LangChainを用いて長文を要約しよう!map_reduce法/refine法
皆さん、ChatGPTを活用していますか?
ChatGPTは多様な用途に利用できますが、その中でも要約というのは得意分野です。
LLM(Large Language Model、大規模言語モデル)であるがゆえに、要約や議事録の作成、キーワード抽出などといったタスクは得意分野です。
しかしながら、LLMには文字数に関する制限が存在します。文字数が多くなると、LLMの計算量が増加し、それに伴いより多くのリソースが必要となります。そのため、文字数を一定の範囲内に制限しているのです。
では、この文字数制限をどのように回避するのでしょうか? LangChainはこの問題を解決するために、2つの方法を提供しています。
LangChainとは?
LangChainは、ChatGPTのような言語モデルの機能を効率的に拡張するためのライブラリです。このツールを使用すると、長文の入力や複雑な計算問題への対応など、言語モデルの課題を短いコードで効率的に解決することができます。
必要なライブラリのインストール
pip install openai
pip install langchain
以下からはOpenAIのAPIを使用します!それぞれOpenAI API keyを設定してください。
API keyの発行方法は他の方の記事を参考にしてください。
map_reduce法とrefine法
以下は、要約に関する公式のドキュメントへのリンクです。 長文を要約する際には、以下のアプローチを採用します!
- 文章を一定量ごとに分割する。
- 分割された文章を処理する。
1のステップ、すなわち文章を分割する方法は以下の通りです。この方法では、文章を指定された量の文字ごとに分割し、それをリストとして返してくれます。
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1500, chunk_overlap=0 , separator=".",
)
texts = text_splitter.split_text(text)
詳細は以下のリンクを確認お願いします。
2の分割された文章への処理方法として、LangChainは2つの方法を提供しています。
それがmap_reduce法とrefine法というものになります。その違いについて図とコードを確認しながら理解していきましょう!
map_reduce法
map_reduce法とは下記の流れになります。
- ドキュメントを分割
- 各ドキュメントに対しLLMへプロンプトを実行(map)
- 得られた各応答結果に対してLLMへプロンプトを実行しする統合する(reduce)⇒最終回答
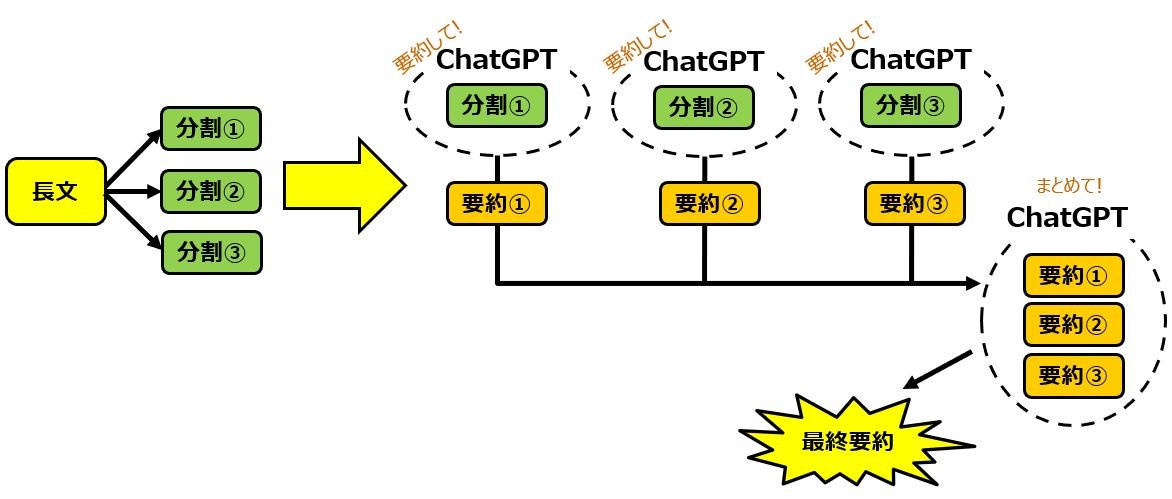
コードは以下になります。
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain.docstore.document import Document
map_prompt_template = """以下の文章をテーマ毎にまとめてく下さい。
------
{text}
------
"""
map_combine_template="""以下の文章をテーマ毎にまとめてください。
------
{text}
------
"""
map_first_prompt = PromptTemplate(template=map_prompt_template, input_variables=["text"])
map_combine_prompt = PromptTemplate(template=map_combine_template, input_variables=["text"])
map_chain = load_summarize_chain(
llm=ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo"),
reduce_llm=ChatOpenAI(temperature=0,model_name="gpt-4"),
collapse_llm=ChatOpenAI(temperature=0,model_name="gpt-4"),
chain_type="map_reduce",
map_prompt=map_first_prompt,
combine_prompt=map_combine_prompt,
collapse_prompt=map_combine_prompt,
token_max=5000,
verbose=True)
with open("/path/to/file/long_text.txt",'r', encoding='utf-8') as f:
text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1500, chunk_overlap=0 , separator=".",
)
texts = text_splitter.split_text(text)
docs = [Document(page_content=t) for t in texts]
result=map_chain({"input_documents": docs}, return_only_outputs=True)
print(result["output_text"])
大事なとこは説明しますね!
map_prompt_template = """以下の文章をテーマ毎にまとめてく下さい。
------
{text}
------
"""
分割された文章に対するプロンプトになります。{text}は分割された文章です。
llm=ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
ベースとなる言語モデルです。temperatureは生成される文章の多様性をコントロールするパラメータです。0~1まで指定できますが、要約は低い値を設定することが推奨されています。model_nameというのはこの場合、OpenAIのモデルを指定することが出来て、今回はgpt-3.5-turboを指定しています。
map_combine_template="""以下の文章をテーマ毎にまとめてください。
------
{text}
------
"""
要約された各分割文章をまとめるプロンプトです。{text}はこれまでのLLMからの回答になります。
文章をまとめる際の言語モデルも、上記で指定したモデルと同じでもいいんですが個別で指定することが出来ます!個人的にはコスパの観点からmapにはgpt-3.5-turbo、reduceにはgpt-4がお勧めです!
reduce_llm=ChatOpenAI(temperature=0,model_name="gpt-4")
また、reduceの際に文章量がmodelの上限を超えるとエラーになってしまいます。その際にその文章を圧縮することが出来ます。token_maxで上限量を指定することが出来て、collapse_promptで上限を超えた際のpromptを指定できます。今回はreduceのpromptと同じにしています。
collapse_llm=ChatOpenAI(temperature=0,model_name="gpt-4")
collapse_prompt=map_combine_promp
refine法
refine法とは下記の流れになります。
- ドキュメントを分割
- 1番目の分割ドキュメントに対しLLMへプロンプト実行
- 2で得られた応答結果と次の分割ドキュメントに対しLLMへプロンプト実行
- 3を繰り返し、最後のドキュメントでの回答が最終回答となる

コードは以下になります。
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain.docstore.document import Document
refine_first_template = """以下の文章をテーマ毎にまとめて下さい。
------
{text}
------
"""
refine_template = """以下の文章をテーマ毎にまとめてく下さい。
------
{existing_answer}
{text}
------
"""
refine_first_prompt = PromptTemplate(input_variables=["text"],template=refine_first_template)
refine_prompt = PromptTemplate(input_variables=["existing_answer", "text"],template=refine_template)
refine_chain = load_summarize_chain(
ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo-16k"),
chain_type="refine",
question_prompt=refine_first_prompt,
refine_prompt=refine_prompt)
with open("/path/to/file/long_text.txt",'r', encoding='utf-8') as f:
text = f.read()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1500, chunk_overlap=0 , separator=".",
)
texts = text_splitter.split_text(text)
docs = [Document(page_content=t) for t in texts]
result=refine_chain({"input_documents": docs}, return_only_outputs=True)
print(result["output_text"])
大事なとこは説明しますね!
refine_first_template = """以下の文章をテーマ毎にまとめて下さい。
------
{text}
------
"""
一番最初に実行されるプロンプトになります。{text}は分割された文章です。
refine_template = """以下の文章をテーマ毎にまとめてく下さい。
------
{existing_answer}
{text}
------
"""
2回目以降繰り返されるプロンプトになります。これまでの回答と新しい文書の内容をもとに、要約を更新するよう指示します。{existing_answer}はこのプロンプトを実行する前の回答が入ることになります。
どちらの方がいいか?
2つの方法を紹介しましたが、どちらが良いのかというのは気になる点であると思います。しかし、どちらの方法もメリット、デメリットがあり、どちらの方が優れていると断言できるものではありません。
教科書的ではありますが、それぞれのメリット、デメリットになります。
map_reduce法
-
メリット
処理を並行して実行できる為、大量のドキュメント処理に適しています。 -
デメリット
個々のドキュメントを個別に処理するため、ドキュメント間の関連性や文脈を見落とす可能性があります。特に、ドキュメントが互いに参照し合っている場合や、全体的な文脈が重要な場合には、この手法は不利となる可能性があります。
refine法
-
メリット
反復的なアプローチを採用しているため、各ステップで得られた情報を利用して結果を改善することが可能です。 -
デメリット
一度に一つのドキュメントのみを処理するため、多数のドキュメントから詳細な情報が必要なタスク、またはドキュメントが頻繁に互いを参照する場合には、この手法は不利となる可能性があります。
個人的にはより多くのパラメータが設定出来て、スピードも優れているmap_reduce方がお勧めです!でも本当は一度に2つの方法を実行できて、それぞれ回答を見比べらる、なんて
終わりに
ここまで、LangChainライブラリを用いたmap_reduceとrefineの紹介と使い方を詳しく解説してきました。これらのメソッドは大量のテキストデータを効率よく処理し、要約や分類を行う際に非常に強力なツールとなります!
map_reduceはテキストの分割と並行処理を容易にし、大規模なデータセットでもスムーズに処理を行うことが可能です。一方で、refineはテキストの連続をステップバイステップで要約し、細かなコントロールを可能にします。
これらのメソッドを適切に利用することで、テキストデータの解析と要約を効果的に行い、情報抽出の精度を向上させることができます。また、これらの技術は様々な業界やシナリオで応用が可能であり、テキストデータから価値ある洞察を引き出すための強力な手段となり得ます。
文章要約はLLMにおいて非常に強力な使用方法の一つです!この記事が、その力を最大限に引き出すための第一歩となることを願っています。何か質問や困ったことがあれば、コミュニティやドキュメントを活用してくださいね!Happy coding!
Discussion