Raspberry Pi 5上でGoogleの軽量LLM Gemma 2Bを動作させてみた
はじめに
Raspberry Pi 5(8GB RAM)を入手したので、オンデバイス(ローカル)のLLMでチャットボットを動作させてみようと思いました。最初は、以前の記事でも紹介している日本語LLM elyza/ELYZA-japanese-Llama-2-7b-instructの4ビット量子化GGUF版を試したのですが、当然ながら処理速度は遅く、毎秒1文字か2文字程度の文章生成でした。そんなとき、Googleから軽量高性能なGemmaモデルが公開されました。日本語には対応していませんが、LLMとしては、かなりパラメータ数の少ない2B(20億パラメータ)版[1]があるので、早速、Raspberry Pi 5(8GB RAM)で試し、それなりに動作するので、その方法を紹介します。
ターゲットプラットフォーム
特にプラットフォームに固有の部分はありませんが、Raspberry Pi 5(8GB RAM)を想定して説明します。キャッシュしている領域も含めると、アプリケーション動作中、8GBメモリをほぼ使っていますので、4GB版でたとえ動作しても、メモリスワップなどで、8GB版上で動作するよりも性能が出ない可能性があります。
環境構築
試行錯誤しているときは、いろいろなPythonパッケージのインストールとアンインストールを繰り返すので、今回は、venvでPythonの仮想環境を構築しました。
mkdir ~/gemma
cd gemma
python -m venv .
source bin/activate
venv環境が構築できたら、まずは、pipをアップグレードします。
pip install -U pip
Llama.cppが必要とするOpenBLASをインストールします。
sudo apt update && sudo apt install libopenblas-dev
Llama.cppのPythonバインディングllama-cpp-pythonをインストールします。
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install --no-cache-dir llama-cpp-python
Gradioをインストールします。
pip install --no-cache-dir gradio
ソースコード
GGUF形式の量子化済みGemmaモデルをHugging Face Hubで公開している方がいらっしゃるので、そのmmnga/gemma-2b-it-gguf利用させていただきました。q4_K_S型で量子化されているモデルを選択しました。元のモデルgoogle/gemma-2b-itの利用規約を確認した上でお使いください。
以下のスクリプトをgr_gemma_chat.pyという名前で、~/gemmaディレクトリにコピーします。
import gradio as gr
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
MEMORY_LENGTH = 2
CONTEXT_SIZE = 2048
MAX_TOKENS = 512
LLM_REPO_ID = "mmnga/gemma-2b-it-gguf"
LLM_FILE = "gemma-2b-it-q4_K_S.gguf"
model_path = hf_hub_download(repo_id=LLM_REPO_ID, filename=LLM_FILE)
llm = Llama(model_path, n_gpu_layers=128, n_ctx=CONTEXT_SIZE)
def construct_prompt(message, history):
prompt = ""
# 過去MEMORY_LENGTH回分の会話をプロンプトに含める
if history is not None:
for item in history[-MEMORY_LENGTH:]:
prompt += "<start_of_turn>user\n{user}<end_of_turn>\n<start_of_turn>model\n{assistant}<end_of_turn>\n".format(
user=item[0], assistant=item[1]
)
# 今回のユーザーメッセージをプロンプトに追加
prompt += "<start_of_turn>user\n{message}<end_of_turn>\n<start_of_turn>model\n".format(
message=message
)
return prompt
def predict(message, history):
# プロンプトを作成
prompt = construct_prompt(message, history)
print("---prompt begin---\n" + prompt + "\n---prompt end---")
# 推論
streamer = llm.create_completion(prompt, max_tokens=MAX_TOKENS, stream=True)
# 推論結果をストリーム表示
answer = ""
for msg in streamer:
message = msg["choices"][0]
if 'text' in message:
new_token = message["text"]
if new_token != "<":
answer += new_token
yield answer
gr.ChatInterface(predict).queue().launch()
実行
先ほど構築した、venv環境を有効にします。
cd ~/gemma
source bin/activate
アプリケーションを実行します。最初の起動時には、モデルのダウンロードを行うので、準備が完了するまでに時間がかかります。
python gr_gemma_chat.py
上記コマンドを実行した標準出力にGradioを起動するためのURL http://127.0.0.1:7860 が表示されますので、このURLをウェブブラウザで開きます。
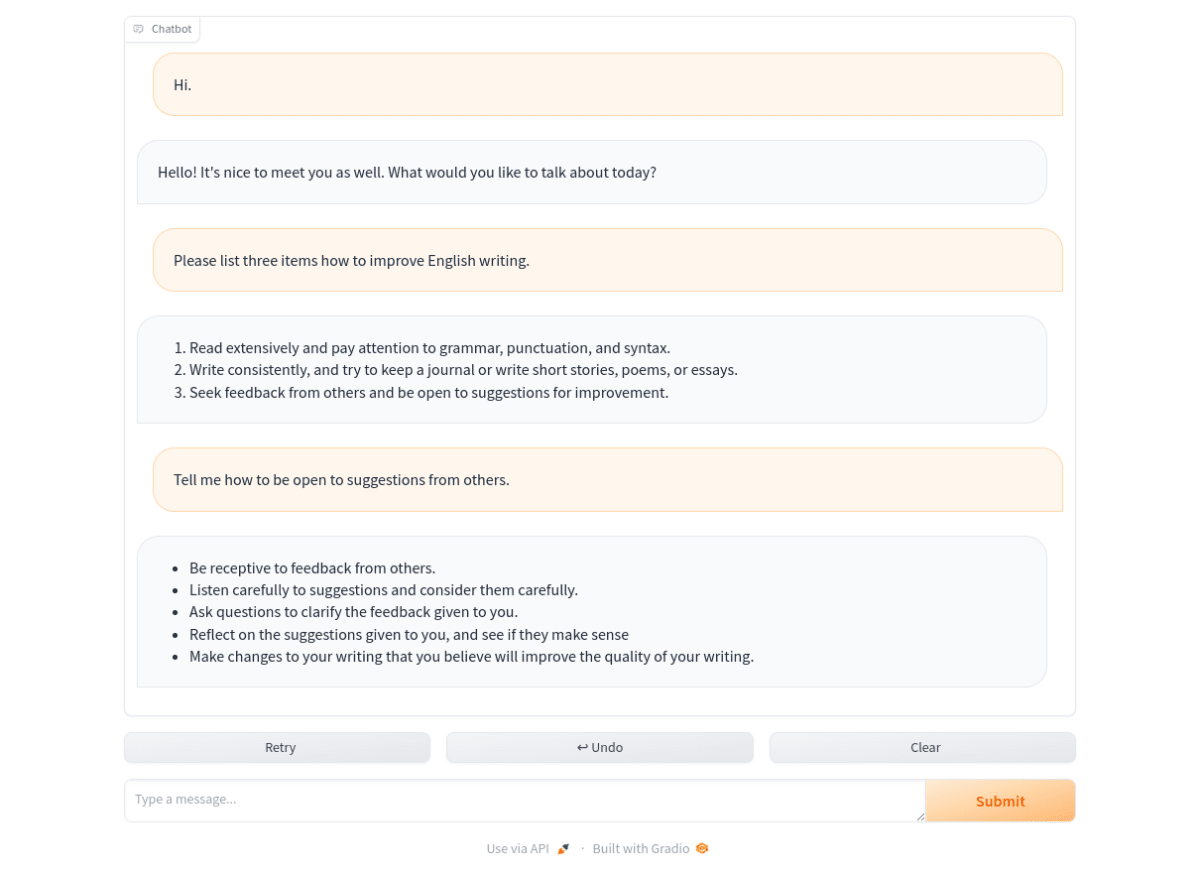
パフォーマンス
上記のスクリーンショットの例では、ユーザーの「Hi.」から始まる1番目の会話では、毎秒4.44トークンで文章を生成しました。(ユーザーのメッセージ入力から、Gemma 2Bが回答を終了するまでは、約8.4秒)
llama_print_timings: load time = 2296.81 ms
llama_print_timings: sample time = 46.96 ms / 22 runs ( 2.13 ms per token, 468.52 tokens per second)
llama_print_timings: prompt eval time = 2296.70 ms / 11 tokens ( 208.79 ms per token, 4.79 tokens per second)
llama_print_timings: eval time = 4733.07 ms / 21 runs ( 225.38 ms per token, 4.44 tokens per second)
llama_print_timings: total time = 8436.12 ms / 32 tokens
「Please list three items how to improve English writing.」で始まる2番目の会話では、以下のとおりでした。
llama_print_timings: load time = 2296.81 ms
llama_print_timings: sample time = 103.13 ms / 53 runs ( 1.95 ms per token, 513.90 tokens per second)
llama_print_timings: prompt eval time = 3918.60 ms / 20 tokens ( 195.93 ms per token, 5.10 tokens per second)
llama_print_timings: eval time = 11588.65 ms / 52 runs ( 222.86 ms per token, 4.49 tokens per second)
llama_print_timings: total time = 18746.25 ms / 72 tokens
「Tell me how to be open to suggestions from others.」で始まる3番目の会話では、以下のとおりでした。
llama_print_timings: load time = 2296.81 ms
llama_print_timings: sample time = 131.89 ms / 66 runs ( 2.00 ms per token, 500.42 tokens per second)
llama_print_timings: prompt eval time = 4094.52 ms / 21 tokens ( 194.98 ms per token, 5.13 tokens per second)
llama_print_timings: eval time = 14833.45 ms / 65 runs ( 228.21 ms per token, 4.38 tokens per second)
llama_print_timings: total time = 22936.92 ms / 86 tokens
まとめ
軽量高性能なGemma 2Bは、Raspberry Pi 5でも、違和感のない速度で文章を生成できることが分かりました。ちなみに、MacBook Air M2チップモデル(16GBメモリ)上で、llama-cpp-pythonをMetal有効[2]にして動作させた場合は、桁違いに高速でした。日本語対応版が出てくるのが本当に待たれます。
Discussion