【FDUA】第2回 金融データ活用チャレンジ参加記(15th solution)
はじめに
開催期間:2024/1/18 18:00 ~ 2024/2/15 23:59
第2回 金融データ活用チャレンジに参加し、最終結果15位になりました。
解法とコンペ開催中の流れを振り返りながら感じたことをまとめていきます。

15th解法
CV: 0.687
Public: 0.6889767
Private: 0.6869111
サマリ
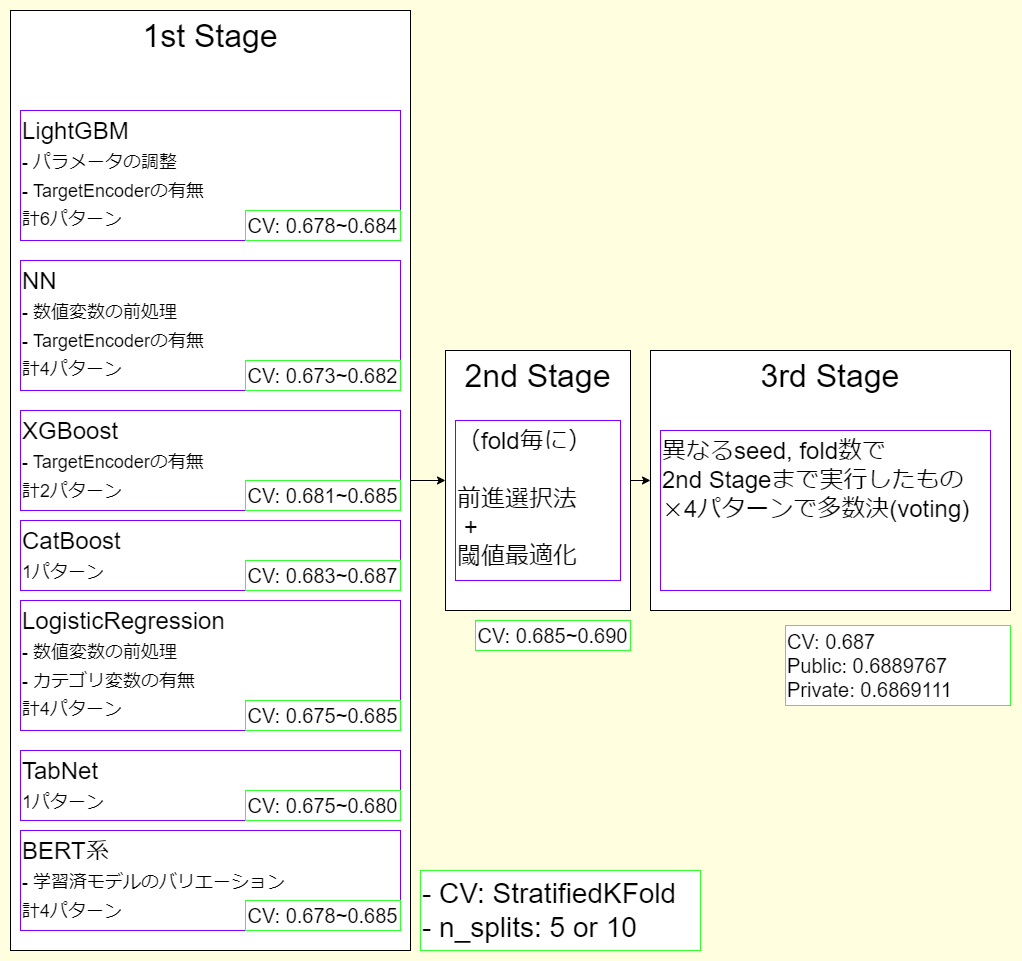
1. 特徴量エンジニアリング + 線形モデル/GBDT/NN
特徴量エンジニアリング
最終的に各モデルに入力した特徴量は以下のものです。
-
カテゴリ変数
State, BankState, FranchiseCode, UrbanRural, RevLineCr, LowDoc, ApprovalFY
をいずれも元データのままカテゴリ変数扱いにして入力しています。
-
数値変数
Term, NoEmp, NewExist, CreateJob, RetainedJob
また、以下の変数は、NNや線形モデル入力用にlog(x + 1)
DisbursementGross, GrAppv, SBA_Appv -
日付変数
DisbursementDate, ApprovalDateのYear, Month(1~12), Day(1~31), Weekday(0~6)をカテゴリ変数扱いにして入力しています -
特徴量エンジニアリング
- 行方向に欠損値をカウントした値
- Termを12で割ったあまり
(生成元データでは結構効きそうな特徴量でしたが、今回のデータではそうでもなさそうです) - DisbursementDate, ApprovalDate, ApprovalFYのそれぞれの組み合わせでのYearの差分
- DisbursementGross, GrAppv, SBA_Appvにlogを取った値のそれぞれの組み合わせの差分
- CreateJob - RetainedJob
- (LowDoc == "Y" and DisbursementGross < 150,000)かどうか
- (LowDoc == "Y" and GrAppv < 150,000)かどうか
- (LowDoc == "Y" and SBA_Appv < 150,000)かどうか
- DisbursementGross, GrAppv, SBA_Appv, TermをSectorでGroupbyした平均、標準偏差、最大値、最小値
- DisbursementGross, GrAppv, SBA_Appv, TermをCityでGroupbyした平均、標準偏差、最大値、最小値
データの説明を読んだり、Cityにoverfitしないことを考えて特徴量を作成しました。細かい精度への影響は確認できていませんが、他の特徴量を作ったり、Cityをカテゴリ変数として入力したりといった実験を経て選択した特徴量になります。
GBDT
LightGBMでは、(boosting_type == "gbdt", "rf", "dart")を試して、最終的に全部をアンサンブルの種にしました。
XGBoostやCatBoostはあまりバリエーションを試していませんが、アンサンブルの種として十分実用的だと思い入れています。
NN
torch.nn.Linearの後に以下のようなResNetぽいブロックを作って4層重ねています。
(アーキテクチャの細かい修正は本質的でないと思ったので、決め打ちで最後まで進みました)
class ResLinearBNDropout(torch.nn.Module):
def __init__(
self,
out_features,
dropout=0.1,
activation="ReLU",
) -> None:
super().__init__()
self.layers = torch.nn.ModuleList(
[
torch.nn.LazyLinear(out_features=out_features),
torch.nn.LazyBatchNorm1d(),
getattr(torch.nn, activation)(),
torch.nn.LazyLinear(out_features=out_features),
torch.nn.LazyBatchNorm1d(),
]
)
self.dropout_layer = torch.nn.Dropout(dropout)
def forward(self, x):
identity = x
for layer in self.layers:
x = layer(x)
x += identity
x = self.dropout_layer(x)
return x
また、あまり精度はよくならなかったですが、TabNetも取り入れました。
2. BERT系モデル
特徴量を全部横並びに[SEP]トークンで区切ってつなげ、BERT系の事前学習済モデルをファインチューニングすることで予測を得ました。

最終的には、以下のバリエーションをアンサンブルに使っています。
- microsoft/deberta-v3-small
- microsoft/deberta-v3-base
- roberta-base
- ProsusAI/finbert(金融系の課題なので何か意味があるかなと思って入れましたがおそらくあまり効果はないです)
3. 2nd Stage: 前進選択法 + 閾値調整
前進選択法
それぞれのモデルで得られたout-of-fold予測値(oof)を使ってforward selectionを行います。具体的な手順は以下です。
- 一番oofのlog_lossが小さいモデルを選択
- 1で選んだモデル以外のモデルに対して以下を実行
-1.0 ~ 1.0で0.01ずつウェイトを調整しながら、1で選んだモデルと加重平均をとることでoofのlog_lossが最小となるモデルとウェイトを取得 - 2で選んだモデルとウェイトを用いて1の予測値を更新
- 2~3をlog_lossが改善しなくなるまで繰り返して最良のモデルとウェイトを取得
このあたりを参考にしました
閾値調整
前進選択法で得られた予測確率について、oof予測値のマクロF1が最も高くなる閾値を取得します。
ソースコードは以下です
import numpy as np
from sklearn.metrics import f1_score
from scipy.optimize import minimize_scalar
def best_f1_threshold(target: np.ndarray, probability: np.ndarray, verbose: bool = True):
def objective(x):
preds = np.where(probability > x, 1, 0)
score = f1_score(target, preds, average="macro")
return -score
minimize_result = minimize_scalar(
objective,
bounds=(0, 1),
)
best_threshold = minimize_result.x
if verbose:
print("#" * 10)
print(minimize_result)
print("#" * 10)
return best_threshold
4. 3rd Stage: ランダムシード + 多数決
2nd Stageまでの予測を乱数seed値とfold数4パターンに対して行い、各モデルから得られた予測値の多数決(voting)で最終的な予測値を取得しました。(本当はもう1つseed値を追加するつもりでしたが、例の最終日の障害で叶わず・・・)
コンペ開催中の流れ
コンペ序盤
コンペ開催のことは知っていましたが、仕事等の都合で、実際に参加できたのは開始から3~4日経ったあたりでした。開会式の動画を見たり、Slackでどういう流れになっているのかを掴みながらベースラインのモデルをLightGBMで実装していました。
最序盤では、リーダーボード計算に使用される正解データに不備があったということで、2024/1/23に再登録が入っています。CVとLBのスコアに開きがあったことから参加者の方が気づいて運営に報告していただいたようです。(最終日のトラブルにかき消されて忘れ去られていますが、これも開催期間延長に相当する多大な影響のような気がします…最大で25~30程度の提出に影響があるので…)
コンペ中盤
徐々にPublicリーダーボードも安定してきており、データに関するSlackでの議論も活発だったと思います。私はROM専でしたが、いろいろデータに関する気づきが得られました。また、Dataiku等のツールに関する投稿の多さからカジュアルに機械学習に入門できるツールの重要性と影響の大きさを感じていました。
コンペ終盤
最高でPublic4位まで登っていましたが、実はリークのあるモデルだということが後で発覚し、最終提出には使いませんでした。(結果論ですが、選んでいたら金圏でした…)
また、oof予測値を使って、データを2分割→それぞれのマクロF1スコアの差分を計算をたくさん行ってプロットし、最終評価がどのくらい揺れそうかについて考えていました。
以下のようなイメージ(使った予測値は、PublicLB金圏にいたときのOOF)
from tqdm.auto import tqdm
from sklearn.model_selection import train_test_split
ls = []
idx = np.arange(len(df))
for step in tqdm(range(30000)):
idx_a, idx_b = train_test_split(
idx,
test_size=0.5,
shuffle=True,
random_state=step,
stratify=df["MIS_Status"],
)
ta, pa = df.iloc[idx_a]["MIS_Status"], df.iloc[idx_a]["prediction"]
tb, pb = df.iloc[idx_b]["MIS_Status"], df.iloc[idx_b]["prediction"]
score_a = f1_score(ta, pa, average="macro")
score_b = f1_score(tb, pb, average="macro")
ls.append(score_a - score_b)
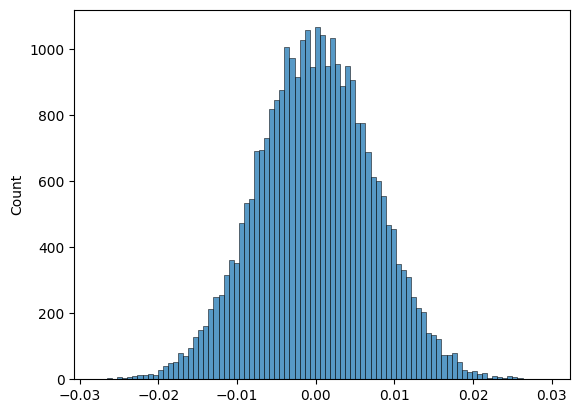
図からわかるように、0.01くらいの揺れは起こってもおかしくないと思い、それだけ揺れると金圏→銀圏下位くらいまで吹き飛ばされることも十分あり得ます。そのため、なるべく頑健な予測値を作れるようsolutionに書いたような複数のseed値で多数決をとる工夫をしていました。
コンペ最終日
コンペ最終日、普通に夕方まで仕事だったので、退勤後に最後のアンサンブルの作成と提出をして寝る予定を立てていました。ところが、最終日16時台からコンペのページに接続できない事象が発生し、提出や最終選択ができない参加者が続出しました。開催期間の延長や最終提出選択の猶予をもらえるよう運営に要望を出していた方も多かったですが、最終的には期日通りにコンペが終わってしまいました。事後の対応の有無についても、記事投稿時点で検討中のようです。
おわりに
- できたこと
- 最終的に比較的高い順位に留まれたこと
- Slackの議論から、データに関する知見を蓄積できたこと
- テーブルデータコンペの自分のソースコードを整理できたこと
- できなかったこと
- 金圏の提出もあったが選べなかったこと(これはShakeを避けるためにある程度仕方ないですが)
- 最終日のトラブルもあり、最後まで走り切れなかったこと
- Public, Privateともに1位だった方のように、何か特別なTrickがありそうということは思っていたが、EDAが足らず取り組めなかったこと(この記事投稿時点で1位解法が公開されていないため個人的にも楽しみにしているところです)
最終日のトラブルで煮え切らない点がありつつも、改めて「できたこと」を整理してみると学びの多いコンペでした。Slackやブログで知見を共有してくださった方々、ありがとうございました!
第3回も開催されることを楽しみにしています!
Discussion