画像生成AIセットアップ編
数年ぶりのWindows PCなので色々わからない。
ユーザーディレクトリーが勝手に決められて、変更しようとして失敗して初期化
初期化したら購入時と少し違う設定になっている気がするけど、まあ良いか・・・。
pip install antlr4-python3-runtime==4.9.3 --no-cache-dir
...
error: [Errno 2] No such file or directory: 'build\bdist.win-amd64\wheel\.\antlr4_python3_runtime-4.9.3-py3.10.egg-info\dependency_links.txt'
で挫折
一番簡単だという触れ込みのFooocusは、画面は表示されて生成中の表示にはなるが、いつまでたっても画像が生成されない。コンソールにはエラーが出力されている。
with safe_open(filename, framework="pt", device=device) as f:
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
ComfyUI動いた! 512x512なら数秒で作り放題。
チュートリアルをやっている https://comfyanonymous.github.io/ComfyUI_tutorial_vn/
DALL-E3ベースのBing Image Generatorではテキストも生成できるとのこと

Create the words "twk" using computer parts. There are many other parts in the background. High resolution. Realistic images. Surreal.
ComfUI.batを作ってショートカットをデスクトップに貼る。
@echo off
start cmd /c python main.py < nul
まだできていないことは、SDXLのワークフローの適用(モデル自体は利用済み)
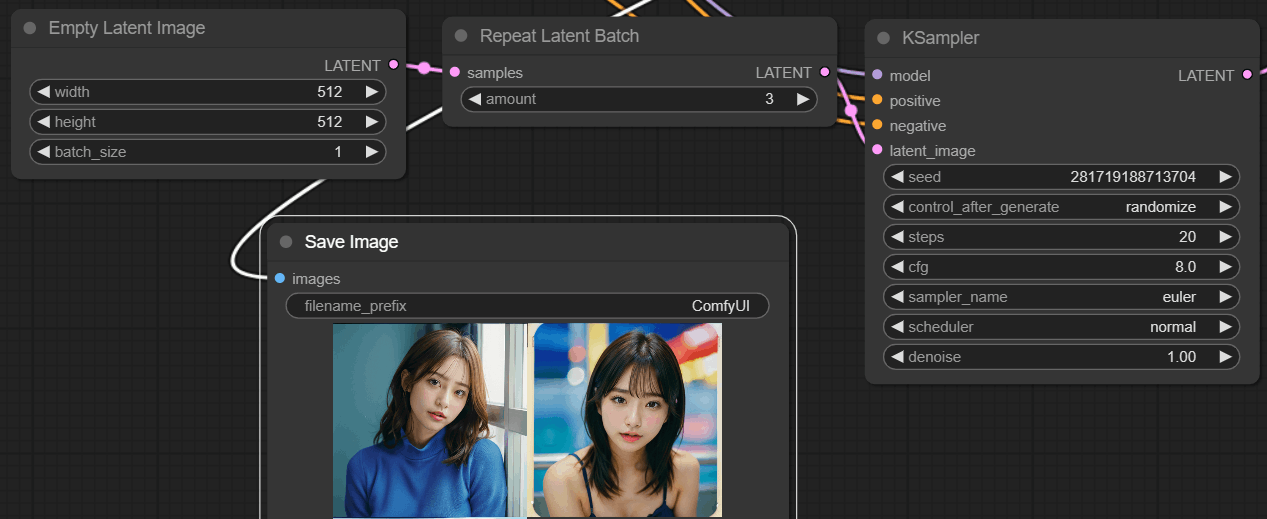
クオリティは調整が必要だとして、別の人の入力値を使うとそこそこそれっぽい画像は出る。



あとは、雰囲気やポーズの調整もできるが、そろそろチャットに移りたい。
全体的には良いのに足や指の数、目などが不自然になった時の対応
ポーズはこれ見てひな形をダウンロードして、必要に応じて編集したらうまく行った。
LoRAとは LoRAは結果をゆがめてしまう物が多いようだ。耳や口の不自然さを直すものがあっても良さそうな物だけど…。
暗い画像を作りたい時にはLoRAが良いみたい。LowRaとかLitとかがある。
いつの間にかWebUIのrun.batがエラーを出力するようになっていたので、インストールし直す。外出先で数ギガ単位のファイルをダウンロードしているけど大丈夫だろうか…。
xformersもTensorRTも入った。入れてしまえば非常に簡単。TensorRTの生成はモデルごとに行う必要がある。
Llama Cleaner非常に入れるのが簡単だし高速だったが、実写の指や耳などは難しそう。ゴミを消すとか、隠れそうな耳を完全に隠すとかはいけそう。