Survey of Query Classification in E-Commerce
はじめに
この記事は、情報検索・検索技術 Advent Calendar 2024 の13日目の記事です。
私は「Eコマース」x「自然言語処理」に興味を持っており、この記事では自然言語処理の中でも「Query Classification」に焦点をあて、サーベイした内容になっています。
Query Classification とは?
検索システムにおいて、検索クエリが何を意図しているかを理解することが検索品質の向上につながります。その分野をQuery Understandingと呼びます。
Query Understandingには、Query Rewriting、Query Expansion、Query Segmentationなど様々なタスクがあります[1] 。
それらのタスクの中で「検索クエリに対し、事前に定義したカテゴリに分類するタスク」をQuery Classification(またはQuery Categorization)と呼びます。
Eコマースの検索システムでは、ユーザがどのカテゴリの商品を探しているかが重要であるため、Eコマース企業はQuery Classificationに関する研究を盛んに行っています。
Query Classificationのタスクが注目されはじめたのは、KDD-Cup2005コンテスト[2][3] がきっかけだと思います。そのコンテストをベースに、タスクの概要や課題について説明します。
タスクについて
KDD-Cup2005コンテストでは、80万件の検索クエリに対して67の階層構造を持つカテゴリを分類するタスクを扱い、各クエリに対して最大5つのカテゴリを割り当てた訓練データが用意されました。評価用の各クエリに、最大5つのカテゴリを割り当てて提出を求められました。
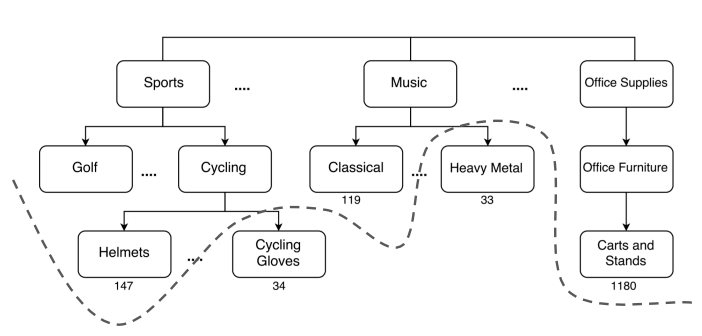
一般的にQuery Classificationは、入力xが検索クエリであり、出力yが複数の階層構造を持つカテゴリのマルチラベル分類のタスクとなります。

階層構造を持つカテゴリ体系のイメージ図[6]
複数のカテゴリを出力するのは、検索クエリが一つのカテゴリに定まらないケースがあるためです。
例えば「ワンピース」の検索クエリだと、Category:Fashion、Category:Comicsの複数カテゴリを持ちます。
マルチラベル分類にあたるため、評価指標はF1、Precision、Recall(macro/micro平均)を扱うことが多いです。
課題
KDD-Cup2005コンテストで明らかになった課題を含め、Query Classificationの課題の一部には以下のものがあります。
- 学習データの不足
- 検索クエリの意図が曖昧
- 階層構造を生かしきれていない
これらを対処した論文をコンパクトにまとめて紹介しようと思います。
詳細については、論文の方を参照してください。
論文紹介
学習データの不足への対策
クエリ : カテゴリ = 1 : N の学習データを人手でアノテーションするにはコストが高いです。
そのため、学習データを大量に確保できる代替データで学習するアプローチをとるのが一般的です。
代替データを確保するアプローチは大きく分けると、二つにわかれます。
- ユーザの行動ログ(商品へのClick,カート追加,注文など)を利用
- 商品タイトル : カテゴリ = 1 : 1 のデータを利用
ユーザの行動ログを利用する場合、検索頻度が極端に少ないクエリ(Long-Tailクエリ)も存在し、一部のクエリに対して学習データの不足が生じます。
Long-Tailクエリに対処したアプローチも存在し、合わせて紹介します。
E-commerce Product Query Classification Using Implicit User’s Feedback from Clicks (2018)[4]
- 所属: Rakuten
- 課題:
- 人手のアノテーションコストが高い
- アプローチ:
- ユーザの暗黙的フィードバック(商品へのClick)を利用することで、学習データを確保
- 2,085カテゴリからなる403,349クエリを含むマルチラベル分類のデータセット
- ユーザの暗黙的フィードバック(商品へのClick)を利用することで、学習データを確保
- 結果:
- 線形SVMのアンサンブルモデルで第一階層カテゴリのmicro-f1は0.82, 末端カテゴリのmicro-f1は0.6を達成
- 補足・感想:
- Clickログを使った論文はこれが最初?
- マイナーカテゴリはクリック総数の閾値処理で対象から外す (5,896→2,085)
マイナーカテゴリ
E-commerce Query Classification Using Product Taxonomy Mapping: A Transfer Learning Approach(2019)[5]
- 所属: The Home Depot
- 課題:
- 人手のアノテーションコストが高い
- アプローチ:
- 商品タイトル-カテゴリのデータは大量にあるので利用
- transfer-learning
- 1st phase: 商品タイトル-カテゴリのデータセット(大量)で学習
- 2nd phase: クエリ-カテゴリのデータセット(少量)で学習
- 結果:
- 2nd phaseのデータセットが少ないほど精度の改善幅が大きい
- 補足・感想:
- 一定数のクエリ-カテゴリのアノテーションデータは必要
Modeling acrosscontext attention for long-tail query classification in e-commerce(2021)[6]
- 所属: Alibaba
- 課題:
- 1ターム追加するだけで推定すべきカテゴリは変わることがあり、データが少ないTailでは顕著
- 「Tシャツ」-> Category:Fashion Top
- 「Tシャツ ボタン」-> Category:Botton
- 1ターム追加するだけで推定すべきカテゴリは変わることがあり、データが少ないTailでは顕著
- アプローチ:
- 類似するクエリの対比関係を学習するモジュールを追加
- ベースモデル + Across Context Attentionモジュールを追加
- 類似するクエリの対比関係を学習するモジュールを追加
- 結果:
- オフライン/オンラインで有効性を検証
- 補足・感想:
- アーキテクチャが複雑になってくる

モデルのアーキテクチャ
Enhanced Representation with Contrastive Loss for Long-Tail Query Classification in e-commerce(2022)[7]
- 所属: Alibaba
- 課題:
- クリックログを用いて学習するのは一般的だが、Long-Tailクエリのデータは不足、ノイズも多い
- アプローチ:
- 先ほど論文と似ていて、ベースのクエリと似たクエリを探し出しContractive Learningを行う
- ベースのクエリ/似たクエリ両方ともログが十分あるものを採用
- 先ほど論文と似ていて、ベースのクエリと似たクエリを探し出しContractive Learningを行う
- 結果:
- Long-tailクエリ(Head/Middle/Tail)では f1スコア+1.43%/+1.03%/+2.99%
- 補足・感想:
- 推論時はMain Moduleのみ利用
- 2022年の論文からBERT利用がベースになってくる

モデルのアーキテクチャ
Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search(2022)[8]
- 所属: JD.com
- 課題:
- BERTを活用したいが、wikipediaとEコマースではドメインが違う
- クリックログをFinetuneで活用するにしても、Long-Tailクエリのデータは不足
- アプローチ:
- Query Classification向けの事前学習方法を提案 (※ベクトル検索タスクは省略)
- MLM + 商品タイトルの部分文字列をクエリとし、商品カテゴリを推定するタスク
- Query Classification向けの事前学習方法を提案 (※ベクトル検索タスクは省略)
- 結果:
- micro-F1で4.6%改善。A/Bテストでも改善。
- 補足・感想:
- 商品タイトルの部分文字列をクエリにしている箇所がLong-Tailクエリの問題を考慮している?
- eコマースに特化したBERTの事前学習の提案は初めて?

Improving Search for New Product Categories via Synthetic Query Generation Strategies(2024)[9]
- 所属: Amazon
- 課題:
- クリックログを活用することが一般的だが、新しいカテゴリに対してのクリックデータは少ない (コールドスタート問題)
- アプローチ:
- 合成データを作成し、新しいカテゴリのデータを補強
- 過去のクエリ、商品のクリックデータからLLMをFinetuningし、商品からクエリを生成できるモデルを作成
- 合成データを作成し、新しいカテゴリのデータを補強
- 結果:
- 合成データ増強なしのベースラインと比較して、公開データセットのPR-AUCは+2.96%と実データセットは+2.34%
- 補足・感想:
- クエリ生成時、クエリとカテゴリの関連性の確率的分布を調整
- LLMを用いたテキスト分類手法はText Classification via Large Language Models[10]があるが、100以上を超えるExtremeマルチラベル分類や推論速度の課題があるので、まだEコマースへの適用は先になりそうで、LLMはデータ拡張に活かす論文が多そう

検索クエリの意図の曖昧性を利用
JointMap: Joint Query Intent Understanding For Modeling Intent Hierarchies in E-commerce Search (2019)[11]
- 所属: Emory University, The Home Depot
- 課題:
- 購入意図ないクエリがある可能性を考慮できていない
- アプローチ:
- 購入意図判定とクエリのカテゴリ分類を同時に学習
- 結果:
- 購入意図判定タスクはmacro-f1 +1.1%、カテゴリ分類タスクはmacro-f1 +6.3%の精度向上
- 補足・感想:
- 購入意図のデータが有無は人手で少量のデータセットを作成し、KNN+SVMを活用し拡張
- カテゴリ分類のデータは「CTRが一定以上高いカテゴリ」を採用

購入意図有無クエリの事例
階層構造を考慮
Deep Hierarchical Classification for Category Prediction in E-commerce System(2020)[12]
- 所属: Alibaba
- 課題:
- カテゴリの階層ごとに分類器を作っていて、階層間の情報を生かせてない
- 階層ごとの予測に不整合が生じる
- 第一階層の分類器ではCategory:Freshと予測し、第二階層の分類器ではCategory:Computerと予測した場合、親子関係にない場合がある
- アプローチ:
- 第N階層の埋め込み表現は第N+1階層の埋め込み層に利用するフレームワークを提案
- 階層の不整合を考慮した損失関数を提案
- 結果:
- 第一階層、第二階層ともに既存研究よりも精度向上
- 補足・感想:
- クエリのカテゴリ分類はマルチクラス分類として扱っている

モデルのアーキテクチャ
HierCat: Hierarchical Query Categorization from Weakly Supervised Data at Facebook Marketplace(2023)[13]
- 企業: Meta
- 課題:
- クリックログのデータはノイズが多い
- 「中古家電」みたいな曖昧なクエリもある
- 言語間で不均衡があり、英語みたいな一般な言語に偏りがち
- アプローチ:
- ノイズの問題は、カテゴリのテキスト情報を利用
- 曖昧なクエリ問題は、階層構造を考慮することで対処(?)
- 子カテゴリの確率を親カテゴリの確率値に足し上げ、同じ階層のカテゴリは合計1になるようにsoftmax
- 言語間の不均衡問題は、XLM Encoderを利用
- 結果:
- オフラインでも既存手法を上回り、オンラインでも検索ブーストに利用しNDCGを+1.4%
- 補足・感想:
- マルチカテゴリ分類として扱っていなく、P(カテゴリ|クエリ)を求める問題として扱っている
- クエリとカテゴリと同じ埋め込み空間にするアプローチ

HCL4QC: Incorporating Hierarchical Category Structures Into Contrastive Learning for E-commerce Query Classification(2023)[14]
-
所属: Alibaba, Tsinghua University
-
課題:
- カテゴリに記載された限られた単語に依存
- マルチラベル分類はカテゴリの階層構造を考慮していない
-
アプローチ:
- CTRが高い商品から、カテゴリごとのBag-of-Wordsを取得して利用
- 階層構造を考慮した損失関数を導入
- 局所的階層的対照損失(LHCL): 共通の親カテゴリの表現を利用してカテゴリ間の差異を計算

- 大域的階層的対照損失(GHCL): 親カテゴリと子カテゴリの表現を一致させ、階層の生合成を維持

- 局所的階層的対照損失(LHCL): 共通の親カテゴリの表現を利用してカテゴリ間の差異を計算
-
結果:
- メジャーカテゴリのf1scoreは+0.81%、マイナーカテゴリのf1scoreは+2.10%
-
補足・感想:
- Deep Hierarchical Classification for Category Prediction in E-commerce Systemを引用していないのは気になる
- Enhanced Representation with Contrastive Loss for Long-Tail Query Classification in e-commerceと同様、推論時はMain Moduleのみ利用

学習データの事例

モデルのアーキテクチャ
Hierarchical Query Classification in E-commerce Search(2024)[15]
- 所属: Georgia Institute of Technology Atlanta, Amazon, The Pennsylvania State University
- 課題:
- カテゴリによっては不均衡で、マイナーカテゴリの精度は低下しがち
- カテゴリの階層構造も利活用できていない
- カテゴリのラベルがついていないクエリも多い
- アプローチ:
- 階層構造を利用
- 階層構造をグラフとしてモデル化し、カテゴリ間の関係性を表現
- 子カテゴリに対するデータが少なくても、親カテゴリに対するデータは多いので不均衡問題は少し緩和
- 同一カテゴリ内や異なるカテゴリ間でクエリ埋め込みの関係をConstract Learning
- マイナーカテゴリの特徴を明確に抽出できる
- kNNと埋め込み表現を利用し、ラベルがないクエリを近隣ラベルに基づいてデータを補強
- マイナーカテゴリに対するデータの補強もできる
- 階層構造を利用

モデルノアーキテクチャ
- 結果:
- AmazonデータセットではSOTAよりも優れており、他データセットではSOTAに匹敵

- AmazonデータセットではSOTAよりも優れており、他データセットではSOTAに匹敵
- 補足・感想:
- 工夫が盛りだくさんなアプローチで、LLMの登場により、どのように変わるか気になる
サーベイでの感想
Query Classificationの論文を時系列で追っていくと
- 2018年: クリックログを使ったアプローチが出現
- 2020年: 階層構造を意識した論文が出現
- 2021年: クリックログはHeadクエリには有効だが、Long-tailクエリには課題があり、様々なアプローチが出現
- 2022年: BERTを使ったアプローチが一般的になる
- 2024年: マイナーカテゴリを意識した論文が出現、またLLMを活用した論文も出現
2025以降はLLMを活用した論文が今より多く出ることが予想されるので、その際は読んでみようと思います。
先ほど紹介した論文はショッピングサイトを運営する企業が多かったのですが、フリマサイトを運営するメルカリでもQuery Classification[16]を取り組んでいます。
フリマサイト特有問題も興味があるため、論文が出た際には読んでみようと思います。
さいごに
本記事では、EコマースにおけるQuery Classificationの研究動向をサーベイしました。
私は「Eコマース」x「自然言語処理」に興味を持っておりますので、Query Classification以外の題材についても、紹介できればと思います。
-
Ying Li et al.: KDD CUP-2005 Report: Facing a Great Challenge('05,KDD) ↩︎
-
Yiu-Chang Lin et al.: E-commerce Product Query Classification Using Implicit User’s Feedback from Clicks('18, IEEE BigData) ↩︎
-
Michael Skinner et al.: E-commerce Query Classification Using Product Taxonomy Mapping: A Transfer Learning Approach('19, SIGIR eCom) ↩︎
-
Junhao Zhang et al.: Modeling acrosscontext attention for long-tail query classification in e-commerce('21,WSDM) ↩︎
-
Lvxing Zhu et al.:Enhanced Representation with Contrastive Loss for Long-Tail Query Classification in e-commerce('22, ECNLP) ↩︎
-
Yiming Qiu et al.: Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search('22,CIKM) ↩︎
-
Akshay Jagatap et al: Improving Search for New Product Categories via Synthetic Query Generation Strategies('24, WWW) ↩︎
-
Xiaofei Sun et al: Text Classification via Large Language Models('23, EMNLP) ↩︎
-
Ali Ahmadvand et al.: JointMap: Joint Query Intent Understanding For Modeling Intent Hierarchies in E-commerce Search ('19, SIGIR) ↩︎
-
Dehong Gao et al.:Deep Hierarchical Classification for Category Prediction in E-commerce System('20, ECNLP) ↩︎
-
Yunzhong He et al.: HierCat: Hierarchical Query Categorization from Weakly Supervised Data at Facebook Marketplace('23,WWW) ↩︎
-
Lvxing Zhu et al.: HCL4QC: Incorporating Hierarchical Category Structures Into Contrastive Learning for E-commerce Query Classification('23, CIKM) ↩︎
-
Bing He et al.: Hierarchical Query Classification in E-commerce Search('24,WWW) ↩︎
-
Mercari engeneering 言語モデルを用いたQuery Categorization ↩︎
Discussion