faster-whisperでwhisper large-v3を動かしてみよう!
先日(11/7)にOpenAIの開発者会議がありましたね。
そのうちの1個にwhisper-large-v3の発表がありました。
他の機能が注目されていて、あまり目立ってはいないですが、とても大きなアップデートと個人的に感じましたので記事にしました!
音声文字起こし Whisperとは?
whisperとは音声文字起こしのことです。
Whisperは、Hugging Faceのプラットフォームでオープンソースとして公開されています。このため、ローカルPCでの利用も可能です。OpenAIのAPIとして使用することも可能です。
whisper large-v3とは?large-v2との違い
以下は教科書的になりますが、公式hugging faceページから引用したものです。
- 訓練データの量
large-v2よりも多くの訓練データを使用しています。具体的には、100万時間の弱ラベル付きオーディオと400万時間の疑似ラベル付きオーディオを使用しており、これによりモデルの精度と汎用性が向上しています。 - 入力データの特徴
128のメル周波数ビンを使用しています。この変更により、より広い範囲の音声周波数をキャプチャし、認識精度を向上させることができます。 - 言語トークン
広東語に対応する新しい言語トークンを導入しています。これにより、特定の言語に対するモデルの性能が向上しています。 - 性能とエラー率
large-v2と比較して、10%から20%の誤り率の削減が見られます。これは、より多くの訓練データと改善されたアーキテクチャのおかげで、より幅広い言語に対する認識性能が向上していることを意味します。
色々書きましたが、個人的に思うのはlarge-v2は英語の文字起こしは素晴らしかったですが、日本語はイマイチな印象でした…。それがlarge-v3は物凄く改善されている!という印象ですね。
そしてlarge-v3はlarge-v2に比べ計算量が増えています。そこで計算量を軽くするCTranslate2という技術を使ったモデルを使用していきます!
CTranslate2とは?
CTranslate2とはAIモデルを高速かつ、効率的に動かすモデルです!
詳細は以下のリンクを確認ください。
そして、whisperにCTranslate2を適用したモデルをfaster-whisperって言います!
もし、自身のローカル環境でwhisperを動かしたいのであればコスト、スピードの観点からfaster-whisperは非常に良い選択肢になります。
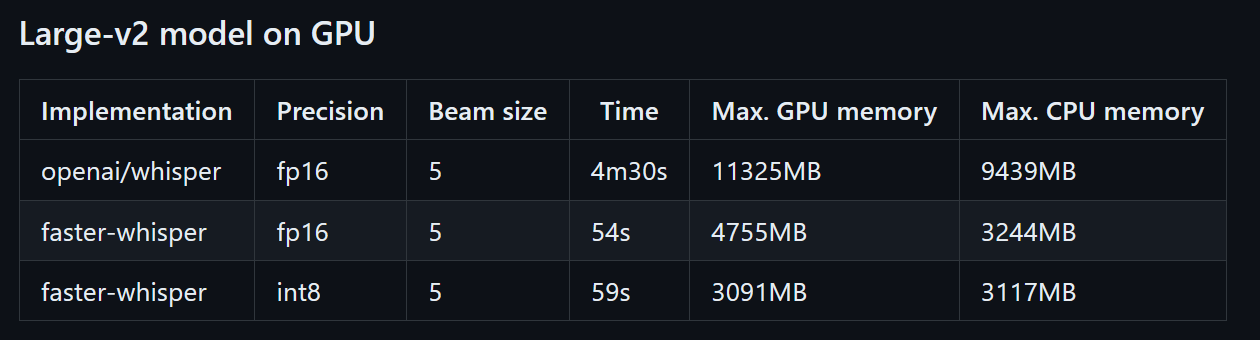
以下はlarge-v2ですが、CTranslate2適用前後である文字起こしにかかった時間は1/5以下、使用GPUメモリは半分以下となっています。
faster-whisperのコード
必要なライブラリは以下です。
pip install yt-dlp
pip install faster_whisper
以下はwhisper-v3を動かすコードです。
下記の方のコードを参考にyoutubeの動画を音声文字起こしできるコードです!
from faster_whisper import WhisperModel
import subprocess
YOUTUBE_ID = "Gh0xzbgCIgg" # Youtube ID
AUDIO_FILE_NAME = f"{YOUTUBE_ID}.mp3"
# Download audio from Youtube
def dl_yt(yt_url):
subprocess.run(f"yt-dlp -x --audio-format mp3 -o {AUDIO_FILE_NAME} {yt_url}", shell=True)
dl_yt(f"https://youtu.be/{YOUTUBE_ID}")
model = WhisperModel("large-v3", device="cuda", compute_type="float16")
segments, info = model.transcribe(
AUDIO_FILE_NAME,
beam_size=5,
vad_filter=True,
without_timestamps=True,)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
import os
os.remove(AUDIO_FILE_NAME)
動画は先日話題になった孫さんの伝説的講演です。これを文字起こししていつでも読めるようにしておきましょう。
使用時のタスクマネージャーのスクリーンショットですが、使用GPUメモリは6~7GBでした。8GBのGPUがあれば十分余裕ですね。

cpuのみで動かすには?
先程紹介したのはGPUを使用したコードでした!もし手持ちにGPUが無くてCPUのみで文字起こししたい場合はmodelのパラメータを変更することで実行出来ます!
model = WhisperModel("large-v3", device="cpu", compute_type="int8")
deviceをcpuに選択して、compute_typeをint8にすることで計算量を減らしています。
おすすめのパラメータ
最後にfast-whisperの個人的おすすめパラメータを紹介します。ここはご自身の目的によって違ってくると思いますので、使ってみて調整してみてください!
vad_filter
vad_filter=True
無音部分を検出して、その箇所を文字起こしから除外してくれます。文字起こしする際に無音箇所があるとおかしな結果が返されることがあるので、事前に無音部分を除外しておくことをお勧めします。
without_timestamps
without_timestamps=True
書き起こされたテキストにはタイムスタンプ(0:30~0:40等の情報)が含まれまなくなります。実行速度が速くなりますので、タイムスタンプが不要ならTrueをお勧めします。
initial_prompt
initial_prompt="XXXXX"
最初のチャンクの文字起こしをする際のシステムプロンプトのようなものになります。これはそこまで重要ではなく、何も設定しないよりはした方がいい位のものです。initial_promptの詳細は他の方の記事を参考にして頂ければと思います。
Discussion