商業登記簿APIを公開しました
この記事は、商業登記簿APIについての宣伝を含みます。
なぜAPIが必要なのか
法人との商取引を始める前に取引先の基本的な情報を収集し、リスクを確認をすることは非常に大切です。
取引しようとしている法人が本当に存在するのか、代表者は誰かといった基本的な事項を取引相手からの申告のみに頼ることは危険なので、公開情報を使って確認する必要があります。

日本では、法人の基本的な情報は商業登記簿(以後登記簿とする)として登記することが義務付けられていて、法務局が管理をしています。
法務局に足を運んで手数料を支払えば、取引をする相手の登記簿を取得することができます。
オンラインでも登記簿提供サービスに利用申請をした上で手数料を払うことで取得することができます。
登記簿には、法人名、法人住所、資本金、代表者氏名、取締役氏名などの重要な情報が記載されていますが、取得できる形式は紙かPDFのみになっており、
登記簿を利用した業務のデジタル化への障害となっています。
また、登記簿を読むためには一定のスキルが必要です。
法人の破産や精算を見逃したり、法人格や資本金を正確に読み取ったりできなければ、単に危険な取引を行ってしまうだけではなく、
犯罪収益移転防止法や独禁法、下請法などの法令に違反して事業存続に対するリスクとなることもあります。
多くの金融機関や取引先の多い会社では登記簿を使った取引先の確認を行うための部署が存在し、専門の人員を配置しています。
社会のいたるところで非効率な業務を強いられていることと登記簿解析を人の目に頼っていることの2つの課題を解決するために、
法人番号をキーとして登記簿PDFを自動で取得し、さらにPDFを解析した結果を構造化して返すAPIを開発しました。
この記事では、APIの仕組みについて解説します。
また、将来的なスケールを見越したうえで、ランニングコストをできるだけ下げるための技術選定についても紹介します。
速習商業登記簿
この章では、そもそも登記簿を使って何を確認したいのか、データで取得するうえで何が難しいのかを理解することを目指します。
最重要の3要素
商業登記簿においてもっとも重要な3つの要素は法人名、法人住所と代表者氏名です。
法人名と法人住所は法人の実在性を確認するために利用します。
取引をしようとしている相手方の法人が実際には存在しなかったというリスクを防ぐことができます。
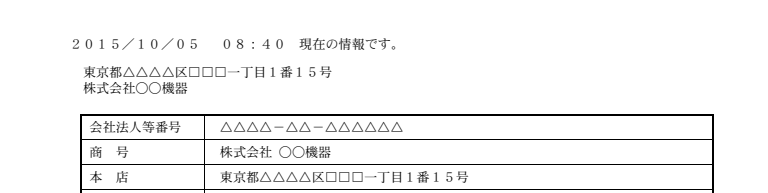
通常、法人名と法人住所は登記簿の中だけでなく枠外にも最新の値が出力される仕様になっています。
後述する変更登記を気にする必要がないこと、住所が長くても改行されないことから、簡単に抽出することができます。
代表者氏名の確認は登記簿を取得する本当の理由です。
実は国税庁の法人番号公表サイトを利用すると、法人番号から法人名と法人住所は無料で確認することができます。
実務上、このサイトを利用して代表者氏名の確認をせずに取引先確認を済ませている場合も多いようです。
それでも手数料を払ってまで登記簿を取得する意味は、代表者氏名が登記簿を確認しないとわからないことにあります。
取引をしようとしている法人の代表者が、反社会的勢力であったり、過去に犯罪歴がある場合には取引のリスクが高いといえます。
また、国際的な制裁対象となっている場合に、そのような法人との取引を開始してしまうと自分の法人も制裁対象になってしまうリスクもあります。
そのようなリスクを回避するためには、登記簿で代表者氏名を確認してリスクデータベースや制裁対象リストと照合して確認を行うべきです。
破産と解散
法人の破産と解散も避けては通れないテーマです。
なぜなら、破産手続きがすでに開始されていたり、解散されている事実が登記簿に登記されている場合、取引しようとしている者はその事実を知っているとみなされるからです。

難しいポイント
登記簿を解析して代表者を決定するうえで、法人格と変更登記がもっとも難しいポイントなので、簡単に解説します。
法人格
ある組織が株式会社や一般社団法人などの法人格を持っているとき、その法人は法律上の権利・義務の主体となることができます。
つまり、その法人が契約を行ったり訴訟を起こしたりすることが可能になります。
法人格にはとても多くの種類がありますが、法人格は登記簿に専用の項目が設けられないため、法人名から抽出する必要があります。
現在APIが対応している法人格の種類を以下に列挙します。
# 現在APIが対応している法人格の種類
株式会社
有限会社
合同会社
合資会社
合名会社
特定目的会社
協同組合
労働組合
森林組合
生活衛生同業組合
信用金庫
商工会
公益財団法人
農事組合
宗教法人
管理組合法人
医療法人
司法書士法人
税理士法人
社会福祉法人
一般社団法人
一般財産法人
一般財団法人
NPO法人
特定非営利活動法人
法人格を抽出しないと代表者が正確にわからないケースがあります。
たとえば、合資会社の場合には無限責任社員が代表者となったり、特定目的会社、有限会社では取締役が代表となる場合があります。
一方で、株式会社では取締役としてのみ登記されている役員が代表者となることはないので、取締役の役員を抽出したときに、代表者と扱ってよいのかは法人格を参照しないと決定できません。
このように、代表者を正確に判定するためには、法人名から抽出した法人格を使って条件分岐を実装する必要があります。
打ち消し線
登記簿の解析でもっとも難しい点は、登記されている役員が現在も有効であるとは限らない点です。

上の画像のように、有効ではなくなった登記には下線が引かれます。法人には、役員に変更があった場合に変更登記を行う義務があります。
しかし、下線が引かれた次の登記で同じ役員が登記される(重任)ケースも多いです。
そこで、基本的な戦略を「各行を独立な登記事項として扱い、下線があれば無効であるとする」として解析を実装しました。
# 構造化された役員情報
{
{役職: 代表取締役, 氏名: 乙野次郎, 登記日: 平成27年4月1日, 辞任日: 平成29年4月1日, 有効: false},
{役職: 代表取締役, 氏名: 乙野次郎, 登記日: 平成29年4月1日, 辞任日: , 有効: true}
}
解析結果はこののようなデータ構造となり、有効な値の中から代表者を探すことでうまく解析することができました。
ざっくりフロー図
登記簿そのものについて詳しくなったところで、登記簿APIが行っていることを解説します。
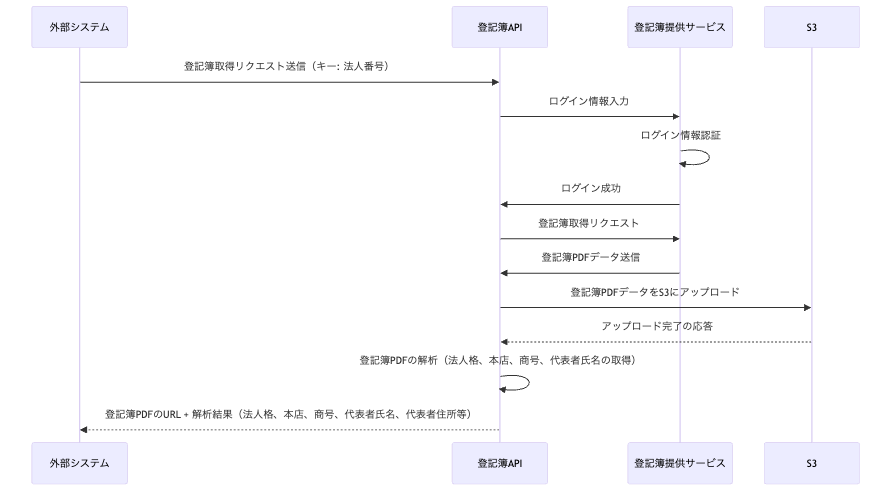
細かい部分を省略していますが、システムのフロー図は@{ryuyama3}のようになります。
APIはリクエストとして法人番号を受け取り、登記簿提供サービスから登記簿PDFを取得します。
登記簿提供サービスはAPIを提供していないので、APIはリクエストを受けた度にログインをして法人番号をフォームに入力して請求、PDFをダウンロードする必要があります。
また、登記簿提供サービスは、ログイン後の画面遷移時にRefererやセッション作成時に発行するトークンの検証を行っているため、
Refererを毎回適切に設定し取得したトークンを引き回す必要があります。
この一連の処理を、PuerkitoBio/goqueryパッケージを利用して実現しています。
登記簿PDFを取得した後は、登記簿PDFデータをファイルIDを付与したうえでAmazon S3にアップロードします。
そして、署名付きURLを発行してAPIのレスポンスに含めます。
同時に、自作の登記簿解析パッケージを利用して登記簿から情報を抽出し、これもレスポンスに含めます。
API仕様
より詳細な実装を知りたい方向けにAPI仕様を解説します。
登記簿APIは、実際にはgettoukiboと命名しました。
リクエストパラメータとして13桁の法人番号を受け取り、桁数、チェックサムなどのバリデーションをします。
法人番号のバリデーションには自作の法人番号パッケージを利用しています。
そして、レスポンスは以下のように定義しました。
パラメータ 型 説明
is_charged bool 課金されたか
published_at timestamp API呼び出し時刻
cache_expires_at timestamp キャッシュ期間
pdf_name string PDFファイル名
file_id string ファイルID
houjin_number string 法人番号
toukibo_created_at timestamp 登記簿発行時刻
houjin_kaku string 法人格
houjin_name string 法人名
houjin_address string 法人住所
houjin_created_at string 法人設立年月日
houjin_bankrupted_at string 法人破産年月日
houjin_dissolved_at string 法人解散年月日
houjin_capital int 資本金
houjin_stock int 発行済み株式数
houjin_executive_names []string(現在有効な)役員氏名
houjin_representative_names []string(現在有効な)代表者氏名
houjin_created_at string 法人設立年月日
houjin_bankrupted_at string 法人破産年月日
houjin_dissolved_at string 法人解散年月日
houjin_continued_at string 法人継続年月日
レスポンスの例
Content-Type:"application/json"
{
"request_id": "018ecc69-d3b7-7ec9-8da8-e9a440300e2c",
"message": "[free] toukibo found in cache",
"is_charged": false,
"published_at": "2024-03-10T13:31:44.187994546+09:00",
"cache_expires_at": "2024-03-13T07:09:58.724351+09:00",
"signed_url": "https://xxxx"
"pdf_name": "0123012301234_20240309220958.pdf",
"file_id": "779243783f72659fe3b6",
"houjin_number": "0123012301234",
"toukibo_created_at": "2024-03-10T13:31:44Z",
"houjin_name": "株式会社近畿商事",
"houjin_kaku": "株式会社",
"houjin_address": "東京都Sample区Sample1丁目1番地1",
"houjin_capital": 200000000,
"houjin_stock": 20000,
"houjin_executive_names": [
"里井達也",
"壹岐正",
]
"houjin_representative_names": [
"壹岐正"
]
"houjin_created_at": "令和2年4月1日",
"houjin_bankrupted_at": "",
"houjin_dissolved_at": "",
"houjin_continued_at": "",
}
HTTPステータスコード
Code 説明
200 OK 処理が正常に完了しました
202 Accpeted 登記簿取得を他のリクエストで処理中です。
400 BadRequest 不正なパラメータです。
401 Unauthorized APIキーが正しくありません。
403 Forbidden 実行できないAPIが指定されました。
404 NotFound 入力された法人番号に対応する結果が存在しません。
429 TooManyRequests APIリクエスト量が制限されました。
500 InternalServerError システムに異常が発生しました。
503 ServiceUnavailable サービスが一時的に利用できません。
512 TeikyoSiteOutsideBusiness Hour 登記簿提供サイトの営業時間外です。
513 TeikyoSiteTemporaryUnavailable 登記簿提供サイトが一時的に利用できませんでした。
514 ToukiJiken 請求のあった会社・法人等は登記事件の処理中です。
516 AccountNotActive アカウントが無効です。
APIのタイムアウトは30秒に設定しています。
登記簿取得には30秒以上かかる場合には、リクエストがタイムアウトした後も非同期で登記簿取得処理を継続します。
登記簿取得処理が完了していない間に、同じユーザーが同じ法人番号に対して登記簿請求をリクエストした場合にはAccepted(202)を返し、
完了後に同じ法人番号に対して登記簿請求がリクエストされた場合には3日間のキャッシュから結果を返すことで、
同じ法人番号に対しての複数回のリクエストに対して冪等かつ一度しか登記簿を取得しないように設計しています。
インフラの話
さて、ここまで登記簿を取得するモチベーションや登記簿APIの仕様を説明してきましたが、どのようなインフラを使って実現するかも重要です。
今回は次の条件を前提に技術選定を行いました。
- 登記簿提供サービスが律速なので、それ以外の部分の実行速度は重要ではない
** 登記簿取得に早くて15秒程度かかる - 必要に応じて数倍~数十倍にスケールできること
- B2Bかつニッチなサービスなので、無限にスケールする必要はない
** ユーザー数はせいぜい100 - 可用性を損なわない範囲で金銭コストと運用コストの両方が安く済むことを重視
** 無料で何かを実現するための開発はしない - サービスにとってコアではない部分には時間をかけない
** OSSや既存のサービスを利用する
DBの選定
もっとも重要なのはDBの選定です。
安く済ませたければVPSでDBをホストすればよいのでしょうが、
設定に時間をかけたくないことと、不要なインシデントリスクを下げたいことからマネージドDBを条件にしました。
その結果、マネージドDBかつ安価だったDigital OceanのPostgreSQLを選択しました。
選択できる中ではシンガポールが一番近かったので選びましたが、AWSの東京リージョンのインスタンスと比べて、数百ミリ秒のレイテンシの改善の余地がありそうでした。
しかし、登記簿取得で数十秒かかってしまうことを考えると、このレイテンシは無視できることから妥協しました。
その後、サービスが軌道に乗ったことによりコストを掛ける判断をし、Vultr東京リージョンのDBへマイグレーションを行いました。
APIサーバーの構成
次に、リクエストを処理するAPIサーバーの構成について考えます。
1インスタンスでAPIをホストしてAPIのドメインをインスタンスのIPアドレスに紐づけるのが一番簡単な構成です。
しかし、登記簿解析にある程度のCPUリソースが必要なので、必要に応じてCPUリソースをスケールさせられる構成を考える必要がありました。
そこで、ロードバランサーの下にいくつかのインスタンスををぶら下げてクラスターを構成することを選びました。
これによって、インスタンスをロードバランサーの下に追加すればCPUリソースを簡単にスケールすることが可能になりました。
この判断の結果、ロードバランサーでTLS終端することでHTTPS化が非常に簡単になるというメリットもありました。
ロードバランサーにはCloudflare Load Balancerを選びました。無料で2サーバーまでロードバランサーにぶら下げることができる点が魅了でした。
そして、ロードバランサーの下にはさくらインターネットのVPSと自宅のPCにUbuntuをインストールしてしてぶら下げました。
ここでは、ロードバランサーと各サーバー間の通信にCloudflare Tunnelを利用しました。
通信を安全に行えることと、固定IPが振られていないサーバーもクラスターに参加させられることから採用しました。
同等の機能を提供するTailscale Funnelも良さそうでしたが、CPUリソース消費量が非常に大きく登記簿解析に影響が出てしまったため不採用としました。
ngrokも非常に有力でしたが、Cloudflare Tunnelで十分でした。
半年ほど運用した後、Cloudflare Load Balancerの仕様変更による障害が発生したため、Cloudflareの利用を取りやめました。さくらインターネットのインスタンスにnginxをインストールしてLBとして使っています。
ロギングと監視
ロギングと監視については、かなりの試行錯誤を行いました。
これは、非常に多くの選択肢が存在することと個人開発の範囲では無視されていることが多く、調べても知見がなかったことによります。
まず、筆者が業務でも利用しているDatadogを検討しました。導入はとても簡単でしたが課金体系が容赦なく、月に数十ドルの課金は不可避でした。
次に、PrometheusとGrafanaをVPSにインストールして試しました。
数ヶ月運用してみましたが、メトリクスの定義やダッシュボードの追加をする難易度が高いと感じました。
そして最後にNewRelicにたどり着きました。
当初はgolangのクライアントとても使いづらく選択肢から外していましたが、Log APIを直接叩いてログを送ればよいことに気が付きました。
機能がひととおり揃っていること、開発者が一人であるうちは無料であることから最終的に採用に至りました。
監視は、NewRelicの機能を利用してAPIのヘルスチェック用のエンドポイントへ毎分リクエストを行うことと、週次で登記簿取得を行いデグレを検知することの2つを行っています。
いずれかに問題が発生したときには、メールとDiscordへ通知が行われます。NewRelicではこのあたりの設定がとても簡単でした。
デプロイ
CDも重要なテーマではあるのですが、現状は手でデプロイをしています。
クラスターを構成する各インスタンスでは、supervisorctlを使ってAPIの実行バイナリをデーモン化して起動させています。
実行バイナリの作成にはgitとgolangのみインストールすればよいので、Ansibleやkubernetesの必要性は生じていません。
サーバーの台数が増えてきたら、mainブランチへのマージをトリガーにした自動デプロイなどを検討する必要があると考えています。
おわりに
登記簿取得のAPI化を実現するために、登記簿PDFを解析するパーサーの開発し、登記簿提供サービスからの自動での登記簿取得を達成したうえで、
APIとしてのあるべき仕様や運用について考えるのはとても根気のいるプロセスで、ここに至るまでに1年を要しました。
より詳細な製品紹介はこちらをご覧ください。
Discussion