生成AI・ChatGPTに支配される前に、押さえるべきAI事情(3章: AI技術関連史)
章立て
- はじめに
-
AI研究の全体像
2.1. AIが担うタスク
2.2. AIと従来プログラムの違い
2.3. AI技術のカテゴリ・分類
2.4. AI研究の視点 - AI技術関連史
3.1. ~ 1957年ごろ:「AI」誕生
3.2. 1957~1980年ごろ: Logic-based AI
3.3. 1980~1993年ごろ:Knowledge-based AI
3.4. 1993~2012年ごろ:Machine Learning
3.5. 2013年ごろ以降 :Deep Learning -
今後のAI技術について
4.1. AI倫理(AI Ethics)
4.2. マルチモーダル化
4.3. ハードウェアの進化
4.4. AI開発の自動化・自律化 - おわりに
本記事に記載の第3章以外の内容は下記のリンクをご参照ください
3. AI技術関連史
本章では、AI技術がどのように発展したかを追う。中でも前章のAI技術分類と同様に、大きな潮流であるSymbolic AIとConnectionist AIを中心に述べる。

AI技術関連史
3.1. ~ 1957年ごろ:「AI」誕生
17世紀に活躍したドイツの学者Gottfried Wilhelm Leibnizは、安全・時間浪費の観点から計算は人間ではなく機械がするべきであるという考え方を持っており、Pascalの計算機をもとにして、長さの異なる歯をもつシリンダーと移動式の歯車を組み合わせて計算(基本的には自然数の四則演算)を可能にしたStepped reckonerまたはLeibniz Wheel(ライプニッツの車輪)と呼ばれる手動機械式の計算機を、1694年に完成させた[1] [2]。これをきっかけにLeibnizは、数学的記述(mathmatical statement、詳細は以下のnoteを参照)の真理値を決定できる機械を作ることができるのではないかと考えるようになった。それが実現できると、機械が論理を扱うことができるようになるため、どういう場合には何をするといった場合分け処理や、明確な理由がある推論といった[3]、より知的な処理が可能になる。そして、機械が論理を扱うためには、人間が自然に行っているコミュニケーションのような、曖昧さが残る表現やその時によって用法・意味が変わるような自然言語(natual langage)ではなく、文法・意味が形式的に与えられて明確に論理が展開できる形式言語(formal language)が必要であると考えられ、Leibnizの研究は形式言語を用いた形式理論(formal theory)にも重きが置かれるようになっていった。さらに、Leibnizは活動の中で、現代のコンピュータの基礎となっている2進数演算(binary arithmetics)や[4]、2進数コンピュータ(binary computer)についても功績を残している[5]。
note
数学的記述(mathmatical statement)は、正しい(真)か間違っている(偽)かが判断できる「文」であり、言葉や記号(symbol)が含まれる。例えば、言葉を使った「1は2よりも大きい」や、記号を使った「1>2」という文は、「偽」であるmathmatical statementである。
Leibnizの論文がドイツのHannoverで閲覧可能になった1830年代以降、その注目度は急速に高まり、Johann Eduard ErdmannやKurt Gödelなど後の研究に多大な影響を与える[6] [7]。この頃、数学界では数学理論を構築するための演繹的な方法(すでに知られている法則(一般論・ルール)や前提から、階段を登っていくように論理を積み重ねて結論を出す考え方[8])に注目が集まっており、数学における形式理論(公理理論とも呼ばれる)に関する新しい問題が提起されていた[9]。1928年、ドイツの数学者であるDavid HilbertとWilhelm Ackermannは、Entscheidungsproblem(ドイツ語。日訳で決定問題、英訳でdecision problem)と呼ばれる、「(一階論理の)すべての数学的記述は、導出可能か」(すべての公理を考慮すれば、命題が証明可能かどうかを判断できるアルゴリズムが存在するかどうか)という問題を提起した[10]。この問題は、「人間の思考プロセスをすべて単純なアルゴリズムで表現することは可能か」と言い換えることができ[11]、もしそのようなことが可能であれば、単純なアルゴリズムだけでも実行可能な機械があれば、人間の思考活動を全てそれで再現できるということになる。
note
数学者や数学団体は自身が発案・直面した未解決問題を公開し、研究を生み出してきた。1900年にHilbertが、パリで開催された国際数学者会議(International Congress of Mathematicians: ICM)および彼の著作で、次の世紀に研究されるべき23の主要な数学的問題が発表された[12] [13] [14]。EntscheidungsproblemはHilbertの23の問題のうち、Diophantine方程式に解があるかどうかを決定するアルゴリズムを求める第10問題に関連している。
1935年、HilbertのEntscheidungsproblemに興味を持ったAlan Turingは、任意の数学的記述の導出に必要な「形式化された手順」が必要である、として研究を開始した。すなわち、どんな数学的記述も導出できる手順が存在するということは、どんな数学的記述も証明可能であると言える、という考え方である。Turingは翌1936年に発表した論文[15]で、そういう手順が可能である仮想的な機械(UTM: Universal Turing machine[16])を考案し、Entscheidungsproblemが成り立たたないことを証明した[17] [11:1] [18] [19]。したがって、例えば数学の定理を証明したい場合、どんな定理の証明も可能なアルゴリズム的な手法は存在せず、総当たり(Brute force)的に証明を試さなければならないということが示されたことになる[20](この際の、Turingのアプローチで独創的だったのは、UTMを考案するにあたり、それまで発明されていた「機械」に注目するのではなく、子供が勉強で使う方眼紙や何か手順を踏むときの人間の思考など、「人間」に注目した上で、実行する手順を徹底的に曖昧さがない論理的な処理に落とし込んだことである[21])。
UTMの論理性は、1943年に発表された、神経生理学者Warren McCullochと数学者Walter Pittsによるニューロンの数学モデル(MPニューロン、MCPニューロンと呼ばれる)およびそれにより構成されるニューラルネットワークモデルの考案のためのインスピレーションをもたらし[22] [23]、UTMの構成は、Machineへの命令を入力データと同じ記憶領域に配置するstored-program方式と呼ばれ、1945年にアメリカの学者John von Neumannにより発表されたコンピュータの構成(ノイマン型アーキテクチャ、von Neumann model、Princeton architectureなどと呼ばれる)にも強い影響を与えるなど[24] [25] [16:1]、UTMは大きな技術的発展をもたらした。
ノイマン型アーキテクチャが発表された1945年末には、世界初の「プログラム可能な(命令の与え方によって様々なタスクをこなすことができる)」計算機であるENIAC(Electronic Numerical Integrator and Computer)[26] [27]、1948年には世界で初めてノイマン型アーキテクチャで動作するManchester Baby(SSEM: Small-Scale Experimental Machineとも呼ばれる)など[28] [29]、続々と電子計算機(以降、コンピュータ)が高性能化していった。
note
Turing machineは論文の中ではcomputing machineと呼ばれている[15:1]。
Universal Turing Machine(引用:[30])

さらに1951年には、Marvin MinskyとDean Edmondsが、SNARC(Stochastic Neural Analog Reinforcement Calculator)という世界で初めて人工ニューラルネットワーク(ANN: Artificial Neural Network)を実装したコンピュータを構築している。SNARCのニューラルネットワークは、MPニューロンの考え方を拡張したHebb理論に基づいており、学習することができるようになっている。
Hebb理論は、1949年にカナダの心理学者Donald Olding Hebの著書で提唱された[31]、ニューロンの数学モデルの学習ルールとそのアルゴリズムを含む理論である。Hebbは、つながっている2つのニューロンが同時に発火すればするほど、それらの接続強度(以降、重み)は強くなるという規則を主張した(これは、後に長期記憶の理論にも影響した)[32]。この規則に基づいて重みを調整すれば、ロジックが変えられる、すなわち所望のロジックを得るために重みを調整すれば、機械が改善されることになるため「学習」と呼ぶことができる(SNARCではHebb則に基づいて重みの更新を人の手で行っていた)[33]。
ただし、純粋な総当たり処理をすべてのタスクに対して行う計算はこの頃のコンピュータの性能では不可能であり[34]、特に探索や認識といった複雑なタスクに対しては、知性的に解を求める方法が求められていたと考えられる。さらに1949年、アメリカのコンピュータ科学者Edmund Berkeleyが著書Giant Brains, or Machines That Thinkで「A machine, therefore, can think.」と言及し[35] [36] [37]、1950年にTuringが発表した論文を「I PROPOSE to consider the question, ‘Can machines think?’」で始めるなど[38]、思考する機械への関心はさらに盛り上がりを見せていた。Turingはその論文でTuring Testという機械の知性を試験する方法を提案している[39](Turing Testについて詳細は割愛)。
1954年にRAND(Research ANd Development)Corporationで、JOHNNIAC(JOHn von Neumann Numerical Integrator and Automatic Computerの略でvon Neumannも開発に携わった)という計算機が構築され[40]、翌年にかけてコンピュータ科学者・認知心理学者のAllen Newellと政治・経済・社会学者のHerbert Simonを中心にLogic Theoristと呼ばれる、IPL(Information Processing Language)というプログラミング言語を用いたプログラムが作成された[41] [42] [43]。Logic Theoristは、人間の数学者の頭脳の能力を模倣するように、Symbolを組み合わせて表現に組み込む「symbolic reasoning」と呼ばれる推論に基づいており[44]、元になる数学定理のから新しい定理を証明することが可能である(しかもいくつかの数学定理は、人間の数学者よりも詳細な証明を示すことができた)[41:1]。このように、基にする要素(root)から論理規則に基づいて分岐しながら目的の要素を探索するアルゴリズムは、今日でも探索木(search tree)として知られており、Logic Theoristは、解ける保証がない問題に取り組むプログラムを作成した点が一つの大きな発明であると考えられる。また、Logic Theoristは実際の問題を解決するために人間の推論能力をシミュレートした世界初の人工知能プログラムと称され[45]、Symbolを用いて人間の思考プロセスをプログラム化するいう思想に基づいたこのような手法は後に、Symbolic AIに分類される[46]。Symbolic AIに対して、人間の脳をモデル化すれば人間と同じように知能をもたせることができるという思想に基づいて、ニューロンの数学モデルを用いてANNを構成する手法はConnectionist AIと呼ばれる[47]。
上記のように、この頃、「考える機械(thinking machine)」に関する取り組みが非常に活発だったと言えるが、Dartmouth大学の数学助教授だったJohn McCarthyがより明確にその研究領域を発展させるために[48]、DSRPAI(Dartmouth Summer Research Project on Artificial Intelligence、ダートマス会議)でRockefeller財団にセミナーのための資金提供を要請し、その研究領域を人工知能(Artificial Intelligence)と名付けた[49]。これが、AIという用語が使われた最初の文書であり[50]、これがAIという研究分野の誕生とされる(1956年にDSRPAIが開催され、Logic theoristはそこで発表された[51])。
3.2. 1957~1980年ごろ: Logic-based AI
本節以降では、AIのアルゴリズムや技術の変遷に注目するため発明者や関係者は割愛する場合がある。
1st AI boom
1958年、Connectionist AIの分野では、RosenblattによりPerceptronと呼ばれる単層のニューラルネットワークが発明された。Perceptronは、MPニューロンが0または1の2種類の値(ブール値)のみを扱うのに対して、ニューロンの入力に小数点以下を含んだ値を扱うようになり[52]、加えてHebb理論のように前節のSNARC同様に機械が学習する方法も考案された[53] [54] [55]。具体的には、ニューラルネットワークの予測出力と正解の出力(教師データ、Training Data)の差を、損失関数(Loss function、Cost function)を用いて損失(Loss、Cost、Error)として表し、損失を最小化するようにニューラルネットワークのパラメータを最適化する(Optimization)という流れで学習を行った。Rosenblattが用いた学習則(Learning Rule)は、Perceptron Learning Ruleなどと呼ばれる[56] [57] [58]。このように教師データを用いる学習方法は教師あり学習(Supervised Learning)と呼ばれ、これに対して教師データを用いないこの頃主流だった学習方法は教師なし学習(Unsupervised Learning)と呼ばれるようになっていく。
このように人間がルールを作らずに機械に学習能力を与える研究分野に対して、1959年にArthur SamuelがMachine Learning(機械学習)という言葉を提唱した[59]。Samuel自身も1952年にCheckersをプレイするプログラムを作成し[60](Alpha-beta pruningと呼ばれる方法で効率的に戦略を探索させた)、1955年にRot Learningと呼ばれる方式で勝者の戦略を学習可能とし[61]、1959年に当時のベストプレイヤーを打ち負かしている[62]。
この頃、Connectionist AIの発展に必要なことは柔軟で強力な学習ルールであるという認識がされており[63]、1960年にBernard WidrowとMarcian E. HoffによりPerceptronのブール値出力の前に線形関数を加えたモデルであるAdaline(Adaptive Linear Neuron)を[64]、Delta ruleまたはLMS(Least Mean Square) ruleと呼ばれる線形出力をもとに損失を算出し、GD(Gradient Descent、Batch Gradient Descent、勾配降下)法を用いて損失を最小化する学習則が発表された[65] [66] [67]。また、勾配を計算するためのポイントをランダムに選択するSGD(Stochastic Gradient Descent)法も同時期に提案され[68]、Optimizationという分野は損失を最小化する数学的アルゴリズム研究として発展していくことになる。また特にSGD法は今日でも広く用いられており、並列計算が可能なMinibatch GD法や、移動平均処理により損失の振動を抑えたMomentum法など[69]、多くの改善版を生み出す一般的なOptimizerとなっている[70]。またこれらは、1次の微分項のみを使うためFirst order methodと呼ばれる[71](Newton法などの高次の微分項を用いた、より高速に収束するOptimization手法も存在したが、計算コストがかかりすぎるため機械学習に用いられることは稀だった[70:1])。
note
ニューロンの数学モデルのことをPerceptronと呼ぶこともあり[72]、その場合、MPニューロンが最初のPerceptronとなる。

ニューロンモデルの変遷(一部引用:[54:1])

教師あり学習のコンセプト(一部引用:[73])
ただし、この時期のAI研究はSymbolic AIの分野がより大きな盛り上がりを見せていた。
様々な特定のタスクに対するAI(前節のLogic Theoristの場合、定理の証明というタスク)がメインだったが、1959年にAllen NewellとHerbert A. SimonによりGeneral Problem Solver(GPS)と呼ばれる、一般的なタスクに対応することを意図したAIが発明された[74]。GPSは、到達したい目標へ一足飛びにたどり着けない場合に、目標との差から中間目標を作って徐々に目標に近づくMeans End Analysis(MEA)と呼ばれる手法を導入しており、GPS以後、MEAはAIに広く利用された[75]。
note
GPSが注目されたものの、実際にはこの頃のAIは、論理や幾何学の定理の証明、Chessのような明確に定義された問題にのみ適用可能だったが、他の理論的研究の基礎になっている[76] 。
このようなAI研究の成功に加え、1961年に世界初のICチップが販売[77](これまでのコンピュータ(IBM704)がメモリ不足だった[78]というAI研究に対するボトルネックを克服するハードウェアの進化)、1965年のムーアの法則[79]、1962年にARPA(Advanced Research Projects Agency、高等研究計画局)にIPTO(Information Processing Techniques Office、情報処理技術局)の設立と[80]、それによるマサチューセッツ工科大学(MIT)、スタンフォード大学(SAIL(Stanford Artificial Intelligence Laboratory)、Stanford HPP(Heuristics Programming Project)等)、カーネギーメロン大学をはじめとするAI研究への投資などにより、AI研究の規模が根本的に変わり、小規模なプロジェクトの集まりから大規模で注目度の高い分野へと推進された[81]。
1965年にはHPPでDENDRAL(DENDRitic ALgorithm)と呼ばれる、化学者が未知の有機分子を特定できるように分子のスペクトル分析を行い構造を示すAIの開発が開始された[82]。SAILのコンピュータPDP-6で作成されたプログラムであり、分子を構成する原子の情報や、探索の優先度など化学者の知識をあらかじめ組み込み、それらを利用して質量分析を行うことができる[83] [84](DENDRALの構成等についてはこちらもご参照)。DENDRALはルールベースで(ゲーム等ではない)現実の問題のために作られたプログラムであり[85]、この後も開発が継続される。
また、1966年にはMITのMAC time-sharingシステム上でELIZAという自然言語処理のAIプログラムが開発された[86]。GUIを持ち、ユーザーの入力からキーワードやフレーズを認識して事前にプログラムされたフレーズからユーザーへの応答を行うため、世界初のChatbotと称されている[87]。プログラム内では、If-thenルールを用いた、単純なパターンマッチングを行っており、膨大な数の会話パターンを事前に用意しておかなければならなかったが[88]、Rogerian療法のセラピストとして応対するバージョン(DOCTOR)で有名になった[89] [90]。
その他、自らの行動を推論できる初の汎用移動ロボットであるShakey the robotや[91]、世界初のPlannningシステムであるSTRIPS(STanford Research Institute Problem Solver)等も[92] [93]、この頃のAIの例として挙げられるが、詳細は割愛する。
note
AIの研究としてではないが、下記の研究も後に重要となる。
1963年、James MorganとJohn Sonquistにより、学歴と年収などのデータの関係性をを分析(回帰分析)するために、数値的な基準を設けてデータを2つに分けることを繰り返してグループ分けを行う、後にAID(Automatic Interaction Detection)と呼ばれる手法が発表された[94] [95]。そして、1972年にはそれをカテゴリ分類へ拡張させたTHAID(THeta Automatic Interaction Detection)と呼ばれる手法も発表された。これらのようにデータを木の枝状に分割していく分析手法は回帰木(Regression Tree)および分類木(Classification Tree)、またはそれらをまとめてCART(Classification And Regression Tree)と称され、今日でも発展を続けている。
1st AI Winter
前節のような盛り上がりを見せたAI研究も、1960年代後半ごろから冬の時代が訪れた。
Rosenblattに発明されたPerceptronは2種類かつ比較的単純な分類タスク(厳密には、線形分離可能なタスク)にしか対応できないことがわかり[96]、1969年に出版されたPerceptrons: an introduction to computational geometryという書籍で単純な論理XOR関数を学習できないことを示されるなど[97]、非常に厳しい目を向けられることとなった。またこの頃の多くの研究者が、1965年頃から使われだした強化学習(Try and Errorで学習していく方法)に取り組んでいるつもりが、教師あり学習になってしまうケースが多発するなどの混乱もあり、学習アルゴリズムにフォーカスした研究が多くなかった[98]。John AndreaeがSTeLLA(Standard Telecommunication Laboratories[99])という環境から強化学習システムを発明しても注目度が上がらない[100]、次元の呪いの提唱など[101]、Connectionist AIや機械学習の分野は下火になっていた。
そして、1969年のマンスフィールド修正案により、ARPAの後身となるDARPA(Defense Advanced Research Projects Agency)の投資対象について、基礎研究ではなく具体的な目的をもった研究を重視するように大きく変更された[102]。それに加え、1973年にScience Research Council(イギリスの科学研究評議会)に向けてAI研究の評価を行ったLighthill reportで、航空機の自動着陸システムがAIよりも従来手法の方が優れていること、AIプログラムの作りこみが難しいこと、組み合わせ爆発問題が起こること等に注目し、AI研究に対して悲観的な見解を示した[103] [104] [105]。
このような流れもあって資金の確保が難しくなり、AI研究の勢いは次第に失速した。AIへの期待は、人間の脳のような柔軟性や汎用性をもってほしいという究極の知性よりも、特定の分野であってもより現実的な問題の解決へと移っていった。
3.3. 1980~1993年ごろ:Knowledge-based AI
2nd AI boom
前述したDENDRALの研究は、対象とする化学構造の拡大を目指すDendral Project、化学的知識活用の向上を目指すMetaDendral Project、さらなる一般化を目指すMycin Projectに分化するなどして継続されていた[106]。開発当初の検索ベースのアルゴリズムでは、専門家レベルの能力をもったAIとはいかなかったが、「プログラムが問題解決を行うためには(従来重視されていた推論方法よりも)知識が重要である[107]」という考え方に基づいており、これはKnowledge-is-power仮説(後のKnowledge principle)と呼ばれ[108]、この後のAI研究に影響を与えている。このようなAI研究において、専門知識を持つ人間がExpertと称されたことから[109]、このような知識と問題解決方法が分けられた構造を持ちそれぞれ別の開発者(専門知識を持つ人、プログラムを作成する人)が担当できるプログラムをExpert System(またはKnowledge based System)[110]、知識を体系化する取り組みはKnowledge Engineeringと呼ばれるようになった[108:1]。このような構造をとることにより、プログラマーが必ずしも専門知識を習得したり、専門知識を持つ人がプログラミングを習得する必要がなくなったことが大きな功績の一つといえる[111]。
Block diagram of Expert System(引用:[112])

一方、この頃ICも着々と集積化を進める。1960年代前半にSSI(Small-Scale Integration)レベル、1960年代後半にMSI(Medium-Scale Integration)レベル、1970年代中盤にはLSI(Large-Scale Integration)レベルへ、そして1971年に初のマイクロプロセッサ(Central Processing Unit: CPUと呼ばれる)Intel 4004が発明されるなど、ムーアの法則通り集積度を上げ、コンピュータの小型化と計算能力向上が順調に進んだ[113] [114](各レベル詳細は割愛)。それによりMinicomputer(MC)と呼ばれる中規模のコンピュータ(現在の「サーバー」規模のコンピュータ)が市場に出始めることとなった[115]。Minicomputerは企業で大量に購入され、それによりドキュメントが増加、それらを整理・参照するツールの需要が高まった[116]。
このような状況の中、1978年にCMUの研究者が、MiniconputerのベンダーであるDECのコンピュータ構成業務をアシストするためのXCON(eXpert CONfigurator)と呼ばれるシステムを開発した[117]。1982年に導入後、年に4000万ドルのコストダウンがされたとされ、AIが産業界で本格的に用いられる例となった[118] [119]。
AIに取り組む研究者の関心がExpert Systemに向いているこの頃、さらに複雑なタスクに対応するため、これまでの常識であったSymbolを用いた決定論的アプローチだけでなく、不確実性・数値を用いた確率的アプローチも注目されるようになってきた[120] [121]。初期の例は、Certainty factorを用いたMYCIN(1975年)[122]、Bayesの定理を用いたPROSPECTOR(1978年)[123]、Fuzzy論理を用いたCADIAG-2(1980年)[124]などが挙げられ、実用的かつ知的レベルの高いAIを目指した取り組みが盛んに行われた。
このようなExpert Systemの発展に伴い、IBMを追い越そうと日本の通商産業省所管の新世代コンピュータ技術開発機構(ICOT:Institute for New Generation Computer Technology)で、国家プロジェクトとして第五世代コンピュータ(FGCS:the Fifth Generation Computer Systems)プロジェクトを推進し[125]、1982年ごろから4億ドルを超える大規模な投資を行った[126]。これに伴い、米国DARPAがSCI(Strategic Computing Initiative)を開始、英国ではAlveyプロジェクトが発足する等、FGCSは海外にも大きな影響を与えた[127]。
AI研究では、1984年に CART: Classification and Regression Trees. という論文が発表されて以降、CARTを含んだ樹形図を用いてデータを分析するための機械学習アルゴリズムである決定木(Decision Tree、樹形図自体を決定木と呼ぶ場合もある)に関する研究が活発になった[128]。1986年には、Expert Systemが推論を行うためのルール生成のために機械学習が重要であるとし田植えで、ID3(Iterative Dichotomiser 3)と呼ばれる決定木が開発された[129]。これまでのCARTが各ノードが2種類の分類を行う木(Binary Tree)を想定していたところを、複数種類に分類できる木(Binary Treeに対してGeneral Tree)に対応するなど[130]、ID3は決定木における大きなブレイクスルーとなっている[131]。
このようにSymbolic AIの分野でExpert Systemが大きな盛り上がりを見せる一方で、Connectionist AIの分野でも大きな進歩があった。
Perceptronを持ちいた階層型のニューラルネットワーク構造を用いたAIは、1979年にNeocognitronと呼ばれるニューラルネットワークが考案され、手書き文字の認識を成功させたことで、AIによる画像のパターン認識が可能であることを示した[132]。Neocognitronは、スライディングウインドウ処理を用いて、画像の中の位置に関わらずパターンを検出することのできる構造であり[133] [134]、後のCNN(Convolution Neural Network、畳み込みニューラルネットワーク)に非常に大きな影響を与えることとなる。
また、ニューロンが相互接続する構造のニューラルネットワークもこの頃発明される。1982年のHopfield networkは、強磁性体による磁場の説明に用いられるIsingモデルに基づいて考案されたニューラルネットワークで[135]、0または1を出力するニューロンが相互に接続されており、パターンを記憶してその情報を利用することができるようになっている[136]。実際には計算効率が悪く非現実的であったが、後のRNN(Recurrent Neural Network)に大きなインスピレーションを与えた[137]。また1985年には、ニューロンの出力を確率的にした制限付きボルツマンマシンが発明されている[138]。
そして教師あり学習の方法について、1986年にDavid Rumelhart、Geoffrey Hinton、Ronald Williamsの論文[139]で発表されたBP(Backpropagation、誤差逆伝搬)法が有効であることが示された。BP法により、教師あり学習において教師データとニューラルネットワークの出力の誤差を、逆伝搬させてネットワークが持つパラメータを調整する(誤差が大きいほどパラメータを大きく調整する)ことができ[140]、広く使われるようになった(BP法の基本コンセプトが発明されたのは厳密には1961年とされるが詳細は割愛)[141]。
同1986年、NETTalkという文字から音素(音の最小単位)への変換が可能なニューラルネットワークが発表された。後の一般的なニューラルネットワークのように入力層-隠れ層-出力層という3層の構造を持ち[142]、学習則にはBP法とSGDが用いられ[143]、英語のテキストを読み上げることが可能であることを示した。同様のタスクにExpert Systemで取り組み(読み上げ精度は高いものの)数年間かかったDECtalkと比べて、ニューラルネットワークを用いたモデルは開発期間が短いことを示した[144]。
1989年に発表された論文内での分類用の弱い学習ツール(weak learner)を変換して強力な学習ツール(strong learner)にもできるかどうかという議論から[145] [146]、1990年に同一タスクに対して複数のニューラルネットワークで学習および推定を行い、最終的な出力値を決定するアンサンブル学習(Ensemble Learning)という手法により、ニューラルネットワークの汎化パフォーマンスを向上できることが示され[147] [148]、これ以降の機械学習研究の中心にアンサンブル学習も存在することとなった[149]。
2nd AI Winter
1980年以降に期待されたExpert Systemは、実は1984年にAIの先駆者であるJohn McCarthyに批判されている。主な批判内容は、Expert Systemのプログラム変更が容易でなく変化に対応しづらいこと、人が当たり前に持っている常識的な知識をAIが持っていないため意思決定が不適切になりうること、の2つである[150]。さらに、実際に専門家の知識をルール化することが非常に難しい場合が目立ってきた[151]。すなわち、Expert Systemは構造化されたデータとルール化可能な論理があって初めて可能であり、自然言語や画像等の(曖昧な)データを取り扱うことが困難だった[152]。1987年から1989年にかけてDARPAのISTO (Information Science and Technology Office)には、Expert Systemが非常に限定的な領域でしか成功していない、と結論付けられている[153]。
また、マイクロプロセッサが開発されてから個人で利用するPC(Personal Computer)が低コスト化していった[154]。それに伴い、1987年までにC言語等のコンパイル言語を扱うOSを搭載したAppleやIBMのPCが流通し、多くのExpert Systemが実行されていたLISPマシンのそれを上回ったにも関わらず、コンパイル言語にExpert Systemの開発にマッチしなかったとされている[151:1]。そして1980年代後半から、特に機械学習による教師あり学習の性能が注目されてきたが、教師データが十分にとれないことや[155]、BP法による学習に時間がかかる点が問題として認識され[156]、コンピュータの性能が制限となり始めた。
また最適化の問題点として、複雑な処理に対応しようとニューラルネットワークを多層にすればするほど、損失関数の勾配が指数関数的に0に近づきやすくなるためBP法での学習が困難になる(ニューラルネットワークの重みが更新されない)という問題(勾配消失問題)が1991年に提唱され[157] [158]、逆に無限大に発散してしまい学習が困難になる問題(勾配爆発問題)も1994年に提唱された[159] [160]。
そして、1987年にDARPAがAIに対する投資を中止[119:1]、1992年にFGCSが目標をほとんど達成することなく正式に終了するなど[161]、研究への投資も縮小した。このようなこともあり、研究者は学術界や企業からの排斥を恐れて、意図的にAIという用語の使用を避けはじめた(代わりに、機械学習、データ分析、Intelligent System、Big Data、Data scienceといった単語を利用した)[162]。
3.4. 1993~2012年ごろ:Machine Learning
前節で述べたExpert Systemが困難だった非構造化データ、非線形データを取り扱うため、機械学習技術(特にカギとなった技術は決定木、BP法である[163])がより注目され始める。ただし機械学習研究が盛り上がった初期は、信頼性のあるデータが少ないこと、ハードウェアリソースの限界もあり研究の再現性がとれないこと、出力の説明性が乏しいことなどから、比較的教師データが少なくても性能を発揮し、理論保障が可能な数学・統計的なアプローチが主流だった[164] [165] [166]。
例えば自然言語処理(NLP: Natural Language Processing)のタスクに対しては、1990年代にN-gram言語モデルと呼ばれる、文章内で次にどの単語がくるかの確率を表したようなモデルの使用が、機械翻訳システムで一般的になり、その後NLPの他の分野にも拡張されたことと合わせて[167]、系列データを扱うのに長けている隠れマルコフモデル(HMMs: Hidden Markov Models)が広く利用された[168]。
そして、パターン認識・分類・回帰のタスクに対しては、非線形データ解析の手法であるカーネル法をベースとして1992年にサポートベクトルマシン(SVM: Support Vector Machine)が提案された[169]。SVMはデータを(基本的には2つの)クラスに分類するとき、可能な限り各クラスが大きく分離されるような平面(MMSH: Maximum Margin Separating Hyperplane)を見つけるアルゴリズムであり[170]、比較的メモリ効率が良く小さなデータセットに向いていたため、手書き文字画像の認識等に用いられた[171] [172]。
この頃、ラベル付きデータとラベルなしデータの両方を学習に用いる半教師あり学習(Semi-supervised learning)という手法も普及しだし[173] [174]、学習データの取り扱いの幅も広がってきたといえる。
一方で大規模なデータセットや強力なコンピューティングリソースが必要であるニューラルネットワークの分野は、1994年にMNIST(Modified National Institute of Standards and Technology)という学習用に6万、テスト用に1万枚の手書き数字画像を含むデータセットが作成され[175]、翌1995年にLeNetと呼ばれるニューラルネットワークを有するAIが手書き数字画像の分類精度において、SVMを含むその他のアプローチの結果を上回ることが示された[176](LeNetの研究自体は1989年ごろから始まっていた[177])。LeNetはCNN構造をもっており、畳み込み処理に学習可能なパラメータをもたせることでパラメータ・計算の削減に成功した点が重要とされ、この後のニューラルネットワーク研究の基盤となっている[178]。
そしてこの1995年には、Windows95・Internet Explorerの発表によりPCとインターネットが多くの人の身近に届いたことで[179] [180]、コンピュータが情報を得やすくなり、大きなデータセットの共有も現実的なものになった。
CNNの他にも、Hopfield networkを拡張した[181]、LSTM(Long-Short Time Memory)と呼ばれるRNNが1997年に発表された。LSTMはネットワーク内にMemoryセルと呼ばれる単位で、情報の記憶(memory)と忘却(forget)を調整することで、RNNで問題となっていた勾配爆発を解決した[182] [183]。
さらに、GNN(Graph Neural Network)というグラフを入出力とするリッチなデータ構造に機械学習を用いる構造が発表された[184] [185]。
note
LSTMの元論文にはメモリーセルが情報をforgetするとは書かれていない[186]
そして、アンサンブル学習の研究でも、Weak learnerにより学習された複数の分類機を、並列に実行して出力結果を集約(Aggregation)するBagging(Bootstrap Aggregating、1996年[187])や、直列に結合して一つの強力な分類機を得るBoosting(1990年[148:1]、1995年[188])といった、主流となる手法が確立された。
これらを元としたアルゴリズムとして、複数の決定木を用いたBaggingに特徴選択プロセスにランダム性を導入することでモデルのパフォーマンスを向上させたRandom Forest(2001年)や[189]、使用する学習データセットのサブセット選択にランダム性をもたせることでBoostingをより一般的な学習フレームワークとしたAdaBoost(Adaptive Boosting、1997年)[190]、AdaBoostとGD法を組み合わせたGradient Boostなど[190:1]、様々な派生形が出現した。
アンサンブル学習BaggingとBoostingの概念(引用:[191])
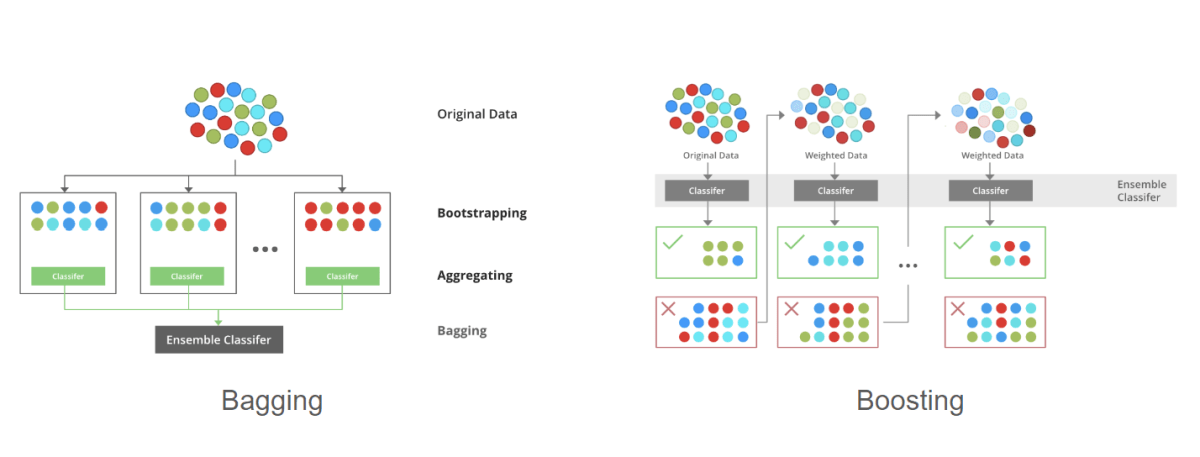
その頃世間でも、1997年にIBM社のDeep Blueがチェスの世界チャンピオンに勝利したり[192]、AIを搭載した製品であるSONY社のAIBO(Artificial Interigence roBOt、1999年)[193] [194]、iRobot社のRoomba(2002年)[195]がリリースされる等、AIのニュースが出始めていた。また、2001年にIT調査会社のMETA Group社(2005年にGartner社に買収されている[196])がBig Dataを提唱し[197]、データソースの範囲が大幅に増加し、データを統合して新しい洞察を生成することが示唆され[198]、2002年にはC/C++の機械学習ライブラリTorchがリリースされるなど[199]、AIの活躍・進化がますます期待された。
ただし、隠れ層を含んだ3層以上のニューラルネットワークはDNN(Deep Neural Network)と呼ばれ[200]、より複雑な非線形関係を計算コストを削減して表現できるようになると期待されたが[201]、依然として学習が難しい(勾配消失問題、局所最適化等)とされ、隠れ層は1層または2層というのが定石だった[202]。そんな中、2006年のGeoffrey HintonとRuslan Salakhutdinovの論文でAutoencoderを持ちいた次元削減の方法が示され[203]、DNNを分類タスクに適用することも可能になった[204]。これ以降、Deep Learningという用語が一般的となり、より注目を浴びていくこととなる[205] [206]。
Network Architecture for an Ordinary Autoencoder(引用:[207])

さらに、アルゴリズム自体だけでなく、データによりアルゴリズムの精度が高まるという考えのもと、2009年に物体認識ソフトウェアの研究のためImageNetという大規模な画像データセットが発表された[208] [209]。翌2010年からILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像認識AIのコンテストが毎年開催され[210]、この頃およびこれ以後のAIブームの触媒となったといえる。
そして、2009年のスタンフォード大学の論文で、主にグラフィック処理のために利用されていたプロセッサであるGPU(Graphic Processor Unit)、2006年にNvidia社によって開発されたCUDA[211]と2008年に発表されたそのプログラミングモデル[212]を利用し、AIの学習を並列に実行することで計算処理が高速化された[213]。これ以来、ニューラルネットワークの学習・推論にGPUが採用されることが多くなった[214]。
2012年のILSCRCでは、AlexNetと呼ばれるDeep CNNモデルが発表され[215]、他を凌駕する性能を見せた。AlexNetは5つの畳み込み層と3つの全結合層という深い構造をしており多くのパラメータを有していたが、CNNでは初めてGPUで学習を行うことで、以前のモデルよりも4倍高速に処理したことが示された[216] [217] [218]。この成果により、Deep Learningが夢物語ではないこと、実用化する方法を世界に示したといえる。
Alexnet Block Diagram(引用:[219])

学習に用いるデータセットが大規模になってくると、最適化アルゴリズムついても、2011年にAdaGrad(Adaptive Gradient)[220] [221]、2012年にRMSprop(Root Mean Square Propagation)といった、勾配の大きさに応じて学習率を調整するように損失の振動を抑制した手法が発表された[222] [223]。また2012年には、更新時に確率的勾配の平均を取るSAG(Stochastic Average Gradient)法なども提案されている[224] [225]。
また、1次法の弱点として、ハイパーパラメータ(ステップ長、バッチサイズ等)調整、並列化による学習プロセスの高速化などが難しいことを上げ、高次法のNewton法を現実的な計算リソースで可能としたLBFGS(memory-Limited Broyden–Fletcher–Goldfarb–Shanno algorithm、2007年)をはじめ[226]、さまざまながStochastic Newton法やQuasi Newton法が開発されるなど[227]、Optimizationの研究も活発になってきた。
インターネットの普及が続き、2000年初期あたりからWeb2.0と呼ばれる時代に入る[228]。Facebook(2004年[229])、Youtube(2005年[230])、Twitter(2006年[231])をはじめとした動的コンテンツを有するWebサービスが続々と立ち上がり、2006年ごろからのWi-Fiの普及もあって[232]、Web上で人々が活動するようになった。さらに、MySQLやPostgreSQLなどのデータベースシステムの成長[233]や2008年ごろのIoT(Internet of Things)の誕生[234]など、発生するデータが増加する明らかな兆候が見え始める。このような流れもあり、2009年のIDC(International Data Corporation)社の調査では2020年までにデジタルデータは44倍の35ゼタバイトに増加する(Data explosion)と予測され大きな反響を呼んだ[235]。それにより学習データが重要とされているAI、特にDeep Learningの分野により期待がかかるようになった。
また、2008年にGitを使用したソフトウェア開発とバージョン管理のためのプラットフォームであるGithubが公開[236]、このころ勢いをつけていたプログラミング言語であるPythonについて[237]、機械学習プログラミングが容易になるライブラリであるscikit-learn(2007年[238])、Theano(2007年[239])などが利用可能となり、AI開発の敷居もますます下がったいえる。
Data growth and expansion (IDC, 2009) (引用:[240])

3.5. 2013年ごろ以降 :Deep Learning
2013年頃に、メディア報道に「Big Tech」という技術系大企業(Big FourはGoogle、Amazon、Facebook、Apple、Big Fiveはそれらに加えてMicrosoft)を表す用語が現れはじめた[241] [242]。これらの企業は例えば、Apple社が音声認識のデジタルアシスタントであるSiriをiPhone 4Sに実装(2011年)[243]、Facebook社がFAIR(Facebook Artificial Intelligence Research)を設立(2013年)[244]、Google社が英国のAIスタートアップDeepMind社を買収(2014年)[245]、Amazon社がスマートスピーカーにバーチャルアシスタントAlexaを搭載(2014年)[246]、Microsoft社がデジタルアシスタントCortanaをリリース(2014年)など[247]、AIに対しても非常に積極的な動きを見せていた。
この頃、CPU性能の一つであるクロック周波数は頭打ち状態となっていたが、マルチコア化、仮想化等により、コンピュータはさらに高性能になっていった[248]。チップレベルでいえば、集積化が進んでも単位面積当たりの消費電力が変わらないというデナード則(Dennard's scaling)が崩壊し、パフォーマンスを上げつつ発熱等の問題に対応するためにはすべてのコアを同時に使用できないという問題(Dark Silicon)に対して[249]、用途別のアクセラレータやヘテロジニアス構造で対応していくという時代に入り[250]、Deep Learningもより高度化していく。
AI研究では、2013年、入力を示すベクトル空間を生成するEmbeddingと呼ばれる処理により、単語の意味を表現したWord Embeddingを生成するWord2vecと呼ばれるモデルがGoogle社の技術者により発表された[251] [252]。そして2014年に発表されたSeq2seq(Sequence-to-Sequence)モデルでは[253]、RNNでWord Embeddingを行い、さらにRNNで別の言語に変換するという機械翻訳モデルが提案された。このようなEmbeddingを行うEncoderと、それをもとに出力を行うDecoderからなる構造を、Encoder-Decoderと呼び[254]、自然言語処理(翻訳)でいうと複雑な文構造や慣用的な表現などニュアンスを考慮した処理を可能とした[255](構造・機能の定性的なまとめはこちらをご参照)。
2014年にStanford大によりGloVeと呼ばれる事前学習されたモデルが発表され[256]、特に機械翻訳ではWord Embeddingが主流になっていった[257]。
note
Word embeddingという言葉は、2003年に提唱され、2008年のA unified architecture for natural language processingという論文で初めて実証されたとされる[257:1]。入力をベクトル空間に焼き直せばよいので、CNNの畳み込み層を、Image Embeddingとする場合もある[258]。
Embeddings can produce remarkable analogies(引用:[259])

そしてこの2014年には、2種類のニューラルネット(それぞれ、Generator、Descriminatorと呼ばれる。詳細は割愛)を用いてAIが画像を生成できる事例を示したGAN(Generative Adversarial Neural network)というモデルが発表され[260]、クリエイティブな能力を持つAI、すなわち生成AI(Generative AI)が見えてきた。
また同2014年に、Adam(Adaptive moment estimation)と呼ばれる[261] [262]、RMSrop法とMomentum法を組み合わせたOptimizer、XGBoost(eXtream Gradient Boost)と呼ばれるアンサンブル学習法が登場した。
この頃、ドイツのIndustrie 4.0(2013年に発表、2015年に拡大[263])中国のMade in China 2025(中国製造2025)(2015年)、日本のSociety 5.0(2016年)、アメリカの米国AI研究開発戦略計画(National Artificial Intelligence Research and Development Strategic Plan)(2016年)など[264]、の戦略などAIを組み込んだ政策レベルの動きも活発化し、国家としてAI技術を前提とした社会を大々的に打ち上げるようになってきた。
また、AI研究においても、2015年には、Google社のエンジニアによりKeras[265]、日本のPreferred Networks社によりChainer[266]、Google社によりTensorflow、翌2016年にFacebook社よりPyTorch[267]というオープンソースのGPUをサポートしたPythonベースの機械学習・Deep Learningのライブラリがリリースされ、さらにAI・機械学習に対する取り組みの敷居が大幅に下がる。さらに同2015年、機械学習モデルの利活用フェーズの考え方として、2009年に発案されたDevOps(Development Operations)の原則[268]を機械学習モデルを組み込んだシステムに適用し、システムの自動化とモニタリングを推進できるMLOps(Machine Operations)というパラダイムも注目され始めた[269] [270] 。
世間的にも、Google社(厳密にはDeepMind社)のAlphaGoというAIが囲碁の世界チャンピオンに勝利し、大きな話題を呼んだ[271]。
AI研究にういては2015年、ニューラルネットワークのさらなる多層化に伴う勾配消失・勾配爆発問題への対策として、Microsoft Research社によりResNet(Residual Network)と呼ばれる、ネットワークの層を飛ばしてニューロンを結合させる(スキップ接続)構造を持ったモデルが提案された [272] [273]。 この技術により、数百数千の層を持つ、ますます深いネットワークの可能性が見出された[274]。
また、Seq2seqモデルではEncoderの出力が固定長であるため長い入力に対応しづらいことなどを問題点とし[275]、Attention機構と呼ばれるDecoderが注目すべき部分を示すベクトルを計算するメカニズムを実装したモデルが提案され、制度が向上することが示された(2015年の論文[276]が多く引用された[277])[278] [279]。このAttention機構を応用したモデルや[280]、画像処理AIに適用した例など[281]、その後さまざまなアルゴリズムのAttention機構が提案された(Attention機構の詳細はこちらもご参照)。
ただし、Attention機構が高精度化に大きく貢献した一方で、RNNを用いたEncoder-Decoderモデルのようなシーケンシャルな構造では大規模な入力に対して、計算に時間がかかりすぎるという欠点があった[282]。これに対して、そこで2017年にMulti-head Attentionという方式のAttention機構を搭載して並列計算可能となった、Transformerと呼ばれるモデルが発表された[283]。このTransformerは入力の全体から注目すべき部分を考慮させる点で、入力のうち特定の部分の前後関係を分析するRNNなどのニューラルネットワークとは、根本的に動作が異なり[284] [285]、CNNやRNNより計算量が抑えられ、訓練が容易で、並列処理CNNもしやすいなどの特長を持つ[286]。
この頃、分散コンピューティングや並列コンピューティングが一般的となってきて、Stchastic LBFGS(2015年)[287]やその改善版が提案されるなど、Optimizationアルゴリズムとして様々なQuasi Newton法なども実用化が見えてきた[288]。
Transformerの構造(引用:[289])
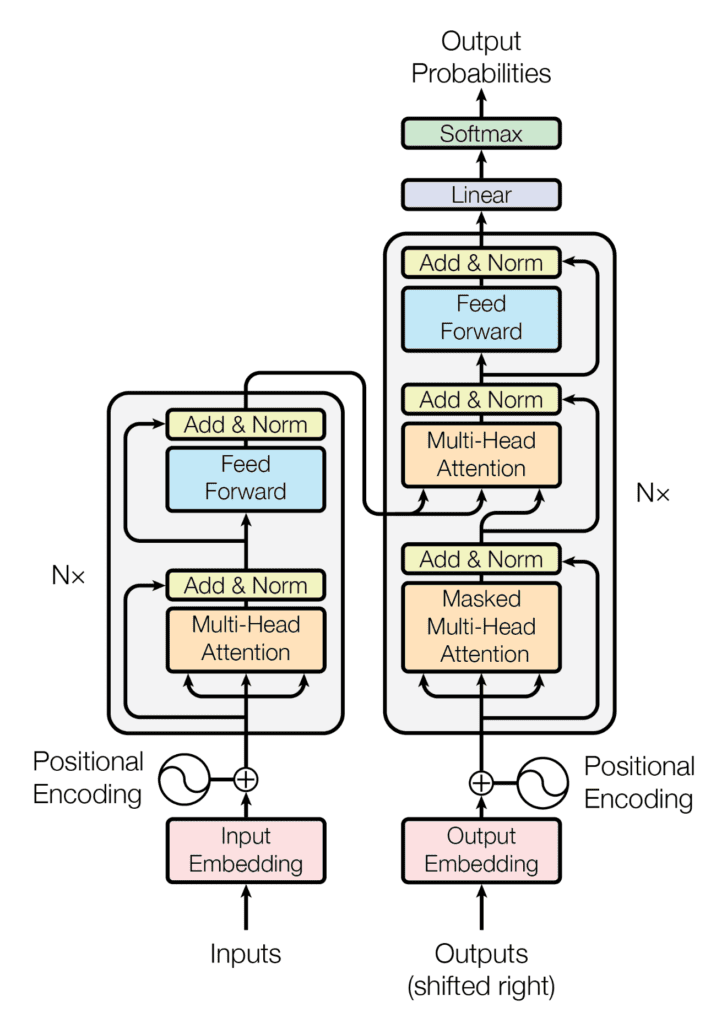
産業界全体では、Industrie 4.0のキーテクノロジーの一つにAIが挙げられていることや[290] [291]、この頃のAI技術への投資元のメインは政府ではなく産業界となったこと[151:2](DARPAが2018年にAI Next Campaignを打ち出すなど、政府関連も投資は継続している[292])、2006年ごろから普及しだしたクラウドコンピューティング技術により[293]、多くのソフトウェアがオンプレミスからクラウドへと移行していった反動や、続々とAIのパフォーマンスが人間の能力を超えてきていることもあり[294]、小規模リソースで動作するEdge AIが注目されてきた。スマートフォンへのAI実装に向けた開発環境としても、2017年にTensorFlow Lite[295]、2019年にPytorch Mobileが発表された[296]。
State-of-the-art AI performance on benchmarks, relative to human performance(引用:[294:1])

大量のデータをGPU等大規模な計算リソースで処理できるようになってきたことにより、2019、2020年ごろから、ラベルのないデータから独自のラベルを自動的に作り、それをもとに学習を進める自己教師あり学習(Self-Supervised Learning: SSL)が注目を浴びてきた[297] [298] [299]。
Transformerモデルは非常に有用であり、2018年には目的や学習方法が異なるGoogle社のBERT(Bidirectional Encoder Representations from Transformers)や[300] [301](2019年にはGoogleの検索にも導入されている[302])、OpenAI社のGPT(Generative Pre-Trained Transformer)といった[303] [304]、自然言語系のAIモデルが発表された。言語系のモデルは大規模な学習データを用いると不連続にパフォーマンスが向上することがわかってきて、モデルサイズ(パラメータ数のこと。10億(Billion)単位でカウントされる)を増加している[305]。
Language Model Sizes Over times(引用:[306])

このようなモデルは特にLLMs(Large Language Models, 大規模言語モデル)と呼ばれ、OpenAI社のGPT-3(2020年7月)[307]、GPT-3.5(2022年3月)[308]、GPT-4(2023年3月)[309]、Google社のLaMDA(2021年3月)[310]、PaLM(2022年4月)[311]、PaLM-2(2023年3月)[312]、Gemini(2023年12月)[313]、Meta社のLLaMa(2023年2月)[314]、LLaMa-2(2023年7月、優先パートナーとしてMicrosoft社が挙げられた)[315]、Anthropic社のClaude(2023年3月)[316]、Claude2(2023年7月)[317]など、現在でも新しいモデルが開発されている。
そしてLLMsは、追加の学習用データセットを用いてFine tuningを行うことで用途に特化したサービスにすることができ[318]、その意味で基盤モデル(Foundation Model)と呼ばれることもある[319]。中でも、GPT-3.5をChatbot用にFine tuningしたChatGPTというサービスは、2022年11月にリリースされて2か月で月間1億人のアクティブユーザーに到達したと推定され、史上最も急速に成長している消費者向けアプリケーションと呼ばれている[320]。これにより、「生成AI」という言葉が爆発的に普及し、オフィスドキュメントのデファクトスタンダードである[321]Microsoft 365にChatGPTを統合したため、技術者でなくてもAIに触れる機械が激増した。
これに伴い、元データを提供する情報検索システムを追加してChatGPTのようなLLMsサービスの機能を拡張するパターンであるRAG(Retrieval Augmentation Generation)パターンや[322]、生成AIに目的の出力を生成させる技術としてPrompt Engineeringなど[323]、新しいコンセプトも続々出現している。
Transformerはそのパフォーマンスの高さから他の分野にも用は拡大し[324] [325]、マシンビジョン(画像認識)向けのVision Transformer(ViT、2020年)など[326]、従来のニューラルネットワークが担ってきたタスクを代替する手法としても用いられ始めている。そして、生成AIという観点では、テキストから画像を生成するtext-to-imageモデルと呼ばれる分野も発展し、Stability AI社のStable Diffusion(2022年)、Midjourney社のMidjourney(2022年)、OpenAI社のDALL-E3(2023年)などが発表されている。
-
Why Logic is Important for Computer Science and Mathematics ↩︎
-
G. Leibniz. De Progressione dyadica Pars I. 15 March 1679. [Principles of binary computers governed by punch cards.] ↩︎
-
2021: 375th birthday of Leibniz, founder of computer science ↩︎
-
Alan Turing and the Development of the Electronic Computer ↩︎ ↩︎
-
ON COMPUTABLE NUMBERS, WITH AN APPLICATION TO THE ENTSCHEIDUNGSPROBLEM ↩︎ ↩︎
-
Alan Turing The Math Genius, The Cryptanalyst, and The Father Of Computer Science ↩︎
-
LOGICAL CIRCUITS: THE INTELLECTUAL ORIGINS OF THE McCULLOCH–PITTS NEURAL NETWORKS ↩︎
-
The First Modern Computer – The Case for Baby, the Manchester Mk I Prototype (Computer History) ↩︎
-
The Rise In Computing Power: Why Ubiquitous Artificial Intelligence Is Now A Reality ↩︎
-
Edmund Berkeley Publishes "Giant Brains," the First Popular Book on Electronic Computers ↩︎
-
On Thinking Machines, Machine Learning, And How AI Took Over Statistics ↩︎
-
Newell, Simon & Shaw Develop the First Artificial Intelligence Program ↩︎
-
Gugerty L (2006) Newell and Simon’s logic theorist: historical background and impact on cognitive modelling. In: Proceedings of the human factors and ergonomics society annual meeting. Symposium conducted at the meeting of SAGE Publications. Sage, Los Angeles, CA ↩︎
-
Dartmouth Summer Research Project: The Birth of Artificial Intelligence ↩︎
-
A PROPOSAL FOR THE DARTMOUTH SUMMER RESEARCH PROJECT ON ARTIFICIAL INTELLIGENCE ↩︎
-
A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence ↩︎
-
Neural Networks: Why Does the Perceptron Rule Only Work for Linearly Separable Data? ↩︎
-
The History of Neural Networks Part 2: Rosenblatt's Perceptron ↩︎
-
The Math behind Neural Networks: Part 1 - The Rosenblatt Perceptron ↩︎
-
Frank Rosenblatt’s Perceptron, Birth of The Neural Network ↩︎
-
PHYS 139/239: Machine Learning in Physics Lecture 2: Perceptron Learning Algorithm & (Stochastic) Gradient Descent ↩︎
-
A Basic Introduction to Feedforward Backpropagation Neural Networks (after Leverington, 2001) ↩︎
-
The ADALINE - Theory and Implementation of the First Neural Network Trained With Gradient Descent ↩︎
-
Some methods of speeding up the convergence of iteration methods ↩︎
-
A Survey of Optimization Methods from a Machine Learning Perspective ↩︎ ↩︎
-
Deep Learning Neural Network Algorithm for Computation of SPICE Transient Simulation of Nonlinear Time Dependent Circuits ↩︎
-
Vintage Computer Chip Collectibles, Memorabilia & Jewelry ↩︎
-
Building the Second Mind, 1961-1980: From the Ascendancy of ARPA to the Advent of Commercial Expert Systems ↩︎
-
DENDRAL: a case study of the first expert system for scientific hypothesis formation ↩︎
-
Buchanan, Bruce & Feigenbaum, E.A. & Lederberg, J.. (1968). Heuristic DENDRAL: A program for generating explanatory hypotheses in organic chemistry. Machine Intelligence. 4. ↩︎
-
DENDRAL and Meta-DENDRAL roots of knowledge systems and expert system applications ↩︎
-
ELIZA A Computer Program For the Study of Natural Language Communication Between Man And Machine ↩︎
-
The computational therapeutic: exploring Weizenbaum’s ELIZA as a history of the present ↩︎
-
1962-6 – “STELLA” CYBERNETIC TORTOISE – JOHN H. ANDREAE AND PETER L. JOYCE (BRITISH) ↩︎
-
CONSEQUENCES OF THE HUGHES PHENOMENON ON SOME CLASSIFICATION TECHNIQUES ↩︎
-
[Feigenbaum, E. A. “The Art of Artificial Intelligence: Themes and Case Studies of Knowledge Engineering,” Proceedings of the International Joint Conference on Artificial Intelligence. Cambridge, MA: MIT Press.] ↩︎
-
[Feigenbaum, E. A., Buchanan, B. G., and Lederberg, J. “On Generality and Problem Solving: A Case Study Using the DENDRAL Program,” in Machine Intelligence] ↩︎
-
Jerry Kaplan, Artificial Intelligence: What Everyone Needs to Know ↩︎
-
History of artificial intelligence: expert systems and AI winters ↩︎
-
History of Artificial Intelligence (AI) and How it has evolved ↩︎
-
Probability Judgment in Artificial Intelligence and Expert Systems ↩︎
-
PROSPECTOR: A Computer-Based Consultation System For Mineral Exploration ↩︎
-
CADIAG: APPROACHES TO COMPUTER-ASSISTED MEDICAL DIAGNOSIS ↩︎
-
Artificial Intelligence in Japan (R&D, Market and Industry Analysis) ↩︎
-
Neural networks and physical systems with emergent collective computational abilities ↩︎
-
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski. A learning algorithm for Boltzmann machines. Cognitive Science, pages 147–169, 1985. ↩︎
-
Back Propagation in Neural Network: Machine Learning Algorithm ↩︎
-
Cryptographic Limitations on Learning Boolean Formulae and Finite Automata ↩︎
-
The Evolution of Boosting Algorithms From Machine Learning to Statistical Modelling ↩︎
-
AI Watch Historical Evolution of Artificial Intelligence ↩︎ ↩︎ ↩︎
-
The History of Artificial Intelligence from the 1950s to Today: The Emergence of NLPs and Computer Vision in the 1990s ↩︎
-
THE IMPACT OF ARTIFICIAL INTELLIGENCE ON THE FUTURE OF WORKFORCES IN THE EUROPEAN UNION AND THE UNITED STATES OF AMERICA ↩︎
-
Symbolic and Neural Learning Algorithms: An Experimental Comparison ↩︎
-
Gradient amplification: An efficient way to train deep neural networks
(https://ml.jku.at/publications/older/ch7.pdf) ↩︎ -
Learning long-term dependencies with gradient descent is difficult ↩︎
-
Top 4 advantages and disadvantages of Support Vector Machine or SVM ↩︎
-
Backpropagation Applied to Handwritten Zip Code Recognition ↩︎
-
Wang, Xin & Liu, Yuanchao & Sun, Chengjie & Wang, Baoxun & Wang, Xiaolong. (2015). Predicting Polarities of Tweets by Composing Word Embeddings with Long Short-Term Memory. 1343-1353. 10.3115/v1/P15-1130. ↩︎
-
A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting ↩︎ ↩︎
-
25 years ago today: How Deep Blue vs. Kasparov changed AI forever ↩︎
-
ロボットによるエンタテインメント市場を創造する4足歩行型エンタテインメントロボット "AIBO(アイボ)"の販売開始 ↩︎
-
iRobot Introduces Roomba™ Intelligent FloorVac - The First Automatic Floor Cleaner In The U.S. ↩︎
-
What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets ↩︎
-
Chapter 9 - The Big Data and Artificial Intelligence: Opportunities and Challenges to Modernise the Policy Cycle ↩︎
-
Auto-Encoders in Deep Learning—A Review with New Perspectives ↩︎
-
Hands-On Machine Learning with R: Chapter 19 Autoencoders ↩︎
-
Lecture 12 Handwritten Digit (MNIST) Recognition Using Deep Neural Networks ↩︎
-
Large-scale Deep Unsupervised Learning using Graphics Processors ↩︎
-
ImageNet Classification with Deep Convolutional Neural Networks ↩︎
-
A practical experiment for comparing LeNet, AlexNet, VGG and ResNet models with their advantages and disadvantages. ↩︎
-
The data that transformed AI research—and possibly the world ↩︎
-
Difference between AlexNet, VGGNet, ResNet, and Inception ↩︎
-
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization ↩︎
-
A stochastic gradient method with an exponential convergence rate for finite training sets ↩︎
-
A Stochastic Quasi-Newton Method for Online Convex Optimization ↩︎
-
Quasi-Newton methods for machine learning: forget the past, just sample ↩︎
-
The Evolution of the Internet: Web 1.0, Web 2.0 and Web 3.0. ↩︎
-
Google buys UK artificial intelligence startup Deepmind for £400m ↩︎
-
A brief history of Cortana, Microsoft's trusty digital assistant ↩︎
-
Dark Memory and Accelerator-Rich System Optimization in the Dark Silicon Era ↩︎
-
AI Accelerators — Part II: Transistors and Pizza (or: Why Do We Need Accelerators)? ↩︎
-
Distributed Representations of Words and Phrases and their Compositionality ↩︎
-
Efficient Estimation of Word Representations in Vector Space ↩︎
-
The Benefits of AI Seq2Seq Models in Machine Translation and Language Processing ↩︎
-
An overview of word embeddings and their connection to distributional semantic models ↩︎ ↩︎
-
Creation of the National Artificial Intelligence Research and Development Strategic Plan ↩︎
-
The History of Keras: From Research Project to Industry Standard ↩︎
-
Artificial intelligence: Google's AlphaGo beats Go master Lee Se-dol ↩︎
-
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ↩︎
-
Review — Neural Machine Translation by Jointly Learning to Align and Translate ↩︎
-
Neural Machine Translation by Jointly Learning to Align and Translate ↩︎
-
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ↩︎
-
Attention is all you need: Discovering the Transformer paper ↩︎
-
AI models are powerful, but are they biologically plausible? ↩︎
-
CRDS 国立研究開発法人科学技術振興機構 研究開発戦略センター 研究開発の俯瞰報告書 システム・情報科学技術分野(2023年) ↩︎
-
A fast quasi-Newton-type method for large-scale stochastic optimisation ↩︎
-
4 Charts That Show Why AI Progress Is Unlikely to Slow Down ↩︎ ↩︎
-
Facebook launches PyTorch Mobile for edge ML on Android and iOS devices ↩︎
-
A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends ↩︎
-
Unleashing the Power of BERT: How the Transformer Model Revolutionized NLP ↩︎
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩︎
-
Improving Language Understanding by Generative Pre-Training ↩︎
-
OpenAI’s new language generator GPT-3 is shockingly good—and completely mindless ↩︎
-
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance ↩︎
-
Introducing Gemini: our largest and most capable AI model ↩︎
-
Introducing LLaMA: A foundational, 65-billion-parameter large language model ↩︎
-
The Ultimate Guide to LLM Fine Tuning: Best Practices & Tools ↩︎
-
ChatGPT sets record for fastest-growing user base - analyst note ↩︎
-
The biggest blocker to LibreOffice adoption? LibreOffice. ↩︎
-
Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy ↩︎
-
A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks ↩︎
-
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ↩︎
Discussion