応してくれる、さすが
と感動していると
恐らく依頼してないけど、確かに欲しい!みたいなことまでやってくれている!天才!
しかも、またしてもそのまま動いてる!
一旦このへんまで
思った以上に正確なコード書いてくれるし、細かいところは気になるけどそれも時間の問題っぽい感じがすごいする
しかし、当初は全部ChatGPTベースで開発してみようと思ったけど、プロンプトエンジニアリングにそこまで慣れてないせいか、何度か試している間にそこそこ疲れてしまった
けど多分慣れていかないといけない気もした
コードを動かすだけならとりあえずChatGPTに投げてから考える、みたいなフローは早そう
ただ、まだ手離れはそんなに良くはなさそう
風の噂でChatGPTの出力したTypeScriptを型チェックにかけてイテレーションするのか、とにかく型安全なコードが出力されるプラグインが開発されているみたいな話も聞くので、何であれ時間の問題ではありそう