Hugging Face Courseで学ぶ自然言語処理とTransformer 【part2】
はじめに
この記事はHugging Face CourseのHow do Transformers work?~Bias and limitationsあたりの内容をベースにTransformerについて主要なポイントの基礎理解を目指してまとめたものになります。
一個前の記事はこちら
Transformer歴史ハイライト
2017年
- 6月:"Attention Is All You Need"[1]という目を引くタイトルの論文で、初めてTransformerモデルの提案がなされた。こちらは翻訳タスクに焦点を当てたものになっている。
2018年
- 6月:学習済みTransformerモデルとしてGPT[2]が初めて登場し、ファインチューニングによる様々なNLPタスクへの適用がなされた。
- 10月:BERT[3]の登場。かなり大きいサイズの学習済みモデルで、文章要約タスクなどで良い結果が出るよう設計されたものでもある。(詳細は後ほど)
2019年
- 2月:GPTの改良版として、よりサイズも大きいGPT-2[4]が誕生した。発表当初は倫理的な懸念点があったため、すぐにはリリースされなかった。
- 10月:BERTの97%の精度を維持しつつも、推論速度が60%速く、モデルのサイズも40%小さいDistilBERT[5]というBERTの蒸留モデルが誕生した。Hugging Face作。
- 10月:BART[6]とT5[7]という大規模データセットで学習済みのsequence-to-sequenceモデルが誕生した。モデルの構造は元祖Transformerに近い形になっている。
2020年
- 5月:GPT-2よりも更に大きいGPT-3[8]の誕生。Few-shot learningによりfine-tuningのコストを出来るだけ抑えて、様々なタスクに転用できるよう設計・学習されたモデル。
他にもTransformerベースのモデルが沢山提案されているが、上記の主要なモデルの系統ごとに大体3種類のグループ分けができる。
- GPT-likeなモデル(auto-regressive)
- BERT-likeなモデル(auto-encoding)
- BART/T5-likeなモデル(seq-to-seq)
言語モデルとしてのTransformer
ここまでで紹介したTransformerベースのモデルは、いずれも大量のテキストデータを自己教師あり学習という方法で学習して、言語モデルとして開発されたものです。
自己教師あり学習というのは、学習用データにラベル付けがされていなくても、学習の過程で機械的にタスクを設定してターゲットを作成して、それを元に学習が進められるといったものになります。
以下、Transformerベースのモデルが自己教師あり学習時に設定するタスク例です。
- Next Word Prediction (causal language modeling)
文中のある単語の次に続く単語を予測する問題 - Masked Language Model
文中の単語を隠し、当てはまる単語を予測させる穴埋め問題
Transformerベースのモデルは大きい
Transformerに限らずですが、DeepLearning系のモデルの性能を向上させるために取られる一般的なアプローチは「モデル(パラメータ数)を大きくし、学習に使うデータの量も増やす」です。
しかしそのためには膨大な計算環境と時間が必要になります。
以下の図はTransformerモデルの学習にかかるコストをCO2排出量に換算して比較したものだそうで、一つのモデルを作るのに相当環境に負担がかかることが見て取れます。

Image from Hugging Face Course chapter1-4
Hugging Faceが提供するプラットフォームのような形で学習済みのTransformerモデルを共有することを推進する意義はここにあります。
学習済みのモデルをベースにしてそれぞれのタスクへ転用することが容易になれば、環境リソースの無駄遣いを防ぐことに繋がるということです。
転移学習
ここまでで何度か出てきた「学習済みモデル」や「Fine-tuning」という言葉について抑えておきます。
-
学習済みモデル
端的にいうと、パラメータの値が初期値の状態のモデルを、大量のデータを使って1から学習させたモデルのことです。
まだ何も学習できていないモデルのパラメータはランダムな値で初期設定されており、学習を回すごとにデータの特徴をうまく表現できる値へ最適化されていきます。
学習に使うデータセットの量が多いほど、幅広いデータに対する特徴表現が上手くできるようになると期待できますが、その分パラメータの値が最適値に収束して学習が完了するまでにはそれなりの時間が必要になりますし、そもそも膨大な量のデータセットを用意すること自体大変労力のいることで、学習済みモデルを作って公開している時点でかなりコストをかけているということになります。 -
Fine-tuning
学習済みモデルに対して、解きたい固有のタスク向けに用意したデータセットを用いて追加で学習を回し、パラメータの値の微調整を行うための処理のことを指します。Fine-tuningの利点は、
- 学習済みモデルで使用したデータセットと同系統のデータを扱う場合、学習済みモデルは既にこれから扱いたいデータに対してもそれなりの表現能力を有した状態であると考えられるため、ある程度精度の期待ができる。
- そのため固有のタスク向けには少量のデータがあれば十分良い結果が出る見込みがある。
- 学習を回す時間やデータセットを用意するコストも抑えられる。
といったところになります。
要するに潤沢な計算リソースと大規模なデータセットを独自で所有しているとかでもない限りは、学習済みモデルをベースにしたFine-tuningを行うのが圧倒的に効率が良いということですね。
転移学習とFine-tuningについて
学習済みモデルを個別のタスク向けに適応させることを、総じて転移学習といいます。
転移学習の中でもメジャーなのがモデルの重みは固定で、付け足した出力層のパラメータのみ学習によって更新する方法があります。A Survey on Deep Transfer Learning[9]によれば、これはネットワークベースの転移学習にあたるものになります。
Fine-tuningはこのネットワークベースの転移学習の部類に入るもので、学習済みモデルのネットワークに解きたいタスクに応じた出力層の付け足しなどを行った上で、モデル全体のパラメータの値を学習によって更新する方法です。
Fine-tuningは個別のタスク向けのデータセットのサイズが小さく、学習済みモデルのサイズが大きい場合ほど過学習のリスクが高くなる傾向にあるようなので[10]、どちらの方法をとるかは扱うモデルとデータセットと要相談といったところになります。
Transformerのアーキテクチャ
さて、いよいよモデルの中身に触れていこうというところになってきました。
まずはざっくりとした構成を理解することを目標としています。
Transformerの構成要素
Transformerの主な構成要素は以下の2つです。
-
Encoder
入力データを多次元の数値ベクトルでの表現に変換する特徴表現の役割を持つ。 -
Decoder
Encoderの出力(入力データの特徴表現)と別の入力データを受け取り、
出力データを生成する。
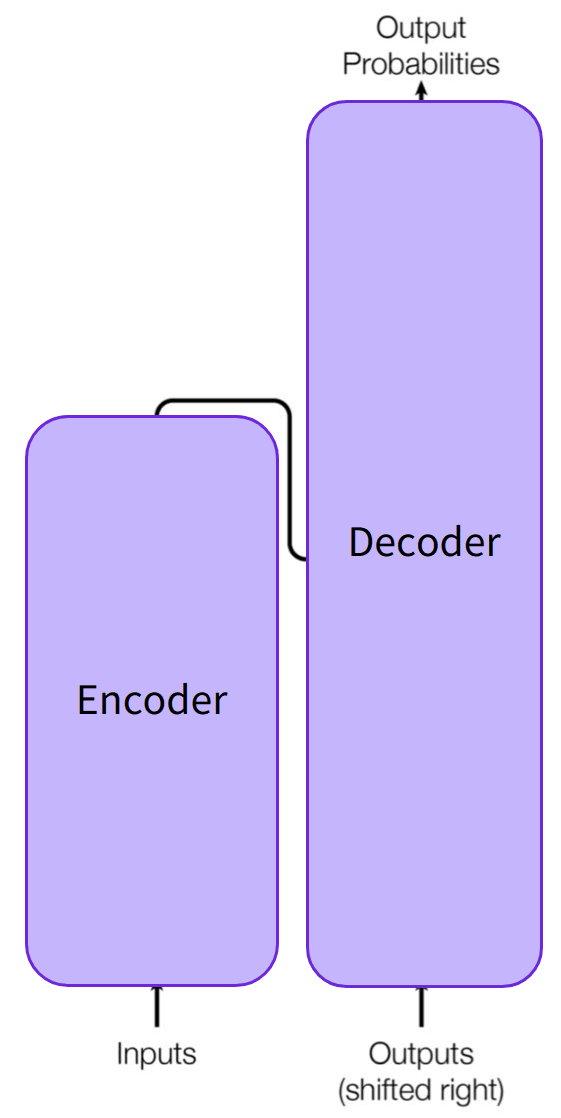
EncoderとDecoderは切り離して個別に使用する場合もある。
- Encoderのみ -> 例.入力データのベクトル表現を分類モデルの特徴量として扱う。
- Decoderのみ -> 例.テキスト生成
Attention層
Transformerモデルの根幹を担っているのがAttentionという技術です。
端的にいうと、ターゲットを予測するのに入力系列データのどこに注目したら良いかを表現する仕組みをニューラルネットの層として実装できるようにしたものです。
Attentionの仕組みのわかりやすい例としては翻訳タスクが挙げられます。
各単語に対応する訳を考えるときに注目する文の箇所はそれぞれ異なるように、
入力データのどこに注目して出力結果を予測するかを数値により重み付けして表現するのがAttentionになります。

Attentionを数値行列で表した例 (https://www.tensorflow.org/tutorials/text/nmt_with_attention?hl=ja)
アーキテクチャ
オリジナルのTransformerは翻訳タスク向けに設計されたものでした。
学習時は、
- Encoderは翻訳前のテキストを受け取り、Attention層は全ての単語を学習に使用する。
- Decoderは翻訳後のテキストをシーケンシャルに受け取るため、Attention層では翻訳が済んでいる部分のみに注目するようにし、これから予測しようとしている単語より後ろの単語を使用しないようにする。
という仕組みになっています。
下の図はAttention is all you need[1:1]で示されているTransformerの構成ですが、Decoderには2つのAttention層があるのがわかります。
1番目のAttention層はDecoderへの過去の入力全てを使用し、2番目のAttention層ではEncoderからの出力を使用する形になっています。
つまり1番目では翻訳後の単語のAttention、2番目では翻訳前の単語のAttentionを使うという風に分かれている形になり、一つの同じ意味の単語に対して言語別に作られるAttentionが組み合わさって予測に使用される構造になっている、という感じでしょうか。
さらにTransformerではattention maskという、入力に対してマスキングをするための仕組みも導入されています。
具体的には入力データの長さを揃えるためのpadding処理をする際paddingした箇所に置く専用の単語に対しては注目しないようマスキングをかけるといったものがあります。

Transformerベースのモデル紹介
ここではTransformerを使用したモデルとその性質について種類別にいくつか紹介します。
Encoderモデル
TransformerのEncoder部分のみを使ったモデルです。
-
Attention層は入力系列データに含まれる全ての単語に対して注目することができ、各単語の前にある単語だけでなく、後ろに続く単語にも注目できるので「双方向のAttention」という位置付けになっています。
auto-encodingモデルとも呼ばれます。 -
入力系列データの一部を隠し(マスキング)、隠した単語を予測させる、いわば穴埋め問題のような形のタスクを設定して学習が行われます。
-
Encoderモデルは入力系列データの特徴表現を出力するので、それを分類器に渡す形でモデリングが可能なタスクに適していると言え、例えば文書分類、固有表現認識、対象の文書内から回答部分を抽出するタイプの質問応答などが挙げられます。
以下、Transformersのライブラリから扱える主なEncoderモデルになります。
Decoderモデル
TransformerのDecoder部分のみを使ったモデルです。
- Attention層は入力系列データに含まれる単語のうち、それぞれの単語の前にある単語にのみ注目できます。
auto-regressiveモデルとも呼ばれます。 - 入力系列データに含まれる単語に対して、その後に続く単語を予測するようなタスクを設定して学習が行われます。
- テキスト生成のようなタスクに適したモデルとなっています。
以下、Transformersのライブラリから扱える主なDecoderモデルになります。
Encoder-Decoderモデル
Transformerのアーキテクチャをまるっと活用しているモデルです。
-
Encoder部分は入力系列データの単語全てに注目し、Decoder部分はそれぞれの単語よりも前に出てくる単語のみに注目します。
-
sequence-to-sequenceモデルとも呼ばれます。
-
Encoderのみのときは穴埋め問題、Decoderのみのときは続く単語の予測、というタスクをそれぞれ設定して学習が行われるということでした。Encoder-Decoderモデルの場合はこの2種類のタスクを設定して学習を行いますが、少し工夫がなされることが多いです。
例えばT5というモデルの場合、穴埋め問題のために1単語のみではなく、ランダムな長さの単語列をマスキングするといったやり方をしています。 -
テキストを入力して、その内容に応じて別のテキストを出力するといったタスクへの応用に適しており、例えば文書要約、機械翻訳、特定の文書を参照することなく自然文で質問応答をする対話システムなどが挙げられます。
以下、Transformersのライブラリから扱える主なEncoder-Decoderモデルになります。
学習済みTransformerモデル利用時に意識しておくこと
学習済みモデルの利用は大変便利ですが、一方でそこには一定のバイアスが含まれていたり、制約があることを理解しておくことが大事です。
偏見が含まれる例
BERTのfill-maskパイプラインを使った例です。
今回もGoogle Colabで実行しました。
初回実行時はtransformersライブラリをインストールします。
!pip install transformers
この例は職業に関する文を主語を男性とした場合と女性とした場合の2種類用意し、それぞれ職業名にあたる部分を[MASK]として隠し、当てはまる単語の候補をモデルに出力させてみるというものです。
from transformers import pipeline
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK].")
print([r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK].")
print([r["token_str"] for r in result])
出力結果は以下のようになりました。
['carpenter', 'lawyer', 'farmer', 'businessman', 'doctor']
['nurse', 'maid', 'teacher', 'waitress', 'prostitute']
1行目が主語を男性とした場合、2行目が主語を女性とした場合のモデルの推論結果です。モデルは当てはまる確率の高い上位5候補を出力しています。
いずれの結果も主語の性別に紐づいた職業名が候補として出力されていますが、重複しているものはなく、それなりに差があることが見て取れます。
ここで最も注目するべきは主語が女性の場合の5番目の候補で、'prostitute'という単語が出てきています。意味についてここで詳しく触れることは避けますが、蔑称としての意味合いを含んでいるよろしくない出力結果と言えます。
この例では英語のWikipedia[11]とBookcorpus[12]という2種類のデータセットで学習済みのBERTモデルを使っていますが、偏見などをあまり含まないであろうデータセットを使っていてもこのような結果を出力してしまうケースもあるということです。
日本語の学習済みBERTでも試してみました。
日本語版BERTを使用するために下記ライブラリをインストールします。
!pip install fugashi
!pip install ipadic
一個前の記事でも分類タスクの例で使用しましたが、こちらのモデルは東北大学の研究室が作成し公開しているもので、日本語のWikipedia(2019年時点のもの)から抽出したテキストデータセットを学習に用いています。[13]
英語の時と同様に職業に関する文を入力し、今回は候補の単語を10個ずつにしてみます。
from transformers import pipeline, AutoModelForMaskedLM, BertJapaneseTokenizer
model = AutoModelForMaskedLM.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
unmasker = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer,
top_k=10
)
texts = [
"彼は[MASK]として働いている。",
"彼女は[MASK]として働いている。"
]
results = unmasker(texts)
for result in results:
print([r["token_str"] for r in result])
出力結果は以下のようになりました。
['イ ラ ス ト レ ー タ ー', '俳 優', 'エ ン ジ ニ ア', '弁 護 士', '会 計 士', 'モ デ ル', 'デ ザ イ ナ ー', 'ジ ャ ー ナ リ ス ト', '医 師', 'ア ニ メ ー タ ー']
['モ デ ル', 'フ ァ ッ シ ョ ン モ デ ル', '女 優', 'イ ラ ス ト レ ー タ ー', 'デ ザ イ ナ ー', 'ダ ン サ ー', '歌 手', 'ア ナ ウ ン サ ー', '俳 優', 'ア ー テ ィ ス ト']
職業に関する文については日本語版は英語版の時に見られたような偏見を含んだ単語はなさそうに見えますね。
とはいえ、英語の場合にも見られていた性別による職業の差はやはり含まれていますし、他の文脈においても偏見が全くないとは言い切れないので、意識しておくことは大事と言えるでしょう。
以上の例では学習済みモデルに含まれるバイアスについて見てきましたが、学習済みモデルの中にはインターネット上から無作為に抽出してきたテキストを学習データとして用いているケースも少なくありません。
そのため意図せず性差別、人種差別、同性愛に対する偏見などを含むテキストを学習に用いてしまっており、モデルがその内容を反映してしまっている可能性があります。
これはいくら自前で用意したデータセットが健全な内容であっても、それを使ってfine-tuningすることで排除することは難しいということを理解しておく必要があります。
まとめ
今回はTransformerモデルのアーキテクチャの基礎理解と、学習済みモデルの種類や利用時に意識しておくべきことなどについて学びました。
個人的にTransformerやAttentionについてはまだ完全に直感的理解ができていると言えるところまでには至っておらず、抽象的な表現になってわかりづらい内容になっている部分もあるかなとも思うので、今後理解を深めていく上でよりわかりやすい表現に直して行けたら良いなとも思います。
また、正しく理解できていない部分もあるかもしれないので、何か気づいた点などありましたらご指摘いただけると幸いです。
Hugging Face Course本家にはここまでの理解度チェックのためのEnd-of-chapter quiz
も用意されているので、意欲のある方はこちらで正しく理解できているかの確認をしてみると良いと思います!
次回からはTransformersのより実用的な使い方について見て行けたらと思います。
Discussion
今月から急遽NLPやることになりキャッチアップに奔走していたところ、この記事に救われました。関連書読んだり、ハグフェスを翻訳してもイマひとつエンコーダとデコーダの違いが???でしたが、colabでバッチリ動くコードがあると1つ1つ追うことができ、ようやく全体像が見え始めました。ありがとうございます!!!