Microsoft Fabric Lakehouse を作成する


はじめに
この記事に書かれている内容は↓のMicrosoft Learnの記事を翻訳機能とあらゆる手段を使って学習した内容です。
最初から日本語で書かれているものとは違い凄く体力を使ったので誰かの役に立てば...と思いここに勉強ログを共有します...
自分用のメモのためキャプチャなどが雑なことお許しください...
「あれしたいときどうすればいいんだっけ...」の方はZennの目次機能を活かしてジャンプしてください。
ちなみにこの学習に半日かかりました...
記事の目安時間は30分と書いてあるのに...辛
==追記==
大元は「Microsoft Fabric のレイクハウスの概要」のトレーニングです。
「演習 - Microsoft Fabric Lakehouse でデータを作成して取り込む」の章で今回紹介している演習を行います。
データレイクハウスって何
図解だけ載せます。

データファイル用のデータレイクハウスを作成

「データの保管」までスクロールすると出てきます

適当に名前をつける

1分ほどたつと新しいレイクハウスが作成されます
Tablesフォルダ
レイクハウス内に保存されているテーブル形式のデータを格納する場所です。
データストレージ:Tablesフォルダには、構造化されたデータがテーブル形式で保存されています。これにより、データの効率的な保存と管理が可能です。
クエリと分析:このフォルダに保存されているテーブルデータは、SQLクエリやデータ分析の対象となります。データアナリストやデータサイエンティストがデータを操作しやすくなります。
データの変換:Sparkやデータフローを使用して、このフォルダ内のデータを変換することができます。これにより、データのクレンジングや加工が行われます。
つまり、「Tables」フォルダは、データレイクハウスの中核的な部分であり、データの保存、クエリ、分析、変換を行うための重要な役割を果たします。
Filesフォルダ
レイクハウス内でさまざまな形式のデータファイルを保存するための場所です。
データストレージ:
構造化データ(CSV、Parquet、ORCなど)や非構造化データ(テキストファイル、画像ファイル、ログファイルなど)を保存します。
データインポート:
外部ソースからデータをレイクハウスに取り込む際に、最初にこのフォルダにファイルをアップロードすることが多いです。これにより、データの集約と統合が容易になります。
データの前処理:
データ分析や変換を行う前に、生データを格納しておく場所として利用します。後でデータクレンジングや変換プロセスを適用することができます。
データ共有:
複数のユーザーやチームがデータを共有する際に、「Files」フォルダを利用して共通のデータリポジトリとして機能させます。
データアーカイブ:
過去のデータや使用頻度の低いデータをアーカイブするための場所としても利用できます。これにより、データの整理と管理が容易になります。
「Files」フォルダは、レイクハウスのデータ管理を効率化するための重要な部分です。異なる形式やタイプのデータファイルを一元的に管理することで、データ操作がスムーズに行えるようになります。

ファイルをアップロードする
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csvのデータをローカルに保存
dataフォルダ作成
レイクハウス エクスプローラーペインのFilesの3点リーダー>新しいサブフォルダー

dataフォルダーを作成

salesファイルをアップロード
レイクハウス エクスプローラーペインのdataの3点リーダー>アップロード>ファイルのアップロード

アップロード画面になるのでフォルダアイコンを押し、先ほどのSales.csvをアップロードする

アップロードが完了していることを確認して完了をクリック

salse.csvが表示されていることを確認

アップロードしたsalse.csvをクリックするとプレビューが見れます

ショートカットはここで使用できる
Microsoftは言います。「多くの場合、レイクハウスで操作する必要があるデータは、他の場所に保存されている可能性がある」と。
確かにそうかも...
今試しているレイクハウスのOneLakeストレージにデータを取り組む方法のほかにも、ショートカットを作成することもできます
fabricでいうショートカットとは
データを直接コピーすることなく、外部ソースのデータを参照して利用する方法
ショートカットを使用した場合のメリット
ショートカットを使うことで、データをコピーせずに直接利用し、効率的かつ安全にデータを活用することができるということです。これにより、リソースの節約やデータ整合性の確保が可能になります。
もう少し詳しく
オーバーヘッドの削減:
データをコピーする作業は時間がかかり、計算資源も消費します。ショートカットを使用することで、この「コピーに伴うオーバーヘッド」(無駄なリソース消費)を避けることができます。
データの不整合リスクの回避:
データをコピーすると、元のデータが更新された場合にコピーされたデータと不一致が発生する可能性があります。ショートカットを使うことで、常に最新のデータを直接参照できるため、この「データの不整合」(データが一致しない問題)を回避できます。
ショートカットの利用方法
Filesフォルダ配下に作成したフォルダの三点リーダーをクリック>新しいショートカット

そうするとダイアログボックスが出てくる...
(Microsoft Learnで試せるのはここまででした)

ファイルデータをテーブルにロードする
Microsoftはこう言います。
「エンジニアであればアップロードされたsalse.csvをApache Sparkを使用して直接Filesフォルダ内のデータを操作できる」
「だけど、データをSQLでクエリ実行できたら最高だよね?だからテーブルにデータをロードすることをおすすめするよん!」
だそうです。
ファイルデータをテーブルに読み込む方法
sales.csvの三点リーダーをクリック>テーブルに読み込む>新しいテーブル


ダイアログボックスが出てくるので、テーブル名をsalseに。
読み込みをクリック

読み込みが終わるの待つ😌

そうすると...Tablesにsalseテーブルが登場!

salseテーブルのデータが保存されている元のファイルを確認する
salseの三点リーダー>ファイルの表示

_delta_logが表示される


deltaってなに?
デルタテーブルは、大量のデータを効率的に管理し、信頼性を保ちながらデータの操作ができるようにするテーブル
デルタテーブルの特徴
-
ACIDトランザクションサポート: デルタテーブルは、Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、Durability(耐久性)を保証するトランザクションをサポートします。これにより、データの一貫性と信頼性が向上します。
-
スキーマの管理: デルタテーブルはスキーマエンフォースメントと進化をサポートしており、データの追加や変更に対して柔軟性があります。
-
時間旅行: 過去のデータバージョンにアクセスできる「タイムトラベル」機能があります。これにより、過去のデータ状態を参照したり、回復したりすることが可能です。
-
スケーラビリティ: 大規模なデータセットを効率的に管理および処理できます。
SQLでクエリ実行する
レイクハウスにテーブルを作成すると、そのテーブルに対してSQLクエリを実行できるようになります!
右上に注目!LakehouseからSQL分析エンドポイントに切り替えます。

新規SQLクエリをクリック

クエリエディタにSQL分を入力!
SELECT Item, SUM(Quantity * UnitPrice) AS Revenue
FROM sales
GROUP BY Item
ORDER BY Revenue DESC;

実行をクリック

🎉結果がでてきました!凄い!
各製品の合計収益が表示されています。

ビジュアルクエリを作成する
Microsoftはこう言います
「Power BIの経験を持つデータアナリストであればPower Queryのスキルを活かしてビジュアルクエリを作成できます」
しゃーない。ビジュアルクエリも試しましょう
ツールバーのvをクリック>新規のビジュアルクエリ

左にあるsalseテーブルをビジュアルクエリエディターペインにドラッグ

ドラッグしたらこんな感じ。

列の選択をする
列の管理のvをクリック>列の選択

検索ボックスにSalesと入力しSalesOrderNumberとSalesOrderLineNumberの2つを選択しOKをクリック

テーブルが二つのなりました!

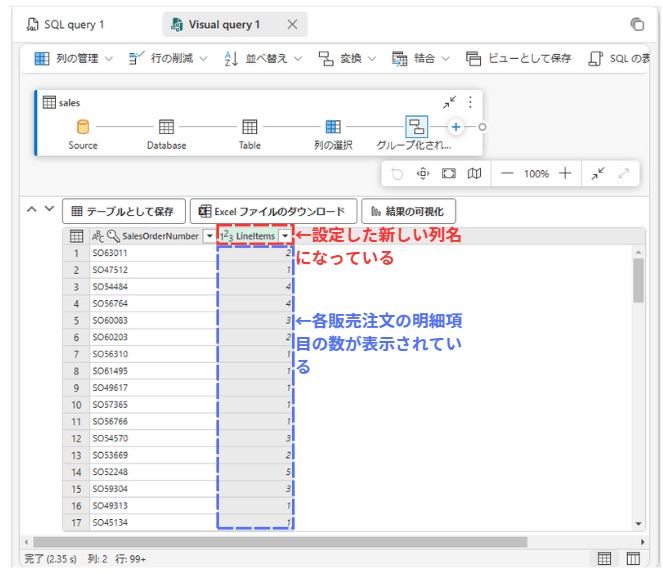
データをグループ化する
変換のvをクリック>グループ化

画像の内容に設定後、OKをクリック
- グループ化:
SalesOrderNumber - 新しい列名:
LineItems - 操作:
個別の値のカウント - 列:
SalesOrderLineNumber

完了すると...グループ化された表が!!
レポートを作成する
やっとここまできましたね~!!
作っていくぞ~~!💪
ツールバーでモデルレイアウトをクリック

すると、モデルスキーマが表示されます。

Microsoftが何か言っているのでお伝えします(他人事)
この演習では1つのテーブルで構成されていますが、実際の現場ではレイクハウスに複数のテーブルを作成し、それぞれをモデルに含めることになります。
そのあと、モデル内でこれらのテーブル間の関係を定義できます。
新しいレポートを作成
他に新しいレポートを作成する方法があると思います。。。
今回はこの手順で作るんだな~程度で(Learnにも説明ありませんでした)
報告タブに移動し、新しいレポートをクリック
(報告タブから行くことが分からず30分ほど苦戦した私...( ノД)シクシク…)  続行をクリック  Power BIの画面になりました🎉  右側のデータペインでsalseテーブルを展開して、ItemとQuantityの2つを選択します。 すると...レポートにテーブルが作成されました🎉  積み上げ縦棒グラフ`を選択してみたり...いろいろなビジュアルを試してみてください

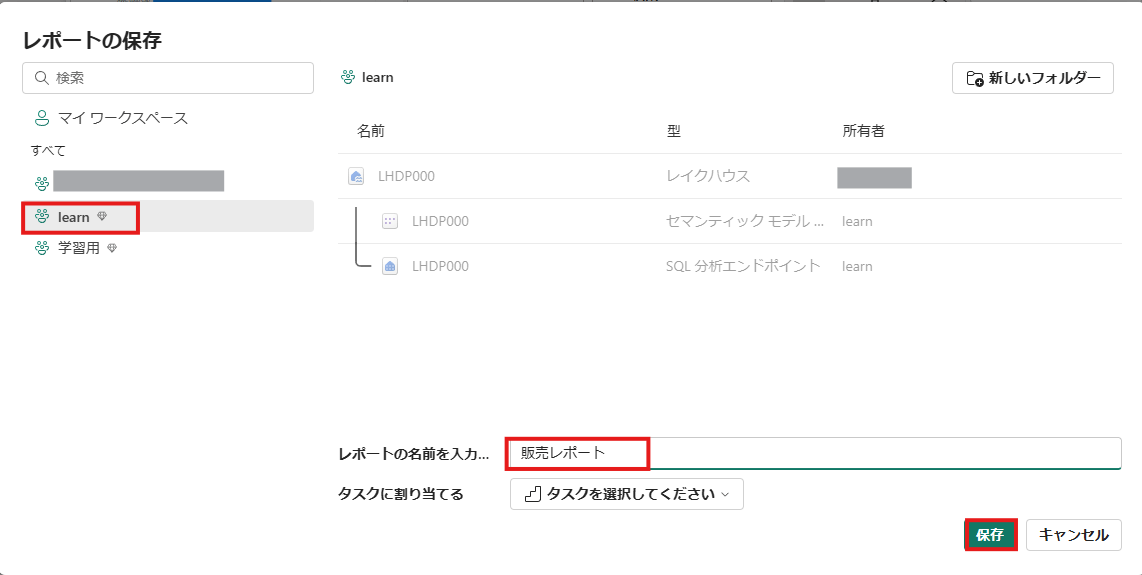
レポートを保存
ファイルのvをクリックして、保存をクリック

ワークスペースを選択し、名前を入力して保存をクリック
ワークスペースを削除する
左側のバーから今回のために作成したワークスペースを選択します。

ワークスペースの設定をクリック

少しスクロールにして このワークスペースを削除する をクリック

Discussion