質問応答向けの新しいデータセット「QuALITY」(前編)
はじめに
こんばんは。今回はこちらの論文にて公開されている、質問応答向けの新しいデータセット「QuALITY」(Question Answering with Long Input Text, Yes!) について、記事を書きます。
QuALITY: Question Answering with Long Input Texts, Yes!
※本記事にある画像は、当論文より引用しています。
少し長くなるので、2回に分けて書きます。これは前編です。前編では、前置きと、QuALITY自体の情報、そしてQuALITYの作成過程について説明します。これらの内容は、主に当論文の2.Data Collectionに相当します。
※後編の内容を変更し、記事を作成しました。内容は、QuALITYのデータの実用性の検証です。
質問応答向けの新しいデータセット「QuALITY」(後編)
前置き
質問応答
質問応答は、文字通り質問に対して答えるタスクであり、自然言語処理のタスクの一種です。
自然言語処理に限らずAIの世界において、構築したモデルの性能を検証する際、ベンチマークと称されるものがよく用いられます。ベンチマークは、テスト用のデータセットやタスク内容、評価指標などで構成されるものです。質問応答タスクの分野だと、SQuADが有名です。
長文に対する処理
このところ、自然言語処理において、比較的長い文章に関する研究が盛んになっていると感じています。たとえば、長文に対する処理を重視したモデルとして、2020年頃にLongformerやBigBirdというモデルが出てきました。また2021年には、LongT5というモデルも出てきました。
おそらく、以前に比べて長文処理の需要が大きくなったのだと思います。短文に比べると、長文の処理は人間にとってだいぶ大変ですし。
長文に対する処理がどれほど求められるのかは、言語タスクの種類によって異なります。しかしおそらく質問応答タスクにおいても、長文に対する処理は興味深いところなのではないかと思います。
QuALITYの有益性
その点、今回たまたま知った当論文を読むと、このデータセットQuALITYに有益性を感じました。具体的には次の事柄です。
・全体的に長文であること
・正解するために、文章をしっかり読む必要があること
・徹底的なチェックと選定に裏付けられた、データの質の高さ
詳しくは、これから述べていきます。
QuALITY自体の情報
まずはQuALITYをイメージしやすくするために、QuALITY自体の大まかな内容を説明します。
データの例
QuALITYにあるデータの例は、下のようなものです。一見して想像するように、QuALITYは回答選択式の質問応答向けデータセットです。

上の表の各列の意味は、次のようになります。
| 列の名前 | 意味 |
|---|---|
| Source | 元とする情報源 |
| Dif. | 回答の難しさ |
| Question | 質問文 |
| Answer Options | 回答の選択肢 |
| Label | 正解 |
また、Sourceの値には次の3種類があります。
| Sourceの値 | 意味 |
|---|---|
| Gutenberg | 「Project Gutenberg fiction stories」というもの。主な内容は科学のフィクション。 |
| Slate | 「Open American National Corpus」というものから取得した漫画の記事。 |
| Misc | その他のノンフィクションのテキスト |
国語の文章問題で例えれば、Source(記事)は初めに与えられる文章、Questionは問い、Answer Optionsは選択肢です。
データ量
データ件数
次の通りです。
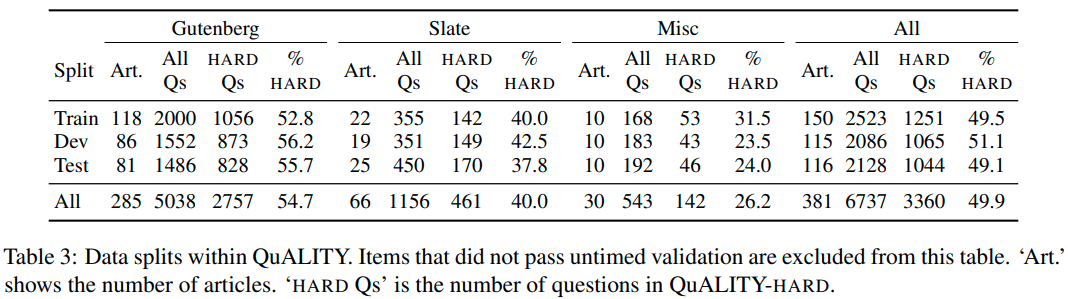
上の通り、質問の数は全部で6737個です。
Artは記事(Article)の数を指します。1つの記事に対し、最大で20個の質問が付随しています。
また、trainは学習用、devは検証用、testはテスト用のデータです。
文中の単語数
また、下の図は文中に含まれる単語の数の分布です。グラフが3つあり、左から順に記事、質問文、回答の選択肢についての、単語の数の分布が表されています。
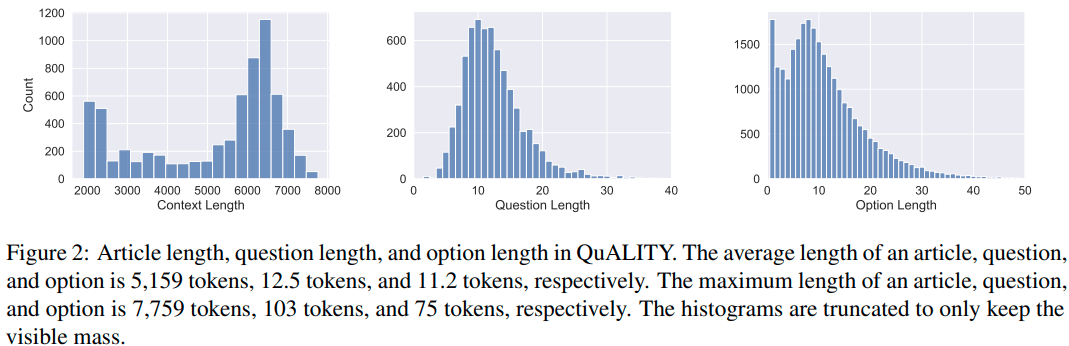
1記事あたりの平均的な単語数は、5,000~6,000程度です。参考までに言うと、当論文の1.Introductionの文章だけでも約630単語です(注釈や、figure、tableの説明文などは除く)。ですので、文章の長さとしては申し分ないと思います。
QuALITYの作成の過程
以上のように、QuALITY自体がどんなものかが少し見えてきました。特に、元となる文章(記事)が長文であることを確認できました。ですので、長文向けの質問応答モデルの性能を測りたいときにはこのデータセットは使えそうです。
しかし、併せてQuALITYの作成過程も押さえたほうが良さそうです。そうすることで、QuALITY自体に対する理解も深まります。特に重要なのは、QuALITYの中にある各質問文は、元となる記事をしっかりと読むことが求められるものとなっていることです。詳しくはこれから述べていきます。
大まかな過程
ラウンドを複数回繰り返します。1つのラウンドは、次のフェーズ(下の1,2,3)から成っています。
- 質問と回答(4種の選択肢)のペアの初期作成
- バリデーションその1(Speed Validation)
- バリデーションその2(Untimed Validation)
1つのラウンドでは、6~30個の記事が対象です。ラウンド内の各フェーズ1,2,3について、以下に説明を記載します。
1. 質問と回答(4種の選択肢)のペアの初期作成
22人の作業者が、各Source(前述のGutenbergなど)内の各記事に対し、質問と回答(4種の選択肢)のペアを作成します。
要点
これに関する要点は次の通りです。
・作業者はできるだけ、「各記事を全体的に読解しないと正解できないような質問(と回答)」を作ります。逆に、45秒程度の時間で正解できるような質問や、Ctrl+F的なやり方で手掛かりを手早く探して正解できるような質問は、なるべく作らないようにします(ここでいうCtrl+F的なやり方は、あくまでもたとえです。何かしらの方法で、特定の単語やフレーズを抽出することを意味します。)。
・1つの記事につき、担当する作業者は2人です。各作業者は別々に作業を行います。各作業者は、1つの記事につき質問と回答のペアを10個作成します。
・作成にあたっては、次のような画面を用います。

作業者が得た収入
作業者は平均的に、1つの記事分をこなすのに50分かかり、そのつど約17.54ドル(ボーナス含む)を得ました。これは時給換算すると、約21ドルです。
このフェーズに限りませんが、作業者は対価を得ます。作業の質が良いほど、ボーナスが増え、トータル的に多くの対価を獲得できます。この制度が、QuALITYの質を支えています。
収入面はQuALITYの作成過程とは本質的にあまり関係ないですが、興味深いところではあるので、併せて記述していきます。
バリデーションその1(Speed Validation)
ここまでは、質問と回答のペアの"初期"作成です。次にやるのは、作成した質問と回答のペアをチェックし、必要に応じて作成内容の修正や削除をしていく作業です。この作業をここではバリデーションと呼ぶことにします。バリデーションは45人の作業者が行いました。
バリデーションには2種類があり、最初にやるのはSpeed Validationというものです。このバリデーションにおいて作業者は、1つの質問につき45秒という時間制限の中で回答していきます。
このSpeed Validationの狙いは、作成した各質問が、前述の「45秒程度の時間で正解できるような質問」に相当していないかをチェックすることです(この秒数は作業者の人数と同じですが、たまたまにすぎないと思います。)。
要点
・1つの質問につき、回答する作業者は5人です。
・作業者は、複数のタスクに取り組みます。ここでいうタスクは、質問への回答です。1タスクあたりの質問数は10個です。なお、これら10個の質問の元となる記事はそれぞれ別物です。
・作業者は、各質問において、まず質問文と回答の選択肢を読みます。その後、記事が表示され、40秒の読解の時間が与えられます。40秒経ったら記事は消えます。その後、作業者は5秒以内に回答します。(1タスクあたりの質問数は10なので、この作業を10回やることになります)
・作業者は1つのタスクを終えると、報酬として2.25ドルがもらえます。さらに、正解した質問の数×0.2ドルが、ボーナスとしてもらえます。
・詳しくは割愛しますが、作成した質問を、別途定められた基準によってチェックします。基準を満たしていればその質問をHARDに、そうでなければEASYに割り当てます。すぐに答えられない質問ほど、HARD側のほうに多く含まれます。
・作成にあたっては、次のような画面を用います。

作業者が得た収入
作業者が1タスクあたりで平均的に得たボーナスは1.03ドルでした。なので、わずかな時間でも51.5%くらいの確率で正解できていることになります(1.03 / 0.2 / 10 = 0.515)。また、1タスクあたりのトータル所要時間は約11~12分だったようです。時給換算すると、ボーナス含めて約17ドルの収入です。
バリデーションその2(Untimed Validation)
次のバリデーションUntimed Validationは、正確性や明確性のチェックのための作業です。
各作業者は、複数のタスクをこなします。タスク1つ分は、1つの記事に対して作成した全20の質問に回答することです。
また、1つの質問に回答するたびに、その質問に関する次の3つの「質問」に回答します。

Q1の意訳:この質問は回答可能であり、かつ明確ですか?
Q2の意訳:この質問に正解するためには、どのくらいの量や範囲を読む必要がありますか?
Q3の意訳:正解から最も程遠いと思う選択肢はどれですか?
これらの「質問」は作成した質問文とは異なるため、鍵カッコでくくって区別をつけています。この「質問」はいわば、質問についての「質問」です。
同様に、「質問」に対する回答は「回答」と記述することにします。
要点
・trainの記事に対しては3人、devあるいはtestの記事に対しては5人の作業者が担当します。(ただ、元々どのようにしてtrain、dev、testの分類がされたのかは分かっていません。おそらくはランダムだと思います。)
・時間制限はないです。作業者は時間をかけて記事を読み、質問に回答ができます。
・1つのタスクを終えるたびに、6.5ドルの報酬が得られます。このバリデーションはQuALITYの質を左右する特に重要なものなのですし、作業自体も大変なので、報酬は比較的多くなっています。
・さらに、個々の質問において2つの条件を満たすと、ボーナスとして0.5ドルがもらえます。それらの条件の1つは、各作業者の回答のうち最もメジャーなものが、自分の回答と一致していることです。もう1つの条件は、各作業者のQ1の「回答」のうち最もメジャーなものが、自分のQ1の「回答」と一致していることです。
・Q1の「回答」の情報を用いて、最終的にQuALITYにその質問を入れるかどうか、ふるいにかけます。その具体的な基準は、Q1の「回答」のうち最もメジャーものが「回答可能であり、明確に答えられる」であるか否かです。もしそうであればその質問をQuALITYに入れ、もしそうでなければその質問は対象外とします。
作業者が得た収入
平均的に、1つのタスクの所要時間は約50~60分、1タスクあたりののべボーナスは8.13ドルだったようです。時間をかけたから不思議ではないですが、正解率は81.3%にもなることが分かります(8.13 / 0.5 / 20 = 0.813)。時給換算すると、ボーナス含めて約16ドルです。
また、前述のデータ件数からすると、最終的にQuALITYに取り込まれた質問の割合は約88.4%だったことが見てとれます(6,737 / 381 / 20 = 0.884)。この値の高さからすると、QuALITYの質の高さがうかがえます。なぜなら、質問を初回作成した時点ですでに回答可能で明確な質問が多そうであり、さらに回答不可能または不明確とされる質問をそぎ落としたからです。
1つのラウンドのまとめ
この図は、これまでのバリデーションの説明の内容が表されたものです。
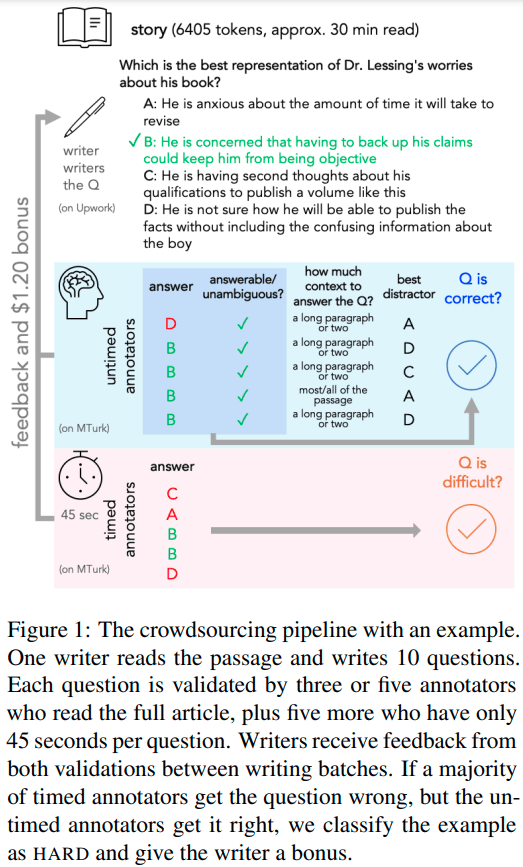
一番下のピンクのエリアが、Speed Validationです。質問ごとに45秒という時間制限の中で、5人の作業者が個々に回答します。
その上の水色のエリアは、Untimed Validationです。時間を十分に使って質問に回答し、その後その質問に関する3種類の「質問」に「回答」します。
全体的に、以上が1つのラウンドにおける作業です。すべての記事に対処するまで、ラウンドを繰り返します。
以上を経ることで、最終的な成果物であるデータセットQuALITYは、質問文も価値あるものになります。なぜなら、各質問文は記事に対する深い理解の求められるものだからです。長文の質問応答モデルの性能を測るとなると、そのほうが良いと思います。
トータルの収入
ちなみに、作業者ののべ収入金額を計算してみたら、約88万ドルにもなりました。こういう作業の費用の相場はよく知りませんが、普通に高額ですね。
また、フェーズごとの内訳は、質問作成が約24万ドル、Speed Validationが約22万ドル、Untimed Validationが約42万ドルです。Untimed Validationは1つ1つのタスクも重いので、この突出した金額はうなずけます。

終わりに
前編はここまでです。お読みいただき、ありがとうございました。
Discussion