質問応答モデルの性能の評価方法
はじめに
こんばんは。今回は、自然言語処理における質問応答モデルの性能の評価方法についてです。
前置き・前提
質問応答タスク
質問応答タスクは、文字通り、与えられた質問に回答するタスクです。
質問応答タスクには、いわば回答選択式のタスクと回答記述式のタスクがあります。今回の記事では、回答記述式、つまり自ら回答を生成するタスクを前提とします。
また、質問ごとに模範解答が1つだけ付いているものとします。
問題提起
質問応答モデルを用いると、与えられた質問に回答できます。ここで問題になるのは、回答結果をどのように評価するかです。ここでいう回答結果の評価は、つまるところ「回答結果と模範解答の類似度」の評価です。この類似度の評価において大事なのは、なるべく人的評価に沿った評価をすることです。
文書分類タスクに比べると本タスクは、出力内容(回答結果)の評価が難しいです。なぜなら、傾向として、明確な正解が特にないからです。これは本タスクだけでなく、機械翻訳や文書要約など生成系のタスク全般において言えることです。1つの模範解答があったとしても、それはある意味、「正解群」のうちの1つに過ぎないのです。
上記の問題提起のきっかけ
きっかけは、この問題について、重要性をだんだんと感じるようになったことです。というのも、この問題は質問応答タスクにとどまらないと思うようになったからです。
1つ例を出します。次の記事は、以前作成した、文書要約の評価指標QAGSに関する記事です。
『文書要約の評価指標QAGSにおいて、2種の回答の類似度をどう測るか』
https://zenn.dev/ty_nlp/articles/ee4e17b6191987
その記事を、ここでは「以前の記事」と呼ぶことにします。
以前の記事の中で書いたように、QAGSには、生成される質問ごとに2種の回答を生成して両者の類似性を評価するステップがあります。ここは、まさに先ほど提起した問題が直接関わってくるステップです。ここの評価がブレると、QAGS自体の質が悪化するおそれがあります。
他の例としては、マルチモーダルの領域であるVQA(画像質問応答)のタスクがあります。このところ、VQAに関する研究は盛んになっているようです。
以上の理由から、提起した問題は質問応答タスクにとどまらないと思いました。そこで、この問題を深く調査したいと考えました。
対象の言語
以前の記事と同様に、今回の記事においても対象の言語を日本語に絞ります。
相関係数
本記事では、最も一般的なピアソンの相関係数を指します。相関係数には他に順位相関係数などがあり、どれを選べばよいかも悩みますが、ひとまずピアソンの相関係数とします。
提起した問題に対する1つの答え
最適解ではありませんが、まずは自分の考える1つのシンプルな解を提示します。
それは、定番のBERTScoreを用いることです。BERTScoreでもって、類似度を評価することです。
ただ、ここでポイントなのが、BERTScoreの計算に用いるライブラリやモデルです。
ライブラリは、以前の記事の中で書いたものと同じです。すなわち、Hugging Faceのライブラリ「evaluate」です。
そしてモデルとして、Hugging Faceにアップされている「distilbert-base-multilingual-cased」というモデルを用います。
上の式は、これらのライブラリやモデルが前提ですのでご注意ください。
※参考(evaluateと「distilbert-base-multilingual-cased」モデル)
上の解を提示した理由
理由は、以下に説明する実験の結果に基づいています。
実験の設定内容
実験のおおまかな手順は次の通りです。
- 「2種の回答のペア、およびその人的評価(類似度)」のデータを複数準備する。
- いくつかのモデルごとに、各データのペアの類似度をBERTScoreでもって評価し、人的評価との相関を調査する。
上の1.のデータセットとして、簡易ですが次のものを作成しました。
| 回答A | 回答B | 人的評価 |
|---|---|---|
| 晴れ | 晴天 | 0.9 |
| 雨 | 雨だった | 0.9 |
| 固い | 堅固だ | 0.8 |
| エーデルワイス | 白いエーデルワイス | 0.8 |
| 返答 | 回答 | 0.8 |
| 机 | 机の上 | 0.7 |
| 東京 | 東京都東部 | 0.7 |
| 看板 | 看板がある。 | 0.7 |
| 絵 | イラスト | 0.7 |
| 皿 | 小皿 | 0.7 |
| 乗り物 | 新幹線 | 0.6 |
| 止まる | 立ち止まる | 0.6 |
| 野球 | ソフトボール | 0.6 |
| コーヒー | ホットコーヒー | 0.6 |
| 赤 | 赤と青 | 0.5 |
| 喫茶店 | 喫茶店が開店予定 | 0.5 |
| 機械 | コンピュータ | 0.5 |
| 看護師 | 医者 | 0.5 |
| 買う | 蛍光灯の購入 | 0.4 |
| 北アメリカ | 南米大陸 | 0.4 |
| 予定 | 不明 | 0.4 |
| 公園 | 遊ぶ | 0.4 |
| 普通 | 難解 | 0.3 |
| 動植物 | たんぽぽ | 0.3 |
| 公開 | 未公開 | 0.3 |
| 靴 | 靴ひも | 0.3 |
| 勉強 | 整頓 | 0.3 |
| 契約書 | 記入 | 0.2 |
| 多量 | 少ない | 0.2 |
| 日本語 | 英語 | 0.2 |
| 道 | 変更する。 | 0.1 |
| 扇風機 | 箱 | 0.1 |
ただし、ここでいくつか補足です。
- これは、2種の回答の類似度の人的評価についてよく知らずに、我流で作ったものになります。評価のしかたはあまり明確ではなく、結構感覚的なものです。
- より細かく言えば、2種の回答の類似度は質問内容に依存しますが、その点も特に考慮していないです。いったん簡易調査を済ませたいので、質問自体は作っていないです。
- データ数は32件であり、少ないかもしれません。より的確な評価を目指すなら、データをもっと作ったほうがいいです。
- 数値的な回答データの作成は控えました。試したところ、数値同士のBERTScoreは高くなりすぎる気がしたためです。数値同士の類似度の評価には、何かルールを導入したほうがいいかもしれません。
また、BERTScoreを計算するためのモデルとして、Hugging Faceにある次の3種類のモデルを比較していきます。
| 実験対象のモデル | URL |
|---|---|
| bert-base-multilingual-cased | https://huggingface.co/bert-base-multilingual-cased |
| distilbert-base-multilingual-cased | https://huggingface.co/distilbert-base-multilingual-cased |
| roberta-base | https://huggingface.co/roberta-base |
様々なモデルを指定して動かした結果、上の3種に絞りました。私のやり方が悪かっただけかもしれませんが、他のほとんどのモデルは、指定して動かしてみてもKeyErrorとなってしまいました。
また、以下は実験のサンプルコードです。Google Colabなら、このままセルにコピー&ペーストして実行するだけで動かせます。
!pip install -q evaluate
!pip install -q bert_score
import numpy as np
import pandas as pd
import evaluate
bertscore = evaluate.load("bertscore")
ls_set = [['晴れ','晴天',0.9],
['雨','雨だった',0.9],
['固い','堅固だ',0.8],
['エーデルワイス','白いエーデルワイス',0.8],
['返答','回答',0.8],
['机','机の上',0.7],
['東京','東京都東部',0.7],
['看板','看板がある。',0.7],
['絵','イラスト',0.7],
['皿','小皿',0.7],
['乗り物','新幹線',0.6],
['止まる','立ち止まる',0.6],
['野球','ソフトボール',0.6],
['コーヒー','ホットコーヒー',0.6],
['赤','赤と青',0.5],
['喫茶店','喫茶店が開店予定',0.5],
['機械','コンピュータ',0.5],
['看護師','医者',0.5],
['買う','蛍光灯の購入',0.4],
['北アメリカ','南米大陸',0.4],
['予定','不明',0.4],
['公園','遊ぶ',0.4],
['普通','難解',0.3],
['動植物','たんぽぽ',0.3],
['公開','未公開',0.3],
['靴','靴ひも',0.3],
['勉強','整頓',0.3],
['契約書','記入',0.2],
['多量','少ない',0.2],
['日本語','英語',0.2],
['道','変更する。',0.1],
['扇風機','箱',0.1]]
ls_model = ['bert-base-multilingual-cased',
'distilbert-base-multilingual-cased',
'roberta-base', ]
for model in ls_model:
print('★★★モデル「' + model + '」を用いた場合')
ls_score_human, ls_score_pred = [], []
print('・各データごとの人的評価、およびモデルによる評価')
for data in ls_set:
score_pred = bertscore.compute(predictions=[data[0]],
references=[data[1]],
model_type=model,
lang="ja")['f1'][0]
print(str(data[2]) + ',' + str(np.round(score_pred, 3)))
ls_score_human.append(data[2])
ls_score_pred.append(score_pred)
s_human= pd.Series(ls_score_human)
s_pred = pd.Series(ls_score_pred)
correl = s_human.corr(s_pred)
print('・相関係数')
print(str(np.round(correl, 3)) + '\n')
ここで大事なのは、下の図の赤枠のようにしてモデルを指定することです。
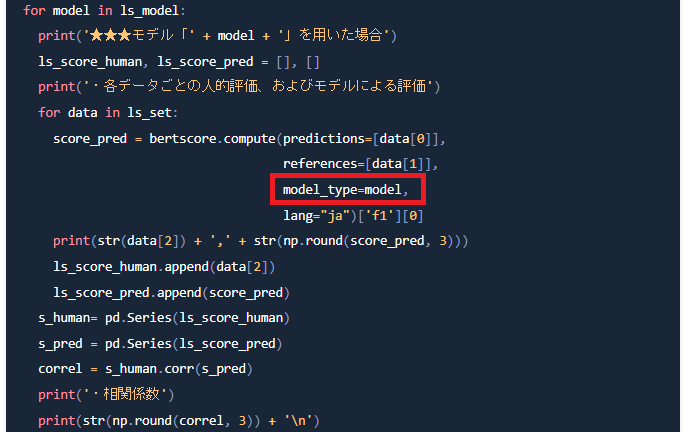
以前の記事では、この指定をしていませんでした(そこまで考えが及ばなかったので…)。
↑※その後2023/6/4(日)に、モデルを指定する形でコードを修正しました。
指定しない場合は、適切そうなモデルが自動的に割り当てられますが、特定のモデルを指定てきてないことに変わりはありません。
ちなみに何度か試したところ、モデルを指定しない場合はよく「bert-base-multilingual-cased」が割り当てられます。他のモデルが割り当てられたケースは、見たことがないです。断言はできませんが、その記事に載せた実験においても、自動的に「bert-base-multilingual-cased」が割り当てられた可能性が高そうです。
実験の結果
モデルごとの相関係数(人的評価とモデルによる評価)は、次のようになりました。
| 実験対象のモデル | 相関係数 |
|---|---|
| bert-base-multilingual-cased | 0.413 |
| distilbert-base-multilingual-cased | 0.576 |
| roberta-base | 0.486 |
明らかに、モデル「distilbert-base-multilingual-cased」の相関係数が高いです。
そのため、BERTScoreの算出にあたって、このモデルを基にするのが良いと考えました。
(参考)実験結果の補足
用いたモデルごとに、各評価を軸とした散布図を作成しました。モデルによる評価の値は、類似度として算出されたBERTScoreです。各点はそれぞれ、「2種の回答のペア、およびその人的評価(類似度)」のデータ1件に対応します。
これらを見ると、それぞれ、相関係数の値に沿った散布ぐあいになっていることを確認できます。
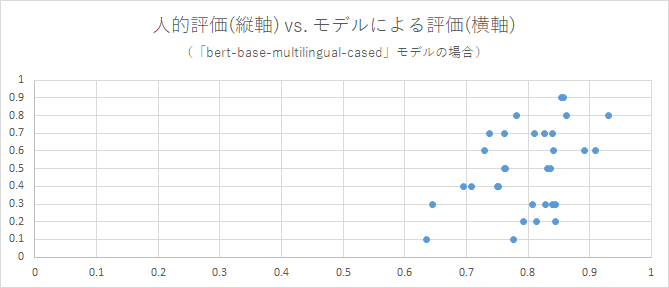
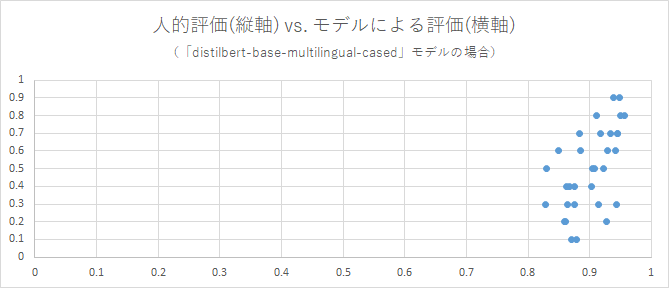
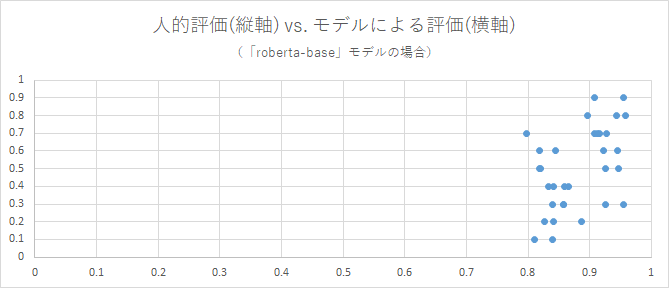
モデルによっては、各点の散布のしかたが特異です。ですが、相関係数を見ずにこれらの散布図から1つのモデルを選抜するとしても、「distilbert-base-multilingual-cased」が一番良さそうです。
回答結果のより良い評価方法
前述の評価方法でもそこそこ十分な気はしますが、さらに的確に評価するための案を提示して、本編を締めくくります。
案1:データセットを自らで作成
「2種の回答のペア、およびその人的評価(類似度)」のデータセットは、自ら作成したほうがいいです。どういう回答同士にどのくらいの人的評価をつけるべきかは、各自の持つタスクによるからです。
案2:得られたBERTScoreに修正をかける
これは以前の記事にて書いたような方法です。得られたBERTScoreに修正をかけます。回答同士が全然似ていない場合でも類似度が過大に評価されがちな場合には、有益な対策です。
ただ、散布図を見ると今回は特にそのような場合に当てはまるとは言い難いので、このままでもいいと思います。
※先ほどの散布図の再掲
案3:類似度の評価の際、複数のモデルを用いる
急に話が変わりますが、機械学習の1つにアンサンブル学習があり、さらにその1つにバギングがあります。代表例はランダムフォレストです。バギングでは、サブモデルなる分類器を複数構築します。そして各サブモデルごとの推論結果を集計し、最多数のラベルでもって推論結果とします。
分類タスクではなく回帰タスク(ラベルではなく数値の予測や推論)においても、似たようなものです。例としては、SVM回帰やランダムフォレスト回帰があります。回帰タスクの場合、各サブモデルごとの推論結果の数値の平均(あるいは加重平均)でもって、数値を推論します。
話を戻すと、この案はそれと同様です。1つ1つのモデルによる評価が人的評価と相関していれば、(相関自体は弱いとしても)各モデルによるBERTScoreの平均を取るのが一案です。平均をとることで、不相応なBERTScoreが出力されるのを避けやすくなります。この作用が、(わずかかもしれませんが)相関の度合いを強めます。
ただ、今回はこの案も採用しませんでした。というのは、モデルごとの相関係数を比べると、モデル「distilbert-base-multilingual-cased」が他のモデルに比べて十分大きかったからです。
※先ほどの表の再掲
| 実験対象のモデル | 相関係数 |
|---|---|
| bert-base-multilingual-cased | 0.413 |
| distilbert-base-multilingual-cased | 0.576 |
| roberta-base | 0.486 |
一番手のモデルに追従するくらいのモデルが他にあれば、この案は効果が出ますが、逆にそうでないと、この案のうまみは乏しいです。
その他の案
- 別のモデルの探索
今回の実験に用いたモデルの他に良いモデルがないかを探すことです。
- BERTScore以外の評価指標
BERTScore以外に、MoverScoreやFrugalScore、BaryScoreなどといった評価指標があるようです。モデルごとに各評価指標を試すことで、より人的評価との相関の高い「モデルと評価指標の組み合わせ」を発見できるかもしれません。
ちなみに、evaluateにFrugalScoreがあったので軽く試そうとしましたが、なぜかうまくいかなかったので見合わせました…。
- 模範解答
これは作業コストを考えると非現実的ですが、模範解答を増やしたり、模範解答ごとの人的評価を設定したりする手があります。すでにあるなら、活用したいところです。
終わりに
最後までご覧いただき、ありがとうございました。
Discussion