[Citus 10]Columnar Storageなど新機能を試す
当記事ではPostgreSQLにSharding機能を提供する、CitusにVersion10が出たことを記念して、それらの新機能を中心とした検証結果の解説を行う。
Shardingは以前から存在する技術で、複数ノードにデータを分散配置することで、スケールアウトが難しいとされるリレーショナル・データベースに水平方向の拡張性を持たせる。単一サーバでは実現できない処理性能を賄うための、分散DBの一種と言える。(参考:2020年のNewSQL「Sharding」)
RDBMSでShardingの拡張機能を持つものとして、下記のようなものがあげられる。
- Spider:MySQLストレージエンジンとして実装されている。国産らしい。
- Oracle Sharding:12cR2から提供されている。
- Vitess:MySQLベースのSharding、PlanetScale社が開発している。
- Citus:PostgreSQLのextensionとして実装されている。
なお、Shardingの実現には、アプリケーション側に同等の機能を持たせるということも良く行われる。例えば、特定範囲のユーザIDを処理するアプリケーションとDBをセットで配置し、処理負荷に応じてその分割範囲やサーバ台数を変更する。
アプリケーション・パーティショニングなどと呼ばれる手法だが、特定DBMSの機能に依存しないため、Shardingを検討する際はこちらも合わせて検討することが望ましいと言える。
Citusとは
CitusはCitus Dataが開発してきたPostgreSQLのSharding用extensionである。
(注:PostgreSQLにはextensionという機能追加の仕組みが存在する。参考はこちらなど)
Citus Dataは2019年にMicrosoftに買収されたが、その後も開発は継続され、Azureでその機能をマネージドサービスとして提供するHyperscale(Citus)が登場するなど、お互いのサービス統合が進んでいる。
Azure以外でもOSSのCitus(Community Editionの名称が継続しているかは不明)を使って、PostgreSQLのSharding環境を構築することは可能であり、今回は以降でそれを試していく。
Citusの構成
Citusを用いた構成では、全てのノードにPostgreSQLとCitus extensionがインストールされ、2種類のノードでクラスタが構成される。
-
Coordinator
クライアントからのクエリを受け付ける。これ自体もPostgreSQLインスタンスである。 -
Worker
データを格納するPostgreSQLインスタンス。クライアントが直接Workerに接続することはない。
[Citusの構成図]
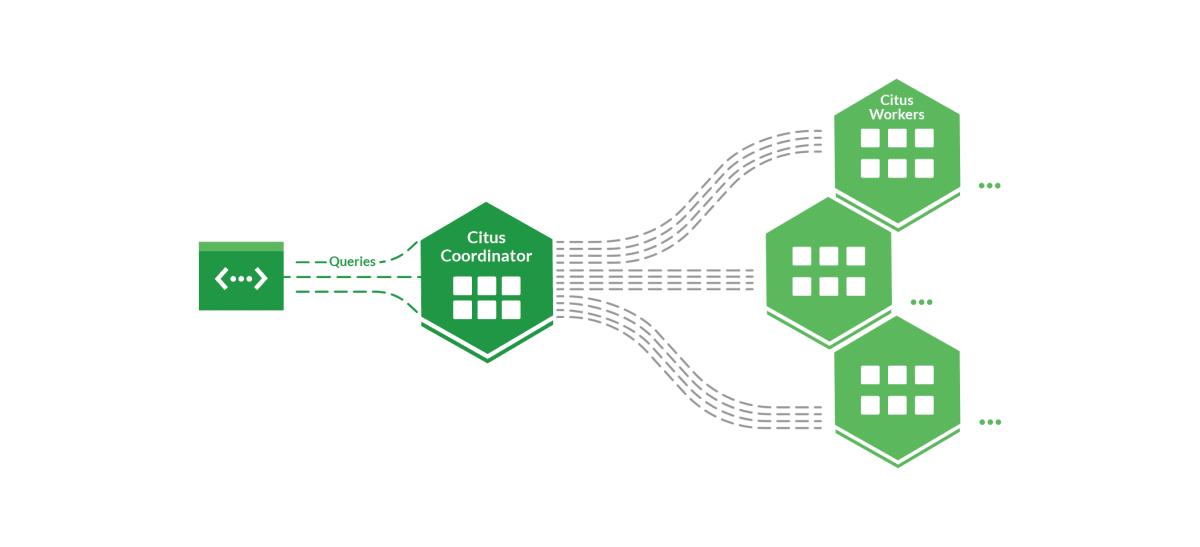
Citusでは複数のWorkerにデータを分散配置し、更に複数Workerにわたってクエリの並列処理を行うことができる。
(3+1)のテーブル種別
Citusでは分散配置のために、3タイプのテーブルが用意されている(参考)。
-
Distributed Table
Workerノードで水平に分割されるテーブル。
Distribution Column(いわゆるシャードキー)と言われる列の値に応じて、レコードは適切なWorkerに格納される。 -
Reference Table
全てのWorkerに同じレコードを格納するテーブル。つまりWorker間でデータがレプリカされている。
Distributed TableとのJOINをWorker内で(通信オーバーヘッドなしで)実行するために使われる。ドキュメントには"When interacting with a reference table we automatically perform two-phase commits (2PC) on transactions."とあるので注意が必要。 -
Local Table
Coordinator上につくられる分散されないテーブル。通常のPostgreSQLのテーブルと同様である。
Citusの機能を活かすためにはDistributed Columnを適切に設計し、Distributed Tableを使うことが重要である。例えば、下図のようにアプリケーションから見ると透過的なTableが各WorkerノードにTable_1001/Table_1002/Table_1003/Table_1004として配置され、Coordinatorがそれらへクエリを分散し、結果を取りまとめてクライアントへ返す。
[CitusのDistributed Tableの構成イメージ]

アプリケーションをCitus上で開発するには、Distributed TableとReference Tableを適切に使い分けるとともに、Colocationと言われる概念も取り入れて、JOIN時に発生するWorkerノード間の通信を抑える設計が必要となる。
なお、後述するようにCitus 10ではColumnar Storageが登場した。これはレコードを保持する形式を(PostgreSQLで一般的な)行形式ではなく、列形式とするものである。
こちらのblogにもあるように、Columnar Storageはデータ分散とは異なる概念のため、Distributed Tableと組み合わせてハイブリッドな構成とすることが可能である。
[行/列混在のハイブリッドテーブルのイメージ]
※ある意味、設計難度は上がったとも言える。
Citusの制約
CitusはPostgreSQLの拡張であるが、PostgreSQLと同様のSQL全てを処理できるわけではない。Distributed Tableを使用した際にはこちらのドキュメントにあるように、いくつかの制約があるため、利用時には確認しておきたい。
(おまけ)HTAPとデュアルフォーマット
以前こちらに書いたように、最近発表されたリレーショナルなデータベースではOLTPとOLAP双方の用途で使えるHTAPを特徴として打ち出すものが多い。それらでは行と列両方の形式で同じデータを保持し、更新があった場合には両者間で同期を行う。
CitusのハイブリッドなSharding構成はデータ範囲によって行と列の形式を使い分けることになるため、デュアルフォーマットではない。また、Columnar Storageは現時点で更新不可で追記のみのため、その辺りの利用感も過去にあげたHTAPのデータベースとは異なる。こうした構成上の特徴をおさえて、行形式と列形式、またはそのハイブリッドのデータベースを上手く活用していく必要がある。
Citus10の新機能
2021/3にCitus v10.0.2がリリースされた。これに合わせて、Citus Dataのblogでも各種記事が公開された。
Citus 10: Columnar for Postgres, rebalancer, single-node, & moreという投稿に紹介されている、Citus 10の新機能は以下の通りとなっている。
-
Columunar Storage
行形式(Heap)ではなく、列形式(Columnar)でデータを格納する。 -
Sharding on a single Citus node
単一ノード内でSharding構成が可能。 -
Shard rebalancer in Citus open source
Citusクラスタ内の各シャードをディスク容量などで再編成(リバランス)する機能。機能自体は以前からクラウドで使われていたものだが今回OSS化された。 - Joins and foreign keys between local PostgreSQL tables and Citus tables
- Functions to change the way your tables are distributed
今回の記事ではColumnar Storageなどの機能をSingle Citus Nodeで試している。rebalancerについては今回検証していないため、別途記事にする可能性がある。
(おまけ)cstore_fdw
Citusではかつてcstore_fdwという、列形式のextensionを開発していた。こちらはPostgreSQLのForeign Data Wrapper(FDW)として開発された。
Citus ColumnarはTable Access Method APIを使って実装された、プラガブルストレージの一種である(おそらくそのはず)。Table Access Method関連の概要と開発経緯については富士通さんの解説が非常に分かりやすい。
Citus DataとしてはCitus Columnarをcstore_fdwの後継と位置付け、今後はそちらを利用するように呼び掛けている。
Single NodeなCitusを試してみる
前置きが長くなったが、ここからはCitus 10を試してみよう。
上で述べたようにSingle Nodeでも多くの機能が利用でき、公式のDockerイメージが提供されているため、VM一つあれば大体の動作を確認することができる。
(検証環境)
- Google Cloud、e2-small(vCPU*2、メモリ2GB)
- Ubuntu 20.04 LTS
- Docker 20.10.5
Docker上にCitus 10のコンテナを起動する方法はこちらのドキュメントに書かれている通りである。
# Citusコンテナの実行
$ sudo docker run -d --name citus -p 5432:5432 -e POSTGRES_PASSWORD=mypass citusdata/citus
# 実行状況の確認
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f68d0e7559f4 citusdata/citus "docker-entrypoint.s…" 12 seconds ago Up 10 seconds (healthy) 0.0.0.0:5432->5432/tcp citus
# PostgreSQLのバージョン確認
$ psql -U postgres -h localhost -d postgres -c "SELECT * FROM version();"
version
------------------------------------------------------------------------------------------------------------------
PostgreSQL 13.2 (Debian 13.2-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
(1 row)
# Citusのバージョン確認
$ psql -U postgres -h localhost -d postgres -c "SELECT * FROM citus_version();"
citus_version
-------------------------------------------------------------------------------------
Citus 10.0.3 on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
(1 row)
4/5時点で提供されているDockerイメージはPostgreSQLが13.2、Citusは10.0.3となっている。
これだけでSingle NodeなCitusとしては動いているわけだが、データも何もないと参考にならない。という訳で、色々とデータをセットアップしてベンチマークなどを掛けてみる。
pgbenchしてみる
まず、pgbenchで初期化して上記のCitus 10にデータをセットアップする(適当に1000万件ほど)。
# 1,000万件のデータを生成
$ pgbench -i -s 100 -h localhost -U postgres postgres
# テーブルサイズを確認
$ psql -U postgres -h localhost -d postgres
postgres=$ SELECT relname AS "relation",pg_size_pretty(pg_relation_size(C.oid)) AS "size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
ORDER BY pg_relation_size(C.oid) DESC
LIMIT 10;
relation | size
-----------------------+---------
pgbench_accounts | 1281 MB
pgbench_accounts_pkey | 214 MB
pgbench_tellers | 48 kB
pgbench_tellers_pkey | 40 kB
pgbench_branches_pkey | 16 kB
では、次にベンチマークを掛けてみる。
# ベンチマークを取ってみる
$ pgbench -c 2 -T 30 -h localhost -U postgres postgres
Password:
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 1
duration: 30 s
number of transactions actually processed: 8694
latency average = 6.907 ms
tps = 289.566954 (including connections establishing)
tps = 289.654332 (excluding connections establishing)
もちろん、extensionが入ったPostgreSQLなのでpgbenchも普通に動く。
この時点ではCoordinatorでCreate Tableをしただけなので、先ほど紹介した3+1のテーブルのうち、Local Tableとしてpgbench向けのテーブルが作成されている。
もう一つ、このデータで集計系SQLの実行計画を比較するためにそれも取得しておこう。
postgres=$ explain analyze select aid % 5,sum(abalance) from pgbench_accounts where aid < 10000 group by aid % 5;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=567.43..701.43 rows=10720 width=12) (actual time=5.089..5.148 rows=5 loops=1)
Group Key: (aid % 5)
Batches: 1 Memory Usage: 409kB
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.43..513.83 rows=10720 width=8) (actual time=0.018..2.925 rows=9999 loops=1)
Index Cond: (aid < 10000)
Planning Time: 0.146 ms
Execution Time: 5.261 ms
(7 rows)
これも特筆すべきことはない、通常のPostgreSQLクエリである。
Distributed Tableを試す
では、次にSingle NodeでDistributed Tableを使ってみよう。いわゆるパーティション・テーブルに近い構成となるが、pgbenchや先ほどの実行計画には変化があるだろうか。
通常のテーブルからDistributed Tableに変換するのは簡単で、create_distributed_table(テーブル名, Distribution Column)のファンクションを使うだけである(なお、1000万件のデータがあるので数分掛かる)。
# Distributed Tableへの変換
postgres=$ SELECT create_distributed_table('pgbench_accounts', 'aid');
NOTICE: Copying data from local table...
NOTICE: copying the data has completed
DETAIL: The local data in the table is no longer visible, but is still on disk.
HINT: To remove the local data, run: SELECT truncate_local_data_after_distributing_table($$public.pgbench_accounts$$)
create_distributed_table
--------------------------
(1 row)
# truncate_local_data_after_distributing_tableも実行して容量確保
postgres=$ SELECT truncate_local_data_after_distributing_table('public.pgbench_accounts');
truncate_local_data_after_distributing_table
----------------------------------------------
(1 row)
# ついでにReference Tableも作っておく
postgres=$ select create_reference_table('pgbench_branches');
NOTICE: Copying data from local table...
NOTICE: copying the data has completed
DETAIL: The local data in the table is no longer visible, but is still on disk.
HINT: To remove the local data, run: SELECT truncate_local_data_after_distributing_table($$public.pgbench_branches$$)
create_reference_table
------------------------
(1 row)
# Shardの状況確認
postgres=$ select * from citus_shards;
table_name | shardid | shard_name | citus_table_type | colocation_id | nodename | nodeport | shard_size
------------------+---------+-------------------------+------------------+---------------+-----------+----------+------------
pgbench_accounts | 102008 | pgbench_accounts_102008 | distributed | 1 | localhost | 5432 | 41926656
pgbench_accounts | 102009 | pgbench_accounts_102009 | distributed | 1 | localhost | 5432 | 42024960
pgbench_accounts | 102010 | pgbench_accounts_102010 | distributed | 1 | localhost | 5432 | 41910272
pgbench_accounts | 102011 | pgbench_accounts_102011 | distributed | 1 | localhost | 5432 | 41967616
pgbench_accounts | 102012 | pgbench_accounts_102012 | distributed | 1 | localhost | 5432 | 42065920
-- 途中略
pgbench_accounts | 102039 | pgbench_accounts_102039 | distributed | 1 | localhost | 5432 | 41984000
pgbench_branches | 102040 | pgbench_branches_102040 | reference | 2 | localhost | 5432 | 8192
(33 rows)
ここから分かるのは以下である。
- citus_table_typeは
distributed、またはreference。 - Distributed Tableのcolocation_idは全て
1、つまり単一ノードに全シャードが格納されている。 - referenceのcolocation_idは
2、Distributed Tableとは異なっている。
(コラム)CitusのデフォルトはHash Sharding
Distributed Tableの作成に使ったcreate_distributed_table()には、distribution_typeのオプション引数が存在する。このdistribution_typeにはappend/hashのどちらかが指定可能で、hashがデフォルトとなっている。
appendのオプションは時系列データなどで使われる特殊なdistribution_typeと位置付けられており、その使い方はこちらのドキュメントに記載がある。
なお、過去にShardingの手法としていくつかのHash ShardingとRange Shardingを紹介したが、範囲検索を重視してRange Shardingを選択する分散SQLデータベースが多い中、CitusのHash採用は正直意外であった。
Citusにpgbenchをかけてみる
データは先ほどと同じ1000万件で、Distributed TableとReference Tableに一部テーブルタイプを変えたもので、pgbenchを実行してみる。
# Citusに対してpgbenchの実行
$ pgbench -c 2 -T 30 -h localhost -U postgres postgres
Password:
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 1
duration: 30 s
number of transactions actually processed: 8597
latency average = 6.987 ms
tps = 286.231689 (including connections establishing)
tps = 286.327216 (excluding connections establishing)
これも問題なく動作する。パフォーマンス上の違いも今回環境ではほぼ差異が見えていない。pgbenchで実行されるデフォルトの処理内容はこちらのドキュメントに記載されているが、ポイントクエリでかつ多重度も低い状況ではShardingのメリットはなく、特異な遅延も発生していない。
そして、先ほどと同様の集計クエリを投入した際の実行計画は以下のようになる。
# 集計クエリの実行計画を確認
postgres=$ explain analyze select aid % 5,sum(abalance) from pgbench_accounts where aid < 10000 group by aid % 5;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=500.00..503.00 rows=200 width=12) (actual time=64.565..64.570 rows=5 loops=1)
Group Key: remote_scan."?column?"
Batches: 1 Memory Usage: 40kB
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=12) (actual time=64.466..64.493 rows=160 loops=1)
Task Count: 32
Tuple data received from nodes: 494 bytes
Tasks Shown: One of 32
-> Task
Tuple data received from node: 20 bytes
Node: host=localhost port=5432 dbname=postgres
-> HashAggregate (cost=39.45..43.41 rows=317 width=12) (actual time=0.531..0.535 rows=5 loops=1)
Group Key: (aid % 5)
Batches: 1 Memory Usage: 37kB
-> Index Scan using pgbench_accounts_pkey_102022 on pgbench_accounts_102022 pgbench_accounts (cost=0.42..37.86 rows=317 width=8) (actual time=0.023..0.417 rows=325 loops=1)
Index Cond: (aid < 10000)
Planning Time: 0.270 ms
Execution Time: 0.578 ms
Planning Time: 1.135 ms
Execution Time: 64.639 ms
(19 rows)
実行計画は大きく変わっている。Citus AdaptiveのCustom Scanが行われ、リモートノード(今回はlocalhostだが)でのクエリ実行がTask内で行われている様子が見て取れる。
特筆すべき事項として、Citusではデフォルトで32のシャードを生成してレコードを分散するが(それが実行計画中のTask Count: 32)、先ほど述べたようにHash Shardingとなるため、範囲検索において全てのシャードにアクセスする必要が出てくる。これは分析クエリ実行時のデメリットになるものと思われる。
なお、実行計画を先ほどのものと詳細に比較すると、Task以降の単一Shard内の実行計画はDistributed Tableにする前と同一であることが分かる。
実行計画の詳細な読み方はCitusのドキュメントなどで説明されている。
Undistribute Tableで元に戻す
Distribute TableやReference Tableを通常のテーブルに戻すには、undistribute_table(テーブル名)のファンクションを使う。こちらも格納されたデータ量に応じた時間がかかる。
# undistribute_tableでDistributed Tableを元に戻す
postgres=$ select undistribute_table('pgbench_accounts');
NOTICE: creating a new table for public.pgbench_accounts
NOTICE: moving the data of public.pgbench_accounts
NOTICE: dropping the old public.pgbench_accounts
NOTICE: renaming the new table to public.pgbench_accounts
undistribute_table
--------------------
(1 row)
# Reference Tableの戻しも同様に行う
postgres=$ select undistribute_table('pgbench_branches');
NOTICE: creating a new table for public.pgbench_branches
NOTICE: moving the data of public.pgbench_branches
NOTICE: dropping the old public.pgbench_branches
NOTICE: renaming the new table to public.pgbench_branches
undistribute_table
--------------------
(1 row)
# 当然、citus_shardsには何もなくなる
postgres=$ select * from citus_shards;
table_name | shardid | shard_name | citus_table_type | colocation_id | nodename | nodeport | shard_size
------------+---------+------------+------------------+---------------+----------+----------+------------
(0 rows)
Citus Columnarを試してみる
では、次にCitus 10の新機能であるColumnar Storageを試してみよう。
これもalter_table_set_access_method(テーブル名, Access Method名)の関数を実行するだけで変換ができる。
# Columnarに変換する前にHeapでサイズを確認
postgres=$ select pg_size_pretty(pg_total_relation_size('pgbench_accounts'));
pg_size_pretty
----------------
1495 MB
(1 row)
# テーブルをColumnarへ変換する
postgres=$ SELECT alter_table_set_access_method('pgbench_accounts', 'columnar');
NOTICE: creating a new table for public.pgbench_accounts
NOTICE: moving the data of public.pgbench_accounts
NOTICE: dropping the old public.pgbench_accounts
NOTICE: renaming the new table to public.pgbench_accounts
alter_table_set_access_method
-------------------------------
(1 row)
# Access Methodがcolumnarに変わったことがわかる
postgres=# \d+ pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------------+-----------+----------+---------+----------+--------------+-------------
aid | integer | | not null | | plain | |
bid | integer | | | | plain | |
abalance | integer | | | | plain | |
filler | character(84) | | | | extended | |
Access method: columnar
Options: fillfactor=100
# Columnar返還後のテーブルサイズを確認
postgres=$ select pg_size_pretty(pg_total_relation_size('pgbench_accounts'));
pg_size_pretty
----------------
35 MB
(1 row)
テーブルをColumnarに変換すると、1,495MBから35MBと大幅にサイズが減少し圧縮が効いていることが分かる。
では、この状態で先ほどの簡単な集計クエリを実行してみよう。
# Columnarに対して、
postgres=$ explain analyze select aid % 5,sum(abalance) from pgbench_accounts where aid < 10000 group by aid % 5;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=27180.92..27183.42 rows=200 width=12) (actual time=53.313..53.316 rows=5 loops=1)
Group Key: (aid % 5)
Batches: 1 Memory Usage: 40kB
-> Custom Scan (ColumnarScan) on pgbench_accounts (cost=0.00..10514.26 rows=3333333 width=8) (actual time=0.485..51.248 rows=9999 loops=1)
Filter: (aid < 10000)
Rows Removed by Filter: 370001
Columnar Chunk Groups Removed by Filter: 962
Planning Time: 0.202 ms
Execution Time: 53.423 ms
(9 rows)
こちらも大きく実行計画が変わり、ColumnarScanのCustom Scanが行われている。
また、見慣れない用語としてColumnar Chunk Groups Removed by Filterというものが登場している。この用語についてはこちらの記事で解説されているが、一定範囲のデータが格納された列をChunkといい、このChunk単位で圧縮されて最小値/最大値が保持されている。クエリ実行時にWHERE句がこの最小値/最大値にマッチしない場合には解凍も行わずに読み飛ばす処理が行われている。これがColumnar Chunk Groups Removed by Filterであり、読み飛ばされたChunk Groupの数が表示されている。
今回のような小規模なテーブル(列数の少ないテーブル)では、HeapとColumnarの差が現れず、むしろインデックスの使えないColumnarのレスポンスが悪い。上述の記事にあるように列数が非常に多く(100列以上)、レコード数も多いケース(5,000万件)ではColumnarの利点が現れている。
なお、通常のHeapとColumnarを混合したハイブリッドなテーブルも試すつもりだったが、今回は時間の都合で割愛する。
現時点でのCitus Columnarの制約
Citus 10.0.3の時点でColumnar Storageにはいくつもの制約がある。
- UPDATE/DELETEが使えない
- Indexが使えない
- logical replication、logical decodingに対応していない
基本的にレコードはINSERTによる追記のみ、削除や更新は全レコードの洗い替えとなる。その他にも多くの制約があるため、利用時にはドキュメントを十分に確認する必要がある。
まとめ
ここまで見てきたように、Citus 10ではこれまでのSharding用途だけでなく、単一DBサーバとしてもColumnar Storageの機能を持つなど、PostgreSQL拡張として新たな可能性を持つ。
また、今回発表されたSingle Nodeでの利用オプションはCitus Dataが主張するscale-out readyとしての用途はもちろん、CI向けに簡易に構成可能なデータベースインスタンスとして利用できるだろう。これまでCitus向けのDDLなどは複数ノードを準備しクラスタを構成しておく必要があったが、今回のSingle Nodeは単一コンテナでテスト用途などをサポートする。
こうしたVersion10の新機能は、現時点ではAzure Hyperscale(Citus)には取り込まれていないが、おそらく近いうちに対応され、マネージドサービスとして使えるようになるはずである。
その際には自動スケールアウトなどと組み合わせて、より使いやすい分散SQLデータベースとなることが予想されるので楽しみに待ちたいところである。
Discussion