Streamlit+FastAPI+Whisperで社内オンプレ文字起こしサーバーを構築(非同期処理)
アプリの構成と概要
前回の記事ではシンプルな音声ファイル文字起こしアプリを作成しました。
このアプリは同期処理と言われるもので文字起こし開始してから文字起こし完了するまでユーザー側は何もできません。
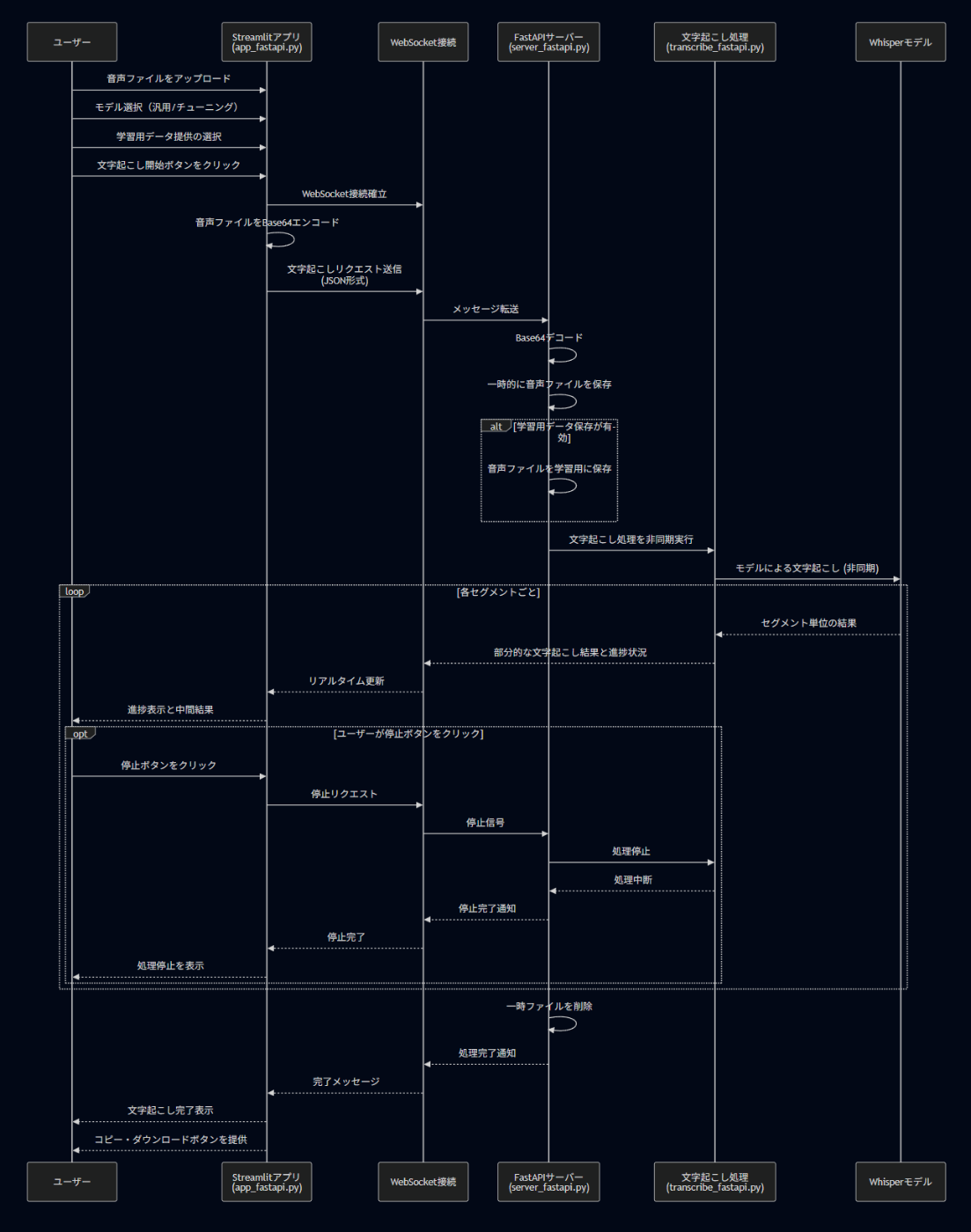
本記事では前回記事のアプリをベースに非同期処理を取り入れ、文字起こし途中の結果確認、進捗度確認、途中停止機能を実装させたものになります。
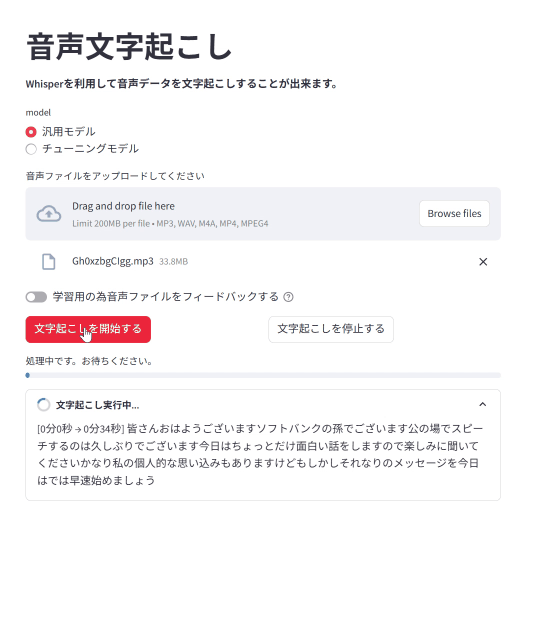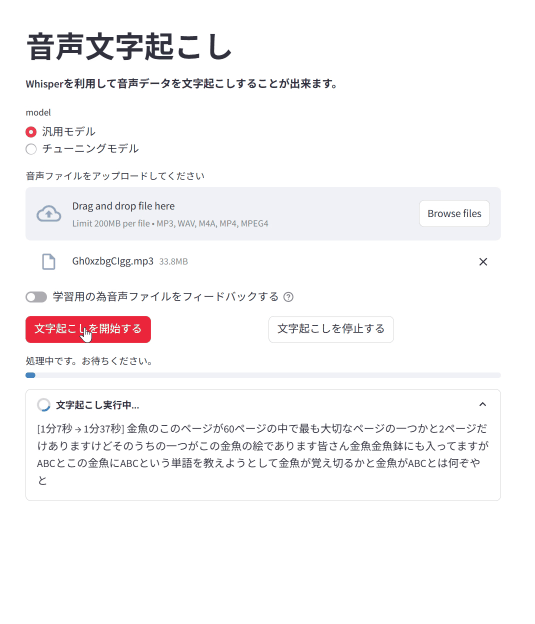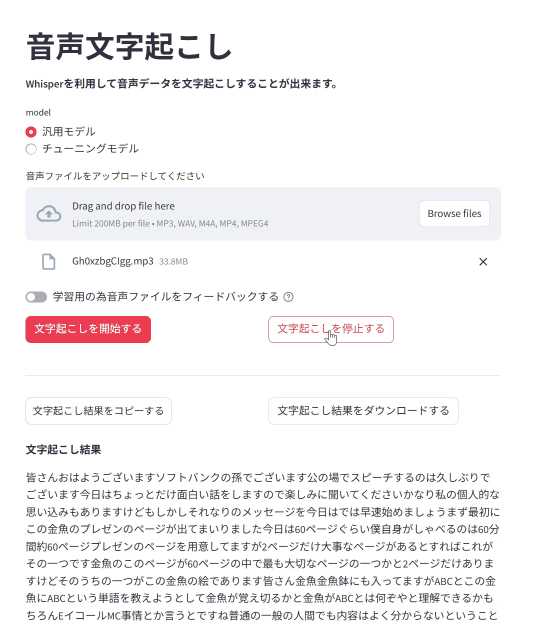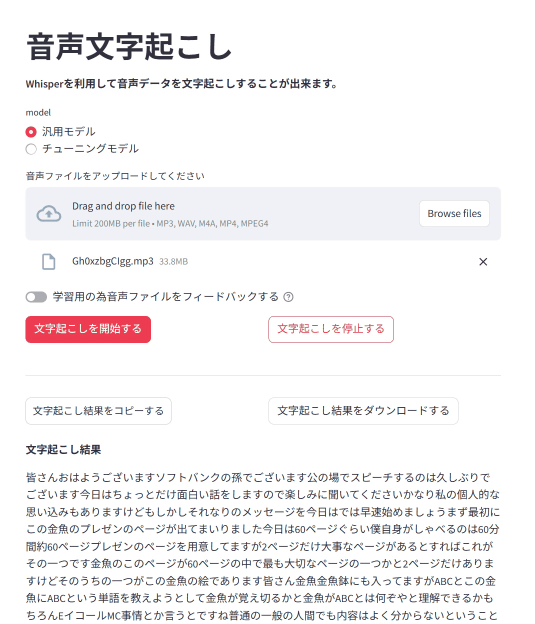
*ソフトバンク孫さんの金魚のスピーチです。いつもありがとうございます。
同期処理と非同期処理の違いって?
同期処理は、自分で掃除機をかけているようなものです。掃除が終わるまで他の作業はできません。
一方、非同期処理は、ロボット掃除機にお掃除を任せるようなイメージです。ロボット掃除機が動いている間、他の家事(例えば洗濯物をたたむなど)を進めることができます!個人的にロボット掃除機は人生買ってよかったものランキングトップ5に入ります。
このように、時間のかかる処理を「バックグラウンドで」動かしながら、他の作業を進められるのが非同期処理の強みです。今回のアプリでは、文字起こしという時間のかかる処理を非同期で行うことで、処理中もユーザーが他の操作(例えば停止ボタンを押すなど)ができるようになっています。

この記事では、以下の3つのコードを用いた構成について紹介していきます。
-
app_fastapi.pyアプリ -
server_fastapi.pyサーバー -
transcribe_fastapi.pyサーバーから呼び出される文字起こし機能
✨ app_fastapi.pyの概要
音声ファイルをアップロードし、そのデータをWebSocket経由でサーバーに送信、whisperによる文字起こし結果をリアルタイムで受信・表示するアプリケーションとなっています。
▶ 全体像
このアプリは以下の3層で構成されています:
- 通信層(WebSocket):音声ファイルのエンコードと送信、逐次的な結果の受信処理
- 非同期制御層(asyncio + threading):複数のタスクを安全に制御、グローバル状態の共有
- UI層(Streamlit):音声ファイルアップロードやボタン操作、文字起こし結果の表示を担う
🔗 1. 通信層(WebSocket) WebSocketManagerクラスの作成
WebSocketは、サーバーとアプリが常に会話できる専用の回線のようなものです。
このクラスは電話のような役割をして、以下のことをやってくれます:
- 接続を覚えておく:一度サーバーとつないだら、その接続を保存しておく
- 安全に使える:複数の処理が同時に接続を使っても混乱しないように鍵(Lock)を使う
- タイムアウト対策:サーバーが応答しなくなったときに、ずっと待ちぼうけにならないようにする
- 丁寧な終了:電話を切るときに「さようなら」と言うように、サーバーにも終了を伝えてから接続を閉じる
これによって、複雑なサーバー通信がとても簡単になり、アプリがより安定して動くようになります。
サーバーとの通信をもっと簡単に扱うために、WebSocketを管理する専用のクラスを作成しています。:
class WebSocketManager:
def __init__(self):
self.websocket = None
self.lock = threading.Lock()
async def connect(self):
# サーバーに接続する関数
async def send(self, message):
# メッセージを送る関数
async def close(self):
# きれいに接続を閉じる関数
🔄 2. 非同期制御層(asyncio + threading) 非同期関数(async)とイベントループ
pythonのasync defで定義された関数は「一旦待って他の処理を先に進められる」便利な関数です。時間のかかる処理(例:音声ファイルの送受信)でアプリが止まらないようにしてくれます。
async def transcribe(model, save_audio, audio_file_path):
# サーバーに接続して音声を送信し、結果を受信する関数
このような非同期関数を動かすには「イベントループ」が必要で、次のようにして実行します:
loop = asyncio.new_event_loop()
loop.run_until_complete(transcribe(...))
このようにすることで、音声送信・受信などをアプリが止まらずスムーズに処理できます。
💡 Streamlitで非同期処理を動かす工夫
Streamlitでは直接awaitを使った非同期処理がうまく動かないことがあります。そのため、以下のように別スレッドでイベントループを動かす工夫をしています:
def process_transcription(model, button_save_audio, audio_file_path):
asyncio.run(transcribe(model, button_save_audio, audio_file_path))
この関数はStreamlitのボタンクリックから呼び出され、内部でasyncio.run()を使って非同期処理を開始します。これによって、Streamlitのボタンと非同期処理の世界をうまくつなぐことができます。
🔄 状態管理でユーザー体験を向上
文字起こしアプリでは、「処理中」「完了」「停止中」などの状態を管理することが重要です。session_stateを使って、これらの状態を効率的に管理する仕組みを実装しています。:
# セッション状態の初期化
if 'full_text_transcribe' not in st.session_state:
st.session_state.full_text_transcribe = "" # 文字起こし結果の全文
if 'done_event' not in st.session_state:
st.session_state.done_event = asyncio.Event() # 文字起こし完了イベント
if 'stop_event' not in st.session_state:
st.session_state.stop_event = asyncio.Event() # 文字起こし停止イベント
if 'server_status' not in st.session_state:
st.session_state.server_status = False # サーバー接続状態
asyncio.Eventは「文字起こしが完了したよ!」「今すぐ停止して!」という合図を非同期処理の間で伝えることができます。
たとえば停止ボタンが押されたときは:
if trans_stop:
st.session_state.stop_event.set() # 停止フラグを立てる
# ここでWebSocketを閉じる処理などを行う
そして非同期処理の中では:
async for message in websocket:
if st.session_state.stop_event.is_set():
break # 停止フラグが立っていたらループを抜ける
# 通常の処理を続行...
このようにして、ユーザーの操作(ボタンクリックなど)と裏側で動いている非同期処理が連携できるようにしています。
💻 3. UI層(Streamlit)
UIは以下のような構成です:
# ファイルアップロード
uploaded_file = st.file_uploader("音声ファイルをアップロードしてください")
# モデルの選択 *ファインチューニングモデルを用意するなら
model = st.radio("model", ["汎用モデル", "チューニングモデル"])
#文字起こし開始ボタン
trans_start = st.button("文字起こしを開始する")
#文字起こし停止ボタン
trans_stop = st.button("文字起こしを停止する")
# 進捗バー
st.session_state.progress_bar = st.progress(0)
# 途中結果表示
transcribe_result = st.empty()
🔘 trans_startとtrans_stop
-
trans_startボタンを押すと、start_transcription()が呼ばれて文字起こしが始まります。 -
trans_stopボタンは、st.session_state.stop_event.set()を通じて処理を止め、WebSocketの切断などを行います。
if trans_start:
process_transcription(model, button_save_audio, audio_file_path)
if trans_stop:
st.session_state.stop_event.set()
close_websocket()
📊 progress_barと📄 transcribe_result
文字起こし中は画面上に進捗バーと結果の表示欄が表示されます:
st.session_state.progress_bar = st.progress(0)
transcribe_result = st.empty()
-
progress_bar:サーバーから送られてくる進捗情報(0〜100)に応じてバーが伸びていきます。 -
transcribe_result:途中経過のタイムラインがここにリアルタイムで表示され、処理が終わると全文がst.session_state.full_text_transcribeに格納されます。
✅ まとめ
app_fastapi.pyは、WebSocketを活用した非同期通信と直感的なStreamlit UIを組み合わせた、音声文字起こしアプリのフロントエンドです。主な特徴として:
- リアルタイム処理:WebSocketによる双方向通信で、途中経過をリアルタイムに表示
- 非同期処理:asyncioとthreadingを駆使し、時間のかかる処理中もアプリが固まらない設計
- 状態管理:session_stateとasyncio.Eventを使った効率的な状態管理
- ユーザー制御:処理の停止や進捗確認など、ユーザーに制御権を与える設計
これらの要素が組み合わさることで、大きな音声ファイルでも快適に文字起こしができるアプリケーションを実現しています。
⚙️ server_fastapi.pyの概要
▶ 全体像
このサーバーは、文字起こしアプリのバックエンド部分を担当するFastAPIベースのWebSocketサーバーです。以下の主要コンポーネントで構成されています:
-
WebSocketエンドポイント (
/ws) - クライアントとの双方向通信を管理 - セッション管理システム - 複数のクライアント接続を個別に追跡
- リクエストハンドラ関数 - 文字起こしと停止要求を処理
- エラー処理メカニズム - 接続切断などに対応する例外処理
- 一時ファイル管理 - 音声データの安全な保存と処理
処理フローとしては、クライアントから受け取ったBase64音声データを一時ファイルとして保存し、文字起こし処理を実行、結果をリアルタイムで返送する流れとなっています。
🔁 1. WebSocketのエンドポイント
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept() # WebSocket接続を受け入れる
session_id = id(websocket) # セッションIDを作成
sessions[session_id] = {'stop': False} # 新しいセッションを初期化
logging.info('Client connected')
try:
while True:
# クライアントからJSONメッセージを受信
data = await websocket.receive_json()
# メッセージのタイプに応じて処理を分岐
if data.get("type") == "transcribe":
await handle_transcribe(websocket, data, session_id)
elif data.get("type") == "stop":
await handle_stop(websocket, session_id)
break # 停止リクエスト後にループを抜ける
except WebSocketDisconnect:
# 切断された場合の処理
logging.info(f"WebSocket disconnected for session {session_id}")
# その他の例外処理...
finally:
# 終了時のクリーンアップ
await cleanup_session(session_id)
この関数は、クライアントとのWebSocket通信の入り口です。接続を受け入れたあと、クライアントからのメッセージ(音声データやコマンド)を待ち受け続けます。受け取った内容に応じて処理が分岐されます。
セッションIDという「会話の識別番号」を作成し、クライアントとの通信状態を管理します。これにより、複数のユーザーが同時に文字起こしを行っても混乱しないようになっています。
🔎 2. クライアントからのデータ
クライアントからのデータはJSON形式になっており、例えば次のような構造になっています:
{
"type": "transcribe",
"audio": "base64でエンコードされた音声データ",
"model": "汎用モデル",
"save_audio": true,
"file_name": "temp.wav"
}
関数 handle_transcribe
この関数は文字起こしリクエストを処理します。主に次のことを行います:
- クライアントから送られた音声データ(Base64形式)をデコードする
- 一時ファイルとして保存する
- 文字起こし処理を実行する
- 結果をクライアントに返す
async def handle_transcribe(websocket: WebSocket, data: dict, session_id: int):
temp_file_path = None
try:
# クライアントからのデータを取得
audio_base64 = data['audio']
model = data['model']
save_audio = data['save_audio']
file_name = data['file_name']
# Base64データをデコードして音声ファイルに変換
audio_file = base64.b64decode(audio_base64)
# 一時ファイルに保存
temp_dir = tempfile.gettempdir()
temp_file_path = os.path.join(temp_dir, os.path.basename(file_name))
with open(temp_file_path, 'wb') as f:
f.write(audio_file)
# 文字起こし処理を実行
await transcribe(temp_file_path, websocket, session_id,
lambda: sessions[session_id]['stop'])
# 例外処理...
finally:
# 一時ファイルの削除
if temp_file_path and os.path.exists(temp_file_path):
os.remove(temp_file_path)
Base64エンコードとは、バイナリデータ(音声ファイル)をテキスト形式に変換する方法です。これによりWebSocketを通じて音声データを送ることができます。サーバー側では、このテキストをデコードして元の音声ファイルに戻します。
🛑 3. ストップリクエストの処理
ユーザーが「文字起こしを停止する」ボタンを押すと、次のようなストップ信号が送られます:
{
"type": "stop"
}
関数 handle_stop
この関数は停止リクエストを処理します:
async def handle_stop(websocket: WebSocket, session_id: int):
logging.info(f"Stop requested for session {session_id}")
if session_id in sessions:
sessions[session_id]['stop'] = True # 停止フラグをセット
try:
# クライアントに停止確認を送信
await websocket.send_json({'done': True, 'message': 'Transcription stopped'})
except (WebSocketDisconnect, RuntimeError) as e:
logging.info(f"Client disconnected while sending stop confirmation")
停止フラグを設定すると、文字起こし処理を行っているtranscribe関数がこのフラグをチェックして処理を中断します。
🔐 4. セッション管理とエラー処理
このサーバーでは、複数のクライアントからの接続を管理するために「セッション」という仕組みを使っています:
# セッション情報を管理する辞書
sessions = {} # {session_id: {'stop': bool}}
# セッション終了時のクリーンアップ処理
async def cleanup_session(session_id: int):
logging.info('Client disconnected')
if session_id in sessions:
sessions.pop(session_id) # セッションを削除
また、様々なエラーに対応するための「例外処理」も実装されています:
- クライアントが突然切断した場合
- 文字起こし処理でエラーが発生した場合
- 一時ファイルの処理に失敗した場合
これにより、問題が発生してもサーバーが停止せず、適切にエラーメッセージを返せるようになっています。
✅ まとめ
server_fastapi.pyは、クライアントから送られてきた音声を受け取り、非同期でリアルタイムに処理・応答するFastAPIベースのサーバーです。
主要な関数ごとに役割が分かれており:
-
websocket_endpoint:全体のコントローラ(トラフィック整理係) -
handle_transcribe:音声データを受け取り保存し、文字起こし処理を実行 -
handle_stop:文字起こし処理の停止フラグを設定 -
cleanup_session:セッション終了時のクリーンアップ
これらの関数が協力し合って、リアルタイム文字起こしを効率良く実現しています。
🔍 transcribe_fastapi.pyの概要
▶ 全体像
このファイルは、サーバー側で受け取った音声ファイルをWhisperモデルを使って処理する部分を担います。具体的には、次のような機能を持っています:
- 音声ファイルをWhisperで処理し、セグメントごとに文字起こしを行う
- タイムラインを含んだ文字列をリアルタイムでクライアントに送信
- 停止指示があれば即時中断し、処理状態を返す
- 最終的な全文結果をWebSocket経由で送信
このファイルはFastAPIのHTTPエンドポイントではなく、WebSocket経由で呼び出されるバックエンド処理を提供する非同期関数モジュールです。
🕒 1. ヘルパー関数
まず、文字起こし処理に使う便利な補助関数が2つあります:
# 秒数を「○分○秒」形式に変換する関数
def convert_seconds(seconds):
minutes = seconds // 60 # 分を計算(整数除算)
remaining_seconds = seconds % 60 # 残りの秒数
return f"{int(minutes)}分{int(remaining_seconds)}秒"
# WebSocketメッセージ送信のヘルパー関数
async def send_websocket_message(websocket, message, session_id):
try:
if websocket.client_state == WebSocketState.CONNECTED:
await websocket.send_json(message)
return True
except (WebSocketDisconnect, websockets.exceptions.ConnectionClosedOK, RuntimeError) as e:
logging.info(f"WebSocket connection issue for session {session_id}")
return False
-
convert_seconds: 秒数を「○分○秒」の形式に変換します。例えば、75秒 → 「1分15秒」になります。 -
send_websocket_message: クライアントにメッセージを安全に送信する関数です。もし接続が切れていたら、エラーを出さずに「送信失敗」を知らせてくれます。
これらのヘルパー関数は、メインの処理をシンプルに保ち、コードを読みやすくする役割を持っています。
🎙️ 2. 非同期関数 transcribe
この関数が文字起こしの本体です。
async def transcribe(audio_file, websocket: WebSocket, session_id: int, should_stop):
引数の意味:
-
audio_file: 音声ファイルのパス(どのファイルを文字起こしするか) -
websocket: クライアントとの通信に使うWebSocket(結果をリアルタイムで送るため) -
session_id: セッションの識別番号(ログ出力などで使用) -
should_stop: 「今すぐ止めてください」という指示が来たかチェックする関数
モデルの準備と文字起こし処理
model = WhisperModel("large-v3", device="cuda", compute_type="float16")
try:
# to_threadでメインスレッドをブロックしないよう実行
segments, info = await asyncio.to_thread(
model.transcribe,
audio_file,
language="ja", # 日本語を指定
beam_size=5, # ビームサイズ(精度向上のため)
vad_filter=True, # 声の検出フィルターを有効化
without_timestamps=True, # タイムスタンプなし
)
except Exception as e:
# エラー処理...
ここではasyncio.to_thread() で処理を別スレッドに分離することで、アプリが固まらないようにしています
基本情報の送信
音声ファイルを解析した基本情報をまずクライアントに送ります:
# 音声ファイルの長さを取得
audio_length = info.duration
# 文字起こし情報をクライアントに送信
message_sent = await send_websocket_message(
websocket,
{
"type": "info",
"language": info.language, # 検出された言語(例:日本語)
"language_probability": info.language_probability, # 言語検出の確信度
"length": convert_seconds(audio_length), # 音声の長さ(例:2分30秒)
"done": False
},
session_id
)
これにより、ユーザーは「この音声は日本語で、長さは○分○秒です」という情報をすぐに知ることができます。
セグメントごとの結果送信ループ
音声は複数の「セグメント」(文章単位)に分けられて処理されます。各セグメントが処理されるたびに、結果をリアルタイムで送信します:
# 文字起こし結果を格納する変数
final_text = ""
# 各セグメント(文章単位の音声)を処理
for segment in segments:
# 停止要求があった場合は処理を中断
if should_stop():
logging.info(f"Transcription stopped by request")
await send_websocket_message(
websocket,
{"type": "stopped", "done": True},
session_id
)
return
# 文字起こし結果を累積
final_text += segment.text
# タイムライン形式のテキスト(開始時間→終了時間 + テキスト)
time_line = f"[{convert_seconds(segment.start)} -> {convert_seconds(segment.end)}] {segment.text}"
# 進捗率の計算(0〜100%)
progress = 0
if audio_length > 0:
progress = int(segment.end / audio_length * 100)
# セグメント結果をクライアントに送信
message_sent = await send_websocket_message(
websocket,
{
"type": "segment",
"data": {
"time_line": time_line,
"text": segment.text
},
"progress": progress,
"done": False
},
session_id
)
# 途中で接続が切れたら処理終了
if not message_sent:
return
# 非同期処理の機会を与える(他の処理が割り込めるよう少し待つ)
await asyncio.sleep(0)
このループでは:
- 「停止ボタン」が押されていないかを毎回チェック
- 文字起こしの結果を全文用の変数に追加
- タイムライン情報(いつからいつまでの発言か)を作成
- 進捗率(何%完了したか)を計算
- それらの情報をクライアントにリアルタイム送信
-
asyncio.sleep(0)で他の処理に実行機会を与える(アプリが固まらないように)
最終結果の送信
すべてのセグメントの処理が終わったら、最終的な全文をクライアントに送信します:
# 最終的な文字起こし結果をクライアントに送信
await send_websocket_message(
websocket,
{
"type": "final",
"data": {
"result": final_text # 完全な文字起こし結果
},
"done": True # 処理完了のフラグ
},
session_id
)
logging.info("Transcription completed successfully")
これにより、クライアント側で「文字起こしが完了しました」と表示され、最終結果を保存したりコピーしたりできるようになります。
エラーハンドリング
この処理には様々なエラー対策が組み込まれています:
- 文字起こしのエラー:モデルの読み込みや処理で問題が発生した場合
- 接続断:クライアントとの接続が途中で切れた場合
- 停止要求:ユーザーが「停止」ボタンを押した場合
各ケースでも安全に処理を終了し、可能なら理由をクライアントに通知します。
✅ まとめ
transcribe_fastapi.pyは、音声認識の中核部分を担うモジュールです。
主な特徴:
-
非同期処理設計:
asyncio.to_thread()で重い処理を別スレッドに分離し、メインのイベントループをブロックせず応答性を維持 - 段階的なデータ処理: 音声の基本情報を最初に送信し、セグメント(文単位)ごとに結果を逐次処理・送信
- リアルタイムフィードバック: 進捗状況を%表示し、処理中の中間結果をすぐにクライアントに表示
- インタラクティブ制御: 停止リクエストに即時対応し、WebSocket接続状態を継続的に監視
- 堅牢なエラー処理: 接続切断やモデル処理エラーに適切に対応
これらの工夫により、ユーザーは大きな音声ファイルでも、徐々に現れる文字起こし結果をリアルタイムで確認し、必要なら途中で停止することもできます。
😊 終わりに
この記事では、Python技術スタックのみを使用した非同期処理対応の文字起こしアプリの作成方法を解説しました。
このアプリは、以下の3つの主要コンポーネントから構成されています:
-
Streamlitフロントエンド (
app_fastapi.py): ユーザーインターフェースを提供し、WebSocketを通じてサーバーと通信します。非同期処理により、文字起こし中でもUIの応答性を維持しています。 -
FastAPIバックエンド (
server_fastapi.py): WebSocketを通じてクライアントとリアルタイム通信を行い、音声ファイルの受信と文字起こし結果の送信を担当します。セッション管理システムにより複数のクライアント接続を安全に処理します。 -
Whisper処理エンジン (
transcribe_fastapi.py): GPUを活用した高性能な文字起こし処理を提供し、結果をリアルタイムでクライアントに返送します。非同期設計により、重い処理中でもアプリの応答性を維持しています。
特に本アプリの特長は以下の点にあります:
- 非同期処理アーキテクチャ: 従来の同期処理(掃除機をかけている間は他の作業ができない)から、非同期処理(ロボット掃除機を動かしながら他の作業ができる)への移行
- リアルタイムフィードバック: 処理進捗の可視化と途中結果の表示
- ユーザー制御: 処理中でも停止可能な柔軟な操作性
- 堅牢なエラー処理: 様々な例外状況に対応する安定した設計
この記事を参考に、皆さん自身のプロジェクトでも非同期処理を活用した、よりインタラクティブで使いやすいアプリケーションを構築していただければ幸いです。
Discussion