アドベントカレンダー22日目を担当します!モデル開発チームの塩塚です。
本日は金曜日で、このままクリスマス突入ですね。そしてそのまま年末年始を迎えるこの時期は少しだけ楽をしたいですよね。
そんな我々にピッタリの機械学習リポジトリがあります。それがこちら Language Segment-Anything です。
公式リポジトリより引用
こちらのオープンソースプロジェクトは、画像とテキスト入力だけで物体検出・セグメンテーションをしてくれます。とても便利ですね。従来は、物体検出・セグメンテーションしたいときに、検出したいオブジェクトに対応したモデルを探して、探しても画像のサイズや画角によってはあまり上手に検出してくれなかったりして、ぱっと試すにも時間が必要でした。それがこのオープンソースではテキストを与えるだけです。しかも物体検出もセグメンテーションを同時に。
本記事では、Language Segment-Anything の仕組みと使い方を紹介し、最後に自分で使って面白かったものを紹介していきます。
仕組み
Language Segment-Anythingは2つのモデルを組み合わせることで実現されています。
Segment-Anything
一つは2023年4月にMeta社が発表したSegment Anything、通称SAMです。10億のマスクと11000枚の画像という大規模なデータセットで学習を行い、かなり細かくセグメンテーションしてくれます。こちらはデモページで簡単に試せますがとてもよいです。

Turingオフィスでのひとコマです。
上の例では画像中全てをセグメンテーションしていますが、任意のポイントを指定するとその領域だけをセグメンテーションできます。

左の棚の領域にカーソルを合わせるとそこだけセグメンテーションしてくれます。
つまり、SAMは画像全体か任意の領域を指定することでセグメンテーションを行ってくれます。加えて、論文を見るとテキストでもセグメンテーションを行うことができるようです。

SAMの論文(Segment Anything)より引用
あれ、SAMだけで当初の目的だったテキストによるセグメンテーションができてしまいました。皆さんSAMを使いましょう!
…で終わると早いのですが、公式の実装にはテキストによるセグメンテーションの例はなく、どうやらissueによるとテキストによるセグメンテーションは未リリースだそうです。

しかし、前述のようにSAMはセグメンテーションしたい領域の位置がわかればその領域をセグメンテーションすることができます。
GroundingDINO
そこで、登場するのが GroundingDINO です。GroundingDINO は、2023年5月に発表されたzero-shotで物体検出を行うことができるモデルです。下の例では dog と cake というテキストを与えるとそれらを物体検出しています。

公式リポジトリより引用
このように、GroundingDINO はテキストだけで画像中の物体を検出することが出来ます。
Language Segment-Anything
Language Segment-Anything はこれらの合わせ技です。まず、GroundingDINO によって物体検出を行い、その結果を SAM に渡すことでセグメンテーション結果を得ます。アイディアはとてもシンプルですね。
こちらは Language Segment-Anything の推論部分です。画像 (image_pil) とテキスト (text_prompt) を GroundingDINO に渡し、その結果 (boxes) をSAMに渡すことで最終的なセグメンテーション結果 (masks) を得ます。
def predict(self, image_pil, text_prompt, box_threshold=0.3, text_threshold=0.25):
boxes, logits, phrases = self.predict_dino(image_pil, text_prompt, box_threshold, text_threshold)
masks = torch.tensor([])
if len(boxes) > 0:
masks = self.predict_sam(image_pil, boxes)
masks = masks.squeeze(1)
return masks, boxes, phrases, logits
「強いモデルと強いモデルを掛け合わせると強い」みたいな感じでとてもいいですね。
使い方
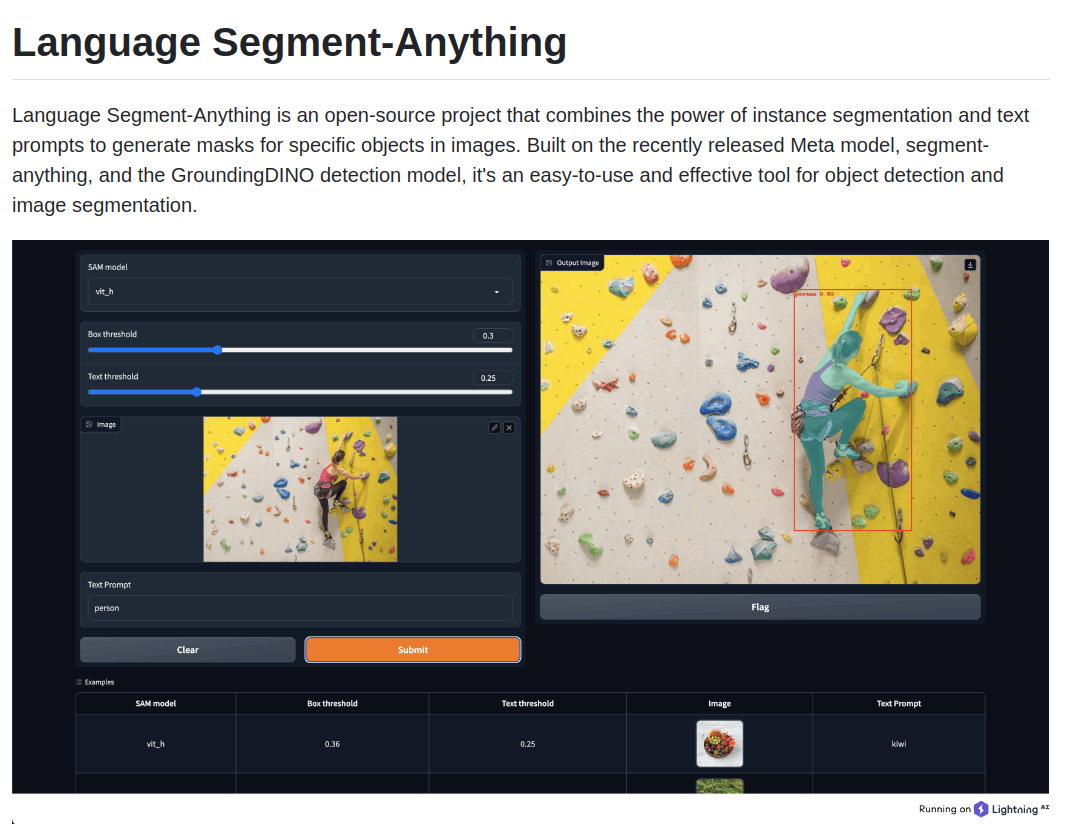
ここまで来ると早速 Language Segment-Anything を試したくなりますが、web上で試せるデモページはありません。代わりに公式によるLightning AI APPを使ったアプリページの立ち上げ方法があるのでこちらを使うことができます。
デモページで試す
基本的にREADMEを順に追えば問題ないのですが、筆者が使っているノートPC (GeForce GTX 1650 Ti Mobile) ではスペック不足でモデルを動かすことが出来ませんでした。代わりにデスクトップPC (GeForce RTX 4090) では動かすことが出来ましたので、ある程度のスペックは必要です。
READMEに沿って環境構築ができれば以下のコマンドでデモアプリを立ち上げることが出来ます。
lightning run app app.py
デモページを立ち上げると以下の様なUIになっており、画像とテキスト (下の例ではcar) をいれるとかっこいいレクサスの物体検出とセグメンテーション結果が得られています。

コードで実行する
デモページでは簡単に試すことができますが、実際に bbox の座標やセグメンテーションマスクを数値として得ることはできません。そのためには実際にコードを動かす必要があります。
といってもこちらもよくREADMEが整備されており、そのとおりにすると良いです。bbox やマスクの描画コードは用意されているので、結果を可視化したい場合はそちらを使用することも出来ます。サンプルコードはこちらが参考になります。
参考ですが、入力画像サイズ (640 x 480) で上記スペックで試した場合、1枚あたり3~4秒ほどかかりました。
from PIL import Image
from lang_sam import LangSAM
model = LangSAM()
image_pil = Image.open("./assets/car.jpeg").convert("RGB")
text_prompt = "wheel"
masks, boxes, phrases, logits = model.predict(image_pil, text_prompt)
以上2つの使い方に触れましたが、さくっと使いたい場合はデモページを使って、多くの画像に対して推論させたい場合はコードで回すこともできそうです。
使用例
ここまで、Language Segment-Anything の説明と使い方を触れていきましたが、最後に使って面白かった例を紹介します。
- 検出したい状況がニッチなとき
Turingは自動運転を開発する会社なのですが、安全性の観点から車内カメラからハンドルを検出し、できればセグメンテーションしたいという状況が発生しました。筆者はまず学習済みモデルを探そうとしたのですが、「車内に取り付けられたカメラ画像のハンドル用の検出モデル」は残念ながら見つけられそうにありませんでした。ましてやセグメンテーション用のモデルはもっとなさそうです。
そんなときでも使えるのがこちらのLanguage Segment-Anythingです。

steering wheelとテキスト入力しています。
開発中の都合上、元画像を公開することは出来ませんが上記のようなニッチな条件でもかなり精度高く検出でき、社内でも好評でした。
裏話的ですが、この結果を疑似ラベルとしてデータセットを作成し軽量モデルを学習することで、リアルタイムにハンドルを検出・セグメンテーションするシステムができました。あくまでもPoCですがそのようなモデルも Language Segment-Anything を使うことで簡単に出来ました。
- 難しそうなセグメンテーションを試したいとき
Turingは自動運転を開発する会社なので、走行可能なエリアを検出することは重要です。車の進行方向を向いたカメラに対する走行可能エリアの検出は一定の先行研究があります。要するに、車載カメラから走行可能な道路面をセグメンテーションするタスクです。
しかし、Turingでは前方だけではなく横方向にもカメラを設置してデータを収集しており、そのような比較的研究されていないデータに対してもセグメンテーションを行うケースがあります。
そのようなケースでも使えるのが Language Segment-Anything です。

road areaとテキスト入力しています。
こちらはTuringのデータ収集車両の左側のカメラなのですが、驚くほどきれいにセグメンテーションできています。また画角も通常のカメラに比べ広く、その影響で画像が歪んでいるのですがそれも関係なくセグメンテーションできています。
- 学習できていないようなデータに対しても
Turingは完全自動運転を開発する会社なので、360°の情報を認識することが重要です。そのため、上記の画像も含めた360°をカバーしたカメラ配置でデータ収集を行っています。それらのデータを結合することで、パノラマ画像のように360°全てをつなげた画像を生成することが出来ます。
そのような画像に Language Segment-Anything を使った結果がこちらです。

おそらく、このような画角・サイズのデータはSAMの学習データには含まれていない、もしくは、その数は少数だと思いますがきれいにセグメンテーションできています。非常に驚きました。
まとめ
以上のように Language Segment-Anything はオブジェクトやカメラ条件が比較的特殊な場合でもうまくセグメンテーションできることがわかりました。みなさんもこれを使って、簡単に高精度にお手元のデータを物体検出・セグメンテーションしてください。とりあえず試すには非常に良いモデルだと思います!
それではメリークリスマス&よいお年を!

Discussion