Turingには「MLOpsチーム」と呼ばれるチームがあります。このチームはもともと、自動運転を実現するMLモデルを開発する「E2Eチーム」から、2025年3月頃に独立して誕生しました。
今回の記事では、MLOpsチーム誕生に至る経緯と、その役割について紹介できればと思います。
自動運転MLモデル開発に必要なドメインは多い
TuringのE2Eチームは、自動運転用の機械学習(ML)モデルを開発するチームです。チーム名の「E2E」はEnd to Endの意味で、このチームが開発するモデルの特徴を表しています。
このチームには、自動運転MLモデルを開発するエンジニアが多くいますが、そのカバーする領域は多岐に渡ります。
機械学習システムを構築するには、ML学習以外にも重要な要素がたくさんある、という話をすると、よく「Hidden Technical Debt in Machine Learning Systems」の論文の絵が参照されることが多いかなと思います。自動運転MLモデルの開発でも同様に、多くの要素を考慮する必要がありますが、自動運転に特有の要素としては、例えば、データ収集計画やセンサーの選択、キャリブレーション、制御との繋ぎ込みといったものがあります。
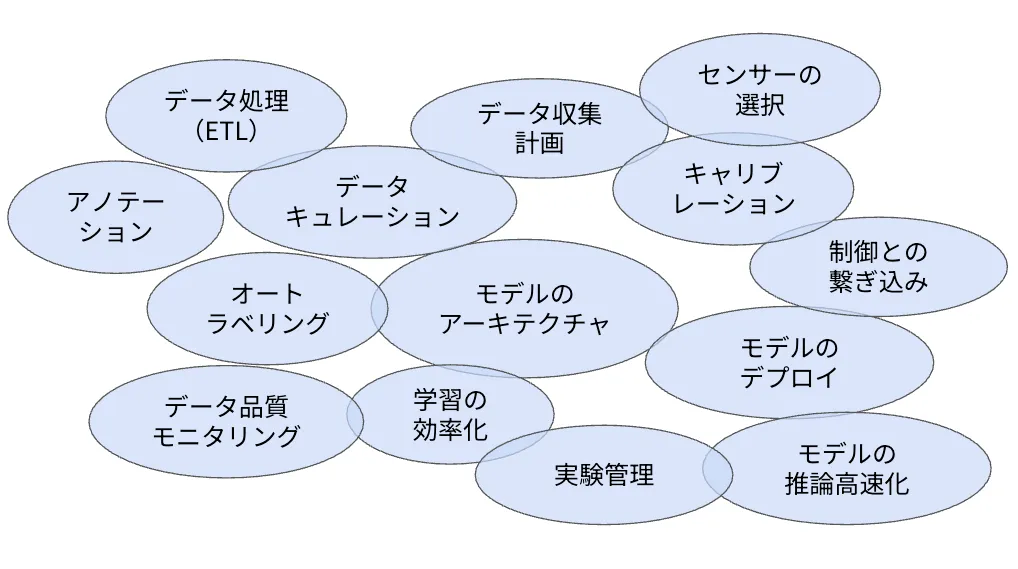
自動運転MLモデルを開発する上で必要な要素それぞれのことを、「ドメイン」と呼ぶことにしましょう。よりよい自動運転MLモデルを開発するためには、それぞれのドメインを高度化する必要があり、それを実現するためのエンジニアの数も次第に増えていきました。一方で、エンジニアが増えると、ワンチームで全てを開発することには限界が生じてきます。
そこで、どのようにチームを分割するか?を考える必要が出てきました。
チームをどうやって分割するか?
まず考えられるのは、ドメインでチームを分割する方法です。
これはシンプルで分かりやすいですが、E2E自動運転モデルを構成するこれらのドメインは、実は相互に深く関係しているため、このような形で分割すると、全体最適なモデルを作れない、という点が課題として考えられました。
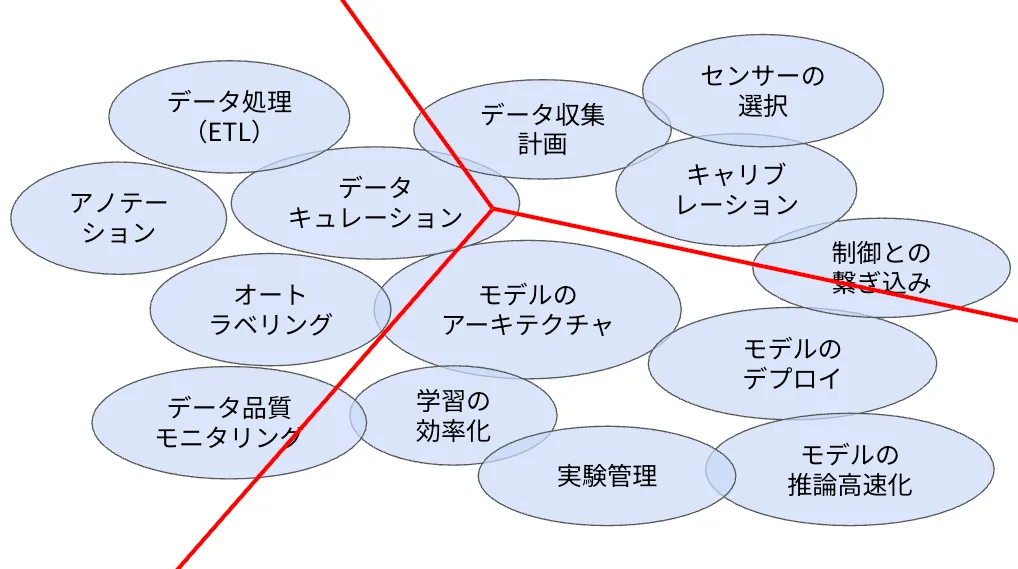
そこで、他の分割方法を考えるために、これらのドメインを別の方向、つまり、ドメインを実現するために必要なシステム構成の観点から見てみましょう。

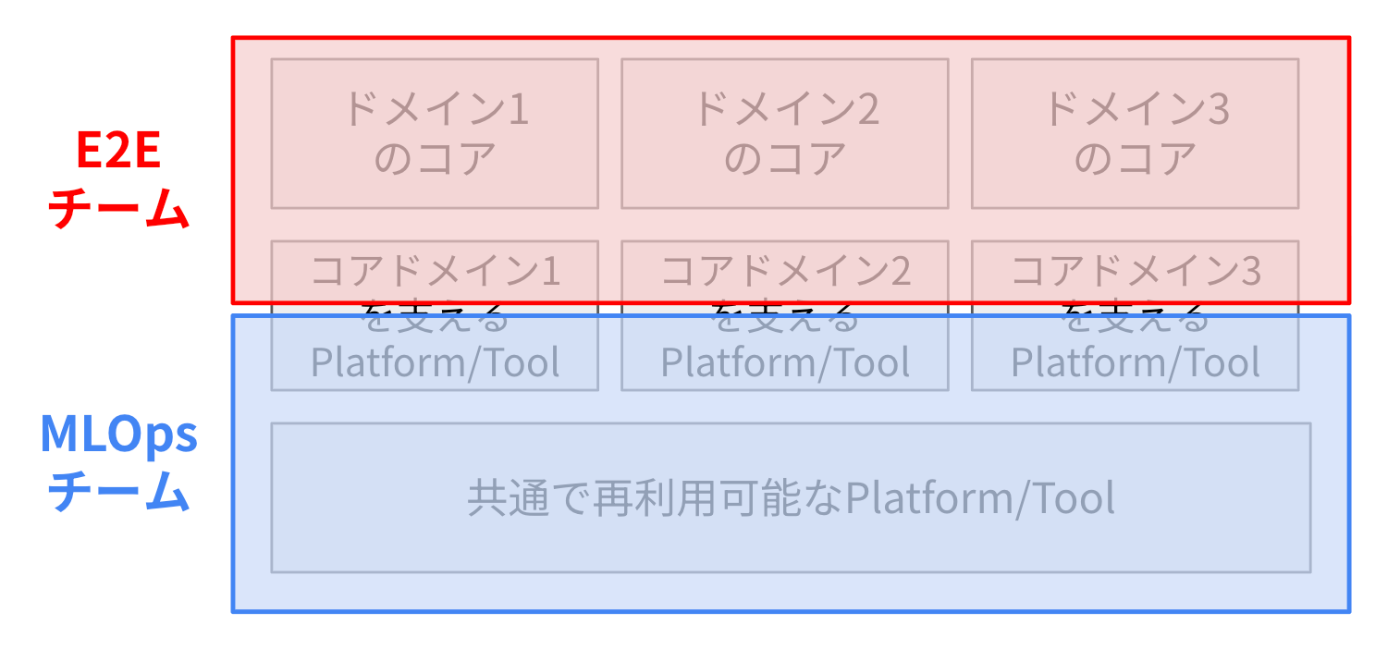
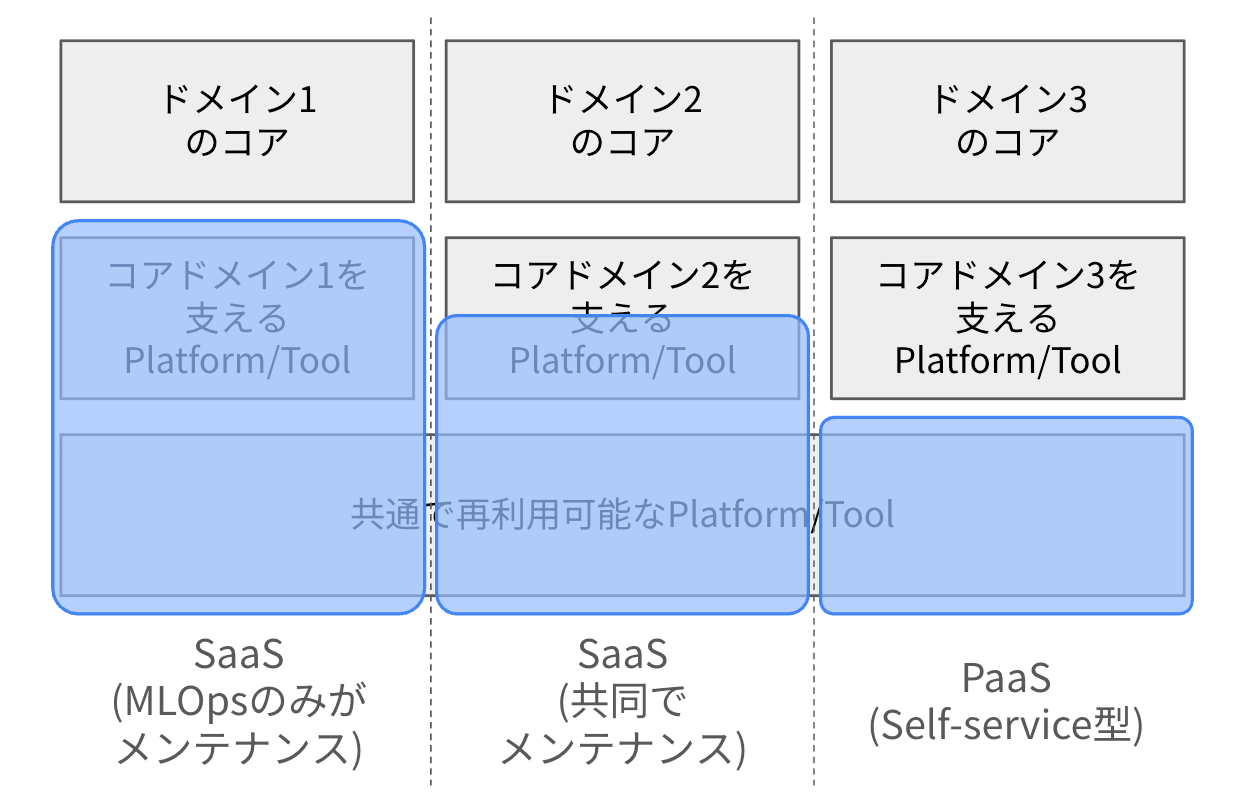
それぞれのドメインをシステム構成の観点から見ると、各ドメインは、ドメインのコアとなる部分と、それを支えるプラットフォーム・ツールから構成されることが分かります。さらに、プラットフォーム・ツールの一部には、ドメインを跨いで、共通で再利用可能なものも存在します。
コンウェイの法則によると、「組織のコミュニケーション構造は、その組織が設計するシステムの構造に反映される」と言われています。逆に言うと、「望むシステム構造を実現するために、組織の構造やチームの分け方を意図的に設計できる」とも言えます(逆コンウェイの法則)。この法則に従って考えると、共通で利用可能なものを異なるドメインで再利用したい場合、それは1つのチームで管理した方が良さそうです。
そこで、以下の図のようなチームの分割方法が生まれました。この図では、「コアドメインを支えるツール・プラットフォーム」が、両方のチームの範囲に入っていると思いますが、これは、この境界線の位置はドメインによって変わり得る、ということを意図しています(詳細は後述します)。
さて、ここまで少し抽象的な話をしてきましたが、このドメインのコアとは具体的にどのようなものになるのか、具体的な例をいくつか見ていきましょう。
例1:オートラベリング
Turingでは、自動運転MLモデル開発への活用を目的として、自車の周りに存在する、歩行者、バイク、車などのオブジェクトに対して、ラベル付けを行っています。このラベルは、そのオブジェクトのクラス(歩行者、バイクといった分類)だけでなく、3次元上での位置・姿勢情報も含んでいます。

このラベリングですが、人手でやろうとすると膨大な工数がかかってしまいます。そのため、人手でつけた少数のラベルから、自動でラベリングを行うモデルを学習し、そのモデルを使って他のデータのラベリングを行います。これをオートラベリングと呼びます。
オートラベリングを実現するために必要な要素を、システムの観点から可視化してみました。

上から順に説明すると、まずオートラベリングモデルのアーキテクチャを考える必要があります。そしてそのアーキテクチャで学習や推論できるように、データローダーやLoss、Optimizerの設計なども含めた学習コード・推論コードを書く必要があります。学習時にはMLモデルを学習するためのGPUインフラが必要です。推論(バッチ実行を想定しています)の際には、データをダウンロードし、前処理を行い、推論を行い、その結果をアップロードする、といった一連の流れを管理するワークフローも必要です。また、どのようなコード・パラメータで推論した結果か、といったことの管理や、この推論をスケーラブルに実行するためのServingインフラの管理も必要です。
さて、この中で、オートラベリングのコアとなる部分はどこでしょうか?
必ずしもこれが正解とは限りませんが、例えば以下の赤枠で囲った部分がドメインのコアとなる部分ではないかと思います。一方、青枠で囲った部分はMLエンジニアにとっては、信頼性が高くかつスケーラブルな環境が用意されていれば、その中身については特にこだわりはないはずです。この青枠の部分を抽象化してMLエンジニアに見せるのが、MLOpsチームの役割と言えます。

例2:キュレーション
自動運転MLモデルを学習するためにはデータが必要で、Turingでは学習に用いるデータを全て自分たちで収集しています。その際、収集したデータ全てを学習に使うのではなく、例えば品質や、右左折・直進の割合、天気や走行エリアのカバレージといった要素を考慮してフィルタリングしたデータのみを使います。この作業をキュレーションと呼びます。
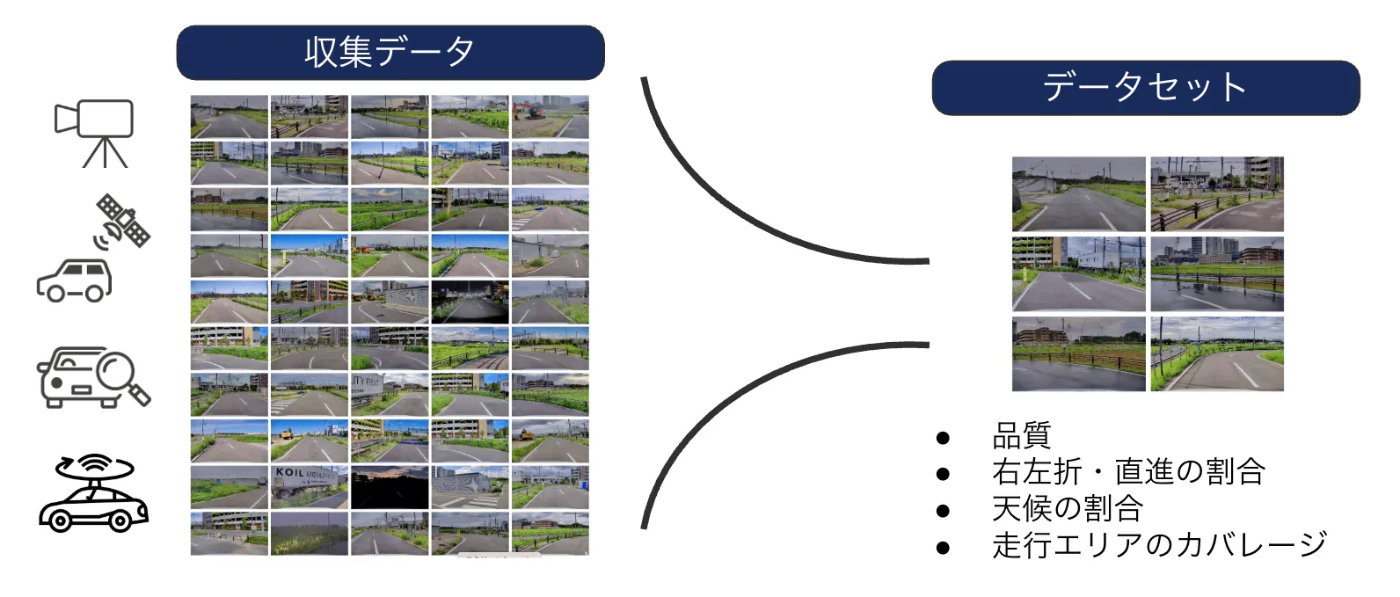
キュレーションを実現するために必要な要素を、システムの観点から可視化してみました。
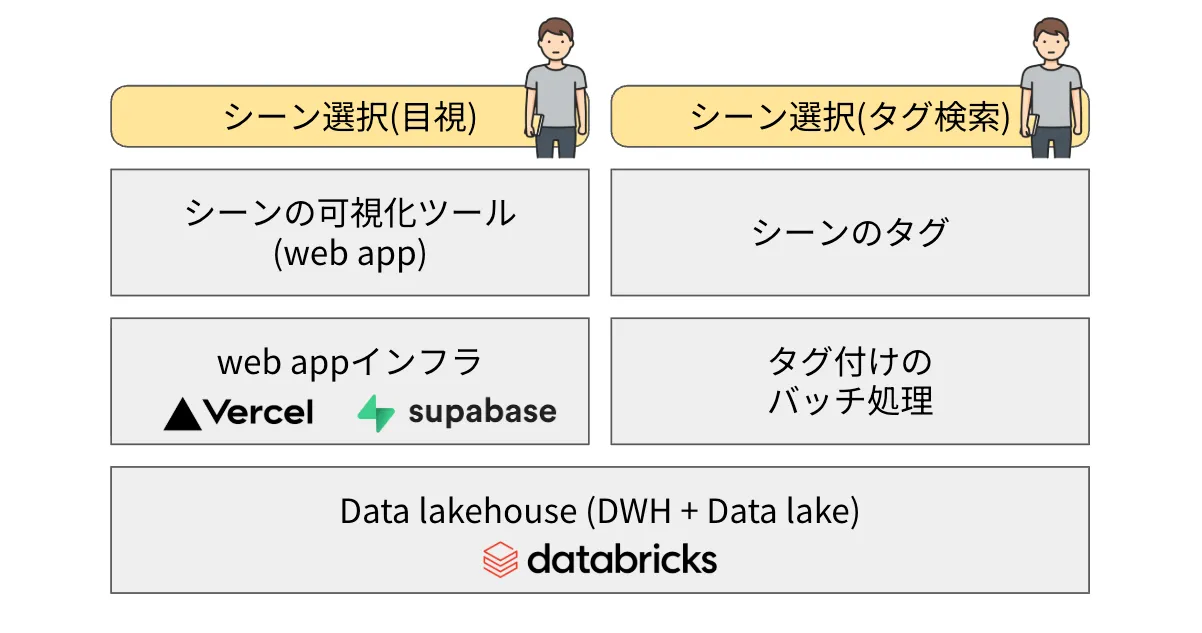
Turingでは、扱いやすくするために、収集したデータを20秒ごとのチャンクに分割しており、このチャンクを「シーン」と呼んでいます。キュレーションとは、適切なシーンを選択することを意味します。
シーン選択の方法は主に2つあります。1つ目は、実際にそれぞれのシーンを目で見て選択する方法です。これを実現するためには、シーンを可視化できるツールが必要です。MLOpsチームでは、シーンの可視化が可能な、内部向けのwebアプリケーションを開発しています。

2つ目は、タグを使って選択する方法です。例えば以下の図に示すように、シーンに対して様々なタグがついていれば、これを使って検索やフィルタリングが可能です。MLOpsチームでは、バッチ処理によって、全てのシーンに対してこれらのタグ付けを行っています。

さて、この中で、キュレーションのコアとなる部分はどこでしょうか?
MLエンジニアが一番考えるべき部分は、「どのようなシーンをデータセットに含めるべきか」だと思われます。そのためには、シーンのどのような部分を見たいか、どのようなタグがあると良いかを考えることも重要です。一方で、それらをツールとして作る部分については、ドメインのコア外と言えそうです。MLエンジニアとしては、いつでも簡単に素早く、思い通りのシーンを見れて、選択できる。そういったツールがあれば良いはずです。
境界線は以下のように引けるのではと思います。このケースでは、MLOpsチームが多くのコンポーネントを担当することになりそうです。

以上、2つの例を通して、ドメインのコアとはどのようなもので、MLOpsはどこを担うのか、を説明してきました。MLOpsの役割が少しずつ見えてきたと思いませんか?
次は、世の中の一般的な概念と対比して、MLOpsチームを定義してみたいと思います。
MLOpsチームとは何であって何でないのか?
MLエンジニア=フルサイクルエンジニア?
コアのドメインとそうでない部分で役割を分離する、という考え方は、「フルサイクルエンジニア」の考え方にも近いと考えています。これは2018年にNetflixのブログで提唱された概念で、ソフトウェア開発のすべてのプロセスを1人のエンジニアが担当できるようにすることで、End-to-Endでの価値提供のスピードを向上させることを目指しています。
一方で、すべての工程をフルサイクルエンジニアに押し付けると、責務や認知不可が高くなりすぎます。そのため、フルサイクルエンジニアをエンパワーする「共通のツールやインフラ」を開発するための専任チームが必要と言われています。
Netflixが指している「共通のツールやインフラ」は、例えばMetaflowのように、AWSなどのクラウドプロバイダーが提供している複数のサービスをさらに一段抽象化して、インフラ周りを特に気にせずに使えるようにしているものを指すと理解しています。これはMLOpsチームの考え方にも近そうです。
一方、Netflixは大規模なプロダクトで様々なサービスが存在しており、「共通のツールやインフラ」も、サービスを跨いで使えるものに専念しているように見えます。Turingは、ドメインを跨いで使えるものだけでなく、それぞれのドメイン側に染み出してプラットフォームやツールを提供している部分が、少し異なる部分ではないかと思います。
プラットフォームエンジニアリング
Platform Engineeringも比較的最近出てきた考え方で、エンジニアの認知負荷を下げて開発効率を向上させるためのプラットフォームを提供する、専任のチームを作るという考え方です。
開発効率を向上させるという観点では似ていますが、これもフルサイクルエンジニアのケースと同じように、Turingはそれぞれのドメイン側に染み出している部分が差分になると思います。
MLOpsの開発の現状
MLOpsが実際に開発・運用しているプロダクト
ここまで、MLOpsチームの役割の定義についてみてきました。ここでは、MLOpsチームがE2Eチームに、どのような形で貢献しているかを、もう少し具体的に見ていきましょう。
E2Eチームへの提供形態は、大きく分けて、①MLOpsチームのみがメンテナンスするSaaSとしての提供、②共同でメンテナンスするSaaSとしての提供、③Self-service型のPaaSとしての提供、の3つに分類できます。それぞれの特徴と例を、表にまとめました。
| 形態 | SaaS(MLOpsのみがメンテナンスする) | SaaS(共同でメンテナンスする) | PaaS(Self-service型) |
|---|---|---|---|
| 説明 | MLエンジニアが利用できるツールをSaaSとして提供。E2Eチームから機能要望を聞いて、MLOpsが実装を行う。 | MLエンジニアが利用できるツールをSaaSとして提供。ただしコードベースは共同でメンテナンスを行う。MLOpsチームは、インフラ周りのコードを抽象化し、E2Eチームがドメイン周りのコードのみに集中できるように日々努めている。 | プラットフォームを提供し、その上で自由に開発をしてもらうパターン。ただし一定のガードレール(権限、使用量のモニタリングなど)は設定する。 |
| 例 | ・データ可視化ツール(webアプリケーション) ・シーンのタグを管理するテーブル |
・データセット作成ツール(データの変換方法、フォーマット等はMLエンジニアが書く) ・オートラベリングツール(オートラベリングに使うモデルはMLエンジニアが開発する) |
・Databricks(DWHや、full managedのnotebook/spark環境として利用。ただしメインとなるテーブルはMLOpsが管理) ・Coder(任意のコンピュテーション環境を構築できる) ・AWS Sagemaker Hyperpod(GPU学習環境) |
これらの形態を、最初のドメインを説明した時の図で表現すると、下の図のようになります。
最初の説明では、MLOpsの領域は決まっているかのように見えたかもしれませんが、実際にはカバーする領域は、いろいろなバリエーションが存在するのです。
サービスの信頼性・効率性向上に向けた取り組み
SaaSやPaaSを提供している以上、信頼性向上に向けた取り組みも必要です。また、インフラにかかるコストを監視し、これらのサービスの効率を向上させることも重要です。信頼性・効率性向上を実現すべく、MLOpsチームでは一般的なDevOpsのプラクティスに則って開発を行っています。
-
CI/CD(継続的インテグレーション/継続的デリバリー)
github actionsを用いてコードの変更を自動的にビルド・テストし、本番環境へのデプロイまでを迅速かつ安全に行う仕組みを構築しています。
-
Infrastructure as Code(IaC)
AWS CDKを使って、インフラ構成をコードで管理し、環境の再現性の担保や、適用前のレビューを可能にしています。
-
モニタリングとアラート
アプリケーションやインフラのメトリクス・ログ・トレースを継続的に監視し、異常時にはSlackに通知するなどの工夫を行っています。
-
継続的改善(Continuous Improvement)
週次で実施しているレトロスペクティブや、障害対応後のポストモーテムを通じて、プロセス・ツール・チーム体制を改善し続けられるように努めています。
また、これらのプラクティスをMLの開発自体に適用する試みも行っています。一般的に、「MLOps」と言うと、これらの取り組みを指すことが多いかもしれません。
例えば、モデルのCIとしてのシナリオテストや、データセット・モデル・実験結果のバージョン管理を行い、それらの間のトレーサビリティを管理する、といったものです。MLOpsチームでは、これらの機能をSaaSとして提供できるよう、開発を進めています。
ユーザーをよく理解するための取り組み
一般的なプロダクト開発がそうであるように、MLOpsチームも、提供するプラットフォーム・ツールのユーザーを詳しく理解することがとても大切です。モデルがどのように開発されているか、E2Eチームがいまどのような課題を抱えているかを正確に理解することで、より良いプラットフォーム・ツールを提供できると考えています。そのために、E2Eチームとの距離を短くすることをとても大事にしており、具体的には以下のような取り組みを行っています。
- 勉強会の開催
週に2回、E2Eチーム、MLOpsチームのそれぞれが、直近の開発内容について、特に技術的な側面を中心に紹介する、勉強会を開催しています。
- スクラムイベントのオブザーブ
プランニングなどのスクラムイベントをオブザーブさせてもらうことで、直近の開発アイテムや課題についての理解を深めています。
- Office Hourの設置
Turingは、大崎とTRC(東京流通センター)の2拠点にオフィスが存在しています。MLOpsチームの拠点は大崎のオフィスなのですが、E2Eチームは実験のためTRCに行っている場合も多いため、MLOpsチームのメンバーの少なくとも1人がTRCに出勤することで、何かあったときに声をかけてもらいやすい環境づくりを行っています。
まとめ
今回ご紹介したように、TuringのMLOpsチームは、E2Eチームが自動運転モデル開発に集中できる環境を整え、開発効率を向上させることをミッションとしています。
ドメイン知識を理解しつつも、より横断的な視点からツールやインフラを整備することで、MLエンジニアの新しいニーズに素早く答えられるよう心がけています。
今後も、E2Eチームの開発するモデルの高度化やチームの拡大に伴い、MLOpsチームにも、より複雑な機能の開発や、スケーラビリティ・信頼性のさらなる向上などが求められると考えられます。そのようなデマンドに応えられるよう、これからもMLOpsチームは成長を続けていきます。

Discussion