はじめに
Turing の生成 AI チームでインターンをしている塩野 (@onely7_deep) です。
生成 AI チームでは、完全自動運転の実現に向けてマルチモーダル基盤モデルの開発に取り組んでいます。
本記事では、Turing からリリースされた盛り沢山な GENIAC の成果物 の中の1つである The Cauldron JA と Wikipedia Vision JA データセットを紹介します!
The Cauldron JA データセット
The Cauldron データセットに関して
The Cauldron データセットは、huggingface が idefics2 の公開と同時にリリースした VLM (Vision-Language Model) の fine-tuning 用の V&L (Vision & Language) データセットです。
VLM を fine-tuning する際には、Captioning, VQA, Chart/Figure understanding など様々なタスク指向の V&L データセットが使用されますが、これらの既存のデータセットは多くの場合、ファイル形式やデータ形式が異なっていることや、データセットの保存場所が点在してしまっているといったような問題を抱えています。
そのため、これまでは点在した V&L データセットを手元にダウンロードし、すべてのデータ形式をユーザー側で統一する必要がありました。
しかし、この作業には予想以上の手間がかかるので、VLM の fine-tuning によく使われる V&L データセットが同じデータ形式で1つの保存場所にまとまっていたらいいのになぁ … と思うわけです。
この願いを叶えたデータセットが、The Cauldron データセットです!
The Cauldron データセットには、50 のタスク指向の V&L データセットが同一のデータ形式でまとめられており、V&L の fine-tuning データセットとして大変扱いやすくなっています。
以下に、A-OKVQA のオリジナルのデータ形式を The Cauldron のデータ形式に変換する一例を示します。
# A-OKVQA の場合
## Original format (変換するにあたり関係のない一部のkeyは除く)
{
"image": <image_path>,
"question": "What is the man by the bags awaiting?",
"choices": [ "skateboarder", "train", "delivery", "cab" ],
"correct_choice_idx": 3
}
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
## The Cauldron format
{
"images": <image_path>,
"texts": [
{
"user": "What is the man by the bags awaiting?\nMake your selection from the four choices given to correctly answer the question.\nOptions: Skateboarder, train, delivery, cab.",
"assistant": "Cab.",
"source": "A-OKVQA"
}
]
}
このように、The Cauldron では、50 のタスク指向の V&L データセットをすべて、上のようなデータ形式に変換することで、データ形式の統一を実現しています。
The Cauldron JA データセットに関して
私達は、この The Cauldron データセットを DeepL API を用いて日本語に翻訳することで、The Cauldron JA データセットを作成しました。
ただし、The Cauldron JA を作成するにあたって、以下の一部のデータセットは、日本語に翻訳するとデータの一貫性が失われると判断したため除外しました。
The Cauldron JA 作成において、除外した 6 つのサブデータセット
| Dataset | Category | Example Image | Example Data |
|---|---|---|---|
| IAM | OCR, document understanding, text |  |
[ { "user": "What does the handwriting in this picture say?", "assistant": "A MOVE to stop Mr. Gaitskell from nominating any more Labour life Peers is to be made at a meeting of Labour MPs tomorrow.", "source": "IAM" }, … ] |
| OCR-VQA | OCR, document understanding, text |  |
[ { "user": "Who wrote this book?\nProvide a short and direct response.", "assistant": "Rosy Daniel.", "source": "ocrvqa" }, … ] |
| RenderedText | OCR, document understanding, text |  |
[ { "user": "What's written on the object in this image?", "assistant": ""The 1966\nBroadway\nmusical\n"Walking\nHappy" is\nbased on\nthe play.", "source": "Rendered text" }, … ] |
| PlotQA | Chart/figure understanding |  |
[ { "user": "How many different coloured dotlines are there?\nProvide a succinct answer.", "assistant": "2.", "source": "plotqa" }, … ] |
| DaTikz | Screenshot to code |  |
[ { "user": "Transform this figure into its TikZ equivalent.", "assistant": "\documentclass[10pt,twosided,a4paper,draft,onecolumn]{article}\n\usepackage{tikz}\n … \end{document}", "source": "DaTikz" }, … ] |
| WebSight | Screenshot to code |  |
[ { "user": "Synthesize the HTML to emulate this website's layout.", "assistant": "<html>\n\ … </body>\n</html>", "source": "WebSight_v02" }, … ] |
最終的に、The Cauldron JA には 44 のサブデータセットが存在します。
この The Cauldron JA の統計量を以下の表にまとめました。
また、Token に関する情報は、tokyotech-llm/Llama-3-Swallow でも採用されている Llama 3 の tokenizer (vocab_size: 128,256) を使用して、質問 ("user"), 応答 ("assistant") 部分の日本語テキストを tokenize することで算出しています。
表中のカラムの説明
-
Dataset: データセット名 -
Category: カテゴリ名(Building and better understanding vision-language models: insights and future directions (Laurençon et al., 2024) と同様のカテゴリ名を使用)- Captioning
- Real-world visual question answering
- OCR, document understanding, text transcription
- Chart/figure understanding
- Table understanding
- Reasoning, logic, maths, geometry
-
# data num: データ数 -
# images: 画像数 -
# QA pairs: 質問・応答ペアの数 -
Example Image: データセットに含まれる画像の 1 例 -
# tokens num: データセット内の質問・応答に含まれる全 token 数 -
# tokens (Mean): 1 データあたりの質問・応答に含まれる平均 token 数 -
# tokens (Standard Deviation): 1 データあたりの質問・応答に含まれる token 数の標準偏差 -
# tokens (Min): 1 データあたりの質問・応答に含まれる最小 token 数 -
# tokens (Max): 1 データあたりの質問・応答に含まれる最大 token 数 -
# data num per image num: 画像枚数あたりのデータ数の辞書{<key>: <画像枚数>, <value>: <データ数>}- 例えば、
{1: 20919, 2: 21081}の場合、画像 1 枚のデータ数が 20,919 件、画像 2 枚のデータ数が 21,081 件あると読み取れる
-
# data num per QA pairs num: 質問・応答ペアの数あたりのデータ数の辞書{<key>: <質問・応答ペアの数>, <value>: <データ数>}- 例えば、
{1: 15717, 2: 13}の場合、質問・応答ペア 1 つのデータ数が 15,717 件、質問・応答ペア 2 つのデータ数が 13 件あると読み取れる
-
# %ratio: The Cauldron JA データセット全体に含まれるデータ数あたりのデータ数の割合
| Dataset | Category | # data num | # images | # QA pairs | Example Image | # tokens num | # tokens (Mean) | # tokens (Standard Deviation) | # tokens (Min) | # tokens (Max) | # data num per image num | # data num per QA pairs num | # %ratio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LNarratives | Captioning | 199,998 | 199,998 | 199,998 |  |
12,110,448 | 60.6 | 23.5 | 12 | 428 | {1: 199998} | {1: 199998} | 8.86 |
| Screen2Words | Captioning | 15,730 | 15,730 | 15,743 |  |
433,645 | 27.6 | 5.82 | 10 | 73 | {1: 15730} | {1: 15717, 2: 13} | 0.70 |
| TextCaps | Captioning | 21,953 | 21,953 | 21,953 |  |
705,606 | 32.1 | 7.19 | 8 | 82 | {1: 21953} | {1: 21953} | 0.97 |
| VisText | Captioning | 9,969 | 9,969 | 9,969 |  |
1,498,467 | 150.3 | 36.9 | 50 | 343 | {1: 9969} | {1: 9969} | 0.44 |
| COCO-QA | Real-world visual question answering | 46,287 | 46,287 | 78,736 |  |
1,652,333 | 35.7 | 22.5 | 1 | 279 | {1: 46287} | {1: 25517, 2: 12784, 3: 5341, 4: 1870, 5: 581, 6: 145, 7: 33, 8: 8, 9: 4, 10: 3, 12: 1} | 2.05 |
| MIMIC-CGD | Real-world visual question answering | 70,939 | 141,878 | 141,869 |  |
7,801,511 | 110.0 | 22.7 | 37 | 428 | {2: 70939} | {1: 13, 2: 70924, 4: 2} | 3.14 |
| OK-VQA | Real-world visual question answering | 9,009 | 9,009 | 9,009 |  |
229,842 | 25.5 | 5.55 | 8 | 78 | {1: 9009} | {1: 9009} | 0.40 |
| Visual7W | Real-world visual question answering | 14,366 | 14,366 | 69,817 |  |
3,407,904 | 237.2 | 157.0 | 37 | 1,630 | {1: 14366} | {1: 348, 2: 1238, 3: 2535, 4: 3527, 5: 3231, 6: 1943, 7: 703, 8: 114, 9: 13, 10: 16, 11: 24, 12: 42, 13: 60, 14: 69, 15: 92, 16: 100, 17: 103, 18: 65, 19: 57, 20: 35, 21: 22, 22: 10, 23: 7, 24: 3, 25: 3, 26: 3, 28: 1, 31: 1, 32: 1} | 0.64 |
| VQAv2 | Real-world visual question answering | 82,772 | 82,772 | 443,757 |  |
9,468,346 | 114.4 | 112.1 | 38 | 5,884 | {1: 82772} | {3: 38666, 4: 14528, 5: 8444, 6: 5216, 7: 3634, 8: 2574, 9: 1808, 10: 1377, 11: 1057, 12: 838, 13: 669, 14: 543, 15: 454, 16: 397, 17: 309, 18: 264, 19: 224, 20: 196, 21: 167, 22: 166, 23: 121, 24: 112, 25: 100, 26: 83, 27: 70, 28: 65, 29: 48, 30: 50, 31: 49, 32: 57, 33: 52, 34: 24, 35: 41, 36: 33, 37: 23, 38: 23, 39: 15, 40: 12, 41: 20, 42: 20, 43: 10, 44: 15, 45: 11, 46: 14, 47: 12, 48: 10, 49: 9, 50: 10, 51: 12, 52: 3, 53: 7, 54: 2, 55: 4, 56: 4, 57: 2, 58: 6, 59: 4, 60: 3, 61: 2, 63: 5, 64: 4, 65: 5, 66: 2, 67: 3, 68: 3, 69: 3, 70: 4, 71: 5, 72: 1, 73: 1, 75: 3, 76: 3, 77: 3, 78: 3, 80: 3, 82: 2, 83: 3, 84: 1, 85: 1, 87: 4, 92: 1, 93: 1, 95: 3, 96: 2, 97: 1, 99: 1, 100: 3, 103: 1, 108: 1, 112: 1, 125: 1, 130: 1, 137: 1, 159: 1, 176: 1, 275: 1} | 3.67 |
| VSR | Real-world visual question answering | 2,157 | 2,157 | 3,354 |  |
127,174 | 59.0 | 41.6 | 24 | 472 | {1: 2157} | {1: 1486, 2: 391, 3: 147, 4: 75, 5: 31, 6: 14, 7: 6, 8: 4, 9: 1, 10: 1, 13: 1} | 0.10 |
| Diagram image-to-text | OCR, document understanding, text transcription | 300 | 300 | 300 |  |
34,988 | 116.6 | 55.9 | 29 | 401 | {1: 300} | {1: 300} | 0.01 |
| DocVQA | OCR, document understanding, text | 10,189 | 10,189 | 39,463 |  |
1,067,589 | 104.8 | 73.0 | 3 | 476 | {1: 10189} | {1: 1795, 2: 1940, 3: 1636, 4: 1507, 5: 984, 6: 707, 7: 486, 8: 392, 9: 291, 10: 433, 11: 13, 12: 5} | 0.45 |
| InfoVQA | OCR, document understanding, text | 2,118 | 2,118 | 10,074 |  |
320,334 | 151.2 | 106.4 | 3 | 839 | {1: 2118} | {1: 245, 2: 355, 3: 286, 4: 255, 5: 263, 6: 212, 7: 130, 8: 98, 9: 70, 10: 139, 11: 10, 12: 16, 13: 7, 14: 5, 15: 10, 16: 3, 17: 4, 18: 3, 20: 4, 23: 1, 26: 1, 28: 1} | 0.09 |
| ST-VQA | OCR, document understanding, text | 17,247 | 17,247 | 23,121 |  |
554,026 | 32.1 | 16.3 | 1 | 154 | {1: 17247} | {1: 12666, 2: 3332, 3: 1213, 4: 30, 5: 5, 7: 1} | 0.76 |
| TextVQA | OCR, document understanding, text | 21,953 | 21,953 | 34,602 |  |
820,209 | 37.4 | 14.1 | 2 | 117 | {1: 21953} | {1: 9304, 2: 12649} | 0.97 |
| VisualMRC | OCR, document understanding, text | 3,027 | 3,027 | 11,988 |  |
429,754 | 142.0 | 110.1 | 35 | 2,440 | {1: 3027} | {3: 2472, 6: 331, 9: 125, 12: 51, 15: 29, 18: 12, 21: 4, 24: 1, 36: 1, 54: 1} | 0.13 |
| Chart2Text | Chart/figure understanding | 26,961 | 26,961 | 30,215 |  |
3,799,803 | 140.9 | 83.4 | 22 | 1,412 | {1: 26961} | {1: 23718, 2: 3233, 3: 9, 4: 1} | 1.19 |
| ChartQA | Chart/figure understanding | 18,265 | 18,265 | 28,287 |  |
881,602 | 48.3 | 24.1 | 8 | 268 | {1: 18265} | {1: 10334, 2: 6312, 3: 1218, 4: 344, 5: 43, 6: 14} | 0.81 |
| DVQA | Chart/figure understanding | 200,000 | 200,000 | 2,325,316 |  |
62,818,679 | 314.1 | 83.9 | 59 | 585 | {1: 200000} | {3: 2, 4: 259, 5: 1127, 6: 2414, 7: 6223, 8: 11582, 9: 14459, 10: 20780, 11: 33896, 12: 37263, 13: 29334, 14: 21263, 15: 13544, 16: 5994, 17: 1597, 18: 241, 19: 20, 20: 2} | 8.86 |
| FigureQA | Chart/figure understanding | 100,000 | 100,000 | 1,327,368 |  |
35,925,965 | 359.3 | 85.1 | 47 | 599 | {1: 100000} | {2: 118, 3: 178, 4: 33, 5: 191, 6: 401, 7: 98, 8: 182, 9: 2715, 10: 3648, 11: 8927, 12: 52825, 13: 1281, 14: 2308, 15: 1949, 16: 90, 17: 2697, 18: 22359} | 4.43 |
| MapQA | Chart/figure understanding | 37,417 | 37,417 | 483,416 |  |
23,278,461 | 622.1 | 288.0 | 16 | 3,105 | {1: 37417} | {1: 65, 2: 216, 3: 574, 4: 937, 5: 1216, 6: 1204, 7: 933, 8: 553, 9: 314, 10: 241, 11: 451, 12: 1193, 13: 3106, 14: 7911, 15: 18503} | 1.66 |
| FinQA | Table understanding | 5,276 | 5,276 | 6,251 |  |
6,892,316 | 1306.4 | 783.7 | 47 | 8,676 | {1: 5276} | {1: 4517, 2: 574, 3: 158, 4: 25, 5: 1, 7: 1} | 0.23 |
| HiTab | Table understanding | 2,500 | 2,500 | 7,782 |  |
493,907 | 197.6 | 308.4 | 5 | 2,919 | {1: 2500} | {1: 1166, 2: 432, 3: 209, 4: 164, 5: 119, 6: 118, 7: 65, 8: 53, 9: 34, 10: 29, 11: 25, 12: 19, 13: 14, 14: 6, 15: 5, 16: 10, 17: 6, 18: 5, 19: 4, 20: 1, 21: 2, 22: 2, 23: 1, 24: 2, 25: 3, 26: 1, 27: 1, 28: 2, 29: 2} |
0.11 |
| MultiHiertt | Table understanding | 7,619 | 30,875 | 7,830 |  |
394,657 | 51.8 | 19.3 | 1 | 286 | {3: 3047, 4: 2314, 5: 1318, 6: 692, 7: 248} | {1: 7444, 2: 143, 3: 28, 4: 4} | 0.34 |
| SQA | Table understanding | 8,514 | 8,514 | 34,141 |  |
2,304,067 | 270.6 | 401.6 | 22 | 7,295 | {1: 8514} | {2: 2185, 3: 3362, 4: 1490, 5: 476, 6: 265, 7: 163, 8: 109, 9: 95, 10: 66, 11: 41, 12: 29, 13: 24, 14: 28, 15: 18, 16: 19, 17: 16, 18: 12, 19: 7, 20: 9, 21: 7, 22: 12, 23: 10, 24: 7, 25: 6, 26: 2, 27: 2, 28: 1, 30: 5, 31: 4, 32: 2, 33: 5, 34: 5, 35: 1, 36: 3, 37: 1, 38: 1, 41: 4, 44: 1, 45: 4, 47: 1, 48: 1, 51: 1, 53: 2, 56: 2, 57: 3, 58: 2, 59: 1, 63: 1, 64: 1, 67: 1, 73: 1} | 0.38 |
| WikiSQL | Table understanding | 74,989 | 74,989 | 86,202 |  |
10,136,361 | 135.2 | 408.7 | 1 | 10,497 | {1: 74989} | {1: 63776, 2: 11213} | 3.32 |
| WTQ | Table understanding | 38,246 | 38,246 | 44,096 |  |
6,406,081 | 167.5 | 549.9 | 1 | 13,625 | {1: 38246} | {1: 32396, 2: 5850} | 1.69 |
| TabMWP | Table understanding | 22,722 | 22,722 | 23,021 |  |
2,847,066 | 125.3 | 106.6 | 19 | 2,754 | {1: 22722} | {1: 22662, 2: 2, 3: 6, 4: 9, 5: 11, 6: 11, 7: 5, 8: 8, 9: 4, 10: 1, 11: 1, 12: 2} | 1.01 |
| TAT-QA | Table understanding | 2,199 | 2,199 | 13,215 |  |
1,418,194 | 644.9 | 377.2 | 184 | 4,533 | {1: 2199} | {6: 2189, 7: 7, 8: 1, 12: 2} | 0.10 |
| TQA | Table understanding | 1,493 | 1,493 | 6,482 |  |
347,443 | 232.7 | 102.0 | 40 | 581 | {1: 1493} | {1: 70, 2: 189, 3: 257, 4: 292, 5: 278, 6: 210, 7: 144, 8: 42, 9: 9, 10: 2} | 0.07 |
| AI2D | Reasoning, logic, maths, geometry | 2,434 | 2,434 | 7,462 |  |
447,424 | 183.8 | 230.1 | 15 | 1,479 | {1: 2434} | {1: 1019, 2: 947, 3: 5, 4: 17, 5: 19, 6: 39, 7: 13, 8: 24, 9: 59, 10: 79, 11: 113, 12: 88, 14: 1, 15: 1, 18: 3, 19: 1, 20: 1, 21: 1, 22: 2, 23: 1, 24: 1} | 0.11 |
| A-OKVQA | Reasoning, logic, maths, geometry | 16,539 | 16,539 | 17,056 |  |
1,243,512 | 75.2 | 22.5 | 31 | 238 | {1: 16539} | {1: 16022, 2: 517} | 0.73 |
| CLEVR | Reasoning, logic, maths, geometry | 70,000 | 70,000 | 699,989 |  |
25,659,527 | 366.6 | 30.5 | 49 | 523 | {1: 70000} | {2: 1, 9: 3, 10: 69996} | 3.10 |
| CLEVR-Math | Reasoning, logic, maths, geometry | 70,000 | 70,000 | 788,650 | |
26,623,723 | 380.3 | 103.2 | 171 | 718 | {1: 70000} | {6: 1897, 7: 1480, 8: 20065, 9: 6347, 10: 3100, 11: 2817, 12: 3548, 13: 5079, 14: 7729, 15: 16539, 16: 1399} | 3.10 |
| GeomVerse | Reasoning, logic, maths, geometry | 9,303 | 9,303 | 9,339 |  |
3,099,284 | 333.1 | 164.8 | 43 | 1,190 | {1: 9303} | {1: 9267, 2: 36} | 0.41 |
| HatefulMemes | Reasoning, logic, maths, geometry | 8,500 | 8,500 | 8,500 |  |
242,064 | 28.5 | 2.83 | 24 | 33 | {1: 8500} | {1: 8500} | 0.38 |
| IconQA | Reasoning, logic, maths, geometry | 27,307 | 27,307 | 29,841 |  |
1,160,029 | 42.5 | 43.4 | 7 | 1,266 | {1: 27307} | {1: 26155, 2: 681, 3: 218, 4: 103, 5: 29, 6: 33, 7: 15, 8: 14, 9: 13, 10: 9, 11: 10, 12: 7, 13: 8, 14: 3, 15: 4, 16: 2, 17: 1, 21: 2} | 1.21 |
| Inter-GPs | Reasoning, logic, maths, geometry | 1,280 | 1,280 | 1,760 |  |
94,797 | 74.1 | 54.4 | 25 | 697 | {1: 1280} | {1: 963, 2: 216, 3: 64, 4: 22, 5: 8, 6: 4, 7: 3} | 0.06 |
| NLVR2 | Reasoning, logic, maths, geometry | 50,426 | 100,852 | 86,373 |  |
6,170,985 | 122.4 | 42.4 | 33 | 870 | {2: 50426} | {1: 15799, 2: 33839, 3: 354, 4: 384, 5: 30, 6: 9, 7: 3, 8: 4, 9: 1, 10: 2, 12: 1} | 2.23 |
| RAVEN | Reasoning, logic, maths, geometry | 42,000 | 63,081 | 42,000 |  |
1,129,930 | 26.9 | 7.39 | 17 | 37 | {1: 20919, 2: 21081} | {1: 42000} | 1.86 |
| ScienceQA | Reasoning, logic, maths, geometry | 4,976 | 4,976 | 6,149 |  |
1,519,770 | 305.4 | 788.3 | 34 | 22,381 | {1: 4976} | {1: 4429, 2: 352, 3: 106, 4: 35, 5: 9, 6: 8, 7: 10, 8: 1, 9: 4, 10: 4, 11: 4, 12: 1, 13: 1, 14: 3, 16: 2, 17: 1, 20: 1, 22: 1, 23: 1, 25: 1, 30: 1, 31: 1} | 0.22 |
| Spot the diff | Reasoning, logic, maths, geometry | 8,566 | 17,132 | 9,524 |  |
370,580 | 43.3 | 25.0 | 1 | 323 | {2: 8566} | {1: 8021, 2: 132, 3: 413} | 0.38 |
| TallyQA | Reasoning, logic, maths, geometry | 98,680 | 98,680 | 183,986 |  |
3,962,925 | 40.2 | 26.3 | 11 | 830 | {1: 98680} | {1: 49606, 2: 27559, 3: 13002, 4: 5159, 5: 1983, 6: 708, 7: 331, 8: 160, 9: 61, 10: 49, 11: 24, 12: 10, 13: 11, 14: 6, 15: 1, 16: 6, 17: 1, 19: 1, 23: 1, 40: 1} | 4.37 |
| VQA-RAD | Reasoning, logic, maths, geometry | 313 | 313 | 1,793 |  |
43,938 | 140.4 | 55.6 | 18 | 342 | {1: 313} | {1: 3, 2: 19, 3: 33, 4: 29, 5: 66, 6: 36, 7: 74, 8: 22, 9: 16, 10: 13, 11: 1, 12: 1} | 0.01 |
The Cauldron JA には、
- multi-turn 質問・応答ペアが含まれるデータセット数: 37
- 複数画像が含まれるデータセット数: 4
含まれているので、multi-turn 推論や、複数画像を用いた推論用の学習データとして使用することもできます。
また、# tokens (Min) (1 データあたりの質問・応答に含まれる最小 token 数) が 1 のものがあり、これは、質問・応答が 0 token である可能性があり、うまく翻訳できていないデータがあることが示唆されました。
実際に、# tokens (Min) が 1 token となっているものを覗いてみると、翻訳結果が空文字列になってしまっていることが確認できました。
{
'id': 'cocoqa_0004336',
'images': ['images/cocoqa/0004336.png'],
'conversations': [
{
'user': 'What is displayed on the plate with a fork\nGive a very brief answer.',
'jp_user': '',
'assistant': 'Entree.',
'jp_assistant': '',
'source': 'COCO-QA',
}
]
}
The Cauldron JA データセットを VLM の fine-tuning 用のデータとして使用する際には、翻訳結果が空文字列になっているデータを除外するなどの前処理を施して、このような不適切なデータをフィルタリングする必要がありそうです。
さらに、The Cauldron JA に含まれるデータセットのカテゴリごとの割合を調べてみると、以下のような結果になりました。
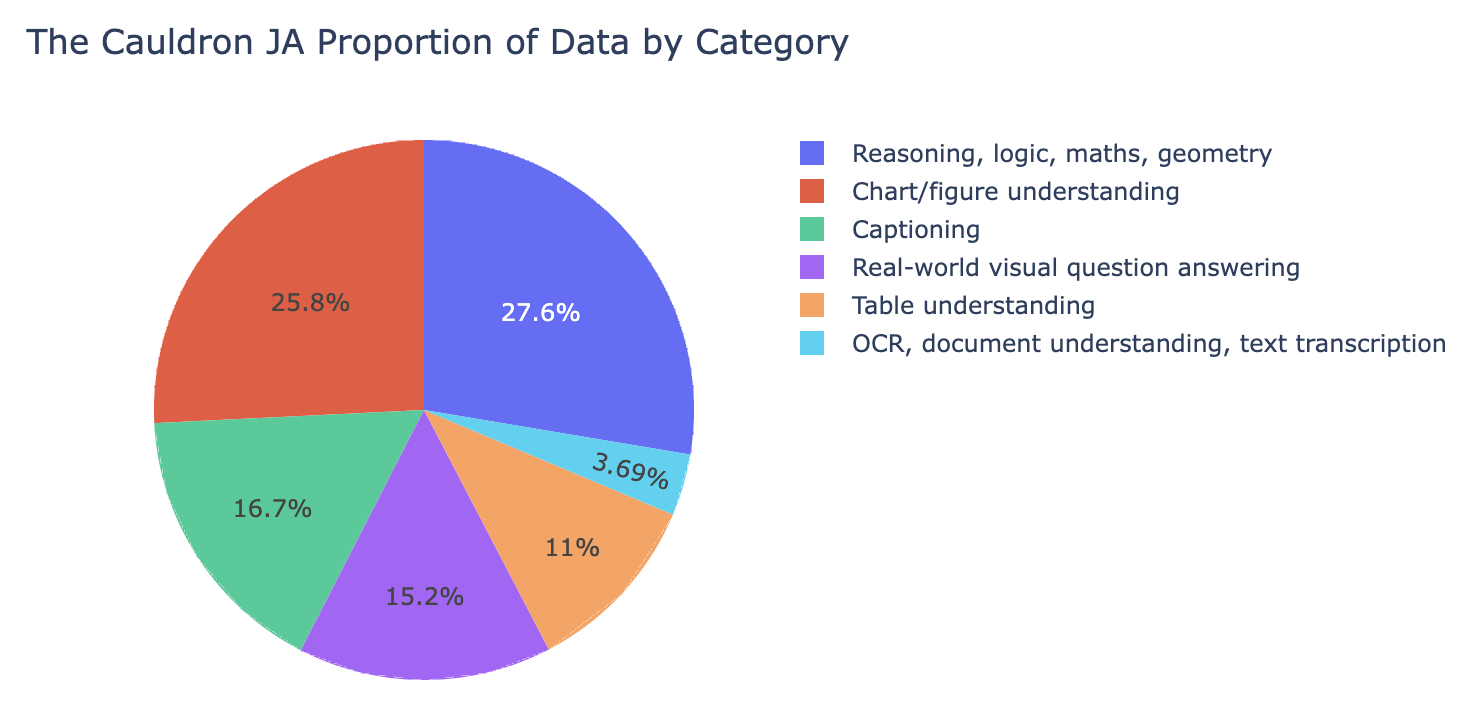
Reasoning, logic, maths, geometry, Chart/figure understanding のデータが多く含まれていることがわかりました。
また、The Cauldron JA に含まれる全データセットに関して、1 データあたりの質問・応答ペアに含まれる token 数のヒストグラムを描画すると以下のようになりました。
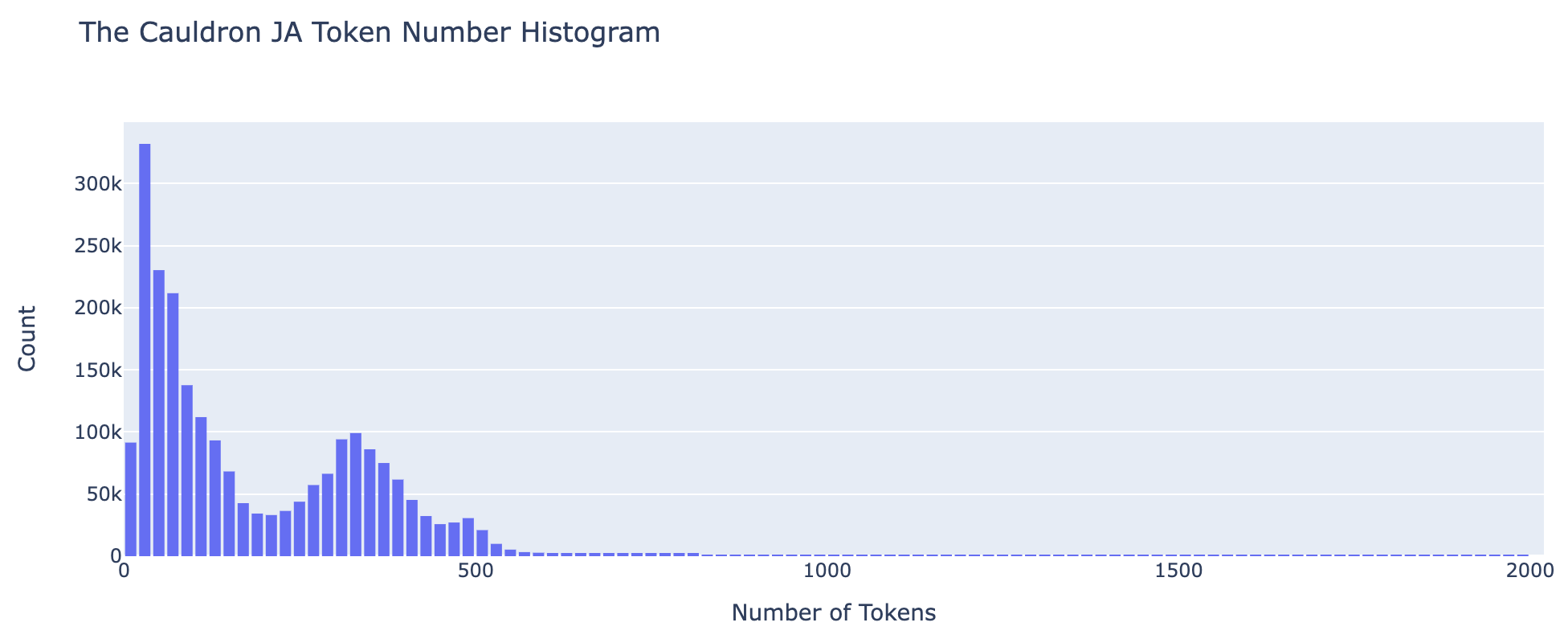
0 - 2000 token の範囲だけで、The Cauldron JA の全データセットの 99.88% をカバーできていることが分かりました。
これより、 The Cauldron JA データセットを使用して VLM の fine-tuning を実施する場合には、Llama 3 の tokenizer (vocab_size: 128,256) を使用する際、学習時の系列長 (SEQ_LENGTH) を 4096 程度まで大きくしなくても、truncate されずに 1 データ分のデータを学習できるかと思います。
The Cauldron JA のデータセットの例
The Cauldron JA に含まれる、全データセットの例を見せたいところですが、データセット数が 44 もあるので、今回は、各カテゴリごとにデータ例を 1 つだけ引っ張ってきて例示したいと思います。
Captioning

{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'How would you summarize this image in a sentence or two?',
'jp_user': 'このイメージを一言で表すと?',
'assistant': 'In this image, we can see some green color fruits and there is a blur background.',
'jp_assistant': 'この画像では、いくつかの緑色の果物が見え、背景がぼやけています。',
'source': 'localized_narratives',
}
]
}
Captioning タスクでは、画像に関する説明文を生成することが要求されます。
この例では、'user': 'How would you summarize this image in a sentence or two?' に対して 'jp_user': 'このイメージを一言で表すと?' と翻訳されており、正しく翻訳できていない事がわかります(正しく翻訳すると、「この画像を1文もしくは2文で要約すると?」のようになるでしょう)。
Real-world visual question answering

{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'What is sitting the the seat of the specialty bike\nWrite a very short answer.',
'jp_user': '専門バイクの座席に座っているもの非常に短い答えを書きます。',
'assistant': 'Cat.',
'jp_assistant': '猫。',
'source': 'COCO-QA'
}
]
}
Real-world visual question answering タスクでは、実在画像(実世界で撮影された画像)に関する質問文に解答することが要求されます。
この例でも、'user': 'What is sitting the the seat of the specialty bike\nWrite a very short answer.' を 'jp_user': '専門バイクの座席に座っているもの非常に短い答えを書きます。' と翻訳されており、正しく翻訳できていない事がわかります(正しく翻訳すると、「特殊な自転車のシートには何が座っているでしょうか。非常に短い解答を書きなさい。」のようになるでしょう)。
OCR, document understanding, text transcription
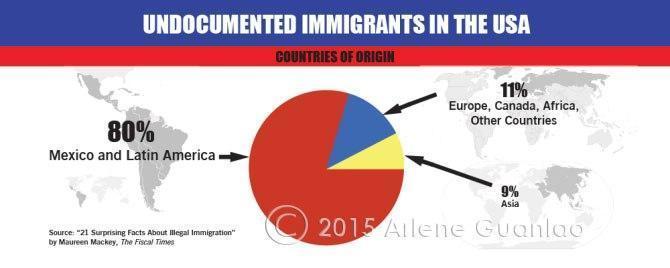
{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'Majority of undocumented immigrants in the USA belongs to which countries?\nGive a very brief answer.',
'jp_user': 'アメリカの非正規移民の大半はどの国に属していますか?簡潔に答えてください。',
'assistant': 'Mexico and Latin America.',
'jp_assistant': 'メキシコとラテンアメリカ。',
'source': 'Infographic-VQA',
},
...
]
}
OCR, document understanding, text transcription タスクでは、実世界の文書を視覚的に認識し、理解する能力が要求されます。
この例に解答するためには、画像がアメリカにおける非正規移民に関するものであり、円グラフを正しく理解する必要があります。
Chart/figure understanding
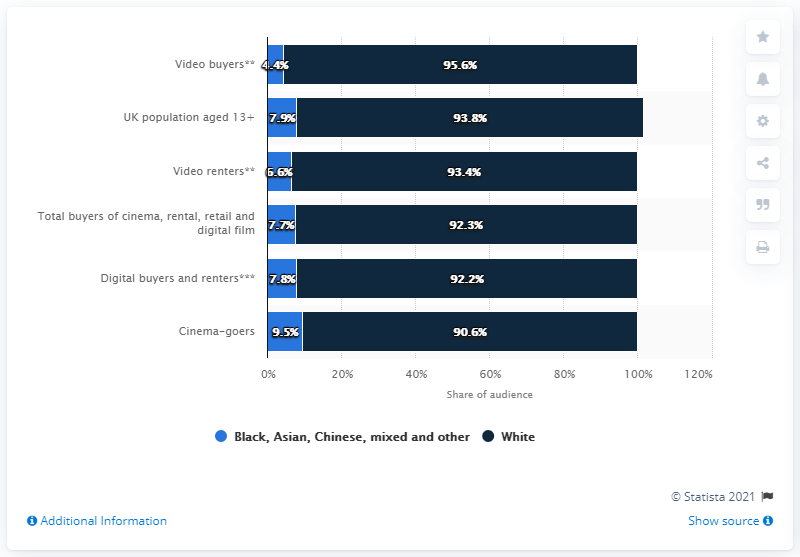
{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'What percentage of video buyers in the UK were black and minority ethnic groups in 2015?\nAnswer briefly.',
'jp_user': '2015年、英国におけるビデオ購入者のうち、黒人や少数民族の割合は?簡潔に答えてください。',
'assistant': '4.4.',
'jp_assistant': '4.4。',
'source': 'ChartQA',
}
]
}
Chart/figure understanding タスクでは、与えられた図を理解する能力が要求されます。
この例に解答するためには、ビデオ購入者に関するデータが可視化されている部分に注目し、さらに黒人や少数民族の凡例の色を特定し、割合に関する数値を抽出することが求められます。
Table understanding
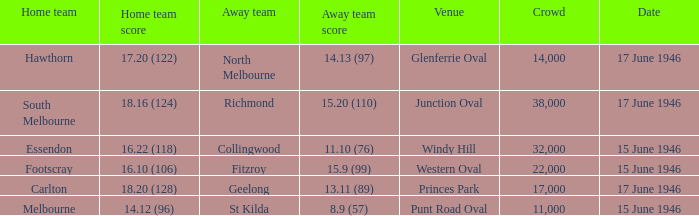
{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'On what date was a game played at Windy Hill?',
'jp_user': 'ウィンディ・ヒルで試合が行われたのは何月何日ですか?',
'assistant': '15 June 1946.',
'jp_assistant': '1946年6月15日。',
'source': 'robut_wikisql',
}
]
}
Table understanding タスクでは、与えられた表を理解する能力が要求されます。
この例に解答するためには、開催場所の列から「ウィンディ・ヒル」を特定し、「ウィンディ・ヒル」のある行から開催日を抽出することが求められます。
Reasoning, logic, maths, geometry

{
'images': [{ "bytes": [ 137, … ,96, 130 ], "path": null }],
'texts': [
{
'user': 'The first image is the image on the left, the second image is the image on the right. For the images shown, is this caption "There is a boy wearing pajamas in the center of each image." true? Answer yes or no.',
'jp_user': '最初の画像は左の画像で、2番目の画像は右の画像です。各画像の中央にパジャマを着た男の子がいます。本当ですか?イエスかノーで答えてください。',
'assistant': 'No.',
'jp_assistant': 'いいえ',
'source': 'NLVR2',
},
...
]
}
Reasoning, logic, maths, geometry タスクでは、推論・論理・数学・幾何学に関する能力が要求されます。
この例に解答するためには、2枚の画像それぞれの状況を把握、比較して質問に解答することが求められます。
さらに、この例では、「イエスかノーで答えてください。」という質問文に対し、(「ノー」ではなく、)「いいえ」と翻訳されてしまっています。このようなデータが学習データに混ざると、モデルの指示追従能力(モデルが指示文に正しく従う能力)を低下させてしまう可能性があります。
このように、The Cauldron JA は、DeepL API を用いて日本語に翻訳されているので、意図しない翻訳結果になっているデータが複数確認できています。
そのため、(上述したように、)本データを VLM の fine-tuning 等に使用する場合は、「イエス→はい / ノー→いいえ」に統一するなど追加の前処理を実施することをおすすめします。
また、上のデータ例を見ても分かる通り、The Cauldron (JA) は、質問文 ('jp_user') に対する応答文 ('jp_assistant') が非常に短くなっています。そのため、このデータをそのまま使用して VLM を fine-tuning すると、生成される出力文が非常に短くなってしまう傾向が確認できています。(このことは、idefics2 (The Cauldron) 提案元論文の What matters when building vision-language models? (Laurençon et al., 2024) でも言及されています。)
The Cauldron JA データセットのまとめ
- The Cauldron JA データセットは、The Cauldron データセットを DeepL API を用いて日本語に翻訳したデータセット
- 44 のタスク指向の V&L データセットが同一のデータ形式でまとめられている
- 意図しない翻訳結果になってしまっているデータが混在する
- 質問文 (
'jp_user') に対する応答文 ('jp_assistant') が短くなっているデータが多い
Wikipedia Vision JA データセット
Wikipedia Vision JA データセットに関して
Wikipedia Vision JA は、日本語版 Wikipedia を元に作成された V&L データセットであり、画像、画像キャプション、画像近傍のテキストの 160 万セットからなります。
Wikipedia Vision JA データセットの取得方法
Wikipedia Vision JA データセットの元となる記事は wikidump の 2024 年 1 月 1 日版の index (jawiki-20240101-pages-articles-multistream-index.txt.bz2) から取得しています。
実際には、
-
jawiki-20240101-pages-articles-multistream-index.txt.bz2から記事リストを取得 - 記事リストから HTML を解析し、画像の URL、画像キャプション、画像近傍のテキストを取得
のような流れで Wikipedia Vision JA データセットを作成しています。
また、「画像近傍のテキスト」の取得方法に関してより詳しく説明します。
Wikipedia の記事の画像は <figure typeof="mw:File/Thumb"> というタグで表現されているのですが、その直後にある本文のテキスト(<p> タグの内部のテキスト)を取得することで画像近傍のテキストを取得しています。本データセットの場合、画像に続く最大 3 つの <p> タグを取得しています。(そのため、データによっては画像近傍のテキスト (description) の長さにバラツキがあります。)
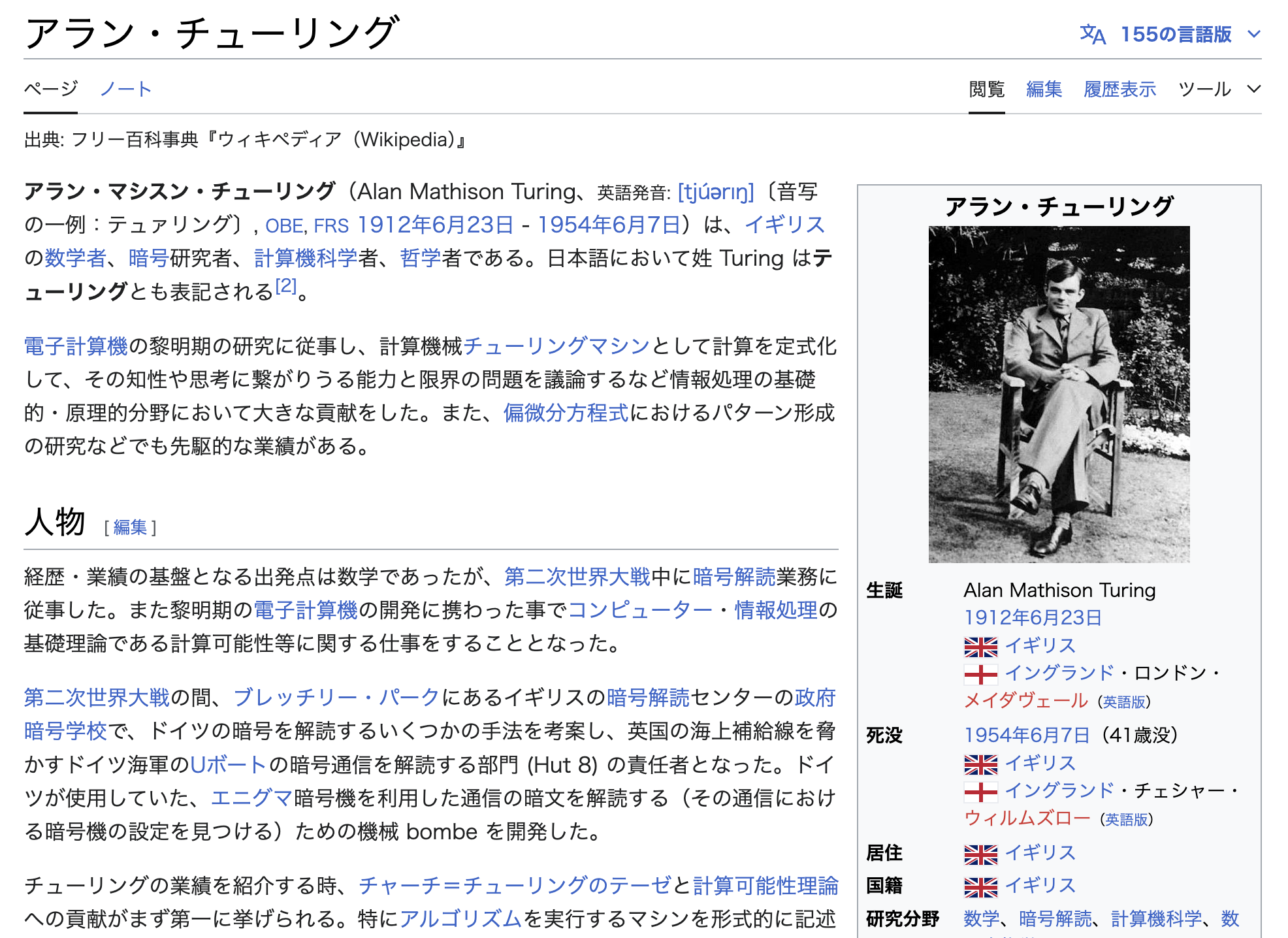
例えば、上のような Wikipedia の記事から、それぞれ「画像キャプション (caption)」と「画像近傍のテキスト (description)」を抽出する場合、
-
画像キャプション (
caption): アラン・チューリング -
画像近傍のテキスト (
description): アラン・マシスン・チューリング(Alan Mathison Turing、英語発音: [tjúǝrɪŋ]〔音写の一例:テュァリング〕, OBE, FRS 1912 年 6 月 23 日 - 1954 年 6 月 7 日)は、イギリスの数学者、暗号研究者、計算機科学者、哲学者である。日本語において姓 Turing はテューリングとも表記される。 電子計算機の黎明期の研究に従事し、計算機械チューリングマシンとして計算を定式化して、その知性や思考に繋がりうる能力と限界の問題を議論するなど情報処理の基礎的・原理的分野において大きな貢献をした。また、偏微分方程式におけるパターン形成の研究などでも先駆的な業績がある。 経歴・業績の基盤となる出発点は数学であったが、第二次世界大戦中に暗号解読業務に従事した。また黎明期の電子計算機の開発に携わった事でコンピューター・情報処理の基礎理論である計算可能性等に関する仕事をすることとなった。
が抽出されます。
Wikipedia Vision JA データセットの基本統計量
この Wikipedia Vision JA データセットの基本統計量を調査しました。
また、Token に関する情報は、the Cauldron JA の時と同様、Llama 3 の tokenizer (vocab_size: 128,256) を使用して、画像キャプション ("caption"), 画像近傍のテキスト ("description") 部分の日本語テキストを tokenize することで算出しています。
- データ数: 1,602,962
- 画像数: 1,602,962
画像キャプション (caption)
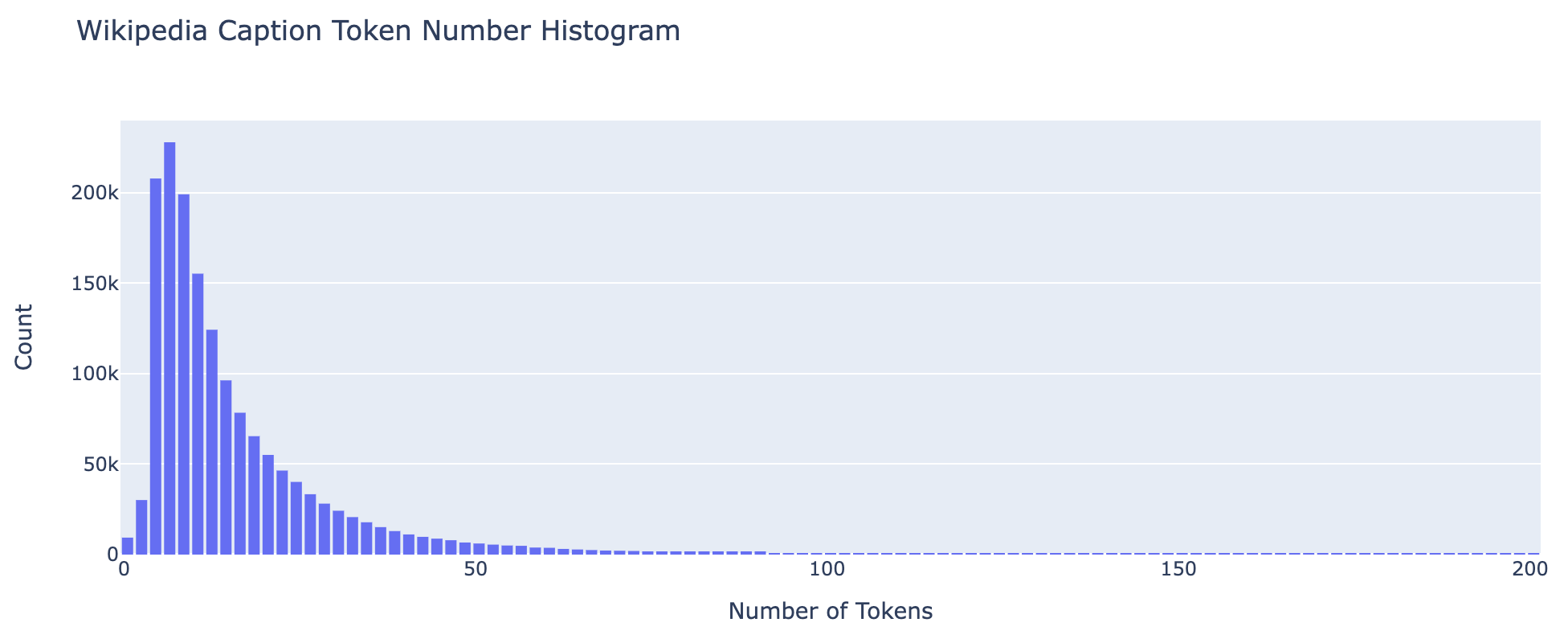
- 1 データあたりのキャプションに含まれる平均 token 数: 16.6
- 1 データあたりのキャプションに含まれる token 数の標準偏差: 18.3
- 1 データあたりのキャプションに含まれる最小 token 数: 1
- 1 データあたりのキャプションに含まれる最大 token 数: 1,046
0 - 50 token の範囲だけで、Wikipedia Vision JA の全データセットの 95.79% をカバーできていることを確認しました。
画像近傍のテキスト (description)
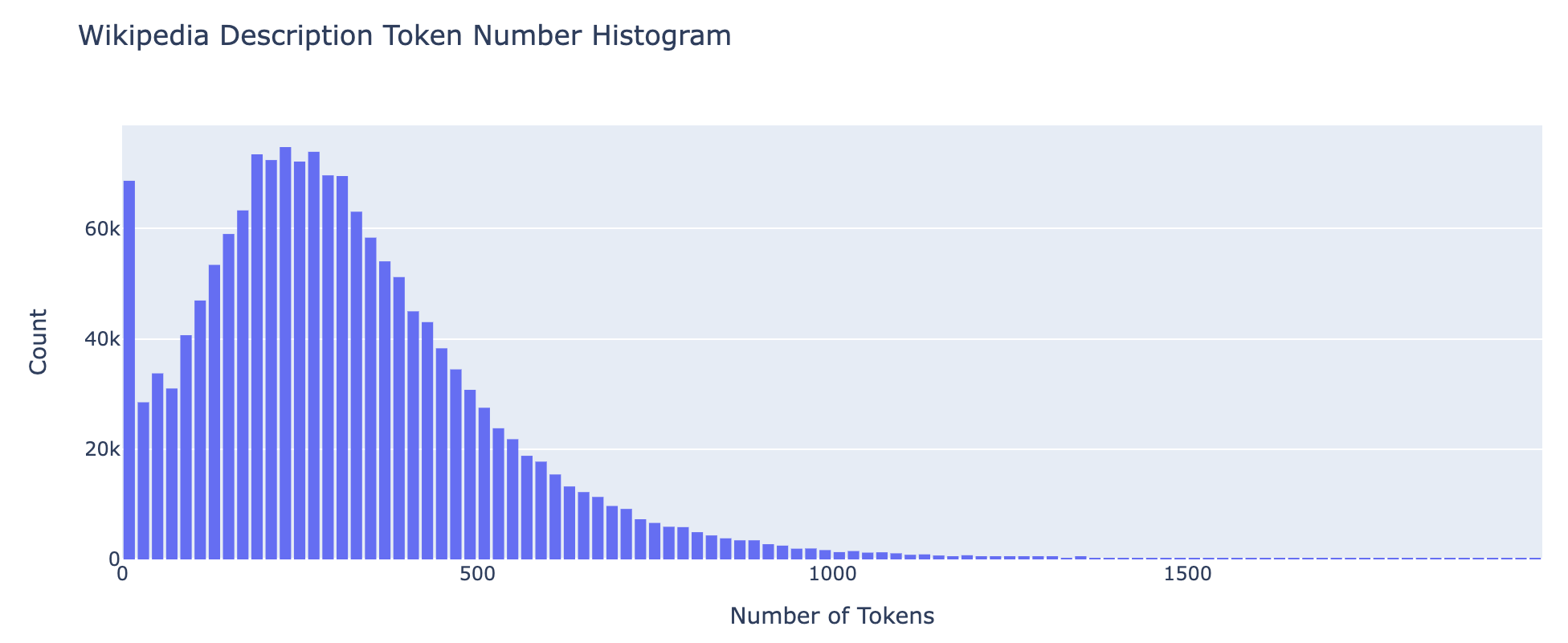
- 1 データあたりのキャプションに含まれる平均 token 数: 315.3
- 1 データあたりのキャプションに含まれる token 数の標準偏差: 213.6
- 1 データあたりのキャプションに含まれる最小 token 数: 1
- 1 データあたりのキャプションに含まれる最大 token 数: 5,568
0 - 2000 token の範囲だけで、Wikipedia Vision JA の全データセットの 99.98% をカバーできていることを確認しました。
また上述したように、上図から、画像近傍のテキストの長さ (token 数) にバラツキがあることが分かります。
Wikipedia Vision JA のデータセットの例
Wikipedia Vision JA には、全データ情報が Wikipedia_Vision_JA.jsonl という JSONL 形式のデータとしてまとめられています。
Wikipedia_Vision_JA.jsonl に含まれる JSON 形式のデータは、以下の key を持ちます。
-
key: 一意な ID -
caption: 画像キャプション -
description: 画像近傍のテキスト -
article_url: 抽出元の記事の URL -
image_url: 抽出元の画像の URL -
image_hash:image_urlのハッシュ値
今回は、Wikipedia_Vision_JA.jsonl に含まれる JSON 形式のデータ例を 1 つだけ例示します。

{
"key": "000057870",
"caption": "アラン・チューリング",
"description": "アラン・マシスン・チューリング(Alan Mathison Turing、英語発音: [tjúǝrɪŋ]〔音写の一例:テュァリング〕, OBE, FRS 1912年6月23日 - 1954年6月7日)は、イギリスの数学者、暗号研究者、計算機科学者、哲学者である。日本語において姓 Turing はテューリングとも表記される。 電子計算機の黎明期の研究に従事し、計算機械チューリングマシンとして計算を定式化して、その知性や思考に繋がりうる能力と限界の問題を議論するなど情報処理の基礎的・原理的分野において大きな貢献をした。また、偏微分方程式におけるパターン形成の研究などでも先駆的な業績がある。 経歴・業績の基盤となる出発点は数学であったが、第二次世界大戦中に暗号解読業務に従事した。また黎明期の電子計算機の開発に携わった事でコンピューター・情報処理の基礎理論である計算可能性等に関する仕事をすることとなった。",
"article_url": "https://ja.wikipedia.org/wiki/アラン・チューリング",
"image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/7/79/Alan_Turing_az_1930-as_%C3%A9vekben.jpg/400px-Alan_Turing_az_1930-as_%C3%A9vekben.jpg",
"image_hash": "52fcf6db07"
}
Wikipedia Vision JA データセットのまとめ
- Wikipedia Vision JA データセットは、wikidump の 2024 年 1 月 1 日版の index を元に作成された V&L データセットである
- Wikipedia Vision JA データセットには、画像 URL、短い画像キャプション、画像近傍のテキストが約 160 万件含まれる
- 画像近傍のテキスト長には、バラツキがある
おわりに
本記事では、Turing からリリースされた GENIAC の成果物 の中の1つである The Cauldron JA と Wikipedia Vision JA データセットを紹介しました!
Turing は「We Overtake Tesla」をミッションに完全自動運転の実現に向けて尽力しています。経済産業省/NEDO の競争力のある生成 AI 基盤モデルの開発を支援する GENIAC プロジェクトにも採択され、生成 AI・大規模基盤モデルの開発を進めています。完全自動運転に向けたマルチモーダルな基盤モデルの開発にご興味ある方、お気軽にコメントや X (Twitter) の DM にてお問い合わせください。

Discussion