[超入門] ド素人でも理解できる!世界一丁寧なデータベース/SQLの教科書
この記事では、 データベース・SQLという概念について、初心者の方向けに可能な限り丁寧に解説していきます。
ぜひ最後までお付き合いください。
この記事のゴール
最初にこの記事のゴールを確認しておきましょう。
- データベースという概念をなんとなく理解すること
- 簡単なSQLを自力で書けるようになること
です。
駆け出しエンジニアの方に読んでいただきたいのはもちろん、営業やマーケティングなど、エンジニア以外の職種の方にも役立つ情報だと思っています。
というのも、最近の先進的な会社では、マーケティング部門が(わざわざエンジニアに頼むことなく)自分でSQLを使ってデータを集計・分析するような例も増えつつあり、今やデータベース/SQLの知識はエンジニアでなくとも身につければ非常に潰しが効く&武器になる知識だからです💪✨
ぜひ前向きに取り組んでみてください!
データベースとは
それでは早速本題に入っていきます。
データベースと聞くとなんだか難しそうに聞こえますが、ぶっちゃけ 単なる「表」の集まり です。
データベースは、膨大なデータを効率よく管理できるように作られています。
少量のデータを管理するだけなら、例えばExcelなどでも十分に管理することもできるでしょう。
データベースで管理するのもExcelで管理するのも本質的にやることは同じです。
データが膨大になってきたときに、Excelでは難しい細やかな集計方法や、便利に管理するための機能を色々使えるのがデータベースのメリットです。
例えば、データベースを使うと、 膨大なデータの中から、指定した条件に一致するデータをお好みの形に整形して取り出したりすることができます 🙌
さて、データベースを作ったり管理したりするためには専用のソフトを使う必要があります。
代表的なデータベースソフトには、
- MySQL(マイエスキューエル)
- PostgreSQL(ポストグレスキューエル、しばしば「ポスグレ」と略される)
- Microsoft Access
などがあります。
ある程度の規模のソフトウェアシステムでは、ほぼ例外なく裏側にデータベースがあります。
ケーススタディ:「ブログ記事と記事ごとのコメント」というデータを管理してみる
例えば、よくある「ブログ記事」と「各記事に寄せられたコメント」というデータを考えてみましょう。
表形式で管理するとしたら下図のようなイメージになるでしょう。

この例だとたまたま1つの記事に1つずつしかコメントが付いていませんが、もちろんコメントはいくつでも投稿することが可能です。
各記事に複数のコメントが付いた場合、表は以下のような形になるでしょう。

パッと見で単純に見づらいと思いますが、この表には見づらいこと以上の致命的な問題があります。それは、 情報が重複して保存されている ということです。
例えば、あとから最後のブログ記事のタイトルを変更する場合 、下図の黄色い部分3箇所を更新する必要があります。

このような場合に、変更になった情報は本質的には 1つの記事のタイトル だけなのに、同じ変更を複数の行に対して行わなければならないため、
- 単純に面倒
- ミスりそう
-
ミスったときにデータの不整合が発生してしまう
- 例えば、上記の例で3行のうち1行だけ記事タイトルを変更し忘れてしまった場合、「どっちが正しい記事タイトルなのか」が分からなくなってしまいます🙄
という問題があることが分かると思います。
たったこれだけのデータ量でもすでに面倒くさそうですが、何十万本も記事があってすべての記事に何百というコメントが付くような巨大メディアだったら 一体どうなってしまうでしょうか…?😰
とてもじゃないけど1つの表で管理するのは無理そうですよね。
ちなみに、この例を見て「Excelの『セルの結合』を使えば重複をなくせるのでは?」と思った方も多くいらっしゃると思います。
それは完全にそのとおりで、表形式のデータの管理にExceというツールを使うなら、確かに「セルの結合」機能によって重複をなくすことはできます。
この話の趣旨は、「そうだとしても、Excelよりもデータベースというツールを使うほうが色々便利だよ」ということなので、その認識で読み進めていただければと思います🙏
データベースを使うとどうなるか
このような情報をデータベースを使って管理する場合、一般的には下図のように 2つの表に分けるのがセオリーです。
ちなみに、データベース用語では「表」のことを「テーブル」と呼びます。


この例では、 記事 テーブルと コメント テーブルにデータを分割して、
- 記事の情報は
記事テーブルだけで管理 - コメントの情報は
コメントテーブルだけで管理 - コメントがどの記事に対してのものか、という情報は、
コメントテーブルの記事IDという列で管理
しています。
ポイントは、2つのテーブルそれぞれで 情報の重複が一切ない という点です。
このような形で管理することで、先ほど例に挙げたような「記事タイトルを変更したい」という場合には、 記事 テーブルの1行だけを変更すればいいという状態になっています。
こんな風に「データの重複を排除した複数のテーブルを管理する」のは、Excelではかなり面倒くさいですよね。
それを簡単にできるようにしてくれるのがデータベースです 👍
SQLとは
データベースにデータを保存したり、データベースからデータを抽出したりといった操作するためには、 SQL(エスキューエル:Structured Query Language) という専用の言語を使う必要があります。
ちなみに、MySQLやPostgreSQLなどデータベースソフトごとにSQLの文法は多少違っていたりします(「方言」と表現されます)。
この記事ではMySQL用のSQLを扱いますが、この記事で扱う内容のレベルならほとんど方言による差異はありませんので、他のデータベースソフトを使う予定がある方もどうぞ安心して学んでください。
データベースに対する操作は、
- データの抽出
- データの追加
- データの更新
- データの削除
の4つがありますが、どの操作をする場合も、SQLで命令を記述する必要があります。 (この記事では「データの抽出」の方法だけを学びます)
例えば、
-
postというテーブルから、 -
dateという列の値が2023-03-01以降の日付になっているものだけを抽出して、 -
idという列の値で降順に並べ替えて、 -
idとtitleという2つの列の値を表示する
ということをやりたい場合は、以下のようなSQLを実行します。
SELECT id,title FROM post WHERE date >= '2023-03-01' ORDER BY id DESC;
なんとなーく、書いてあることの意味は想像できそうでしょうか。
それではここから、SQLの書き方について詳しく学んでいきましょう。
よく使うSQLを覚えよう
ここからは、データベース内に以下のような2つのテーブルが存在していることを想定して、SQLの使い方について説明していきます。(ケーススタディの例の、テーブル名と列名を英語にしただけです)


なお、こちらのツール に実際にこの例と同じ内容のテーブルを作ってありますので、リンク先の画面右の欄にSQLを打ち込んで Run SQL という青いボタンをクリックすると、実際にSQLを実行してみることができます。
SELECT
まず、データの抽出を行う際に必ず必要となる命令がこの SELECT です。
最も原始的なSELECT文は以下のようなものになります。
SELECT id,title,text,date FROM post;
これを実行すると以下のような結果が得られます。
| id | title | text | date |
|---|---|---|---|
| 1 | はじめまして | これから毎日投稿します! | 2023-01-01 |
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
SELECT 取得したい列名をカンマ区切りで並べる FROM テーブル名 ;
という構文です。
ちなみに、 すべての列を取得したい場合 は、 id,title,text,date のようにすべてを列挙する代わりに * と省略することもできます。
-- この例では以下の2つは全く同じ意味
SELECT id,title,text,date FROM post;
SELECT * FROM post;
WHERE
先ほどの例では、テーブル内のすべてのデータが取得されましたが、条件を指定してそれに合致するデータだけを抽出したいということが多々あるでしょう。
そんなときに使うのが WHERE です。
例を挙げてみましょう。
-- idが2のデータだけを抽出
SELECT * FROM post WHERE id = 2;
このSQLを実行すると、以下のような結果が得られます。
| id | title | text | date |
|---|---|---|---|
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
基本のSELECT文の末尾に WHERE 条件 を追加すればいいわけですね。
条件の指定方法
条件を指定するための演算子はかなり色々あるのですが、ここでは特によく使うものだけをピックアップして紹介します。
単純な比較
| 演算子 | 意味 | 使い方の例 | 例の意味 |
|---|---|---|---|
= |
等しい | WHERE id = 2 |
idが2である |
!= |
異なる(≠) | WHERE id != 2 |
idが2でない |
> |
左辺が右辺より大きい | WHERE id > 2 |
idが2より大きい |
>= |
左辺が右辺以上の大きさ(≧) | WHERE id >= 2 |
idが2以上 |
< |
左辺が右辺より小さい | WHERE id < 2 |
idが2より小さい |
<= |
左辺が右辺以下の大きさ(≦) | WHERE id <= 2 |
idが2以下 |
文字列の部分一致
| 演算子 | 意味 | 使い方の例 | 例の意味 |
|---|---|---|---|
LIKE |
左辺が右辺の文字列と部分一致する | WHERE text LIKE '%!%' |
textが ! を含む |
WHERE title 'こん%' |
titleが こん で始まる |
||
WHERE title '%なら' |
titleが なら で終わる |
%がワイルドカードで、そこにどんな文字列が入ってもマッチする、という考え方です。
配列に含まれる
| 演算子 | 意味 | 使い方の例 | 例の意味 |
|---|---|---|---|
IN |
左辺の値が右辺の配列に含まれる | WHERE id IN (1,3) |
idが1または3である |
条件の否定
| 演算子 | 意味 | 使い方の例 | 例の意味 |
|---|---|---|---|
NOT |
直後の演算子または条件を否定する | WHERE id NOT IN (1,3) |
idが「1または3」ではない |
WHERE title NOT LIKE 'こん%' |
textが こん で始まらない |
||
WHERE NOT id >= 2 |
idが「2以上」ではない |
複数条件の結合
| 演算子 | 意味 | 使い方の例 | 例の意味 |
|---|---|---|---|
AND |
2つの条件を「かつ」で結合する | WHERE id > 1 AND title LIKE '%なら' |
idが1より大きく、かつ、titleが なら で終わる |
WHERE id NOT IN (1,3) AND text LIKE '%!%' |
idが「1または3」でなく、かつ、textが ! を含む |
||
OR |
2つの条件を「または」で結合する | WHERE id > 1 OR title LIKE '%なら' |
idが1より大きいか、または、titleが なら で終わる |
WHERE id IN (1,3) OR text NOT LIKE '%!%' |
idが「1または3」であるか、または、titleが ! を含まない |
||
() |
結合された条件のまとまりを明示する | WHERE text LIKE '%!%' AND (id > 1 OR title LIKE '%なら') |
textが ! を含み、かつ、「idが1より大きいか、または、titleが なら で終わる」 |
ORよりANDのほうが演算子としての優先度が高いため、ANDとORを複雑につなぎ合わせる場合、
()で適切にまとまりを明示しておかないと、意図と異なる意味の条件になってしまう恐れがあります。例えば、「
条件AAND条件BOR条件C」は、「AかつB」またはCという意味ですが、「条件AAND (条件BOR条件C)」 は、Aかつ「BまたはC」という意味で、それぞれ異なる条件を表します。
JOIN
さて、次はちょっと発展編です。SQLでデータを抽出する方法を学ぶ上でもっとも重要なポイントになります💪
ここまで見てきた例では、いずれも1つのテーブルだけからデータを抽出していました。
しかし、例えば 「『投稿日が 2023-03-01 以降の記事』に付いているコメントの本文を一覧で欲しい」 という場合、 comment テーブルに対するSELECT文にどんなWHEREを記述しても、所望のデータを取得することはできません。なぜなら、 comment テーブルには、「そのコメントの親である記事の『投稿日』の情報」は載っていないからです。
そもそもデータベースの世界では、 各テーブル内にデータの重複がなくなるように「わざわざ」テーブルを細かく分けている わけですから、データを抽出する際に複数のテーブルを結合したくなる場面が当然にあるのです。
こういう場合に使うのが、 JOIN という命令です。
先ほど例に挙げた「『投稿日が 2023-03-01 以降の記事』に付いているコメントの本文の一覧」を抽出するSQLは、以下のようになります。
SELECT
comment.text
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
post.date >= '2023-03-01'
;
※ SQLの言語仕様では、スペースと改行はともに文法上の意味を持たないため、長いSQLを書くときは適切に改行やスペースを入れて見やすく整形することがあります。
複雑に見えますが、そんなに難しいことはしていません。ポイントは以下の部分です。
FROM
post JOIN comment ON post.id = comment.post_id
FROM の対象が今までのように単一のテーブルではなく post JOIN comment ON post.id = comment.post_id という「何か」になっています。
この「何か」の正体は、 post テーブルと comment テーブルを結合して作った1つの大きなテーブル です。
この部分の意味を紐解くと、以下のようになっています。
-
postとcommentを結合(JOIN)する - 結合の条件は
ON post.id = comment.post_idとする- つまり、
postテーブルのid列の値と、commentテーブルのpost_id列の値が等しい行を結合する
- つまり、
少しややこしいので実物のイメージを見てみましょう。
元となる以下のような2つのテーブルを、
結合することで、以下のような大きな1つのテーブルを作っているのです。
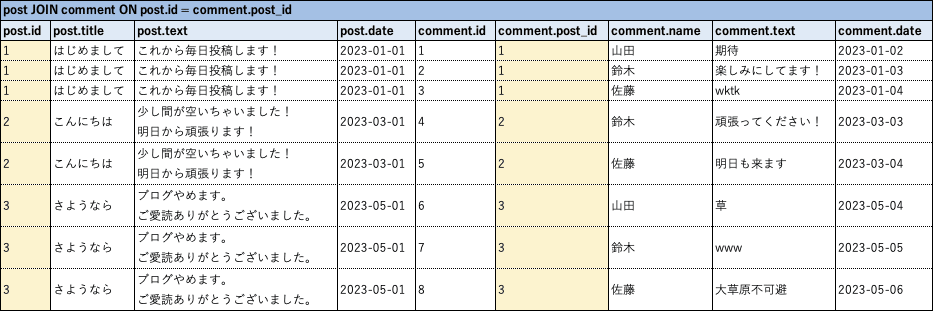
黄色く塗った列の値が、各行で一致していることが分かると思います。これは、 ON post.id = comment.post_id という条件で結合した結果です。
元々 comment テーブルには「このコメントがどの投稿に対するものか」が分かるように post_id という列が用意されていました。これを結合条件に利用したわけです💡
データベースにテーブルを作る際には、ここでいう
commentテーブルのpost_id列のように、後で関連するテーブルと結合するときのために、関係性を保持しておくための列を予め用意しておくのがセオリーなので、皆さんがSQLを使ってデータを集計するときにはこのような列が必ず用意されているという前提で考えてもらって大丈夫です👌
では、ここまでを理解した上で元のSQLを改めて見てみましょう。
SELECT
comment.text
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
post.date >= '2023-03-01'
;
結合後のテーブルに対して、 WHERE post.date >= "2023-03-01" という条件で絞り込んだ結果のうち、 comment.text 列だけを出力する、という内容になっていることが理解できるかと思います。
ところで、SELECTで取得する列やWHEREの条件に使用する列を指定する際、今までは SELECT id,title,text,date や WHERE id = 2 のように、 列名だけ を書いていましたが、今回は SELECT comment.text WHERE post.date >= '2023-03-01' のように、 テーブル名.列名 という形式で指定しています。
この理由は簡単で、例えば SElECT text とだけ書いた場合、 post テーブルの text なのか comment テーブルの text なのか分からないからです。
単一のテーブルからSELECTする場合は列名だけでいいけど、テーブルを結合した場合は常に テーブル名.列名 と指定する必要がある ということを覚えておいてください👌
これで、一番の山場である JOIN をクリアしました🙌
AS
唐突ですが、先ほどの例に手を加えて、コメントの本文だけでなく記事の本文も出力するようにしてみましょう。
SELECT
post.text, comment.text
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
post.date >= '2023-03-01'
;
このSQLを実行すると、以下のような結果が得られます。
| text | text |
|---|---|
| 少し間が空いちゃいました! 明日から頑張ります! |
頑張ってください! |
| 少し間が空いちゃいました! 明日から頑張ります! |
明日も来ます |
| ブログやめます。 ご愛読ありがとうございました。 |
草 |
| ブログやめます。 ご愛読ありがとうございました。 |
www |
| ブログやめます。 ご愛読ありがとうございました。 |
大草原不可避 |
結果として得られたテーブルの列名に、元のテーブル名が含まれていないため、どちらも text という列名で出力されてしまって、このままだとどっちがどっちか分からないですね🙄
このような場合に役立つのが AS という命令です。これは、SELECTで取得する列名に 別名 を付けるための命令です。以下のように使います。
SELECT
post.text AS '記事本文',
comment.text AS 'コメント本文'
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
post.date >= '2023-03-01'
;
| 記事本文 | コメント本文 |
|---|---|
| 少し間が空いちゃいました! 明日から頑張ります! |
頑張ってください! |
| 少し間が空いちゃいました! 明日から頑張ります! |
明日も来ます |
| ブログやめます。 ご愛読ありがとうございました。 |
草 |
| ブログやめます。 ご愛読ありがとうございました。 |
www |
| ブログやめます。 ご愛読ありがとうございました。 |
大草原不可避 |
分かりやすいですね!
JOINを使った場合に限らずいつでも使えるので、覚えておきましょう👌
SELECT id, text AS '本文' FROM post;
| id | 本文 |
|---|---|
| 1 | これから毎日投稿します! |
| 2 | 少し間が空いちゃいました! 明日から頑張ります! |
| 3 | ブログやめます。 ご愛読ありがとうございました。 |
ORDER BY
WHERE で条件による絞り込みを行いましたが、集計・分析において絞り込みに次いで頻繁に使うのが 並べ替え でしょう。
SQLでは、 ORDER BY という命令を使ってデータの並べ替えを行います。
例えば、投稿一覧を id の降順 で取得するSQLは以下のようになります。
SELECT * FROM post ORDER BY id DESC;
| id | title | text | date |
|---|---|---|---|
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
| 1 | はじめまして | これから毎日投稿します! | 2023-01-01 |
文法は、 ORDER BY 列の指定 昇順/降順の指定 です。
昇順/降順の指定 には、昇順の場合は ASC 、降順の場合は DESC を入れます。( ASC は「昇順」を表す英単語 ascending の略語、 DESC は「降順」を表す英単語 descending の略語)
ORDER BY は WHERE よりも後ろに書かなければならない決まり なので、その点だけ要注意です。
| SQL | 結果 |
|---|---|
SELECT * FROM post WHERE id > 1 ORDER BY id DESC; |
正常に実行可能 |
SELECT * FROM post ORDER BY id DESC WHERE id > 1; |
エラー |
GROUP BY
次は少しだけ難解かもしれませんが、ある程度複雑な集計をしようとすると必要になってくる GROUP BY という命令です。
例えば、 「2023-03-01以降にコメントが付いた記事の一覧」 が欲しいとします。
この場合、素直にSQLを書くと以下のようになるでしょう。
SELECT
post.*
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
comment.date >= '2023-03-01'
;
これを実行するとどんな結果が返ってくるでしょうか?
正解は以下です。
| id | title | text | date |
|---|---|---|---|
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
条件で絞り込んだ結果の「記事の一覧」が欲しかったのに、同じ記事がいくつか重複して出力されていました。なぜでしょうか?🤔
思い出してみましょう。 JOIN を使って結合されたテーブルは、下図のような形をしていました。

この大きなテーブルに対して WHERE comment.date >= '2023-03-01' という条件で絞り込んで(下図の黄色い部分)、post.* を出力したわけですから、取得されるデータは下図の赤い部分になります。

確かに上記の結果と一致していますね。
理屈は分かりましたが、重複を削除して純粋な「条件に合致する記事の一覧」を取得する方法はないのでしょうか?
あります。それが GROUP BY です👍
この例では、以下のように GROUP BY を追記することで、重複を削除した一覧を取得することができます。
SELECT
post.*
FROM
post JOIN comment ON post.id = comment.post_id
WHERE
comment.date >= '2023-03-01'
-- 以下を追記
GROUP BY post.id
;
| id | title | text | date |
|---|---|---|---|
| 2 | こんにちは | 少し間が空いちゃいました! 明日から頑張ります! |
2023-03-01 |
| 3 | さようなら | ブログやめます。 ご愛読ありがとうございました。 |
2023-05-01 |
文法は GROUP BY 列名 です。
こうすることにより、 列名 に指定した列の値が同一である行をグルーピングして、1行として出力してくれます。
なお、 ORDER BY と同様、GROUP BY も WHERE より前に書くことはできないので、要注意です。
LIMIT
LIMIT は、取得する結果の上限数を指定するための命令です。以下のようにして使います。
SELECT * FROM comment LIMIT 3;
| id | post_id | name | text | date |
|---|---|---|---|---|
| 1 | 1 | 山田 | 期待 | 2023-01-02 |
| 2 | 1 | 鈴木 | 楽しみにしてます! | 2023-01-03 |
| 3 | 1 | 佐藤 | wktk | 2023-01-04 |
本当は全部で8件あるのに、最初の3件しか出力されていません。
実際の集計時にはあまり使わないかもしれませんが、欲しい結果を得るためのSQLを試行錯誤しながら書いているときにはとてもよく使う命令です。
例えば、全部で数千万行もあるような巨大なテーブルからデータを取り出すためのSQLを、実際に実行しながら試行錯誤して書くことを想像してください。
無造作に SELECT * FROM user; などと入力してしまったら、データベースソフトはテーブルから数千万行を取得して画面に出力しようとします。これはデータベースサーバーに無意味に大きな負荷をかけてしまう上に、結果が表示されるまでに数十秒から数分ぐらいは待たされることになるでしょう。(サーバーのスペック次第ですが)
しかし、SElECT * FROM user LIMIT 10; を実行すると、例え user テーブルに全部で数千万行のデータが格納されていたとしても、最初の10行を見つけた時点で処理は終了するため、サーバーの負荷も少なく、待ち時間も短くて済みます。
「このSQLで意図どおりの結果が出てくるかな?」というのを確認するためにSQLを実行するような場合は、常に LIMIT 10 など上限を設定して実行する癖をつけておくとよいでしょう。
関数
ここまで、SELECT文の代表的な構文を学んできました。
これらを駆使すれば、データベースからお好みの情報を切り出して一覧化することができるでしょう。
ところで、SQLには、SELECT文で取得した一覧に対してさらに何らかの加工を行う命令も用意されています。
このような命令のことを 関数 といいます。
例えば、MySQLの DATE_FORMAT() という「日付の表示形式を指定する関数」 を使うと、以下のようなことができます。
SELECT
id,
DATE_FORMAT(date, '%Y/%m/%d')
FROM post;
| id | DATE_FORMAT(date, '%Y/%m/%d') |
|---|---|
| 1 | 2023/01/01 |
| 2 | 2023/03/01 |
| 3 | 2023/05/01 |
ここでは、集計において特に頻繁に使うであろう代表的な関数をいくつか紹介します。
MySQLには実に様々な関数が用意されています。興味があれば覗いてみてください😇
なお、最初に「この記事で扱う内容のレベルならほとんど方言による差異はありません」と書きましたが、データベースソフトによる違いが最も大きいのが、用意されている関数の種類や名称です。
これから紹介するような基本的な関数ならどのデータベースソフトでもほとんど同じ仕様で用意されていますが、例えば上記の DATE_FORMAT() 関数などは実はMySQL特有の関数で、他のデータベースソフトでは名称や仕様が異なっています。
このような場合は、postgresql date_format や microsoft access date_format などと検索してみれば、「目的のデータベースソフトには DATE_FORMAT() 相当の関数はあるのか、あるならどのような名称・仕様なのか」が簡単に調べられるかと思います👍
ちなみに、PostgreSQLでは TO_CHAR()、Microsoft Accessでは Format() がそれぞれMySQLの DATE_FORMAT() の代替となる関数です。
COUNT()
データの一覧を取得するのではなく、 データの個数だけを知りたい という場合に役立つのが COUNT() 関数です。
以下のように、特定の列名を COUNT() で囲う形で使用します。
-- 投稿日が2023-03-01以降である記事の数
SELECT COUNT(id) FROM post WHERE date >= '2023-03-01';
| COUNT(id) |
|---|
| 2 |
COUNT() を外すと(当たり前ですが)内訳が分かります。
-- 投稿日が2023-03-01以降である記事の一覧
SELECT id FROM post WHERE date >= '2023-03-01';
| id |
|---|
| 2 |
| 3 |
SUM()
COUNT に次いで頻繁に使う関数に SUM() があります。 COUNT() は取得したデータの個数を出力する関数でしたが、 SUM() は取得したデータの合計値を出力する関数です。
COUNT の例で書いたSQLの COUNT の部分を SUM に置き換えてみると、以下のような結果が得られます。
SELECT SUM(id) FROM post WHERE date >= '2023-03-01';
| SUM(id) |
|---|
| 5 |
取得した一覧の id の値である 2 と 3 を合計して 5 が出力されていますね。
この例のように id を合計したいというケースは実際にはほとんどないと思いますが、例えば 値段 や 得点数 など、集計時に列の値を合計したくなることは割とよくあります。
AVG()
合計が出せるなら平均も出したいのが人情ですね。平均値を出力する関数は AVG() です。( average の略)
SELECT AVG(id) FROM post WHERE date >= '2023-03-01';
| AVG(id) |
|---|
| 2.5000 |
まとめ
データベースの概念とSQLの具体的な使い方について、ケーススタディーを通して学んできました。
最初に掲げたこの記事のゴールは
- データベースという概念をなんとなく理解すること
- 簡単なSQLを自力で書けるようになること
でした。ここまで読んでくださった皆さんはきっとこのゴールを達成されていることと思います。
もし分かりにくかったところや難しかったところなどあれば、Twitter でフィードバックをいただければ、手直しや続編の執筆など検討させていただきます!
それでは、よきSQLライフを✨
Discussion