はじめに
Turing Researchチームの佐々木(kento_sasaki1)です。Researchチームでは、完全自動運転の実現に向けて、マルチモーダル基盤モデルの開発に取り組んでいます。
先日、私たちは日本語Vision Language Model (VLM) のベンチマーク「Heron-Bench」を新たに公開しました。本記事ではHeron-Benchについて解説し、日本語VLMの現状と今後の展望について述べます。詳細についてはarXiV論文 「HERON-BENCH: A BENCKMARK FOR EVALUATING VISION LANGUAGE MODELS IN JAPANESE 」も公開していますので、合わせてご覧ください。
自動運転とVision Language Model
本題に入る前に、まず「TuringがなぜVision Language Modelの開発を行っているのか」について述べたいと思います。
VLMは大規模言語モデル (LLM)に視覚を持たせたマルチモーダルモデルであり、画像と質問を入力すると、画像の状況を判断して回答することができます。TuringではこれまでHeronというVLMを学習できるフレームワークを開発しており、私たちが開発したモデルでは以下のツイートのように高速道路で豚さんが沢山いる状況において、「画像では、高速道路の車線を走る車と、道路を横断する3頭の豚が写っている。この状況ではドライバーは慎重になり、豚に危害を加えたり、事故を引き起こしたりしないように注意する必要がある。(略)」と状況判断ができます。
完全自動運転では、この事例のようにロングテールのあらゆるエッジケースに対して適切に判断できることが求められます。これを実現するために、運転の知識に加えて一般常識と言われるような知識をうまく組み込むことで対応できるのではないかと注目が集まっています。こうした背景から、最近では企業・アカデミアの両方で「自動運転とVision Language Model」をテーマにした取り組みが加速しています。
直近では、Tesla CEOのイーロン・マスク率いるAI企業「xAI」は、4月12日にGrok-1.5 Vsionを公表しました。Grok-1.5 Visionは、xAIが発表する初めてのマルチモーダルモデルです。このモデルは、チャート図の写真からコードを生成したり、カメラ画像から運転状況の判断を行うことができます。ブログでは、現実世界の空間理解を評価するRealWorldQAベンチマークを導入していることが紹介されており、以下のような事例が挙げられています。

その他にも、中国のOpenDriveLabが「自動運転に向けたVQA」や「世界モデル」に関する研究で注目を集めています。例えば、DriveLM: Driving with Graph Visual Question Answering [Chonghao Sima, Katrin Renz, et al., 2023]では、走行画像に対してPerception, Prediction, Plannning, Behavior, MotionのQAを付与したデータセットを作成し、運転状況理解を目的としたモデルを公開しています。
このモデルでは、自動運転車がフロントカメラから画像を取得している状況を考えます。
 https://opendrivelab.com/DriveLM/
https://opendrivelab.com/DriveLM/
「Perception」では、画像から重要なオブジェクトを見つけ出し、それらの位置や状態を認識します。これらの情報は、「What obects should the ego-car notice?」, 「The white car is …」のようにQAペアで表されます。これらのQAペアは、グラフ構造の頂点となります。「Prediction」では、Perceptionで認識されたオブジェクトの将来の動きや相互作用を予測します。「What may these obects do in the future?」, 「The white car is going to turn left」のように表されます。そして、「Planning」では、「What should the ego-car do in the future?」, 「Go straight and cross the dashed laneline」のように取るべき安全な行動を計画します。これらの計画は、Perceptionで認識された環境の状態と、Predictionで予測したオブジェクトの将来の動きを考慮します。この後、Planningを実行するための「Behavior」(速度と操舵角度)のQAとBehaviorに基づき、自車のTrajectoryを出力する「Motion」があり、グラフの枝が順に伸びていきます。
日本語VLMの性能評価ベンチマーク Heron-Bench
次に本題である、Heron-Benchについて紹介します。
背景
日本語LLMの評価指標としては、llm-jp-evalやJapaneese MT-Benchがあり、これらが広く使われています。一方で、現状では日本語の高い言語能力を有するLLMを用いて日本語データで学習されたVLMはほとんど公開されておらず、日本語VLMの性能を適切に評価する方法も確立されていない課題があります。こうした状況を踏まえて、私たちは自動運転のドメインに限定せず、日本語VLMの発展に向けてHeron-Benchという汎用的な性能評価ベンチマークを提案しました。
また、日本語VLMのベースラインモデルとしてHeron GITを公開しました。GitHubのHeronリポジトリで学習データセット、モデルファイル、コードを全て公開しています。また、デモサイトで簡単に試すことができます。
データセットの作成
Heron-Benchは、LLaVA-Bench-in-the-wild [Haotian Liu, Chunyuan Li, et. al., 2023]を参考に作成した、日本特有の画像と質問のペアデータセットです。日本特有の画像を21枚収集し、各画像に対してConversation, Detail, Complexの3つのカテゴリーを設定しています。さらに、各カテゴリーごとにいくつかの質問を用意しており、合計102の画像と質問のペアデータを含みます。また、以下の図に示すように、各画像にアニメ、アート、文化、フード、景色、ランドマーク、交通の7つのサブカテゴリーのいずれかを付与しています。
 Heron-Benchのサブカテゴリ一覧
Heron-Benchのサブカテゴリ一覧
Heron-Benchのスコア算出
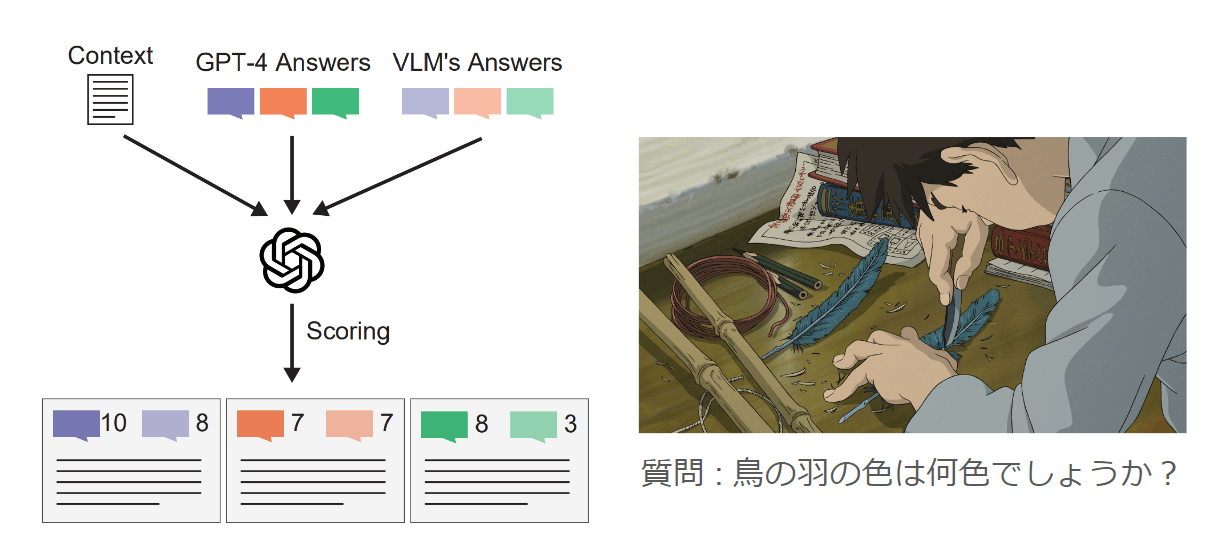
Heron-Benchは、GPT-4を審判としてスコアを算出します。事前準備として、GPT-4にContextと質問を含むPromptを与えて回答させ、模範解答(GPT-4 Answers)を用意します。スコアは、Context, GPT-4V Answers, VLM’s AnswersをGPT-4に入力し、10点満点で評価して算出されます。
例えば、「鳥の羽の色は何色でしょうか?」という質問に対するGPT-4 Answerは、「鳥の羽の色は青色です。」です。これに対して、VLM (例 : Claude 3 Opus) が「鳥の羽の色は青色です。画像では、青い羽ペンを持っている人物の手が描かれています。」と回答した場合、GPT-4は「GPT-4 Answerは過不足なく回答しているため10点満点、Claude 3 Opusは青色と正しく言及していますが質問の意図とは異なる情報を含んでいるため、7点です。」のように自動判定します。
ベースラインモデル Heron GIT
Heron-Benchに加えて、ベースラインモデルとしてHeron GITを提案しました。Heron GITはLLMにjapanese-stablelm-base-alpha-7b [Meng Lee, Fujiki Nakamura, et al., 2023]、画像を認識するVision-EnoderにCLIP [Alec Radford, Jong Wook Kim, et al., 2021]、AdapterにGIT [Jianfeng Wang, Zhengyuan Yang, et al., 2022]を用いて学習しています。Heronについては、以前のテックブログ「日本語Vision Languageモデル heron-blip-v1の公開」でも詳しく書かれていますので、ご参照ください。
Heron-Benchを用いた各種モデルの性能評価
Heron-Benchを用いて様々なVLMの日本語の性能評価を行いました。Closed modelとして、GPT-4V, Claude 3 Opus, Gemini Pro Vision、Open modelとしてLLaVA-1.6 (7B), LLaVA-1.5 (7B), Qwen-VL (7B), EvoVLM-JP,そして今回提案しているベースラインモデルHeron GITを比較しました。
定量評価
各モデルの評価結果を下図に示しています。Heron-Benchの他に、LLaVA-Bench (In the Wild)を日本語訳したベンチマークの結果も示しています。
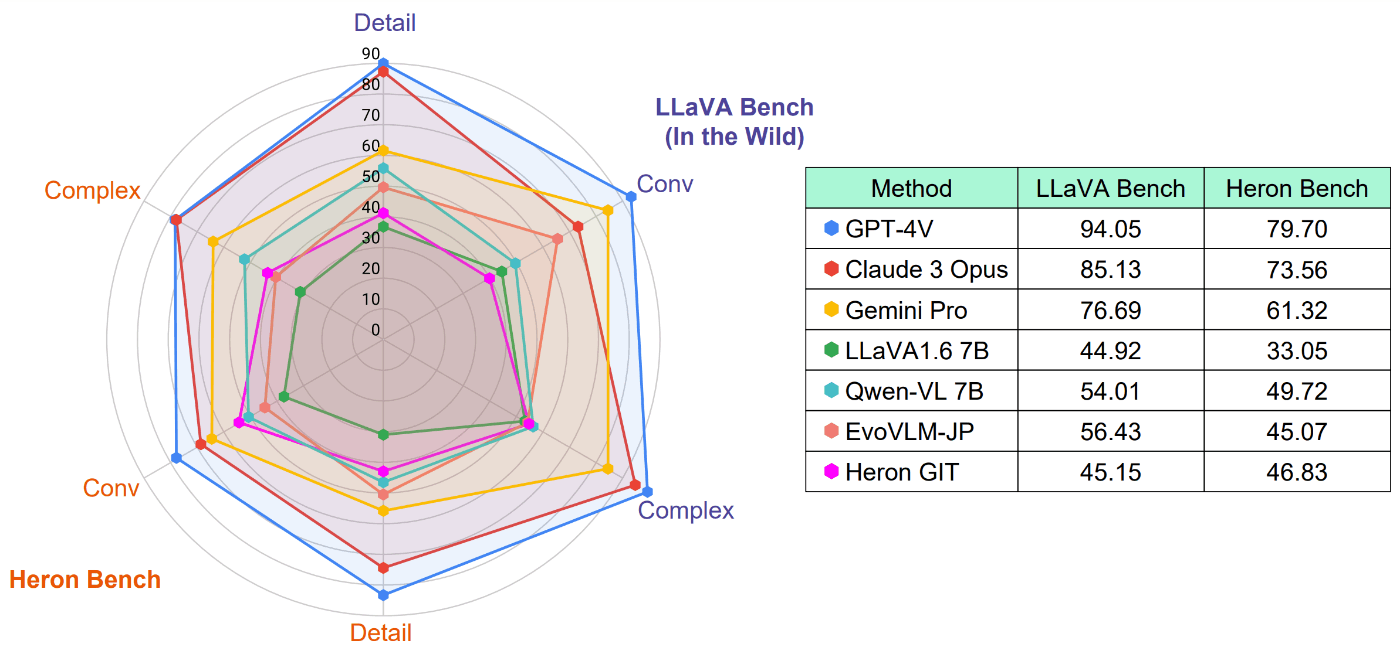
Closed modelであるGPT-4VやClaude 3 Opusは一貫して高いスコアを達成しています。Open modelの中では、大規模な画像-テキストペアで学習されたQwen-VLが最も高いスコアとなっています。また、日本を拠点とするSakana AIが提案したEvoVLM-JPは、他のOpen modelよりも日本語版LLaVA-Bench (In-the-Wild) で高いスコアを達成しています。
私たちが今回提案しているベースモデルのHeron GITは、日本語版LLaVA-Bench (In-the-Wild) においてLLaVA 1.6 (7B)をわずかに上回る性能ですが、Heron-BenchではEvoVLM-JPと同等のスコアを達成しています。
定性評価
続いて、定性評価を行います。Heron-Benchの質問に対するHeron GIT, GPT-4V, Claude 3 Opusが生成した回答を示します。
Heron-Bench (Conversation) の回答例
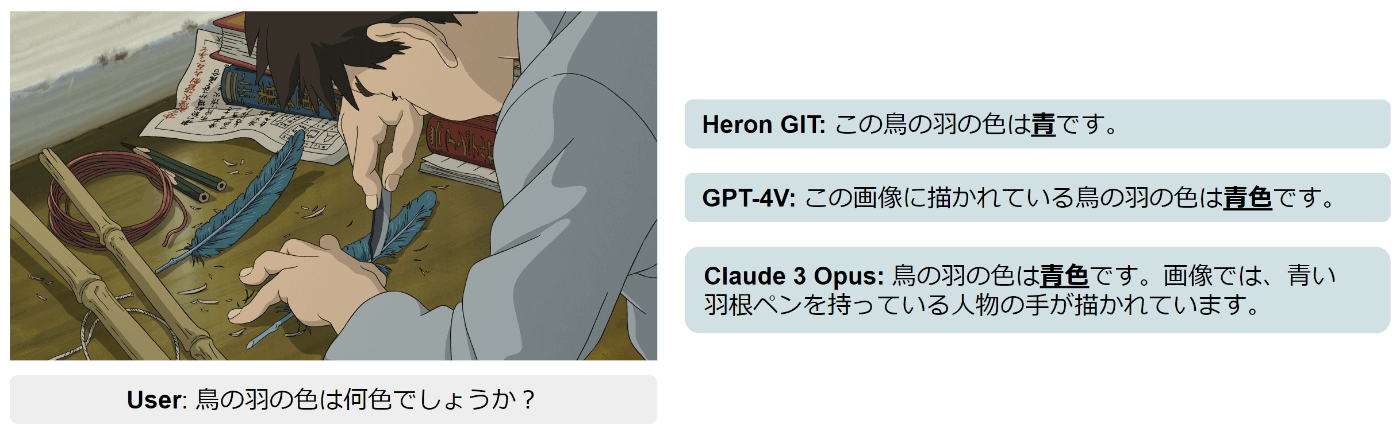
この写真は、ジブリ映画「君たちはどう生きるか」の一場面です。「鳥の羽の色は何色でしょうか?」のように単純な会話形式の質問に関しては、Heron GITはGPT-4VやClaude 3 Opusと同等の回答能力を示しています。Heron GIT は他のOpen modelと比較して、特にConversationカテゴリーにおいて高いスコアを示してより、この結果は人間による主観的評価とも一致しています。
Heron-Bench (detail) の回答例

大阪場所における横綱の土俵入りの写真です。この写真について、「力士たちは何を行っているのか説明してください。」と質問を投げかけたとき、Heron GIT, GPT-4V, Claude 3 Opusはすべて誤った回答をしています。私たちに人間にとっては、力士は土俵に3人いることは明らかですが、すべてのモデルが「2人の力士が対峙」のように回答している点が特徴的です。
このような回答をしてしまうのは、相撲が通常2人で行われるという一般的な知識に影響された結果だと考えています。相撲の他にも、日本特有の文化や知識を問う質問に対する誤答は複数確認でき、Heron-Benchはこのような日本の文化や知識理解の評価に有効であると考えられます。
Heron-Bench (complex) の回答例
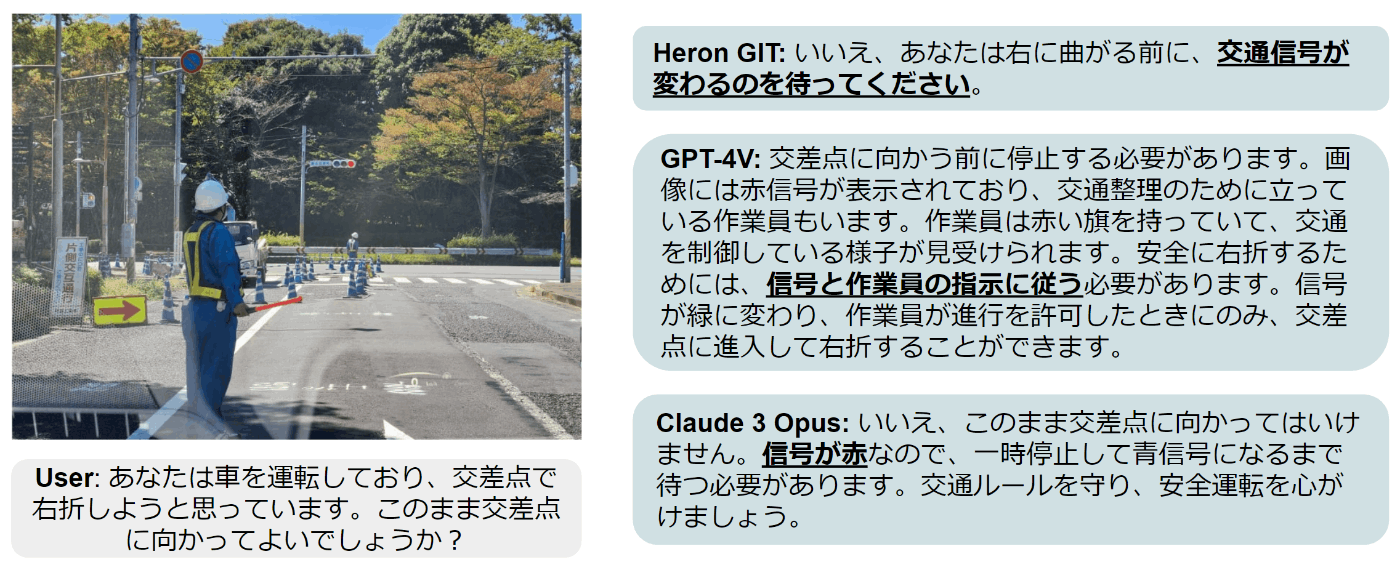
こちらは、柏の葉キャンパス駅からTuring Nova工場に自動車で向かってるときに遭遇した工事現場の写真です。この状況において「あなたは車を運転しており、交差点で右折しようと思っています。このまま交差点に向かってよいでしょうか」と質問をすると、Heron GIT, GPT-4V, Claude 3 Opusのいずれも信号機の色を正しく認識し、停止の判断ができていました。一方で、GPT-4Vのみが信号機と交通作業員の指示の両方を正しく理解できていました。自動運転において、作業員の指示や他のエージェント(歩行者やドライバー)の意図を理解するのかは大きな課題となっていますが、VLMはこうした課題の解決における糸口になると示唆する事例となっています。
現状の課題と今後の展望
現状、Heron-Benchの評価スコアはGPT-4の判断に基づいているため、GPT-4自体の性能に依存しています。また、定性評価を通じて明らかになったように現在のVLMは、オブジェクトのカウントやオブジェクト同士の関係理解が不十分である場合があり、さらなるモデルの改善が必要と考えられます。
さらに、自動運転やロボティクスの分野に応用するためには時間的・空間的な理解能力の向上が欠かせません。現在、Turingではこれら課題の解決に向けて取り組んでいます。
おわりに
本記事では、日本語VLMの汎用的な性能評価を目的としたベンチマーク「Heron-Bench」と、ベースラインモデルとして「Heron GIT」を紹介しました。Heron-Benchには、日本特有の画像と質問応答のペアデータが含まれており、日本語VLMの性能を詳細に分析することが可能になります。ぜひ日本語VLMの評価にご活用ください。
Turingは「We Overtake Tesla」をミッションに完全自動運転の実現に向けて尽力しています。経済産業省/NEDOの競争力のある生成AI基盤モデルの開発を支援するGENIACプロジェクトにも採択され、生成AI・大規模基盤モデルの開発を進めています。完全自動運転に向けたマルチモーダルな基盤モデルの開発にご興味ある方、お気軽にコメントやX (Twitter) のDMにてお問合せください。
お知らせ
先月、Turing Semiconductor/AI Day 2024を開催し、Turingエンジニアが生成AIと自動運転に関する最新の研究成果、領域のホットトピックについて発表しました。YouTubeで録画映像を公開していますので、ぜひご覧ください。

Discussion