リアルタイム文字起こしアプリをstreamlitで作成してみよう!
最近、テック系イベントのブースでリアルタイム文字起こしのデモを見る機会があって、whisperとstreamlitでローカル環境のみで実行出来たら面白いなと思い作成してみました
文字起こし画面
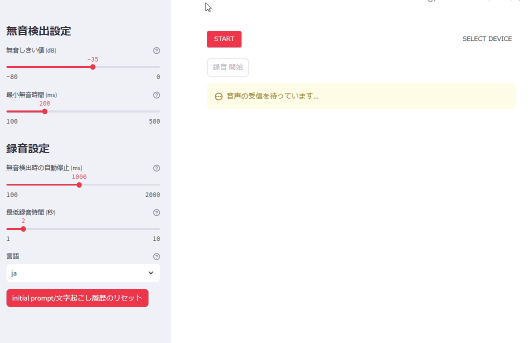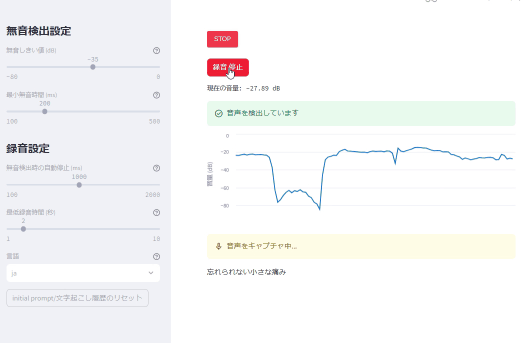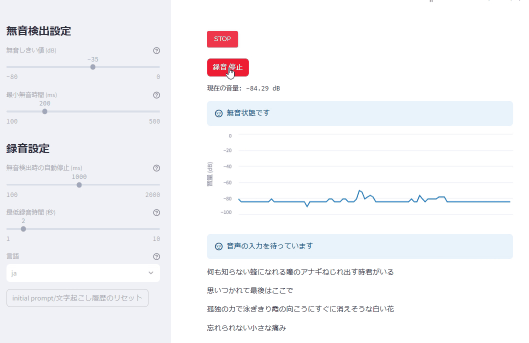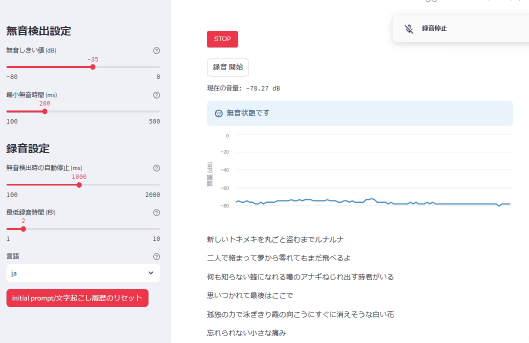
*カラオケしてます
github
streamlit-webrtc
streamlitで画像/音声処理をリアルタイムで行うカスタムコンポーネントを作成されている方がいましたので、それを使って音声を取り込みます。
作成してみよう!!
必要なパッケージ
streamlit==1.38.0
streamlit_webrtc
requests
pandas
altair
av
numpy
twilio
pydub
aiortc
openai
アプリ
長いので省略しますがGithubで公開しています。
app.py
import logging
import queue
import time
import os
import tempfile
import asyncio
import pydub
import streamlit as st
from streamlit_webrtc import WebRtcMode, webrtc_streamer
import requests
import altair as alt
import pandas as pd
st.set_page_config(layout="wide",page_title="realtime-transcribe")
logger = logging.getLogger(__name__)
# セッション状態の初期化
if 'recording' not in st.session_state:
st.session_state.recording = False # 録音中かどうかのフラグ
if 'recorded_audio' not in st.session_state:
st.session_state.recorded_audio = None # 録音済み音声データ
if 'temp_audio_file' not in st.session_state:
st.session_state.temp_audio_file = None # 一時保存用の音声ファイルパス
if 'is_capturing' not in st.session_state:
st.session_state.is_capturing = False # 音声キャプチャ中かどうかのフラグ
if 'capture_buffer' not in st.session_state:
st.session_state.capture_buffer = pydub.AudioSegment.empty() # 音声キャプチャ用バッファ
if 'volume_history' not in st.session_state:
st.session_state.volume_history = [] # 音量履歴(グラフ表示用)
# 録音開始/停止ボタン
def toggle_recording():
if st.session_state.recording:
st.toast(f"**録音停止**",icon=":material/mic_off:")
else:
st.toast(f"**録音開始**",icon=":material/mic:")
st.session_state.recording = not st.session_state.recording
if not st.session_state.recording:
# 録音停止時、キャプチャも停止
st.session_state.is_capturing = False
webrtc_ctx = webrtc_streamer(
key="sendonly-audio", # WebRTCコンポーネントの一意の識別子
mode=WebRtcMode.SENDONLY, # 送信専用モード
audio_receiver_size=256, # 受信バッファサイズ
rtc_configuration={
"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}], # STUN/TURNサーバー設定
"iceTransportPolicy": "all", # ICE接続ポリシー
},
media_stream_constraints={"audio": True}, # 音声のみ有効化
)
st.button(
"録音 " + ("停止" if st.session_state.recording else "開始"),
on_click=toggle_recording,
type="primary" if st.session_state.recording else "secondary",
disabled=webrtc_ctx.audio_receiver is None
)
if 'full_text' not in st.session_state:
st.session_state.full_text = ()
if webrtc_ctx.audio_receiver is None:
st.session_state.recording = False
# 無音部分の検出結果を表示する場所
silence_info_placeholder = st.empty()
# 無音検出用のパラメータ設定
# サイドバーにスライダーを配置して、ユーザーがリアルタイムに調整できるようにする
st.sidebar.title("無音検出設定")
silence_threshold = st.sidebar.slider(
"無音しきい値 (dB)",
-80, 0, -35,
disabled=st.session_state.recording,
help="音声を「無音」と判断する音量レベルを設定します。\n"
"値が小さいほど(例:-50dB)より小さな音も「音声あり」と判断します。\n"
"値が大きいほど(例:-20dB)大きな音のみを「音声あり」と判断します。"
)
min_silence_duration = st.sidebar.slider(
"最小無音時間 (ms)",
100, 500, 200,
disabled=st.session_state.recording,
help="この時間以上の無音が続いた場合に「無音区間」と判断します。\n"
"短すぎると話の途中の短い間も無音と判断され、\n"
"長すぎると長めの間も音声の一部と判断されます。"
)
# 録音設定
st.sidebar.title("録音設定")
auto_stop_duration = st.sidebar.slider(
"無音検出時の自動停止 (ms)",
100, 2000, 1000,
disabled=st.session_state.recording,
help="この時間以上の無音が続くと、自動的に録音を停止します。\n"
"話者の発話が終わったことを検出するための設定です。\n"
"短すぎると話の途中で録音が止まり、長すぎると無駄な無音時間が録音されます。"
)
min_recording_duration = st.sidebar.slider(
"最低録音時間 (秒)",
1, 10, 2,
disabled=st.session_state.recording,
help="録音を保存する最低限の長さを設定します。\n"
"これより短い録音は無視されます。\n"
"短すぎると雑音なども録音されやすく、長すぎると短い返事なども無視されます。"
)
with st.sidebar:
language = st.selectbox(
"言語",
["ja", "en" ,"zh"],
index=0,
disabled=st.session_state.recording,
help="音声認識に使用する言語を選択します。"
)
if st.button("initial prompt/文字起こし履歴のリセット",type="primary",disabled=st.session_state.recording):
st.session_state.full_text = ()
status_placeholder = st.empty()
chart_placeholder = st.empty()
rec_status_placeholder = st.empty()
transcription_placeholder = st.empty()
# 過去の音声データを保持するバッファ
sound_window_len = 5000 # 5秒
sound_window_buffer = None
# 一時ファイルへの保存とオーディオプレーヤーの表示
# 非同期関数として実装し、UIのブロッキングを防止
async def save_and_display_audio(audio_segment):
# 録音時間のチェック - 短すぎる録音は処理しない
recording_duration = len(audio_segment) / 1000.0 # ミリ秒から秒に変換
if recording_duration < st.session_state.get('min_recording_duration', min_recording_duration):
# 最低録音時間未満の場合は処理を中断
rec_status_placeholder.empty()
return
rec_status_placeholder.success("サーバーへ送信!!",icon=":material/check_circle:")
# 一時ファイルの作成 - システムの一時ディレクトリに保存
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix='.wav')
temp_file_path = temp_file.name
temp_file.close()
# 音声ファイルの保存 - 非同期処理で実行してUIブロッキングを防止
await asyncio.to_thread(audio_segment.export, temp_file_path, format="wav")
# 以前の一時ファイルがあれば削除 - リソースリークを防止
if st.session_state.temp_audio_file and os.path.exists(st.session_state.temp_audio_file):
try:
await asyncio.to_thread(os.unlink, st.session_state.temp_audio_file)
except Exception as e:
logger.warning(f"一時ファイルの削除に失敗: {e}")
# 新しい一時ファイルのパスを保存
st.session_state.temp_audio_file = temp_file_path
# メモリ効率化: オーディオセグメントをコピーする代わりに参照を保存
st.session_state.recorded_audio = audio_segment
# 録音後に不要なバッファをクリア - メモリ使用量を削減
global sound_window_buffer
sound_window_buffer = None
# GCを強制的に実行してメモリを解放 - 大きな音声データを扱うため必要なケースがある
import gc
gc.collect()
try:
# 音声認識APIへのリクエスト送信
# ファイルを開いてバイナリモードで読み込む
with open(temp_file_path, 'rb') as audio_file:
response = requests.post(
"http://XXX.XXX.XXX:XXXX/transcribe", # 音声認識APIのエンドポイント
files={"audio": ('audio.wav', audio_file, 'audio/wav')},
data={"model": "汎用モデル", "save_audio": False, "file_name": "temp_audio.wav","language" : language,
"initial_prompt": "\n".join(st.session_state.full_text) if st.session_state.full_text else ""}
)
# レスポンスのステータスコードを確認
if response.status_code == 200:
try:
json_data = response.json()
if "full_text" in json_data:
full_text = json_data['full_text']
# 文字列の先頭に追加(新しいテキストが上に表示される)
st.session_state.full_text = (full_text,) + st.session_state.full_text
else:
st.markdown(f"**APIレスポンス:**\n{json_data}")
except ValueError:
st.error(f"レスポンスをJSONとして解析できません: {response.text[:100]}...")
else:
st.error(f"APIエラー: ステータスコード {response.status_code}")
st.code(response.text[:200]) # エラーメッセージの最初の部分を表示
except Exception as e:
st.error(f"APIリクエストエラー: {str(e)}")
logger.error(f"API通信中にエラーが発生: {e}", exc_info=True)
# APIを使用した場合
# with open(temp_file_path, 'rb') as audio_file:
# client = OpenAI()
# response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
# full_text = response.text
# st.session_state.full_text = (full_text,) + st.session_state.full_text
# セッション状態に最低録音時間を保存
st.session_state.min_recording_duration = min_recording_duration
transcription_placeholder.markdown("\n".join(st.session_state.full_text) if st.session_state.full_text else "")
# 最後に音が検出された時間を記録
last_sound_time = time.time()
no_sound_duration = 0
# 呼び出し側の関数も非同期にする
async def process_audio():
await save_and_display_audio(st.session_state.capture_buffer)
# 非同期関数を実行するためのヘルパー関数
# Streamlitの実行環境では非同期処理の扱いが複雑なため、この関数で適切に管理する
def run_async(async_func):
import asyncio
try:
# 既存のループを取得 - すでに実行中のループがあれば活用
loop = asyncio.get_event_loop()
if loop.is_running():
# すでに実行中の場合は、future/taskとして追加
# 別スレッドで実行中のループに新しいタスクを安全に追加
future = asyncio.run_coroutine_threadsafe(async_func, loop)
return future.result()
else:
# ループが存在するが実行中でない場合
return loop.run_until_complete(async_func)
except RuntimeError:
# ループが存在しない場合は新規作成 - 初回実行時など
new_loop = asyncio.new_event_loop()
asyncio.set_event_loop(new_loop)
try:
return new_loop.run_until_complete(async_func)
finally:
# ループをクローズする前に保留中のタスクを完了させる
# リソースリークを防止するための重要な後処理
pending = asyncio.all_tasks(new_loop)
for task in pending:
task.cancel()
new_loop.run_until_complete(asyncio.gather(*pending, return_exceptions=True))
new_loop.close()
# オーディオ処理のメインループを非同期関数化
async def process_audio_stream(webrtc_ctx):
sound_window_buffer = None
while True: # メインループ - WebRTCストリームから音声を継続的に処理
if webrtc_ctx.audio_receiver:
try:
# タイムアウト付きでフレームを取得 - ブロッキングを防止
audio_frames = webrtc_ctx.audio_receiver.get_frames(timeout=1)
except queue.Empty:
logger.warning("Queue is empty. Abort.")
break
# 受信した音声フレームを処理しchunkを作成
sound_chunk = pydub.AudioSegment.empty()
for audio_frame in audio_frames:
sound = pydub.AudioSegment(
data=audio_frame.to_ndarray().tobytes(),
sample_width=audio_frame.format.bytes,
frame_rate=audio_frame.sample_rate,
channels=len(audio_frame.layout.channels),
)
sound_chunk += sound
if len(sound_chunk) > 0:
# 音声バッファの管理 - 指定サイズの履歴を保持
if sound_window_buffer is None:
sound_window_buffer = sound_chunk
else:
sound_window_buffer += sound_chunk
# バッファが指定の長さを超えたら、古い部分を削除(スライディングウィンドウ)
if len(sound_window_buffer) > sound_window_len:
sound_window_buffer = sound_window_buffer[-sound_window_len:]
# 現在の音量レベル計算
current_db = sound_chunk.dBFS if len(sound_chunk) > 0 else -100
# 音量履歴の更新とグラフ表示
st.session_state.volume_history.append({"音量": current_db})
if len(st.session_state.volume_history) > 100:
st.session_state.volume_history.pop(0) # 100ポイントに制限
# データがリスト形式の場合、DataFrameに変換
df = pd.DataFrame(st.session_state.volume_history)
df = df.reset_index().rename(columns={"index": "時間"})
# x軸 (時間) を非表示にする設定
chart = alt.Chart(df).mark_line().encode(
x=alt.X("時間", axis=None), # x軸を非表示にする
y=alt.Y("音量", title="音量 (dB)")
).properties(
height=200,
width='container'
)
# st.altair_chart の代わりにプレースホルダーを使って更新
chart_placeholder.altair_chart(chart, use_container_width=True)
# 無音部分の検出と状態管理
if sound_window_buffer:
if len(sound_chunk) > 0:
silence_info = f"\n現在の音量: {current_db:.2f} dB"
# 音量に応じて状態を表示と録音制御の判断
if current_db <= silence_threshold: # 無音状態
status_placeholder.info("無音状態です",icon=":material/sentiment_calm:")
if st.session_state.is_capturing:
no_sound_duration += len(sound_chunk) # 無音継続時間を計測
# 録音中だが音声キャプチャしていない場合のメッセージを表示
elif st.session_state.recording and not st.session_state.is_capturing:
rec_status_placeholder.info("音声の入力を待っています",icon=":material/sentiment_calm:")
else: # 音声検出状態
status_placeholder.success("音声を検出しています",icon=":material/check_circle:")
no_sound_duration = 0 # 無音継続時間をリセット
# 録音開始ロジック - 音声検出時に自動的にキャプチャ開始
if st.session_state.recording and not st.session_state.is_capturing:
st.session_state.is_capturing = True
st.session_state.capture_buffer = pydub.AudioSegment.empty()
rec_status_placeholder.warning("音声をキャプチャ中...",icon=":material/mic:")
# 情報を表示
silence_info_placeholder.text(silence_info)
# 録音バッファ更新と自動停止ロジック
if st.session_state.recording and st.session_state.is_capturing:
st.session_state.capture_buffer += sound_chunk
# 無音状態が一定時間続いた場合の自動停止処理
if no_sound_duration >= auto_stop_duration:
st.session_state.is_capturing = False
if len(st.session_state.capture_buffer) > 0:
await process_audio() # 録音データの処理と音声認識
no_sound_duration = 0
else:
# WebRTC接続待機状態
status_placeholder.warning("音声の受信を待っています...",icon=":material/pending:")
time.sleep(0.1)
if st.session_state.full_text:
transcription_placeholder.markdown("\n".join(st.session_state.full_text) if st.session_state.full_text else "")
# メインループを非同期で開始する
run_async(process_audio_stream(webrtc_ctx))
# アプリケーション終了時の一時ファイル削除
if st.session_state.temp_audio_file and os.path.exists(st.session_state.temp_audio_file):
try:
os.unlink(st.session_state.temp_audio_file)
except Exception as e:
logger.warning(f"一時ファイルの削除に失敗: {e}")
文字起こしサーバー
server.py
from flask import Flask, request, jsonify
import logging
logging.basicConfig(level=logging.DEBUG)
import re
app = Flask(__name__)
from faster_whisper import WhisperModel
# グローバル変数としてモデルを初期化
# whisper_model = WhisperModel("turbo", device="cuda", compute_type="float16")
whisper_model = WhisperModel("large-v3", device="cuda", compute_type="float16")
def convert_seconds(seconds):
minutes = seconds // 60
remaining_seconds = seconds % 60
return f"{int(minutes)}分{int(remaining_seconds)}秒"
@app.route('/transcribe', methods=['POST'])
def transcribe():
model = whisper_model
try:
audio_file = request.files['audio']
file_name = request.form['file_name']
initial_prompt = request.form['initial_prompt']
language = request.form['language']
audio_file.save(file_name)
segments, info = model.transcribe(file_name,
language = language,
beam_size = 5,
task = "transcribe",
vad_filter=True,
without_timestamps = True,
initial_prompt = initial_prompt
)
full_text=""
time_line=""
segment_before=""
for segment in segments:
sentences = re.split('(?<=[。?!、])', segment.text)
seen_sentences = set()
cleaned_sentences = []
for sentence in sentences:
if sentence not in seen_sentences:
cleaned_sentences.append(sentence)
seen_sentences.add(sentence)
cleaned_text = ''.join(cleaned_sentences)
if not cleaned_text==segment_before:
time_line+="[%s -> %s] %s" % (convert_seconds(segment.start), convert_seconds(segment.end), cleaned_text)+" \n"
full_text+=cleaned_text+"\n"
segment_before=cleaned_text
result = {
"language": info.language,
"language_probability": info.language_probability,
"time_line":time_line,
"full_text":full_text
}
return result
except Exception as e:
return str(e), 500
if __name__ == "__main__":
app.run(host="0.0.0.0", port=XXXX, debug=False)
実行
streamlit run app.py
python server.py
*whisperのAPI使うなら文字起こしサーバーを建てる必要はありません。
フロー
以下のようなフローになります。
- 音声キャプチャ
- 音量分析
- 無音/有音検出
- 録音制御
- 音声データ保存
- API送信
- 結果表示
このアプリは、ユーザーが話し始めると自動的に録音を開始し、話し終わると自動的に録音を停止して音声認識を行い、結果を画面に表示するという、ハンズフリーで使える直感的な音声文字起こしツールとして機能します。
フローチャート
1. 音声キャプチャ
ウェブブラウザから音声を取得するのは意外と大変!でも、streamlit_webrtcライブラリを使えば簡単にできちゃいます。まずは音声をキャプチャする部分から見ていきましょう。
# WebRTCの設定
webrtc_ctx = webrtc_streamer(
key="sendonly-audio", # 識別子(名前のようなもの)
mode=WebRtcMode.SENDONLY, # 送信専用モード
audio_receiver_size=256, # バッファサイズ
rtc_configuration={
"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}],
"iceTransportPolicy": "all",
},
media_stream_constraints={"audio": True}, # 音声のみ有効化
)
このコードで何が起きているかというと:
- webrtc_streamerがブラウザのマイクにアクセスするためのコンポーネントを作成
- mode=WebRtcMode.SENDONLYでユーザーからサーバーへの一方通行の通信を設定
- media_stream_constraints={"audio": True}で音声だけを取得するように指定
次に、取得した音声データを処理する部分を見てみましょう:
if webrtc_ctx.audio_receiver:
try:
# 音声フレームを取得
audio_frames = webrtc_ctx.audio_receiver.get_frames(timeout=1)
except queue.Empty:
logger.warning("Queue is empty. Abort.")
break
# 音声フレームを処理して使いやすい形に変換
sound_chunk = pydub.AudioSegment.empty()
for audio_frame in audio_frames:
sound = pydub.AudioSegment(
data=audio_frame.to_ndarray().tobytes(),
sample_width=audio_frame.format.bytes,
frame_rate=audio_frame.sample_rate,
channels=len(audio_frame.layout.channels),
)
sound_chunk += sound
ここでのポイントは:
- webrtc_ctx.audio_receiver.get_frames()でマイクからの音声データを取得
- 取得したデータは「フレーム」という小さな音声の断片の集まり
- それぞれのフレームをpydub.AudioSegmentに変換して扱いやすくする
- sound_chunkに音声データを蓄積していく
シンプルに言うと、このコードはあなたのブラウザのマイクから音声を拾って、それをPythonで処理できる形に変換しているんです!次のセクションでは、この取得した音声データをどうやって分析するのか見ていきましょう🎤
2. 音量分析
音声をキャプチャしたら、次はその音の大きさ(音量)を分析してみましょう!これができると「今話しているかどうか」がわかるようになります。
# セッション状態の初期化(アプリを起動したときに一度だけ実行)
if 'volume_history' not in st.session_state:
st.session_state.volume_history = [] # 音量履歴をリストで保存
# 現在の音量レベル計算
current_db = sound_chunk.dBFS if len(sound_chunk) > 0 else -100
# 音量履歴の更新
st.session_state.volume_history.append({"音量": current_db})
if len(st.session_state.volume_history) > 100:
st.session_state.volume_history.pop(0) # 100ポイントに制限
ここでのポイントは:
- sound_chunk.dBFSで音の大きさをデシベル(dB)という単位で取得
- デシベル値は「0に近いほど大きな音」「マイナスが大きいほど小さな音」を表す
- 音量の履歴を保存して、後でグラフにする準備をしている
- 履歴は100ポイントまでに制限して、メモリを節約
そして次に、取得した音量データをリアルタイムでグラフ表示する部分です:
# データをPandasのDataFrameに変換
df = pd.DataFrame(st.session_state.volume_history)
df = df.reset_index().rename(columns={"index": "時間"})
# グラフの設定
chart = alt.Chart(df).mark_line().encode(
x=alt.X("時間", axis=None), # x軸を非表示
y=alt.Y("音量", title="音量 (dB)")
).properties(
height=200,
width='container'
)
# グラフを表示
chart_placeholder.altair_chart(chart, use_container_width=True)
このコードは:
- 保存した音量データをPandasの「DataFrame」という形式に変換
- Altairというライブラリを使って、きれいな折れ線グラフを作成
- chart_placeholderというあらかじめ用意しておいた場所にグラフを表示
- use_container_width=Trueで、画面の幅に合わせてグラフのサイズを調整
このおかげで、マイクに入ってくる音の大きさがリアルタイムで視覚化されます!声を出したときにグラフがピョンと跳ね上がり、静かなときには下がっていくのが見えるはずです📊
次のセクションでは、この音量データを使って「話しているとき」と「静かなとき」をどうやって区別するのか見ていきましょう!
3. 無音/有音検出
音量データが取れたら、次は「今話している?それとも静か?」を判定する機能を作りましょう。これが無音/有音検出の核心部分です!
まずは、ユーザーが調整できるパラメータをサイドバーに設定します:
# サイドバーに無音検出の設定を追加
st.sidebar.title("無音検出設定")
silence_threshold = st.sidebar.slider(
"無音しきい値 (dB)",
-80, 0, -35,
help="音声を「無音」と判断する音量レベルを設定します。\n"
"値が小さいほど(例:-50dB)より小さな音も「音声あり」と判断します。\n"
"値が大きいほど(例:-20dB)大きな音のみを「音声あり」と判断します。"
)
min_silence_duration = st.sidebar.slider(
"最小無音時間 (ms)",
100, 500, 200,
help="この時間以上の無音が続いた場合に「無音区間」と判断します。"
)
ここでは2つの重要な値を設定しています:
- 無音しきい値: この値より小さい音量は「無音」と判断(-35dBがデフォルト)
- 最小無音時間: この時間以上の無音が続いたら「無音区間」と判断
次に、実際に音量を判定して状態を更新する部分を見てみましょう:
# 現在の音量と閾値を比較
if current_db <= silence_threshold: # 無音状態
status_placeholder.info("無音状態です", icon=":material/sentiment_calm:")
if st.session_state.is_capturing:
no_sound_duration += len(sound_chunk) # 無音継続時間を計測
elif st.session_state.recording and not st.session_state.is_capturing:
rec_status_placeholder.info("音声の入力を待っています", icon=":material/sentiment_calm:")
else: # 音声検出状態
status_placeholder.success("音声を検出しています", icon=":material/check_circle:")
no_sound_duration = 0 # 無音継続時間をリセット
# 録音開始ロジック(次のセクションで詳しく説明)
# ...
ポイントはこうです:
- current_db <= silence_thresholdで「今は無音かどうか」を判定
- 無音なら「無音状態です」と表示し、無音の継続時間をカウント
- 音声があれば「音声を検出しています」と表示し、無音カウンターをリセット
- アイコンも状態に合わせて変化するので視覚的にもわかりやすい!
この判定結果は画面上のステータス表示に反映されるだけでなく、次のセクションで説明する「録音制御」にも重要な役割を果たします。ユーザーが話し始めたら自動的に録音を開始し、話し終わったら自動的に停止する仕組みの基礎になるんですね🎯
次に、この無音/有音検出を使って、どのように録音をコントロールするのか見ていきましょう!
4. 録音制御
音声を検出できるようになったら、次はその結果を使って録音をコントロールする機能を作りましょう。手動と自動、両方の方法で録音を開始・停止できます。
まずは、手動で録音をコントロールするボタン部分から見てみましょう:
# 録音開始/停止ボタンの機能
def toggle_recording():
if st.session_state.recording:
st.toast(f"**録音停止**", icon=":material/mic_off:")
else:
st.toast(f"**録音開始**", icon=":material/mic:")
st.session_state.recording = not st.session_state.recording
if not st.session_state.recording:
# 録音停止時、キャプチャも停止
st.session_state.is_capturing = False
# 録音ボタンの表示
st.button(
"録音 " + ("停止" if st.session_state.recording else "開始"),
on_click=toggle_recording,
type="primary" if st.session_state.recording else "secondary"
)
このコードはシンプルですが、いくつかの重要なポイントがあります:
- toggle_recording()関数は録音状態をオン/オフに切り替える
- ボタンのテキストは状態に応じて「録音開始」または「録音停止」に変わる
- ボタンの色も録音中なら「primary」(目立つ色)、そうでなければ「secondary」に
- 状態が変わるとトースト通知で知らせてくれる!
次に、音声検出による自動録音開始の部分を見てみましょう:
# 音声が検出されたとき(無音状態でないとき)の処理
if current_db > silence_threshold: # 音声検出状態
status_placeholder.success("音声を検出しています", icon=":material/check_circle:")
no_sound_duration = 0 # 無音継続時間をリセット
# 録音ボタンが押されているが、まだキャプチャ開始してない場合
if st.session_state.recording and not st.session_state.is_capturing:
st.session_state.is_capturing = True
st.session_state.capture_buffer = pydub.AudioSegment.empty()
rec_status_placeholder.warning("音声をキャプチャ中...", icon=":material/mic:")
ここでのポイントは:
- 音声が検出されたときに、もし録音モードなら自動的にキャプチャを開始
- キャプチャを開始すると画面上に「音声をキャプチャ中...」と表示される
- capture_bufferという空のバッファを用意して、そこに音声を貯めていく
最後に、無音検出による自動録音停止の部分です:
# 録音バッファ更新と自動停止ロジック
if st.session_state.recording and st.session_state.is_capturing:
st.session_state.capture_buffer += sound_chunk
# 無音状態が一定時間続いた場合の自動停止処理
if no_sound_duration >= auto_stop_duration:
st.session_state.is_capturing = False
if len(st.session_state.capture_buffer) > 0:
await process_audio() # 録音データの処理(次セクションで説明)
no_sound_duration = 0
この部分の重要なポイント:
- 録音中はsound_chunk(今取得した音声)をバッファに追加し続ける
- 無音状態がauto_stop_duration(サイドバーで設定した時間)より長く続くと、自動的にキャプチャを停止
- キャプチャが停止すると、録音されたデータを処理する関数process_audio()を呼び出す
これで自動音声検出と自動停止の仕組みができました!話し始めると自動的に録音が始まり、話し終わると自動的に録音が止まる便利な機能の裏側はこんな感じになっています🎤✨
次のセクションでは、録音した音声データをどうやって保存して処理するのか見ていきましょう!
5. 音声データ保存
録音が終わったら、その音声データを一時的にファイルとして保存する必要があります。これは音声認識APIに送るための準備段階です。
まずは、録音した音声を保存する関数の全体像を見てみましょう:
async def save_and_display_audio(audio_segment):
# 録音時間のチェック - 短すぎる録音は処理しない
recording_duration = len(audio_segment) / 1000.0 # ミリ秒から秒に変換
if recording_duration < st.session_state.get('min_recording_duration', min_recording_duration):
# 最低録音時間未満の場合は処理を中断
rec_status_placeholder.empty()
return
rec_status_placeholder.success("サーバーへ送信!!", icon=":material/check_circle:")
# 一時ファイルの作成と保存
temp_file = tempfile.NamedTemporaryFile(delete=False, suffix='.wav')
temp_file_path = temp_file.name
temp_file.close()
# 音声ファイルの保存 - 非同期処理で実行
await asyncio.to_thread(audio_segment.export, temp_file_path, format="wav")
# 以前の一時ファイルがあれば削除
if st.session_state.temp_audio_file and os.path.exists(st.session_state.temp_audio_file):
try:
await asyncio.to_thread(os.unlink, st.session_state.temp_audio_file)
except Exception as e:
logger.warning(f"一時ファイルの削除に失敗: {e}")
# 新しい一時ファイルのパスを保存
st.session_state.temp_audio_file = temp_file_path
# 録音データの参照を保存
st.session_state.recorded_audio = audio_segment
ちょっと長いですが、順番に見ていきましょう。
まず録音時間のチェック:
- len(audio_segment) / 1000.0で録音の長さを秒単位で計算
- 設定した最低録音時間よりも短い場合は処理しない(誤録音防止)
次に一時ファイルの作成:
- tempfile.NamedTemporaryFileでシステムの一時ディレクトリに一時ファイルを作成
- suffix='.wav'で拡張子を指定(音声ファイルだとわかるように)
- ファイル名を取得してからクローズ(後で使えるように)
そして音声の保存:
- audio_segment.exportで録音した音声を実際のファイルとして保存
- await asyncio.to_threadで非同期処理(UIがフリーズしないように)
- ファイル形式は「wav」を指定
古いファイルの削除と状態の更新:
- 前回の録音ファイルがあれば削除(ディスク容量を節約)
- 新しいファイルパスをセッション状態に保存
- 録音データ自体も参照として保存
さらに、メモリ効率化のコードもあります:
# メモリ効率化: 不要なバッファをクリア
global sound_window_buffer
sound_window_buffer = None
# GCを強制的に実行してメモリを解放
import gc
gc.collect()
これはメモリリークを防ぐための工夫です
不要になったバッファをNoneに設定して解放
ガベージコレクション(gc.collect())を実行してメモリを確実に解放
非同期処理を使うことでUIの応答性を保ちながら、バックグラウンドで音声ファイルの保存処理を行うことができます。これがasync/awaitの強みです💾✨
次のセクションでは、保存した音声ファイルを実際にAPIに送信する方法を見ていきましょう!
6. API送信
録音データをファイルとして保存できたら、次はそのファイルを音声認識APIに送信します。ローカルの文字起こしサーバーで文字起こしする場合とOpenAIのAPIを使う場合を紹介します。
ローカルサーバー方式
try:
# 音声認識APIへのリクエスト送信
with open(temp_file_path, 'rb') as audio_file:
response = requests.post(
"http://XXX.XXX.XXX.XXX:XXXX/transcribe", # 音声認識APIのエンドポイント
files={"audio": ('audio.wav', audio_file, 'audio/wav')},
data={"model": "汎用モデル", "save_audio": False, "file_name": "temp_audio.wav",
"language" : language, "initial_prompt": st.session_state.full_text}
)
# レスポンスの処理
if response.status_code == 200:
try:
json_data = response.json()
if "full_text" in json_data:
full_text = json_data['full_text']
# 文字列の先頭に追加(新しいテキストが上に表示される)
st.session_state.full_text = full_text + "\n" + st.session_state.full_text
else:
st.markdown(f"**APIレスポンス:**\n{json_data}")
except ValueError:
st.error(f"レスポンスをJSONとして解析できません: {response.text[:100]}...")
else:
st.error(f"APIエラー: ステータスコード {response.status_code}")
st.code(response.text[:200]) # エラーメッセージの最初の部分を表示
except Exception as e:
st.error(f"APIリクエストエラー: {str(e)}")
logger.error(f"API通信中にエラーが発生: {e}", exc_info=True)
http://XXX.XXX.XXX:XXXX/transcribe"はサーバーのIPアドレスを指定してください。
この方法のポイント:
指定したIPアドレスのローカルサーバーにリクエスト送信
音声ファイルと一緒に、言語設定や前回の認識結果などのパラメータも送信
レスポンスはJSON形式で返ってくるため、それを解析して表示
OpenAI API方式(オプション)
もし外部のOpenAI APIを使いたい場合は、以下のようなコードに変更できます:
# OpenAI APIを使用する場合
with open(temp_file_path, 'rb') as audio_file:
client = OpenAI()
response = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
)
full_text = response.text
st.session_state.full_text = full_text + "\n" + st.session_state.full_text
この方法のポイント:
OpenAIの公式ライブラリを使用(pip install openaiが必要)
APIキーの設定が別途必要(環境変数などで設定)
OpenAIの高精度なWhisperモデルが使える
応答形式が異なるので、JSONパースが不要で直接テキストが取得できる
選択のポイント
どちらの方法を選ぶかは以下のポイントで判断するとよいでしょう:
ローカルサーバー方式
- メリット:インターネット接続不要、低遅延、データプライバシー
- デメリット:サーバーのセットアップと維持が必要
OpenAI API方式
- メリット:セットアップが簡単、高精度な認識
- デメリット:API使用料金が発生、インターネット接続が必要
実装を切り替える場合は、該当部分のコメントを入れ替えるだけでOKです!🔄
次のセクションでは、APIから取得した認識結果をどのように表示するかを見ていきましょう!
7. 結果表示
最後に、音声認識の結果をユーザーにわかりやすく表示する部分を見ていきましょう。単に文字を表示するだけでなく、アプリの状態もリアルタイムに伝えるための工夫がたくさんあります!
テキスト表示の基本部分
# セッション状態に認識結果を保存
if "full_text" in json_data:
full_text = json_data['full_text']
# 文字列の先頭に追加(新しいテキストが上に表示される)
st.session_state.full_text = full_text + "\n" + st.session_state.full_text
# 認識結果の表示
transcription_placeholder.markdown(st.session_state.full_text)
このコードのポイント:
- APIからの応答に「full_text」がある場合、それを取得
- 新しいテキストを先頭に追加するので、最新の認識結果が常に上に表示される
- markdown形式で表示するので、改行がきれいに反映される
状態表示の仕組み
アプリには様々な「状態」があり、それぞれに応じた表示をしています:
# 録音中の状態表示
if st.session_state.recording and st.session_state.is_capturing:
rec_status_placeholder.warning("音声をキャプチャ中...", icon=":material/mic:")
elif st.session_state.recording and not st.session_state.is_capturing:
rec_status_placeholder.info("音声の入力を待っています", icon=":material/sentiment_calm:")
# 音声送信時の表示
rec_status_placeholder.success("サーバーへ送信!!", icon=":material/check_circle:")
# 音量状態の表示
if current_db <= silence_threshold: # 無音状態
status_placeholder.info("無音状態です", icon=":material/sentiment_calm:")
else: # 音声検出状態
status_placeholder.success("音声を検出しています", icon=":material/check_circle:")
いくつかのポイント:
- placeholderを使うことで、同じ場所に異なる情報を「上書き」表示できる
- info、success、warningなどでメッセージの色や雰囲気を変えられる
- アイコンを使って視覚的にも状態がわかりやすい
リアルタイムグラフと音量レベル表示
# データフレームの作成とグラフ表示
df = pd.DataFrame(st.session_state.volume_history)
chart = alt.Chart(df).mark_line().encode(
x=alt.X("時間", axis=None),
y=alt.Y("音量", title="音量 (dB)")
).properties(
height=200,
width='container'
)
chart_placeholder.altair_chart(chart, use_container_width=True)
# 現在の音量も数値で表示
silence_info = f"\n現在の音量: {current_db:.2f} dB"
silence_info_placeholder.text(silence_info)
このグラフ表示のポイント:
- リアルタイムで音量の変化がわかるグラフ
- 横幅はコンテナに合わせて自動調整
- 数値でも現在の音量を確認できる
サイドバーでの初期設定とリセット機能
with st.sidebar:
language = st.selectbox(
"言語",
["ja", "en" ,"zh"],
index=0,
help="音声認識に使用する言語を選択します。"
)
if st.button("initial promptのリセット", type="primary"):
st.session_state.full_text = ""
このコードでは:
- サイドバーに言語選択メニューを配置
- 日本語、英語、中国語から選べる
- 「initial promptのリセット」ボタンで認識結果をクリアできる
initial_promptとlanguageパラメータ
ローカルサーバーでの文字起こし処理では、initial_promptとlanguageという重要なパラメータを使用しています。これらの設定がどのように機能するのか詳しく見てみましょう:
# ローカルサーバーのWhisperモデルへ渡されるパラメータ
segments, info = model.transcribe(file_name,
language = language,
beam_size = 3,
task = "transcribe",
vad_filter=True,
without_timestamps = True,
initial_prompt = initial_prompt
)
language パラメータ
with st.sidebar:
language = st.selectbox(
"言語",
["ja", "en" ,"zh"],
index=0,
help="音声認識に使用する言語を選択します。"
)
このパラメータの役割:
音声で話されている言語を指定("ja"=日本語、"en"=英語、"zh"=中国語)
言語を明示的に指定することで認識精度が向上
設定しない場合、モデルは音声の最初の30秒から言語を自動検出しようとする
特に短い音声や複数の言語が混ざる場合に言語を指定すると効果的
initial_prompt パラメータ
# APIリクエストのパラメータに含まれる
data={"model": "汎用モデル", "save_audio": False, "file_name": "temp_audio.wav",
"language" : language, "initial_prompt": st.session_state.full_text}
このパラメータの役割:
- 文字起こしの「ヒント」として機能する初期テキスト
- 前回までの認識結果を提供することで、文脈を維持できる
- 専門用語や固有名詞の認識精度を向上させる効果がある
- 長い会話の場合、前後の文脈を理解してより自然な文字起こしができる
以上の表示方法を組み合わせることで、ユーザーは直感的にアプリの状態を理解し、音声認識の結果をスムーズに確認できます。画面上のさまざまな場所に配置された情報が、ユーザー体験を大きく向上させているんですね!📊🎤📝
これで一通りのコード解説は完了です。このアプリはStreamlitの特徴を活かした、シンプルながらも機能的な音声認識システムです。ぜひ自分なりにカスタマイズして、オリジナルの音声アプリを作ってみてください!
まとめ
今回のエンジニアリングブログでは、Streamlitを使ったリアルタイム音声認識アプリの内部構造を解説しました。このアプリがどのように動作しているのか、一連のフローを振り返ってみましょう:
全体の流れ
- 音声キャプチャ:WebRTCを使ってブラウザからリアルタイムで音声を取得
- 音量分析:取得した音声の音量レベルを計算してグラフ表示
- 無音/有音検出:設定した閾値に基づいて話し声と無音を区別
- 録音制御:音声検出による自動録音開始と無音検出による自動停止
- 音声データ保存:録音データを一時ファイルとして保存
- API送信:保存した音声ファイルを音声認識APIに送信
- 結果表示:認識結果と各種状態をリアルタイムに表示
使われている主要技術
- Streamlit:直感的なウェブアプリケーションフレームワーク
- WebRTC:ブラウザでのリアルタイム通信技術
- Pydub:Pythonでの音声処理ライブラリ
- Asyncio:非同期処理によるスムーズなUI体験
- Altair:データの視覚化ライブラリ
- Whisper:高精度な音声認識モデル(ローカルまたはOpenAI API)
このアプリケーションの特長
- ユーザーフレンドリーな設定:サイドバーでの直感的なパラメータ調整
- 視覚的フィードバック:音量グラフや状態表示によるリアルタイム情報
- 柔軟な認識オプション:ローカルサーバーとOpenAI APIの両方に対応
- 文脈を考慮した認識:前回の認識結果を活用した高精度な文字起こし
- 自動録音制御:ユーザーの発話を自動検出して録音と停止を制御
おわりに
このアプリは、比較的シンプルなコードで高度な音声認識機能を実現しています。Streamlitの強力な機能と、Pythonの豊富なライブラリを組み合わせることで、専門的な知識がなくても実用的なアプリケーションを作ることができます。
ぜひこのコードをベースに、自分だけのカスタマイズを加えてみてください。例えば認識結果の自動要約、感情分析、自動翻訳機能など、アイデア次第でさらに便利なツールに発展させることができるでしょう。
音声データは情報の宝庫です。このアプリケーションが、あなたの音声認識プロジェクトの出発点になれば幸いです!🎤✨
Happy Coding!
参考記事
Discussion