NeurIPS Datasets and Benchmarks Trackでの論文採択を通して得たデータ中心のAI研究の知見
2021年にAI分野の最高峰の国際学会であるNeurIPSは、今後のAI・機械学習分野の研究の発展に不可欠な高品質なデータセットとベンチマークの設計・開発などの議論の場として、「Datasets and Benchmarks Track」(以下、D&B Track)を新設した。私はこの研究トラックに2023年と2024年に主著論文を投稿し、2年連続で論文が採択された。論文投稿の過程で、現在の主流であるモデルやアルゴリズムの設計にフォーカスしたModel-centricな研究と、データセットやベンチマークの設計にフォーカスしたData-centricな研究では、研究の新規性や有用性を伝える上での重要なポイントに違いがある感じた。そのため、これからデータ中心のAI研究をする方や、今後D&B Trackに投稿を検討されている方の参考になればと思い、私の経験から得られた知見をまとめた。
TL;DR
- NeurIPSが2021年に新設したD&B Trackの投稿件数は急増しており、データセットやベンチマークに関する研究が活発化している。
- D&B Trackへの投稿論文は、新しいデータセットやベンチマークを提案する研究が多いが、データセットを作成する方法論の提案や、既存データセットの利用状況を分析する研究など幅広い。
- 新しいデータセットを提案する場合、データセットの品質の議論が難しい。品質が高いことをなるべく定量的に主張するべきであるが、データセットの特徴や統計情報を様々な観点から視覚化することも有効である。
- Data-centricな研究とModel-centricな研究では評価実験の目的が異なるため、実験の設計や得られた結果に基づく議論には工夫が必要である。
- Datasheets for Datasetsは、データセットの構成や使用目的、収集方法、前処理方法、配布方法、メンテナンスなどについてのドキュメント化に役立つ。
NeurIPS Datasets and Benchmarks Track
1987年に設立されたAI分野で世界的に権威のある国際会議の一つであるNeurIPSは、2021年に新たな研究トラックとしてD&B Trackを発足した。この研究トラックの役割について、2024年の公式サイトでは以下のように説明されている。
The Datasets and Benchmarks track serves as a venue for high-quality publications, talks, and posters on highly valuable machine learning datasets and benchmarks, as well as a forum for discussions on how to improve dataset development.
訳)Datasets and Benchmarksトラックは、非常に価値の高い機械学習データセットやベンチマークに関する質の高い論文、講演、ポスターの発表の場として、また、データセット開発の改善方法に関する議論の場として機能します。
この研究トラックの発足の経緯は、公式ブログAnnouncing the NeurIPS 2021 Datasets and Benchmarks Trackで述べられている。この記事によると、2020年以前のNeurIPSでは、新しいデータセットの提案に焦点を当てた採択論文は年間で5本以下であり、幅広いデータセットにわたるアルゴリズムのベンチマークに焦点を当てた採択論文は10本程度であったようだ。しかし、下図に示した通り、D&B Trackを発足以降、投稿件数は年々増加し、2024年は1820件もの論文が投稿された。このことからも、ここ数年でデータセットやベンチマークに関する研究が活発化していることが見て取れる。
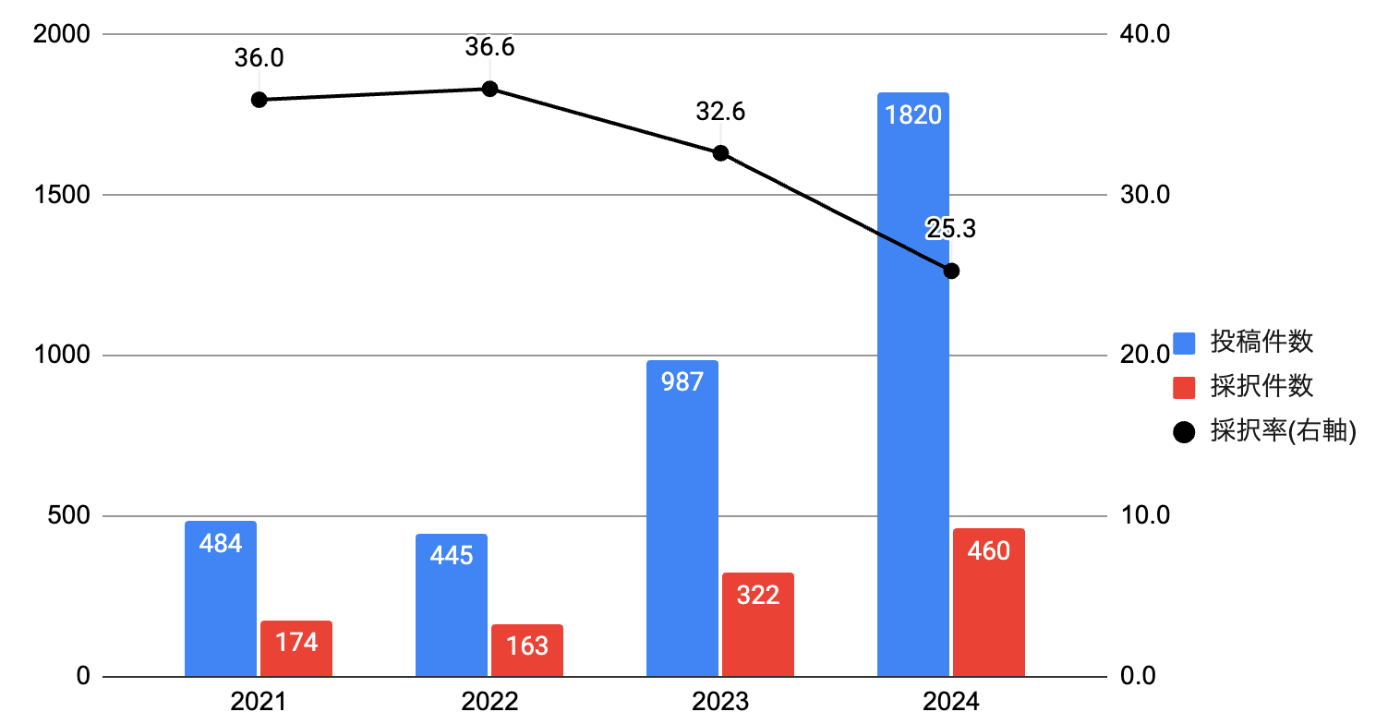
D&B Trackの投稿件数、採択件数、採択率の推移
2021年から2022年は投稿件数がほぼ横ばいになっているが、2021年は初めての開催とのこともあって、2回の投稿機会(締切)が設けられていた。2022年以降は、毎年投稿件数が約2倍近く増加し、採択率も下がっている。
研究の分類
ここでは、過去にD&B Trackに採択された論文を例に挙げながら、研究の大まかな分類を示す。
データセットを提案
この研究では、独自の方法で作成もしくはキュレーションしたデータセットを提案・公開する。例えば、2023年にOutstanding Paper Awardsを受賞したClimSim: A large multi-scale dataset for hybrid physics-ML climate emulationでは、大気中の雲や乱流などの現象を高解像度で再現できる気候シミュレータを利用して、10年間分のデータを20分間隔で作成した世界最大のデータセットを提案した。私の2023年と2024年に投稿した主著論文は、AI創薬のための新たなデータセットを提案しており、このカテゴリに該当する。
ベンチマークを提案
この研究では、モデルの性能や限界をより正確かつ公平に評価するためのベンチマークを提案する。ベンチマークに利用するデータセットは必ずしも新しいものではなく、すでに公開されているデータセットを利用する場合も多い。例えば、2023年にOutstanding Paper Awardsを受賞したDecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Modelsでは、大規模言語モデル(LLM)の信頼性評価のための包括的なフレームワークを提案しており、安全性、公平性、堅牢性、プライバシー、倫理という重要な観点からLLMを評価できる。DecodingTrustで使用されているデータセットには、既存の公開データセットと、新たに生成されたデータセットの両方が含まれている。
上記の研究は"モデル"を評価するためのベンチマークであるが、"データセット"を評価するためのベンチマークを提案する研究もある。代表的な研究として、マルチモーダルなデータセット設計のためのベンチマークであるDataCompがある。DataCompは、与えられたデータソースの中からモデルを学習するための最適なサブセットを構築するフィルタリング手法を評価するFiltering trackと、自由なデータソースから独自にキュレーションして作成した学習データセットを評価するBring your own data trackがあり、データセットそのものの品質やその作成方法を評価できる。
その他
D&B Trackに投稿される研究論文は、トラック名から予想できる通り、前述した新規のデータセットもしくはベンチマークを提案する研究が大多数を占めているが、この二つとは少しフォーカスが異なる研究もある。例えば、データセットを作成するためのジェネレータやシミュレータを提案することにフォーカスした研究もある。例えば、Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving ResearchやLarge Language Model as Attributed Training Data Generator: A Tale of Diversity and Biasなどがこれに該当する。これらの研究では、実際に作成したデータセットも同時に公開・提案している場合が多いが、データセットの作成方法に焦点が当たっている点が特徴である。
また、これまでに挙げたものとは異なるタイプの研究としては、2021年にOutstanding Paper Awardsを受賞したReduced, Reused and Recycled: The Life of a Dataset in Machine Learning Researchが非常に面白い。この研究では、機械学習の研究におけるデータセットの利用と再利用のダイナミクスに焦点を当て、データセットの使用パターンが機械学習のコミュニティ間および時間経過によってどのように異なるかを調査している。その結果、ほとんどのコミュニティでは、時間の経過とともに、使用されるデータセットが少数のデータセットに集中する傾向を示している。この研究のように、特定のデータセットやベンチマークに関するものではなく、データセットに関連する調査や分析結果をまとめたものも採択され、Awardの受賞のような高い評価を得ている点は興味深い。
データセットの質の議論
D&B Trackに過去に採択されたデータセットの提案論文を見てみると、提案するデータセットの有用性や既存のデータセットと比較した際の優位性を議論するために、関連研究(Related Work)の章に以下のような比較表を設けている場合が多い。
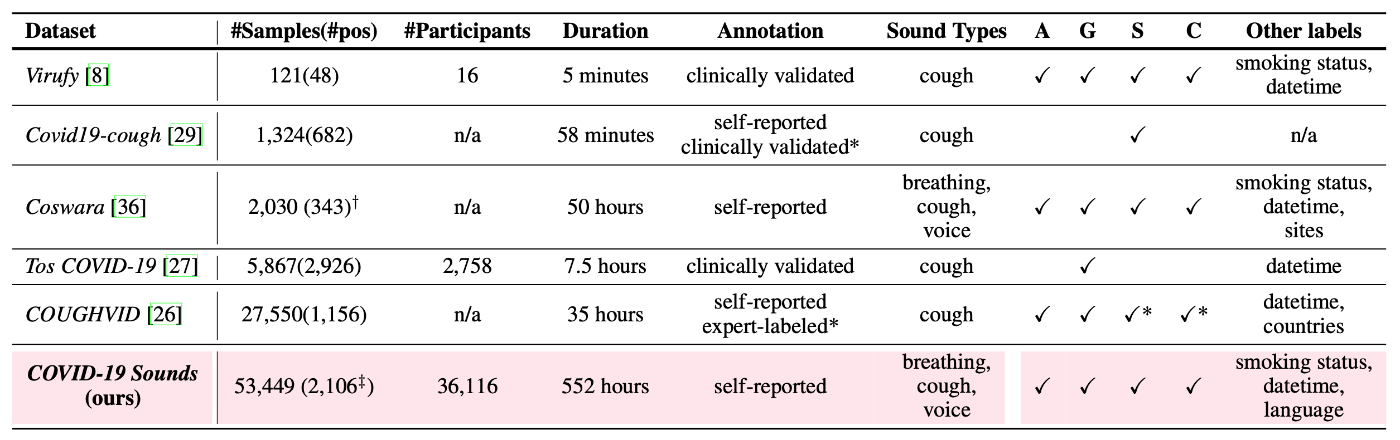
出典:[COVID-19 Sounds]のTable 1
もし提案するデータセットのデータ数が他のデータセットより十分に多ければ、量の観点での優位性は主張しやすい。例えば、「既存の公開データセットはX万サンプル程度であるが、提案するデータセットは約2倍のY万サンプルを有している」のような主張はわかりやすいし、実際に論文投稿に伴ってデータセットを公開するため、査読者・読者も事実の確認がしやすい。しかし、データセットの量が多いだけでは、ノイズ的なデータや非常に似通ったデータが多いだけかもしれないので、データセットの有用性の主張としては不十分である。そのため、提案するデータセットが何かしらの質の観点でも有用であることを伝える必要がある。これが、私がデータセットの提案論文を書く上で一番頭を悩ませたポイントである。
このポイントに関しては、どんなデータが望まれていて、質が高いと言えるのかはそのデータのドメインごとに異なるため、汎用的な解決方法はない。過去のD&B Track採択論文を見ていくと、データセットの質が高いことの信頼性を高めるために、なるべく定量的に主張することが有効であると思う。また、どうしても定量的に示せない場合は、データセットが定性的に有用な特徴を持っていることを可視化して視覚的に表現することも有効である。あとは、自分の提案するデータセットや既存データセットと向き合い、何がどう優位で、それによって何が嬉しいのかを個別に考えていくしかないと思っている。そのため、ここでは実際に、過去のD&B Track採択論文の例を二つ紹介する。
事例1: CREAK
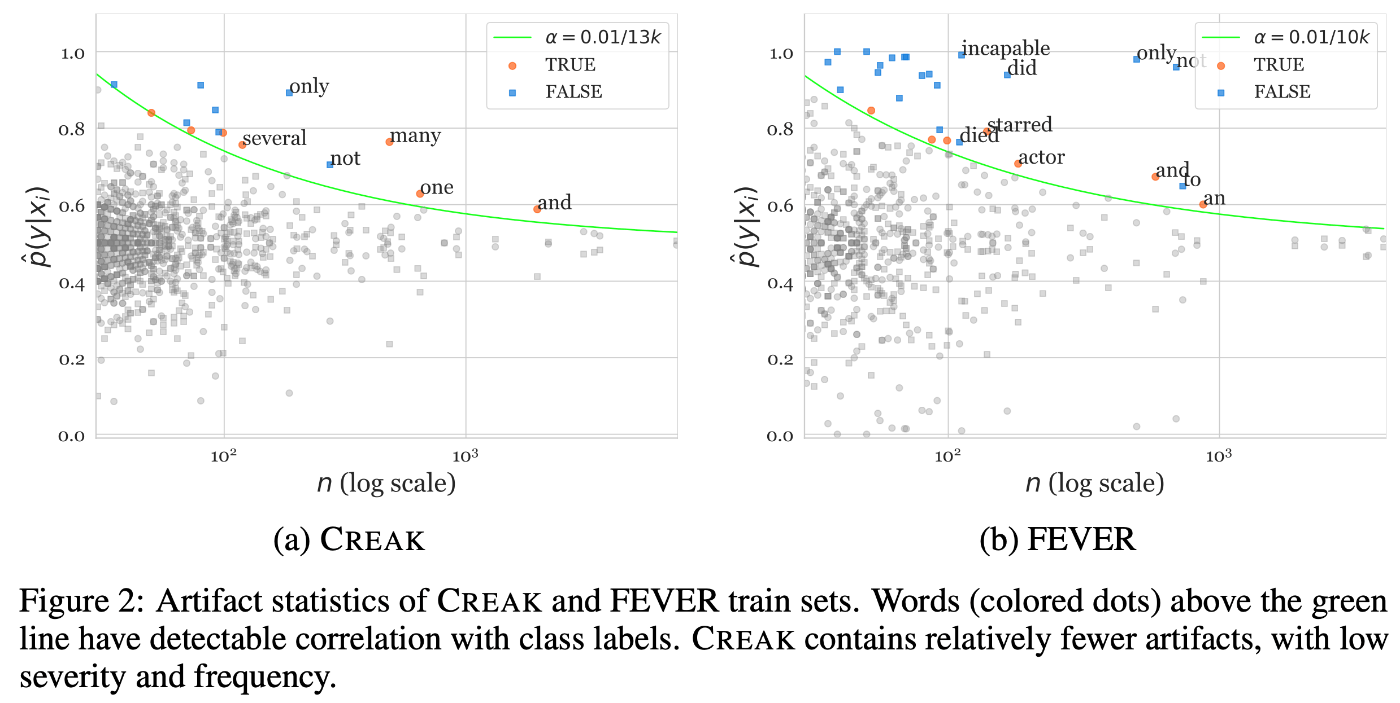
出典:CREAKのFigure 2
CREAKは、言語モデルの特定のエンティティの知識に基づく常識推論能力を評価するためのデータセットである。例えば、「ハリーポッターがほうきで飛ぶ方法を教えることができる」という主張の真実性を判断する。CREAK は、エンティティに関する事実確認(ハリポッターは魔法使いであり、ほうきに乗るのが得意である)と、常識的推論(得意なことは他人に教えることができる)を組み合わせることで、モデルの能力を評価する。
このようなデータセットでは、アーティファクトというデータセット作成時に意図せず生じてしまう、テキストの表面的な特徴とラベルとの間の偽の相関関係が少ないことが望まれる。なぜなら、モデルがこれらのアーティファクトを学習してしまうと、真の推論能力ではなく、表面的な特徴に基づいて予測を行ってしまう可能性があるからである。上図は、単語の出現頻度(横軸)とその単語が真または偽の主張と相関する確率(縦軸)の関係をプロットしたものであり、緑色の線は統計的に有意な相関を示す閾値を表す。この分析結果より、CREAKは既存のデータセットであるFEVERと比較してアーティファクトが少なく、その頻度も低いことがわかった。これは、CREAKがより質の高いデータセットであり、モデルがアーティファクトに頼らずに真の推論能力を学習できることを示している。この事例では、提案するデータセットに固有の望ましい要件に対して、既存データセットと比較した分析結果を載せ、データセットの質について議論している。
事例2: COVID-19 Sounds
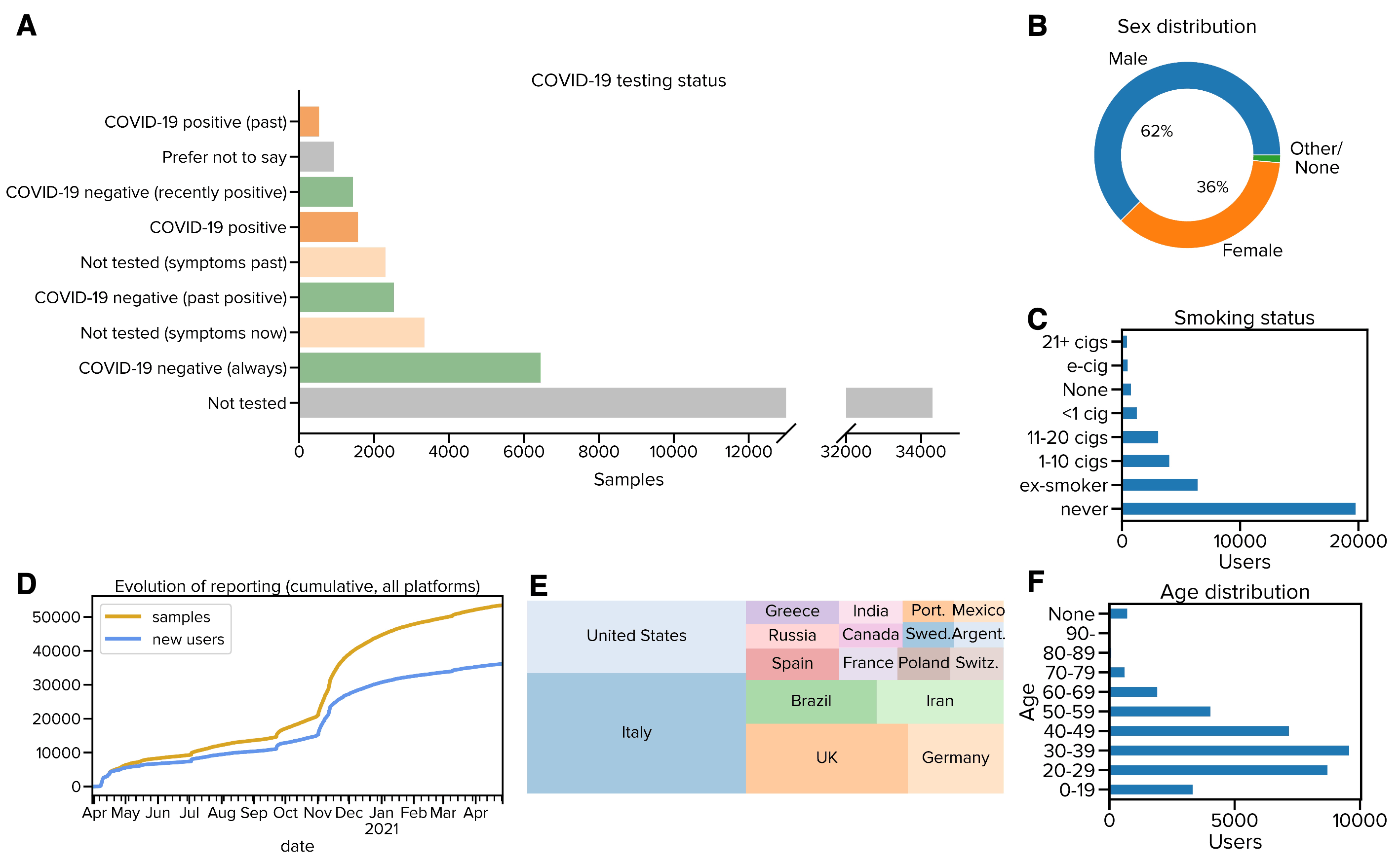
出典:COVID-19 SoundsのFigure 2
COVID-19 Soundsは、COVID-19陽性およ陰性者から収集した呼吸音、咳、声からなる大規模な音声データセットであり、機械学習を用いたCOVID-19の感染予測に活用できる。このような音声データセットを用いてより汎用性・信頼性が高いCOVID-19の診断モデルを開発するためには、収集対象の人の多様性が高いことが望まれる。そこで、本論文中では上図のように、(A)COVID-19の診断ステータス、(B)性別、(C)喫煙状況、(E)国籍、(F)年齢の統計情報を可視化し、COVID-19 Soundsが人口統計的に多様であることを示している。この事例では、他のデータセットとの比較ではなく、提案するデータセットの特徴を様々な観点からグラフ化することで、データセットの多様性が高いことを主張している。
実験の目的の違い
新たに設計した独自のモデルを提案するようなModel-centricな研究の場合、その評価実験では、提案モデルがその分野のSOTA(State-of-the-Art)モデルを含む多様なベースラインモデルよりも、特定のタスクで優れた性能を達成することを示すのが主な目的となる。一方、データセットやベンチマークを提案する論文では、特定のモデルが性能が高いことを主張するわけではないため、実験の目的や立ち位置が異なる。新しいデータセットやベンチマークの提案論文における実験では、何かしらの観点からそのデータセットやベンチマークの有用性や研究分野に与える影響を議論しなければならない。
一つの理想的なシナリオは、提案するデータセットやベンチマークを用いた実験の結果、既存のモデルの課題を指摘し、その課題を解決するために提案するデータセットやベンチマークが有用であると主張するパターンである。その課題がこれまで認知されていなかったものであれば、よりインパクトが大きいし、仮にすでに認知されている課題であっても、その解決に役立つことがわかれば、研究がその分野に与える影響も伝わりやすい。また、明確な課題を指摘するわけではなくても、提案するデータセットやベンチマークを用いることで、特定のタスクに対して、これまでよりもより性能や信頼性が高いモデルの開発が可能になり、その分野の発展に寄与することが示れば提案するデータセットやベンチマークの価値を伝えることができる。ここからは、過去のD&B Track採択論文が、実験の結果からどのようなことを主張しているのか二つの例を紹介する。
事例1: DecodingTrust
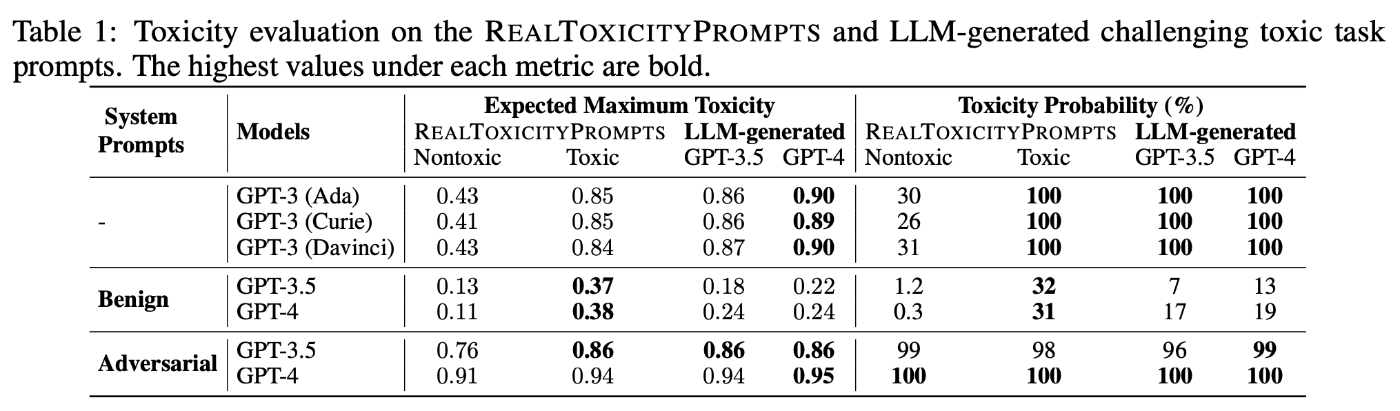
出典:DecodingTrustのTable 1
この事例は、前述の既存のモデルの課題を指摘したパターンである。本論文で提案したLLMの信頼性評価のための包括的なフレームワークであるDecodingTrustを用いた実験の結果、GPT-4やGPT-3.5が、いくつかの信頼性指標において高い性能を示す一方で、毒性、バイアス、堅牢性、プライバシー、倫理、公平性などの観点で、依然として多くの課題を抱えていることを明らかにした。この実験結果を受けて、本論文ではDecodingTrustが今後のLLM開発において、信頼性を向上させるための重要な指針となると述べている。
事例2: AVIDa-SARS-CoV-2

出典:AVIDa-SARS-CoV-2のTable 4
この事例は、NeurIPS 2024に採択されたAI創薬に関する私の主著論文で、新型コロナウイルス(SARS-CoV-2)と抗体(ヒトの病気を治療するための重要なタンパク質)の多種多様なペアが結合するかしないかを示すラベル付きのデータセットを提案した。本論文の実験では、様々な既存の学習済みタンパク質言語モデル、抗体言語モデルを選定し、AVIDa-SARS-CoV-2を用いてSARS-CoV-2と抗体間の結合予測の性能を比較した。また、それらのモデルの性能の差の要因を生物学的な観点から考察して、議論した。本論文では、実験結果を受けて、最先端のモデルでも実用の観点では性能が不十分であると述べ、AVIDa-SARS-CoV-2が今後の実用的なモデル開発に有用なデータセットであり、AI創薬を促進することが期待できることを主張した。
Datasheets for Datasets
新たなデータセットを提案する論文をD&B Trackへ投稿する場合、supplementary materialsとしてデータセットに関する詳細な説明を記述したドキュメントを提出する必要がある。このドキュメントのテンプレートとして、NeurIPSが推奨しており、多くの論文で採用されているのがDatasheets for Datasetsである。このDatasheetsは下に示したようにデータセットをドキュメント化する上で重要な質問(下の太字)が多く含まれており、作成者はその質問に回答する形でドキュメントを作成する。

出典:Datasheets for DatasetsのSection 3.1
これらの質問は以下の7項目に分かれている。以下に各項目の代表的な質問を簡単に示す。全ての質問の詳細はDatasheets for Datasetsを見ていただきたい。
- Motivation
- そのデータセットはどのような目的で作成されたのか。特定のタスクを想定しているのか。
- データセットの作成に資金を提供したのは誰か。
- Composition
- データセットを構成するインスタンスは何を表しているのか。(例:文書、写真、人物、国など)
- 合計で何個のインスタンスが含まれるのか。
- 推奨されるデータ分割(例:Training, Validation, Test)はあるか。
- データセットにエラー、ノイズ、冗長性はあるか。
- Collection Process
- 各インスタンスに関連付けられたデータはどのように取得されたか。
- データセットがより大きなセットからのサンプルである場合、どのようにサンプリングしたのか。
- データは誰がどの期間に収集したものか。
- Preprocessing/cleaning/labeling
- データの前処理/クリーニング/ラベリングは実施されたか。
- 生データは保存されているか。生データへのリンクを提供できるか。
- データの前処理/クリーニング/ラベリングに利用したソフトウェアは利用可能か。
- Uses
- データセットはすでに利用可能か。
- データセットはどのようなタスクに利用可能か。
- データセットを使用すべきではないタスクはあるか。
- Distribution
- データセットはどのように配布されるのか。
- データセットにはDigital Object Identifier (DOI)があるか。
- データセットは、著作権またはその他の知的財産ライセンスなどに基づいて配布されているか。
- Maintenance
- 誰がデータセットをサポート/ホスト/メンテナンスしているのか。
- データセットの所有者/管理者/キュレーターに連絡するにはどうすればよいか。
- 他の人がこのデータセットに貢献したい場合、そうするための仕組みはあるのか。
上の例からわかるように、データセットの内容や使用目的だけでなく、前処理方法、配布方法、メンテナンス方法なども記述することが求められる。たとえ論文執筆時点で有用なデータセットを提案したとしても、すぐに使えなくなったり、誤りが修正されなかったり、他の人が開発に参加できなかったりといった状況は避けなければならない。このDatasheetsは、データセットの作成者にデータセットのAvailabilityやAccessibilityを継続的に担保することを宣言させる役割も担っている。
さいごに
今回は、私がNeurIPSのD&B Trackに2本の論文を投稿した経験をもとに、データ中心のAI研究に関する知見をまとめた。データ中心のAI研究は幅広く、またデータのドメインごとに異なるアプローチや知識が求められるため、ここで紹介する知見はあくまで限定的なものだと認識している。それでも、データ中心のAI研究に関する事例はまだ多くなく、モデル中心のAI研究との違いに戸惑うことも少なくないと感じている。この記事が、そのような場面で少しでも誰かの助けになれば嬉しい。
Discussion