はじめに
チューリングのVLAチームでエンジニアをしている横井です。
2025年にKaggleで開催された自動運転とVLM (Vision-Language Model) のドメインである2COOOLコンペに社内のKaggler (
Kento Sasaki, ymg_aq, colum2131, Hidehisa Arai, Hotaka Ueda) で参加しました。幸運にも2位を獲得し、ICCVに参加するなどの貴重な経験ができたので参加記録を残します。
これはKaggle Advent Calendar 2025の3日目の記事です。

表彰してもらえました
本記事では以下の内容を紹介します。
- コンペの概要と課題設定
- 上位入賞につながった工夫やアプローチ
- トップカンファレンスに現地参加して見た自動運転分野の最新潮流
Kaggle・VLM・自動運転に興味のある方の参考になれば嬉しいです。
2COOOLコンペとは?
2025/8/24 ~ 10/2 にKaggleで開催された2COOOL (2nd Workshop on the Challenge Of Out Of Label Hazards In Autonomous Driving) コンペは、コンピュータービジョン分野におけるトップカンファレンスであるICCV (International Conference on Computer Vision) のワークショップに併設されたコンペです。
ワークショップはメインカンファレンスの会期中またはその直前に開催される特定の専門分野に特化した小規模なイベントです。本コンペは、2COOOLワークショップの一部として企画され、Kaggleで開催されました。
学会主催のコンペなので、賞金はありますがKaggleのポイントやメダルは付与されません。代わりに上位チームや優秀なコンペ解法論文を提出したチームは2025/10/19 ~ 10/20 にハワイ・ホノルルで開催されるICCVのワークショップにおいて口頭発表やポスター発表の機会が与えられます。
コンペ概要
本コンペは「自動運転における未知の危険(Out-of-Label Hazard)」の研究を推進するために開催されました。課題はドライブレコーダー動画から事故レポートを生成することです。
学習データは与えられず、サブミットで推論する661本の動画だけが提供されます。動画には、交通事故や動物が急に飛び出すなどのヒヤリハットのシナリオが含まれます。元動画に加えて「人間の視線ヒートマップ」が付与された動画も提供されます。

ヒートマップ付き動画と元動画の例。赤いトラックがバイクに追突する様子が映っています
タスク概要
予測する事故レポートは以下の11項目です:
- 危険・事故が始まるインシデントフレーム番号
- 危険か事故か、または何も起きないかの検知
- 危険・事故の深刻度の分類
- 自車が危険・事故に関与したかの分類
- 危険・事故の種類の分類
- 危険・事故に関与した自転車/スクーター台数
- 危険・事故に関与した動物の数
- 危険・事故に関与した歩行者の数
- 危険・事故に関与した車両の数(自車除く)
- 危険・事故直前の状況キャプション
- 危険・事故の発生理由のキャプション
サブミットの形式は、動画1本につき1行のCSVで上記の項目を全て埋める必要があります。ポイントは「分類」や「数カウント」だけでなく 「自然言語のキャプション」まで求められるところです。つまり、VLMやLLMを活用する必要があります。
評価指標
動画像キャプションで一般的に用いられる CiDER-D・METEOR・SPICE の平均値が本コンペの評価指標です。一次順位はこのスコアで決まりますが、最終順位は上位チームの結果をコンペホストが人手で評価し、総合的に判断して決定されます。
Kaggleのリーダーボードは CiDER-D と METEOR のみで算出された順位であるため、最終結果としての参考になりません。当初アナウンスされていたコンペ終了日である 9/29 に CiDER-D・METEOR・SPICE で評価したICCVのリーダーボードが公開されました。その後、事前告知無しでコンペ終了が3日間延長され、改善の時間が与えられました。
どのようにコンペに挑んだか
本格的に取り組み始めたのは 9 月中旬で、約 2 週間ほど時間をかけました。学習データが提供されないコンペであるため、モデル学習は諦め、VLM への入力設計とプロンプト改善に注力しました。コードやプロンプトは Cursor や ChatGPT にアイデアを投げて実装してもらい、自分で 0 から書くことはほぼありませんでした。
最初のアプローチ:動画をVLMに入力
最初は動画をVLMにそのまま入力し、危険・事故が始まるインシデントフレームの検出やキャプション生成などを同時に出力させるナイーブな方法を採用しました。具体的には、以下のようなプロンプトと動画ファイルをVLMに投げる方法です。
この動画を見て、以下の項目を全て答えてください
- 危険/事故が始まるフレーム
- 事故の種類
- 事故前・事故後の説明
しかし、推論結果のほとんどが “No incident” となり、危険や事故の検出がほとんどできませんでした。この結果から「入力情報を一度に全部与える」「複数タスクを同時に解かせる」のは、当時のオープンなVLMとして最高性能だった GLM-4.5 でも難易度が高すぎると判断しました。
インシデントフレームを重視したマルチステージ推論
長尺の動画をそのまま入力すると情報過多で、モデルが本当に見るべき瞬間を見落としやすくなります。そこで、重要な場面だけをモデルに与えることでより正確な説明生成ができると考えました。
サブミットCSVには「危険・事故が始まるインシデントフレーム番号」が必須であり、インシデントが起きるフレームの特定はタスク的にも評価的にも重要です。このことから、次のような2段階の推論に切り替えました。
- 動画全体をモデルに入力し、トリガーとなる危険・事故が始まるインシデントフレームを特定
- 特定したインシデントフレームの周辺だけをモデルに入力し、インシデントの詳細説明を生成
thinkingモードとvLLMを活用
本タスクでは「何が起きて、なぜそうなったのか」を自然言語で説明することが求められます。そのため、VLMはthinkingモード(内部で思考ステップを展開し、より深い推論を行うモード)で推論した方が良いと判断しました。実際、thinkingモードが使えるVLMである GLM-4.5 を thinking あり / thinking なし で同一入力比較したところ、thinking ありの方が事故の原因や関与している車両の数など、文脈依存の情報がより正確になりました。
性能向上のため 100B 超の VLM を採用しましたが、Transformers では動画 1 本の推論に数分かかり、vLLM などによる高速化が必須でした。当時の vLLM(v0.10/0.11)はサーバーモードでの動画入力は thinking のテキストが出力できなかったため、動画ではなく複数フレームを入力する方式にしました。
vLLM で GLM-4.5 や Qwen3-VL-235B など巨大なパラメータのVLMを動かす参考資料はほとんどなく、本コンペで一番大変だったのは vLLM の環境構築だった覚えがあります。
Self-consistencyで生成のゆらぎを平均化
VLM/LLM は temperature や top_p などのサンプリングパラメータによって生成結果に揺らぎが生じます。特に thinking モードでは、多様な推論を得るために確率的サンプリングが推奨されています (Qwen3-VLの例)。そこで、同じ画像+プロンプトに対して 温度付きサンプリングを n 回実行し、推論結果を統合する Self-consistency を採用しました。具体的には、各推論で予測した11項目を以下のルールでまとめました:
- 分類ラベル:多数決
- 人数・台数などのカウント値:中央値
- キャプション:テキストだけ別の表現になるのを防ぐため、上記ラベル・数値と最も整合するサンプルを採用
この集約により一貫性の高い予測が得られ、n=8 からリーダーボードのスコアが安定して改善しました。
異なるフレームウィンドウの推論結果をLLMでアンサンブル
インシデントフレーム周辺の全フレームを VLM に投げるのは無駄が多く計算コストもかかるため、一般的な動画処理と同様にフレーム間引きを行いました。ただし、ウィンドウ幅が大きいとインシデントを見落とし、小さいと冗長な入力で計算量が増えるというトレードオフがあります。この問題を避けるため、異なるウィンドウ幅で画像フレームをVLMに入力して推論を行い、各推論結果をLLMに入力して統合しました。
2位になった我々の解法
解法は前節で述べた内容を盛り込んだもので、以下の 3 Stage + Ensembling & Blind A/B で構成されます。コードは公開しています。

解法の概要図
Stage 1:Frame-level Captioning(粗いスキャン)
ヒートマップ付き動画と元動画を縦に結合し、10 フレーム間隔でフレームをサンプリング(例: 1, 11, 21, 31, …)します。ヒートマップ付き動画を使うことで “運転者が注視していた領域” もモデルに伝えます。サンプリングした各フレームを VLM(GLM-4.5V)に入力し「その周辺の状況説明」と「歩行者/車両/動物などの存在」をテキストで出力します。
Stage 2:Incident Frame Detection(事故フレーム推定)
Stage1の出力を LLM(gpt-oss-120b)に渡し、インシデントフレーム番号を推定します。

Stage1,2のイメージ
Stage 3:Incident Captioning(事故レポート生成)
Stage 2 で推定した事故フレームの周辺フレームだけを VLM(GLM-4.5V と Qwen3-VL-235B-A22B-Thinking)に入力して事故レポートを生成します。周辺フレームは、様々なウィンドウ幅でVLMに入力して多様な結果を生成させます。Qwen3-VL-235B-A22B-Thinking が非常に強力で、このモデル使うことで順が大幅に改善しました。
Ensembling(複数レポートの集約)
Stage 3 で作成した事故レポートを LLM(Qwen3-Next-80B)で統合します。このアンサンブルにより CiDER-D が特に改善しました。
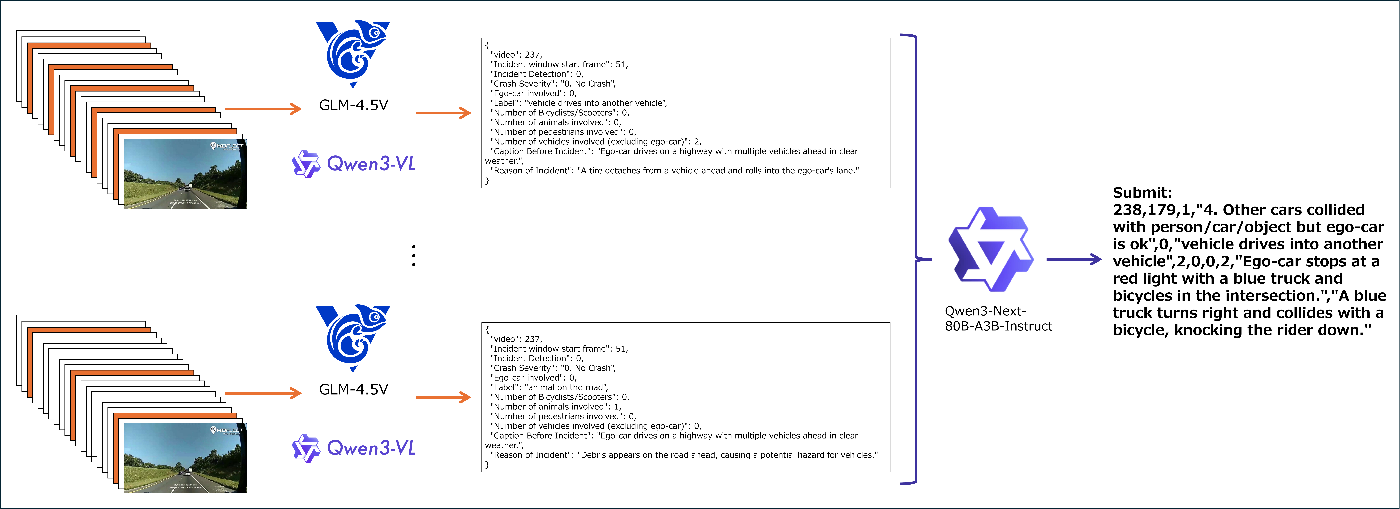
Stage3とEnsemblingのイメージ
Blind A/B Scoring(最終レポート選択)
最終評価は人手評価で行われるため、提出用 CSV の内容を Blind A/B テストできる Web アプリを実装し、目視確認で最も良いレポートを選びました。この仕組みは ymg_aq さんが作ってくれたものです。
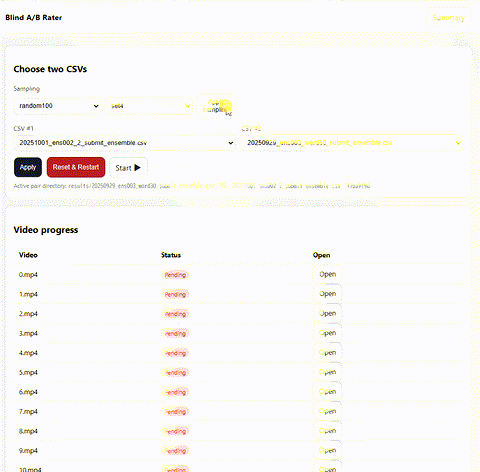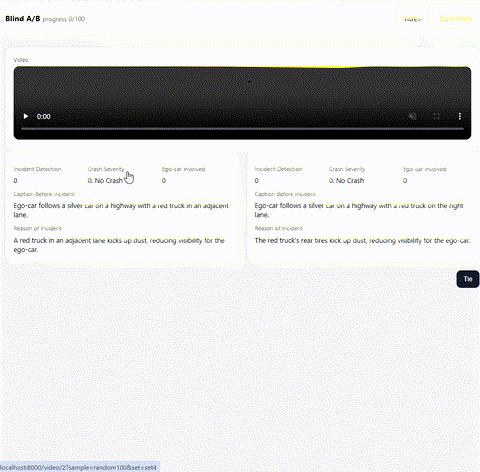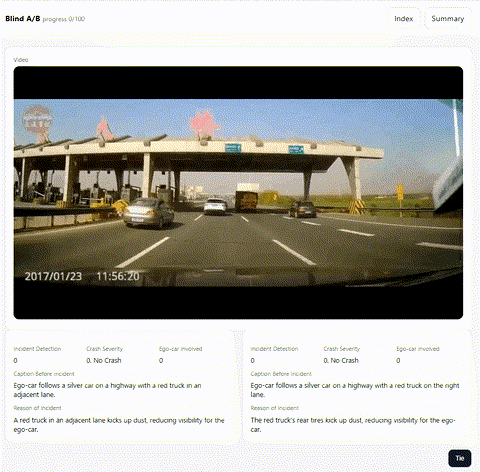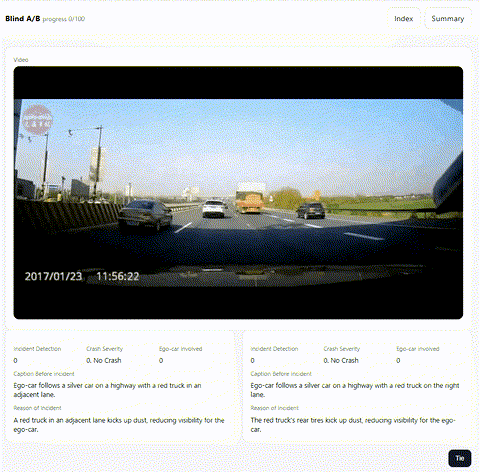
Blind A/B テストのアプリ画面
解法論文を作成
ICCV 参加権を得るため、解法の技術レポートを提出しました。執筆は Kento Sasaki さんが担当してくれました。提出期限はコンペ終了からわずか 2 日後という非常にタイトなスケジュールでした。論文はアクセプトされ、arXivで公開しています。
ICCV の現地発表に向けて、内容をまとめたポスター資料も作成しました。

参加したICCVの雰囲気
現地会場は学生・企業・研究者が入り混じり、活気がありました。
会場の様子

会場入口

開放感がある会場でした

多くの参加者が行き交ってにぎやかでした
2COOOLワークショップの様子
ワークショップ当日のスケジュールは「ポスター設営」「口頭発表」「ポスターセッション」「表彰式」があり、あっという間に過ぎました。

ポスターセッションの様子

口頭発表はチームメンバーがしてくれました
ICCVのポスターセッションの様子
膨大な数のポスターセッションがあり、非常に面白かったです。
ICCVの別ワークショップに通った自社メンバーの論文ポスター
ICCVの口頭発表の様子
口頭発表も多岐にわたり、どれも濃い内容でした。

基調講演の様子。世界各地の望遠鏡から得た観測データをもとにブラックホール像を再構成する話

Wayveの発表
企業ブースの様子
企業ブースでは、ビッグテックを中心に多くの企業が参加しており、各社の最新技術や研究事例を見ることができました。

Metaのブース
Googleのブース

Appleのブース
懇親会の様子
最終日前日の夜には、広い会場で懇親会が開催され、多くの研究者が集まり交流を深めました。

研究者同士が一堂に会し、食事をしながら交流
ICCVで感じた自動運転の潮流
TeslaやWayveなど主要な自動運転企業を招いたワークショップがありました。
特に Tesla の講演は非常に興味深い内容でした。以下は、ワークショップ主催者によるまとめ記事です。
全体を通して強く感じたのは、
世界モデル × 生成シミュレータ × E2E(End-to-End) / VLA(Vision-Language Action) x RL(強化学習)
というキーワードです。
世界モデルと生成シミュレータを前提にした closed-loop 評価と RL
複雑な交通シーンを「世界モデル」で生成し、その上で RL や closed-loop 評価する流れがありました。世界モデルはデータ生成・評価・RL を回すためのインフラとして扱われ始めている印象でした。
Tesla
3DGS(3D Gaussian Splatting)ベースの高速なシミュレータとリアルタイム世界モデルを使い、危険シーンの再現や車両挙動の編集を行いつつ、E2E モデルを closed-loop で評価していました。「自動運転のボトルネックは学習ではなく評価」というメッセージが印象的でした。

NVIDIA / Uber / Wayve
いずれも 世界モデルでデータを生成・拡張し、それを蒸留・RL に繋げるという構図を強調していました。Wayve は GAIA-2 でマルチビュー走行動画を生成して「シミュレーション内学習」への布石を置いています。

Wayve の GAIA-2 の例
VLM やクラスタリングを活用したデータキュレーション
単にたくさんデータを集めるのではなく「どのシーンを増やすか」「どの失敗ケースを重点的にカバーするか」といったキュレーションロジックの設計が紹介されました。
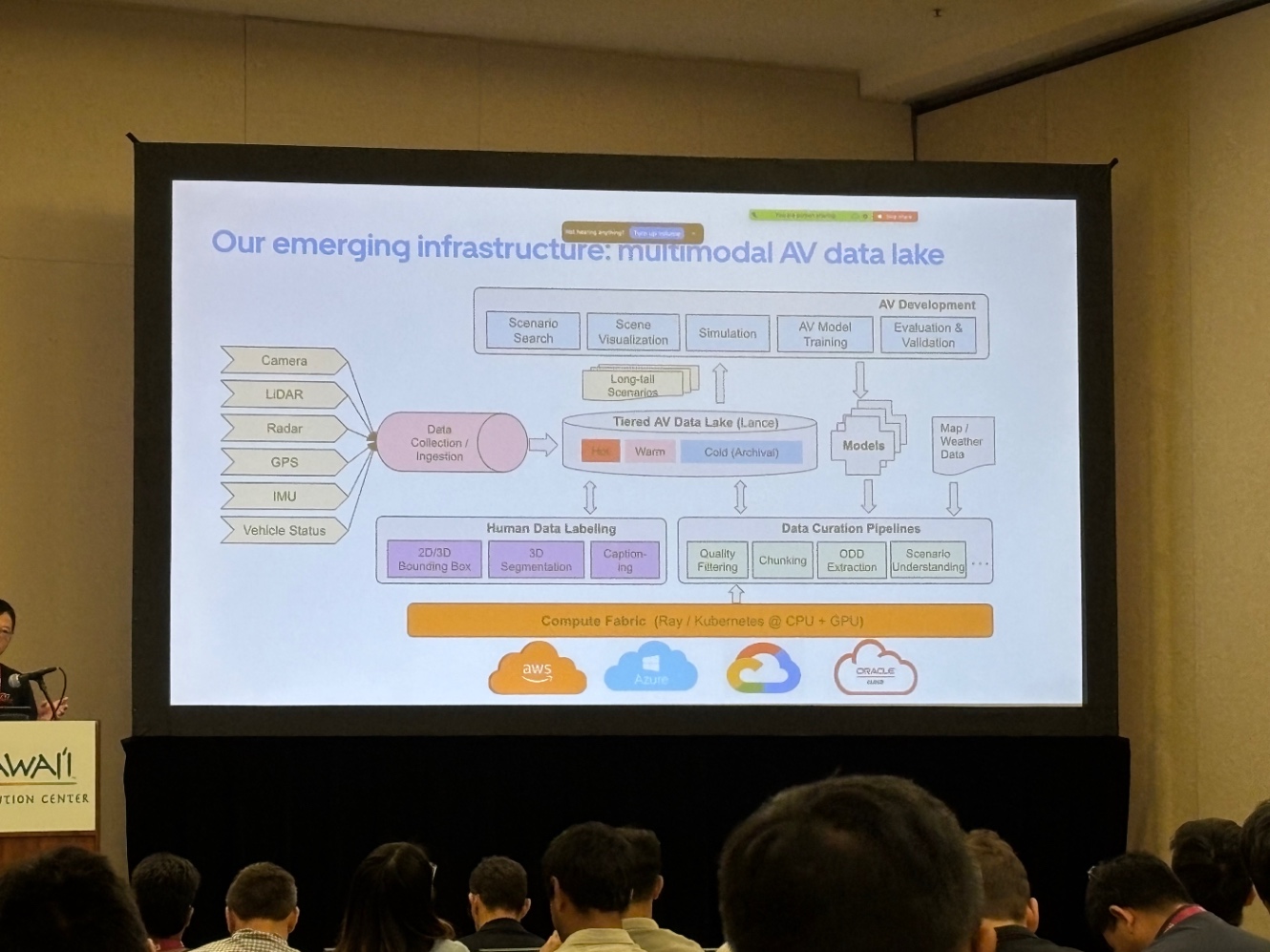
NVIDIA
VLM で運転動画を言語化 → クラスタリング → ロングテールやマイナークラスを増やす形でデータ混合を最適化し、E2E モデルの性能を短時間で引き上げるアプローチを紹介。論文 CLIMB に代表されるように、「データ混合比を自動探索するフレームワーク」が提案されていました。
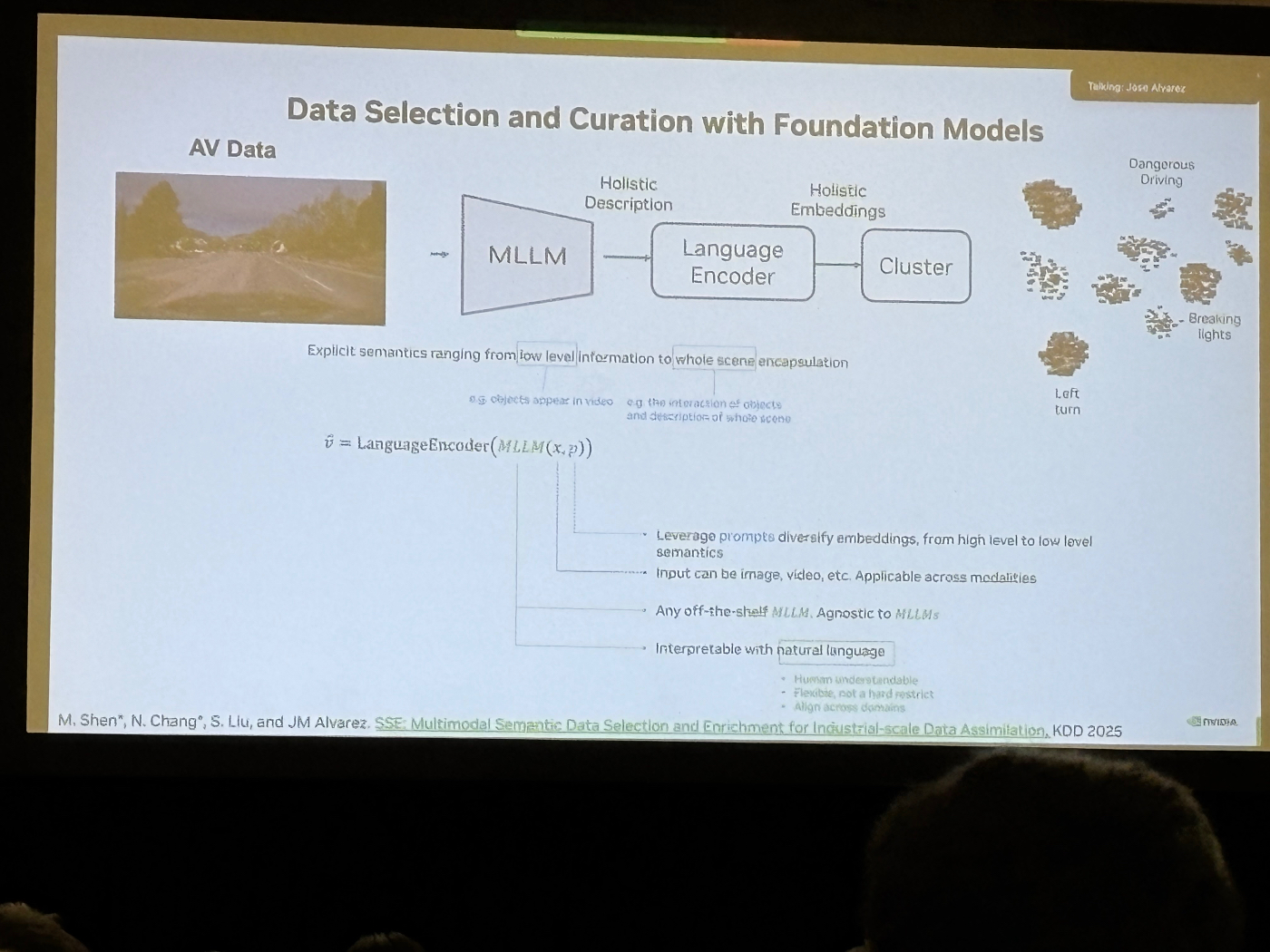
Uber
70か国・15,000都市規模のデータレイクを前提に、VLM と detection モデルを組み合わせてシナリオマイニングを実施。「走行時間ではなく、有効データ量と多様性が重要」というメッセージで、NVIDIA と同様にモデルとデータが自己改善し続ける “データフライホイール” の設計を強調していました。
E2E / VLA への移行と自動運転 Foundation Model 化
各社とも、モジュール分割ベースから End-to-End / VLA へと移行していました。
Tesla
7カメラ・IMU・オドメトリ・音声まで含めた巨大 E2E モデルを初めて詳細公開。中間表現として 3D Occupancy, 物体・レーン・信号・制限速度、言語によるアクション記述、3DGS などを内部で同時に予測し、それらをもとに reasoning して最終アクションを出す概念図を示しました。

Waymo
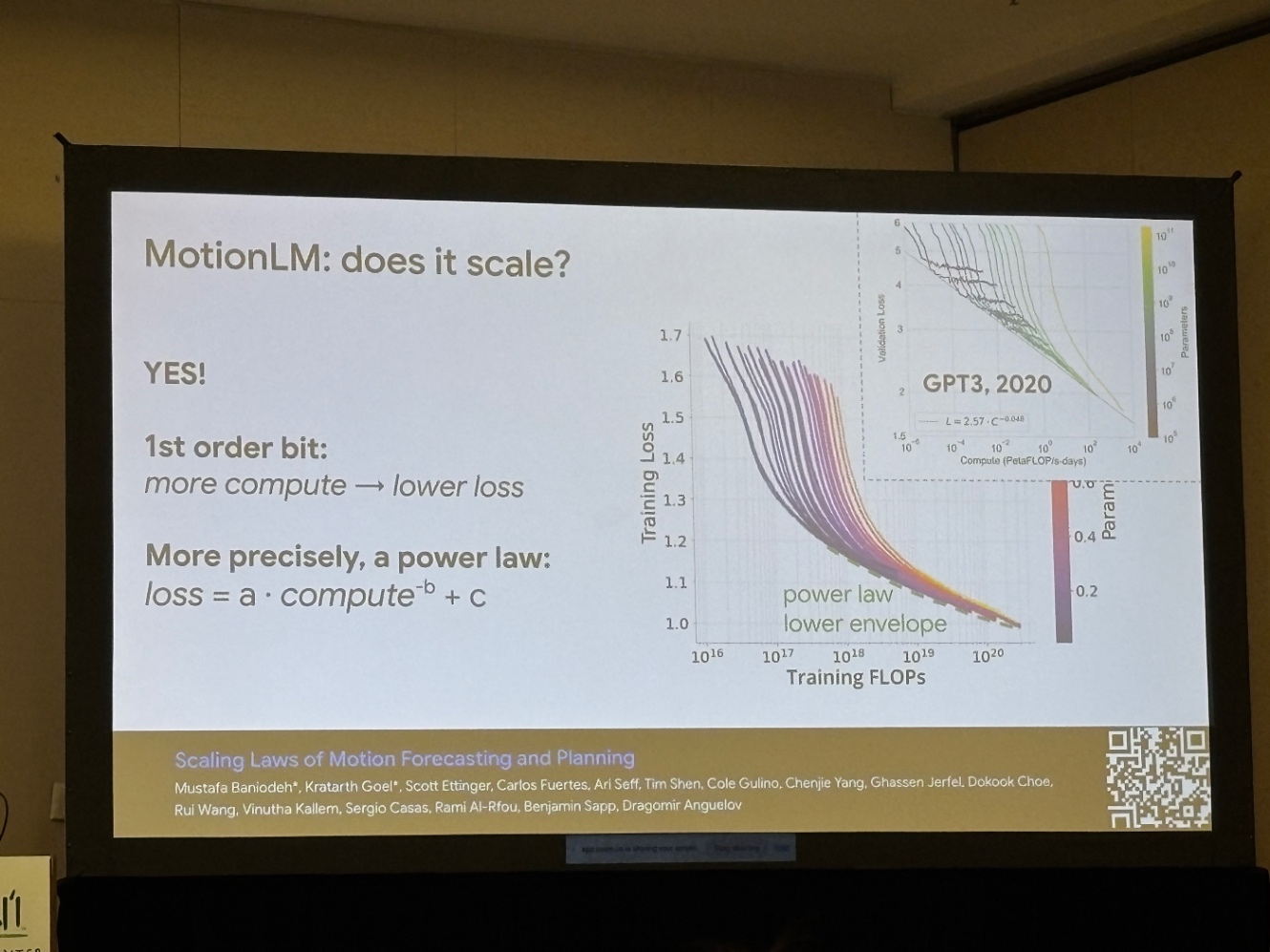
MotionLM という「将来軌跡をトークン列として扱う LM 風デコーダ」を提示し、スケーリング則と蒸留で実用ラインまで引き上げた事例を紹介しました。
Wayve
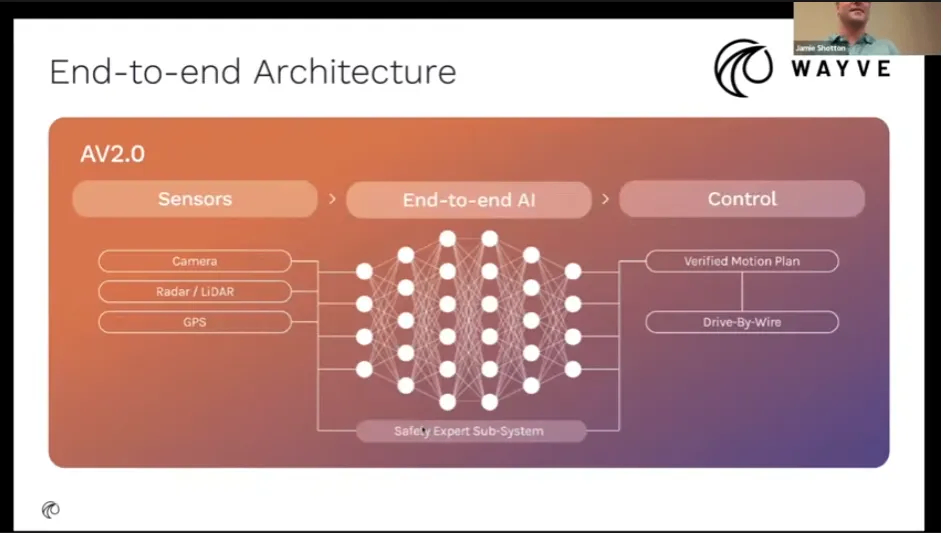
AV 2.0 と称して End-to-End アーキテクチャを前提に、Lingo / Rig3R / GAIA-2 といったモジュールを積み上げる方向性。少量の追加データで日本展開まで持っていった話も含め、“スケールすれば賢くなる E2E” を強く推していました。
VLM を活用した説明性・言語インターフェース
VLM を「評価」「解析」「説明」に使う動きもありました。
Uber / NVIDIA
VLM を使ったデータキュレーション・エラー分析を実際のパイプラインとして説明しました。

NVIDIA のスライド
Tesla / Wayve
運転モデルに「別のシステムと協調するシステム2」や「運転の言語説明 (Lingo)」をくっつけ、
「なぜそのアクションを取ったのか」を後から自然言語で説明できる仕組みを目指していました。

Tesla のスライド
おわりに
2COOOLコンペでは、動画データで VLM と LLM を活用する知見を獲得することができました。
また、ICCV の現地参加を通じて、自動運転企業が注力する 世界モデル × 生成シミュレーション × E2E / VLA × RL といった潮流を直接確認できたことも大きな収穫でした。
学会コンペはKaggleのメダルは得にくいものの、エンジニアとしての視野を広げる貴重な機会になります。チューリングでは今回のようにコンペを通じて国際学会に参加し、最新研究に直接触れられるチャンスもあります。興味を持っていただけた方は応募してもらえると嬉しいです。

現地で撮ったハワイの風景

Discussion