1. はじめに
Turing 生成AIチームの荒居です。生成AIチームでは、完全自動運転の実現に向けて、現実世界の複雑な状況を理解し未来を予測するAI、「世界モデル」の開発に取り組んでいます。世界モデルは、生成AIによって様々な交通状況や歩行者の行動をシミュレーションすることを可能にし、安全かつ効率的な自動運転を実現するための重要な鍵となると私たちは考えています。
この記事で解説している内容:
- 世界モデルとは何か
- 世界モデルの開発はなぜ自動運転に重要なのか
- 世界モデルGAIA-1について
2. 世界モデルとは
世界モデルとは、現実世界の物理法則や因果関係、物体間の相互作用などの「世界の仕組み」を表現するモデルのことです。人間は、生まれながらにして備わっている身体感覚や運動能力を通じて身の回りの世界に関するメンタルモデルを構築し、それを基に予測や計画、行動をおこなっています。例えば、ボールを投げるときには、重力や空気抵抗などを考慮して、ボールの軌道を予測し、適切な力加減で投げることができます。
近年は、人間が自然と獲得するこのメンタルモデルを、学習を通じてAIに獲得させる試みが強化学習やロボティクス、自動運転などの分野で取り組まれるようになってきています。
例えば自動運転分野における世界モデルの研究では、今回紹介する、英国のスタートアップWayveの開発したGAIA-1や、OpenDriveLabが開発したGenADなどがあります。
また、自動運転以外の領域ではOpenAIが2024年の2月に公開したSoraも世界モデルとみなすことができます。Soraは、さまざまな物体が相互作用するような長尺の動画を破綻なく生成できるという点でかなり注目を集めており、物理世界における汎用シミュレータとしての用途が期待されています。
3. 世界モデルは自動運転にどう役立つか?
世界モデルを自動運転に活かす方法は大きく分けて「自動運転システムの一要素としての利用」と「シミュレータとしての利用」の2パターンが存在します。自動運転システムの一要素としての利用は、世界モデルの内部で現在の世界の状態を表現した状態表現や、未来の予測結果の状態表現を自動運転エージェントの運転判断に用いるという利用方法です。一方、シミュレータとしての利用は、世界モデルを用いて未知の運転状況を生成し、それを用いて自動運転エージェントを学習や評価を行うという利用方法です。以下にそれぞれのパターンについてより詳細に説明します。
3.1 自動運転システムの一要素として世界モデルを利用する
世界モデルが大量の学習を通じて獲得した、現在の状況に関する表現や、未来の状況に関する表現はそれ自体が運転に有用な可能性があります。例えば、周囲の歩行者や車両の動きの予測が自動運転において有用であることはすでに多くの研究で指摘されています。
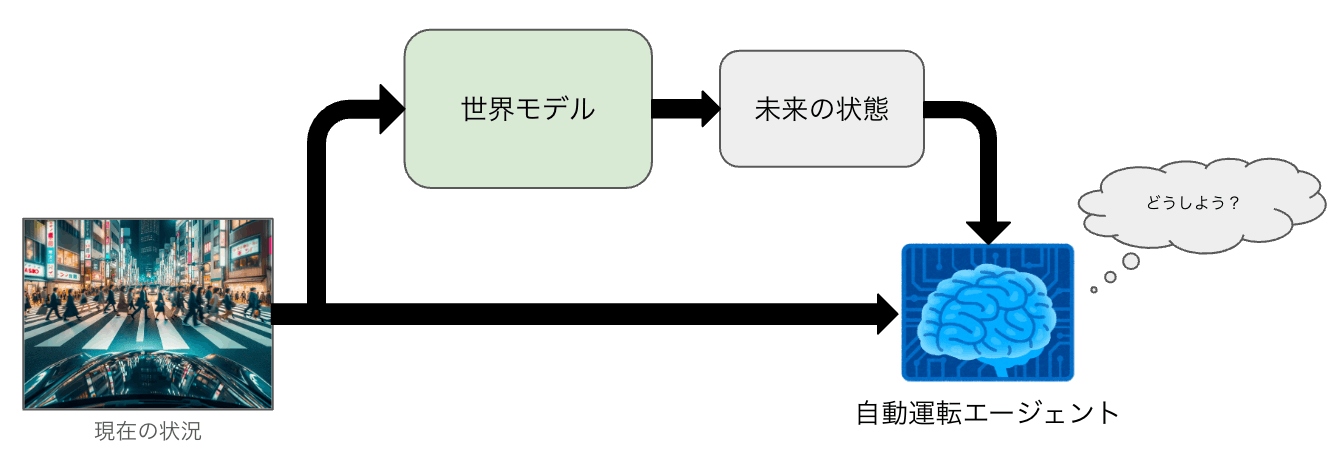
世界モデルの出力を自動運転システムの入力にするイメージ
また、例えばアクションで条件付けた生成が可能なモデルが作成できた場合には、現在の状況を踏まえて取りうるいくつかの選択肢それぞれをとった場合に未来がどのように変化するかを世界モデルを用いて予測し、その結果をもとに現在取るべきアクションを決定する、といった「シミュレータ同梱」の自動運転システムを考えることもできます。
このような「シミュレータ同梱」なシステムは、私たちが意思決定をする際にも働いているシステムだと考えられます。例えば、家を買う状況を考えてみましょう。多くの人は、家を買う際にはその家を購入したことによってどのような未来が待ち受けているのかを脳内でシミュレーションしその結果をもとに購入の判断をします。家の購入ほど大きな意思決定ではなくても、例えば朝着る服を選ぶときや、レストランで料理のリストから食べる料理を選ぶとき、運転の最中に前の車を追い抜くかどうかの判断をするときなどにこのような未来予測のシステムが私たちの中で働いていることは多くの人に同意していただけるでしょう。
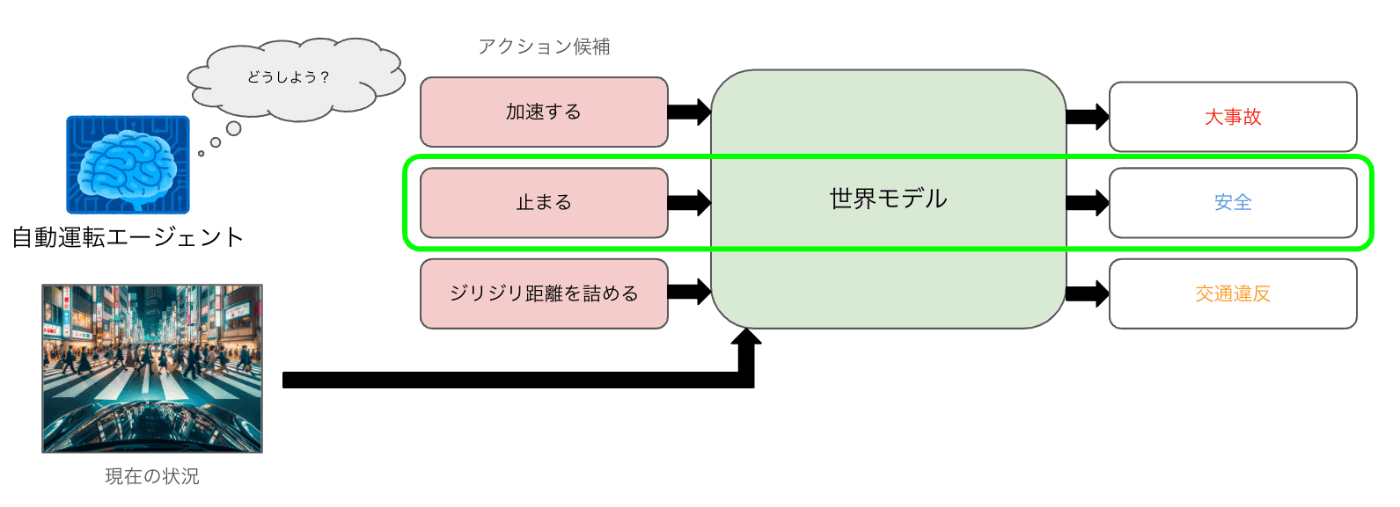
シミュレータ同梱の自動運転システムのイメージ
自動運転システムの一要素として世界モデルを利用する場合の一つの制約として、世界モデル自体が実機上でリアルタイムに動かせる程度の大きさ(パラメータ数・計算量)である必要があります。
3.2 シミュレータとして世界モデルを利用する
自動運転の開発において、シミュレータは開発の安全性・効率性の観点で非常に重要な要素としてよく用いられています[1]。シミュレータとしてはCARLAのような物理演算エンジンを用いたものが有名ですが、学習を通じて世界の仕組みの表現を獲得した世界モデルもシミュレータとして使えるのではないか、と近年注目を集めています。
先ほどの「シミュレータ同梱の自動運転システム」でも世界モデルをシミュレータとして用いていましたが、ここで紹介するのは自動運転システムとは切り離された、世界を模擬した環境としてのシミュレータです。
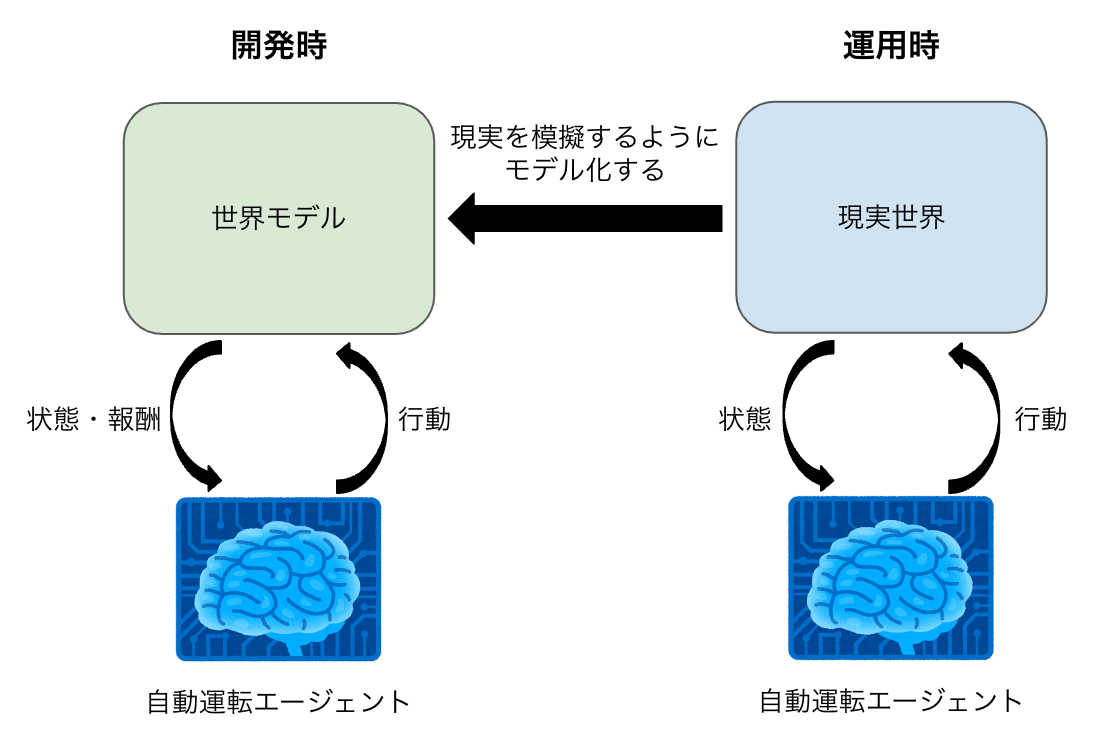
自動運転システムとは切り離された、世界を模擬した環境としてのシミュレータ
物理演算シミュレータに対して世界モデルの優れている点としては、物体間の相互作用をより正確に反映させられる可能性があげられます。例えば、人が多く行き交う交通環境において低速で走行する場合、周囲の人は自車の運動に応じて行動を変化させながら移動すると考えられます。

CARLAではマップや天候、時間帯などを自由に選択できるほか、車両や歩行者、その他のオブジェクトをマップに配置することができる
仮に自車がジリジリと距離を詰めるような動きをしているのであれば、まだ横断歩道を渡り始めていない人は横断歩道に侵入せず車に道を譲るような動きをするかもしれません。一方で、車が完全に停止しているのであれば、まだ横断歩道を渡り始めていない人も特に車に注意を払うことなく横断歩道を渡り始めるかもしれません。

人が多く行き交う交通環境において低速で走行するイメージ generated by DALL-E
このような物体間の高度なインタラクションを反映したシミュレーションを物理演算シミュレータ上に構築するのは困難な一方、大量のデータをもとに学習された世界モデルはこのようなインタラクションを自然に表現できる可能性があります。
この他にも、エッジケースの生成という観点でも世界モデルが優れている可能性があります。一般的に自動運転システムの開発では、稀だが対処困難な状況において機能させることが大きな問題となりやすく、いかにエッジケースのデータを収集できるかが成功の鍵となってきます。
例えば以下のツイートのような、高速道路でたくさんの豚さんがいるような状況は自動運転システム開発の障害となるようなエッジケースの代表例ですが、このような状況において自動運転システムがどう振る舞うのかのテストのためにもこのようなエッジケースのデータは必要ですし、大量に安価に似たようなエッジケースのデータを生成することができるのであれば、学習にそのデータを用いることも可能であると考えられます。
物理演算シミュレータではこのようなエッジケースに一つ一つ対応していくのは困難であると考えられます。例えば、上記のように豚さんが高速道路に歩いている例を再現するためには豚というオブジェクトを定義し、それらの動きがどうあるべきか、という運動則を実装する必要があります。仮にそれができたとして、この「豚」を「牛」に変えるためにはまた新たに牛というオブジェクトを定義し運動則を実装する必要があり、この作業を運転シーンに出てきうるオブジェクト全てに対して行なっていくのは現実的ではありません。
一方で、大量のデータから学習を行う世界モデルは、豚や牛が歩いているデータを学習データに含めることによって、人間が明示的にそれらのオブジェクトの挙動を記述しなくてもそれらのオブジェクトを含んだ運転シーンを生成できる可能性があります。
シミュレータとしての利用を考えた場合、実際に自動運転車の中で運転判断を行う自動運転エージェントとシミュレータの世界モデルを切り離して使うことができるため、シミュレータの実行環境は計算環境の制限を受けません。自動運転のエージェントは例えばNVIDIAのJETSON上で動作しなければならないといった制約を受けますが、極端な話で言えばシミュレータとしての世界モデルはサーバ上のH100 96台で動作するモデルであっても問題はありません。
4. GAIA-1の概要
さて、ここまでは一般的に世界モデルとはどういうものか、世界モデルは自動運転にどう活かすことができるのか、を紹介しましたが、ここからはこのブログのタイトルにも入っているGAIA-1という世界モデルについての紹介になります。
GAIA-1は、英国のスタートアップWayveが開発した世界モデルで、動画やテキスト、アクションに関する情報をもとに未来のリアルな動画を生成することができます。
NVIDIA GTC2024のキーノート冒頭で紹介されるなど、海外では大きな注目を集めている生成AIモデルです。
4.1 GAIA-1は何ができるのか?
GAIA-1は以下のようにさまざまなタスクを解くことができます。
まず、GAIA-1は動画の途中までを与えて、その続きを生成することができます。特に動画の途中から、あり得そうな複数の未来について生成できる点は、シミュレータとして利用する際に非常に有用な性質の一つです。
また、動画の途中までと、「左に行く」のような行動指示を与えて、行動指示に従った先の動画フレームを生成させることができます。単に途中まで与えた動画の先の未来が予測できるだけではシミュレータに用いることはできないですが、自車の操作に応じて変化する未来の生成ができる機能があることで、GAIA-1はシミュレータとしても用いることができるようになっています。
また、GAIA-1はテキストによる状況説明を与えることで状況に沿った動画生成を行うこともできます。例えば「雨が降っている」「晴れている」と言った天気の説明を入れることでそれらの状況下での運転動画を生成できます。この機能があることで、上の例でも説明したようにエッジケースの動画を生成させる、といったようなこともできるようになってくる可能性があります。
テキスト指示と行動指示を同時に与えてそれらに従った動画を生成することも可能で、逆にテキスト指示も行動指示も、参照する動画フレームも全く与えない状態から運転動画も生成できるようになっています。従って、学習・評価データに全く存在しないような走行映像も無から生成できるということです。
5. GAIA-1のモデル構成
GAIA-1は入力として動画(画像列)と各画像に付随した状況説明、各画像に付随したアクション(スピード、ステアリング操作)を受け取ることができるマルチモーダルモデルになっています。
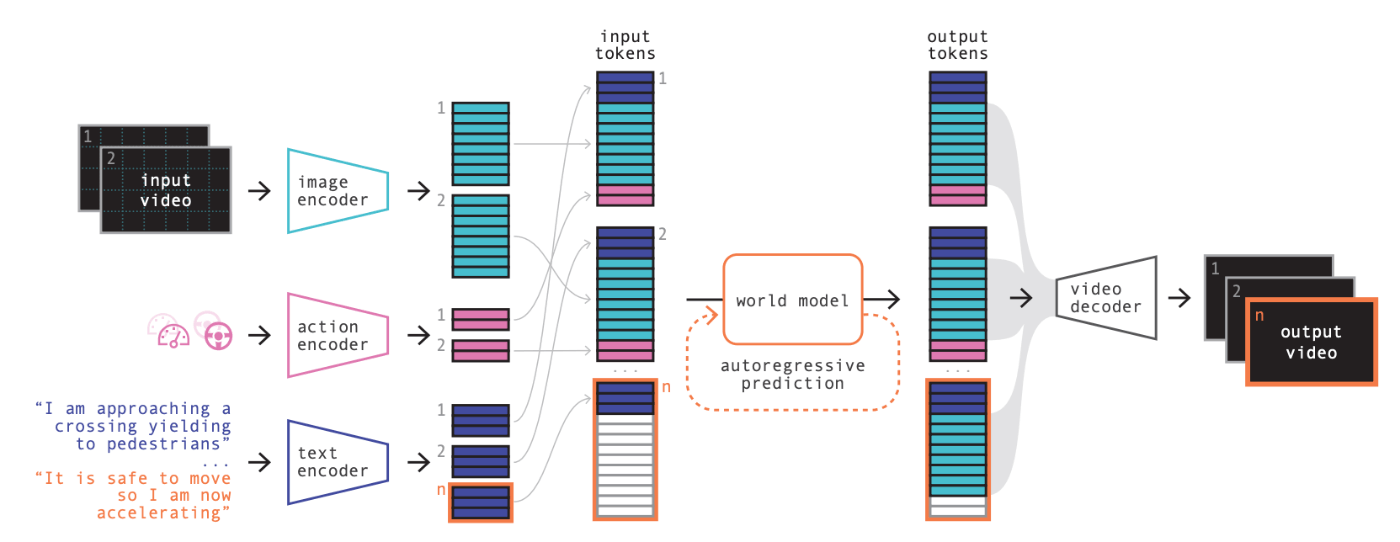
GAIA-1は複数のコンポーネントに分かれた構造になっており、大きく分けると画像を離散トークンに変換する「Image Tokenizer」と、画像・テキスト・アクションのトークン列から未来の画像トークンを自己回帰的に予測する「World Model」、予測された画像トークン列から動画を生成する「Video Decoder」の3つから成ります。
このうち、未来を予測するという機能の中核を担うのが「World Model」です。「World Model」は近年大きな発展を遂げたLLMの技術が用いられており、過去の状態を表現したトークン列をもとに次のトークンを予測するという仕組みを用いることで、将来の状態を表現したトークン列を文章生成と同じ仕組みを用いて生成します。
GAIA-1の世界モデルはLLMと同じように過去の離散トークン列を受け取り未来の離散トークン列を予測する枠組みのため、動画やテキスト、アクションといった入力データを離散トークンに変換する必要があります。特に動画(画像列)は一般的に離散トークンの集合として扱うことは少ないため、特殊な変換が必要になります。この変換を行うのが「Image Tokenizer」です。
また、GAIA-1の世界モデルが予測するのは未来の画像列を表現したトークン列になります。これを画像列の形式に戻す部分も変換が必要になります。この変換を行うのが「Video Decoder」です。
5.1 Image Tokenizer
Image Tokenizerはその名の通り、画像を離散のトークン列に変換するモデルです。GAIA-1では
モデルの構造はVQ-VAEを用いており[2]、学習後はVQ-VAEのデコーダを捨てて、エンコーダのみをImage Tokenizerとして用いています。VQ-VAEはオートエンコーダのボトルネック部で最近傍法を用いて特徴マップの各ピクセルの特徴ベクトルを一度離散トークンに変換するようなモデルのため、画像を離散トークンの集合に変換する、というGAIA-1の目的に適ったモデルです。
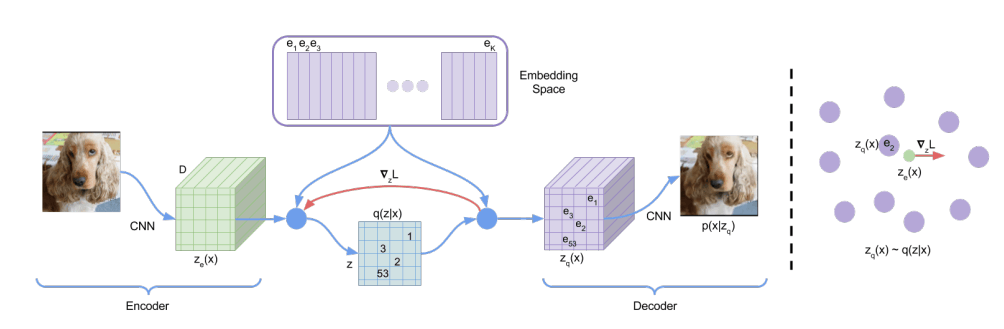
VQ-VAEのモデル構造の模式図。エンコーダで特徴マップを作成した後特徴マップ内の各ピクセル毎に最近傍法を用いて学習可能なEmbeddingテーブルへのルックアップを行い、離散トークンを得る
GAIA-1のVQ-VAEは複数の損失関数の重みつき和を用いて学習が行われています。VQ-VAEの学習に用いられる再構成誤差と量子化誤差以外に、学習済みのDINOのEmbeddingと画像特徴のEmbeddingを近づけるような「帰納バイアス損失」が用いられている点は少し変わった点です。
5.2 World Model
GAIA-1の世界モデルは、基本的にはLLMと同じものになっていて多層のTransformer Decoderからなっています。入力は動画のフレーム毎に状況説明のテキスト32トークン分と、フレームの画像トークン576個分とアクションのトークン2個分の合計610トークンを一列に並べたようなデータになります。
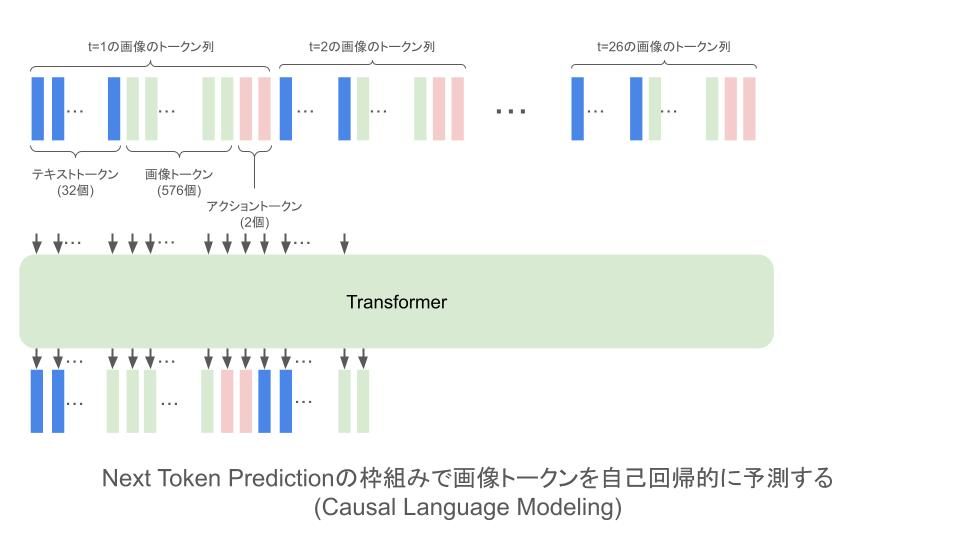
画像のトークンはImage Tokenizerで
学習は入力を1トークン分ずらしたものを予測するようにする、Next Token Predictionの枠組みで行います。なお、上記の画像ではテキストトークンやアクショントークンについても予測ができるように学習が行われているように描いていますが、実際にはこの部分については損失関数を計算せず、画像トークンに対する予測のみについて損失計算を行うようにしています。
未来予測を行う場合、1フレーム分の予測は次のトークンを予測し、その予測結果をコンテキストに入れてさらに次のトークンを予測するという自己回帰的なアプローチを576回繰り返します。
5.3 Video Decoder
World Modelで予測された未来のフレームを高品質な画像列として復元し可視化をするのがVideo Decoderの役割です。簡易的な可視化であれば、Image Tokenizerの学習で得られたVQ-VAEのデコーダをそのまま未来のフレームの画像トークン列から画像列を生成する変換器として用いることができるのですが、フレーム間の一貫性が保たれない可能性がある点や動画の超解像ができない点からGAIA-1では、Denoising Video Diffusion ModelがVideo Decoderとして用いられています。
Video Decoderのモデル構造は空間方向と時間方向を分けたアテンション構造を入れた3D U-Net構造になっています。学習においては画像生成、動画生成、動画の自己回帰生成、動画補完の4つのタスクを同じ確率で選択しながら複数のタスクで一つのモデルを学習する、ということを行っています。

Video Decoderは4つのタスクで学習が行われている
画像生成のタスクの場合は、画像のトークン列とノイズをもとにノイズ除去をしていくことで画像生成を行うように学習が行われています。この際時間方向のアテンション層を無効にしているようです。動画生成はトークン列とノイズをもとにノイズ除去をしていくことで一貫性のある画像列を生成するように学習が行われています。この際は時間方向のアテンション層が有効化され、それぞれの画像フレームのノイズ除去に同じ動画中の他のフレームの情報を考慮するようになっています。自己回帰生成は、時間的に前のフレームとノイズ、画像トークン列をもとにノイズ除去を行うタスクになっており、動画補完は、時間的に挟まれたフレームの画像列を前後のフレームとノイズをもとに推論するようなタスクです。
U-Netのモデルはノイズ自体を予測する(正確にはStable Diffusion2系でも用いられているvターゲットを予測する)ように学習が行われています。
6. GAIA-1はどうすれば作れるのか?
GAIA-1は、大規模かつ高品質なデータセットで学習が行われていて、再現のためには大量のコンピューティングリソースを必要とします。また、実装やモデル構造の詳細も公開されていないため、どのような実装になっているかは推測する必要があります。
この節では、どのようなデータをどの程度集める必要があるのか、モデルの実装はどのようにするのが良さそうか、学習の手順としてどのようなステップを踏めば良いのか、という点について私たちが考察したものをお伝えしようと思います。
6.1 GAIA-1の学習データについて
GAIA-1はWayveが独自に英国内で収集した4,700時間分の走行動画を用いて学習が行われている、と公表されています。このデータセットは非公開のため、GAIA-1の再現を行うためには同等の量のデータセットを用意する必要があります。
モデル構成の節で紹介したように、GAIA-1は動画の各フレームに対して状況説明のテキストとスピード・ステアリング操作の情報が付与されたデータを用いて学習されているため、学習のためには同等のデータも必要になってきます。
同等程度の量のテキスト・アクション・走行動画のデータセットとして公開されているものではOpenDriveLabが公開したOpenDV YouTube Datasetがあります。このデータセットは、YouTubeから収集した世界40カ国以上の走行データ約1,750時間にBLIP2を使ってテキストの状況説明をつけ、別のデータセットで学習したアクション分類モデルでアクションの情報を付与したものです。Wayveの持つ4,700時間分のデータセットには量では及ばないものの、さまざまな国・さまざまなカメラ配置・さまざまな運転環境で撮影された走行映像になっているため、多様性という面ではWayveのデータセットを凌駕している可能性があります。

OpenDV YouTubeデータセットに含まれる運転シーン。さまざまな国・地域の運転シーンが含まれている
また、より小さいデータセットだと、例えばBDD-Xデータセットなどがあります。このデータセットは77時間分の動画に対しアクションに関する説明のテキストが付与されたものになっています。小規模に実験をする場合はこのデータセットなどを使って実験をするのが良さそうです。
データを独自に収集するという方法も忘れてはいけません。Turingでは数千時間以上の走行データと、それに紐付いたアクションの情報をすでに収集済みですが、Turingが開発しているHeronのようなVision & Languageのモデルを用いることでこれらの動画データにテキストによる状況説明を付与することが可能です[3]。
私たちは独自に収集した走行データと、独自に開発したVision & Languageモデルを用いてテキスト・動画・アクションが紐付いたデータを作成し、世界モデルの開発を進めていこうとしています。
6.2 モデルの実装について
GAIA-1のモデルは、あまり情報が公開されておらず、具体的な実装やアーキテクチャについては推測をするしかありません。
6.2.1 Image Tokenizerの実装についての考察
Image Tokenizerは0.3BパラメータのFully Convolutionalなモデルを使っていることが論文には記述されています。また、ベクトル量子化に用いるEmbedding層のvocabulary sizeは8,192であるとされています。入力が
また、論文中では中間層の特徴量を学習済みのDINOモデルの特徴量と近づけるようにしている、という記述があります。仮に公開されているgithub.com/facebookresearch/dinoのモデルを用いていて、それをベクトル量子化層に入力する直前の特徴マップと近づけるようにしている場合、パッチサイズを16に設定しているViT-B/16のモデルを使っている可能性があります。ViT-B/16のモデルの特徴量は768次元であり、DINOの特徴量とImage Tokenizerの中間層の特徴量はCosine Similarityを高めるようにしている、という記述があるため、ベクトル量子化層に入力する前の特徴マップは768次元になっているのではないかと考えられます。

論文中の記載を元に推測したImage Tokenizerの概要
6.2.2 World Modelの実装についての考察
World Modelは6.5BパラメータのTransformerモデルで、入力のトークン長が15,860であるという記述がGAIA-1の論文中にはありますが、具体的にどのようなアーキテクチャのモデルが用いられているかは明言されていません。とはいえ、近年世間の耳目を集めるLLM開発競争はアーキテクチャの革新性というよりも、データや学習レシピに高性能を達成する秘訣がある傾向が強いかと思います。したがって、再現実装を行う場合はhuggingface/transformersに実装されている有名なアーキテクチャを改変する形で使うのが良さそうです。
World Modelで特殊な点の一つとして独自のPositional Encodingを用いている点があります。World Modelの入力は1フレームで
import torch
import torch.nn as nn
class LearnableFactorizedSpatioTemporalPositionalEmbedding(nn.Module):
def __init__(self, num_spatio_embeddings: int, num_temporal_embeddings: int, embedding_dim: int):
super().__init__()
self.spatio_embeddings = nn.Embedding(num_spatio_embeddings, embedding_dim)
self.temporal_embeddings = nn.Embedding(num_temporal_embeddings, embedding_dim)
self.num_spatio_embeddings = num_spatio_embeddings
self.num_temporal_embeddings = num_temporal_embeddings
def forward(self, attention_mask: torch.LingTensor, _):
batch_size = attention_mask.size(0)
# [0, 1, 2, ..., num_spatio_embeddings-1, 0, 1, 2, ..., num_spatio_embeddings-1, ...]という形のテンソルを作成
spatio_indices = torch.arange(
self.num_spatio_embeddings,
device=attention_mask.device
).repeat_interleave(self.num_spatio_embeddings).unsqueeze(0).repeat((batch_size, 1))
# [0, 0, 0, ..., 1, 1, 1, ..., 2, 2, 2, ...]という形のテンソルを作成
temporal_indices = torch.arange(
self.num_temporal_embeddings,
device=attention_mask.device
).repeat_interleave(self.num_spatio_embeddings).unsqueeze(0).repeat((batch_size, 1))
return self.spatio_embeddings(spatio_indices) + self.temporal_embeddings(temporal_indices)
6.2.3 Video Decoderの実装についての考察
GAIA-1のVideo Decoderは2.6Bパラメータの3D U-Netであることが論文中に記載されています。Video Decoderについても他の2コンポーネントと同様に具体的なモデルのアーキテクチャは示されていないほか、学習も複数のタスクで行われているという記述があり複雑なことが推測されます。
Video Decoderの実装については私たちの方もこれまでの経験が薄いため、現時点での具体的な実装方法はわかっていない部分がありますが、3D U-Netの中で用いられている"Factorized Spatio Temporal Attention"についてはMake-A-Videoの実装が、複数のタスクで学習を行う手法についてはFlexible Video Diffusion ModelingやOpenSoraの実装が参考になるのではないかと考えています。
6.3 学習について
GAIA-1の学習はImage Tokenizer、World Model、Video Decoderそれぞれを分けて行います。World ModelとVideo Decoderの学習にはImage Tokenizerで画像を離散トークンにした結果を用いるため、最初にImage Tokenizerを学習する必要があります。
一方で、実際に未来の動画を生成する際はWorld Modelの予測した未来の画像トークンがVideo Decoderの入力になるものの、Video Decoderの学習の際は予測された画像トークンではなく、実際の画像をImage Tokenizerでトークン化したものを使うことができます。したがって、World Modelの学習とVideo Decoderの学習は同時並行で行うことができます。
GAIA-1の学習には大量の計算リソースも必要になってきます。一番計算が軽いImage Tokenizerでも32×A100 80GB GPUで4日を要したという記述があります。また、World Model部分は64×A100 80GB GPUで15日、Video Decoderは32×A100 80GB GPUで15日かけて学習が行われています。近年のBigTechのLLM開発ではこれと比べても桁がちがうGPU daysが学習にかけられているのでそれと比べると大したことはないと思われる方もいるかも知れませんが、A100 80GB GPUを用いて1568 GPU daysかかる学習というのはなかなか手を出しづらいものかと思います。
世界モデルを含む生成AIの学習には大量の計算資源が必要なことを見越し、私たちは96基のH100 GPUからなる専有GPU計算基盤「Gaggle-Cluster-1」の構築準備を進めてきました。Gaggle-Cluster-1は、ノード間通信やストレージ速度を高速化することで、大規模モデルの学習効率を最大化するよう設計されており、2024年9月に稼働予定です。
私たちはこの計算基盤を生かし、世界モデル等の生成AI開発を実施していこうと考えています。
7. GAIA-1の課題・今後の発展
GAIA-1は非常に高品質で一貫性のある動画を生成できるモデルとして、自動運転の研究コミュニティだけではなく、生成AIの研究開発のコミュニティで高く評価されています。一方で、実際に自動運転開発に用いていくことを考えるとまだまだ多くの課題が残されています。
7.1 推論速度の問題
一番大きな課題は、推論の速度です。GAIA-1は1フレーム分の未来の生成のために576トークン分の自己回帰プロセスを回す必要があります。この段階ではまだ離散トークンによる状態表現でしかないため、動画の生成をするためにはさらにVideo Decoderを用いたデノイジングプロセスを実行する必要があります。ここ数年でのDenoising Diffusion Modelsの発展は著しいとはいえど、デノイジングプロセスでは複数回モデルによる推論を行なって反復的にノイズ除去を行なっていく必要があるため、どうしても推論時間が長くなりがちであることは多くの研究で指摘されています。
自動運転において世界モデルを使う方法は大きく分けて「自動運転システムの一要素としての利用」と「シミュレータとしての利用」の二つが存在する、という話はすでに上で紹介しましたが、推論の速度が遅いことはどちらの使い方においても問題になります。
自動運転システムの一要素として利用する場合、自動運転システムの制御周期内に処理が終わることが期待されるため、推論に時間がかかってしまうことは死活問題です。一方でシミュレータとして利用する場合も、エージェントがアクションを行いその結果起きた状態の変化や報酬などの情報がフィードバックされるループが遅くなるため実験の効率に大きな影響を与えてしまいます。
7.2 エッジケースにまつわる問題
また、GAIA-1は4,700時間の動画で学習されているものの、全てが運転時の走行映像なため走行映像になかなか出てこないような概念は理解していない可能性が高いです。例えば上の例では高速道路に豚さんが大量にいるような状況をシミュレートできる可能性について論じましたが、これは豚という概念を理解するのに十分な豚のデータを学習データに含んでいた場合です。走行映像のみでは例えば豚に関して言えば十分なデータが含まれていない可能性があります。
また、自動運転開発において真に重要なのは事故が起きてしまった場合のデータや事故が起きそうだった「ヒヤリハット」な状況のデータですが、このようなデータはそもそも稀なため集まりづらいですし、Wayveがデータ収集のために雇ったドライバーは安全な運転を心がけていると思われるため、ヒヤリハットな状況がそもそも一般的なドライバーよりも起こりづらい可能性もあります。
7.3 今後の発展
推論速度の問題の解決は簡単ではないものの、他のモデルアーキテクチャの活用などを通して、解決できる糸口はあると考えています。例えばOpenDriveLabが開発したGenADは未来の状態の予測を自己回帰的な予測ではなく、Denoising Diffusion Modelを用いて行う手法を提案しています。残念ながらこの方法でもリアルタイムでの生成はできていないということが報告されていますが、576トークン分の自己回帰を回避できる方法としては有望な方向性であると考えられます。また、近年はAlt-TransformerとしてMamba等の状態空間モデルが注目されています。これらのモデルはTransformerよりも高速であるという報告があり、高速化のために有用な可能性があります。
エッジケースの問題のシンプルな解決策は、運転画像に限らない多様な動画で世界モデルを学習することが挙げられるかと思います。また、ヒヤリハットの映像を収集しているヒヤリハットデータベースのようなものも存在するため、さまざまな研究機関・企業と連携をしながらヒヤリハットのデータを学習データとして収集することが重要であると考えられます。
今後世界モデルを自動運転に活かせる形にしていくためには上記で挙げた課題の解決のほかに、マルチカメラ化や長期の整合性の担保などが必要になってくると考えられます。
8. おわりに
本記事では、世界モデルという概念の紹介と、それがどのようにして自動運転に役立つのかを紹介し、高性能な世界モデルとして注目を集めているGAIA-1について詳細に解説しました。また、GAIA-1相当のものを再現するために必要な準備について現段階で私たちが考えていることについても紹介しました。
Turingは「We Overtake Tesla」をミッションに完全自動運転の実現に向けて尽力しています。経済産業省/NEDOの競争力のある生成AI基盤モデルの開発を支援するGENIACプロジェクトにも採択され、生成AI・大規模基盤モデルの開発を進めています。完全自動運転に向けたマルチモーダルな基盤モデルの開発にご興味ある方、お気軽にコメントやX (Twitter) のDMにてお問合せください。
-
自動運転開発におけるシミュレータの活用の記事を合わせてお読みください。 ↩︎
-
Heronについては合わせて日本語Vision Languageモデル heron-blip-v1の公開も合わせてお読みください。 ↩︎

Discussion