信頼できるLLM-as-a-Judgeの構築に向けた研究動向
近年、大規模言語モデル(LLM)は自然言語処理から科学研究、教育、法律、金融まで幅広く応用され、その柔軟な生成能力は社会や研究のあり方を大きく変えている。しかし、その柔軟さゆえに出力の評価は難しい。最も確実なのは専門家によるマニュアル評価だが、コストと時間がかかりスケールしにくいという課題がある。この解決策として注目されているのがLLM-as-a-Judgeである。これは、LLMに「ジャッジ(評価者)」の役割を担わせ、人間のような文脈理解と判断力を活かしつつ自動化によるスケーラビリティを実現するアプローチである。しかし現状のLLM-as-a-Judgeは、まだ「信頼できる評価者」と呼ぶには課題が多い。本記事では、arXivにて2024年11月23日に初稿が投稿され、2025年3月9日に最新版(v5)として改訂されたサーベイ論文 「A Survey on LLM-as-a-Judge」 をもとに、信頼できるLLM-as-a-Judgeを構築するための研究動向と既存研究を整理する。
LLM-as-a-Judgeとは
近年、LLMは人間に近い推論や思考プロセスを模倣できるようになり、従来は専門家が担っていた「評価」という役割を担う可能性が注目されている。これがLLM-as-a-Judgeと呼ばれるアプローチである。LLM-as-a-Judgeとは、事前に定義されたルール、基準、または好みに基づいて、出力や行動を評価するためにLLMを使用することを指す。サーベイ論文では、LLM-as-a-Judgeを次のように形式化している。

ここで、
-
\varepsilon -
P_{LLM} -
x -
C x -
⊕ x C
を表している。実際に、LLM-as-a-Judgeを実施する際には、例えば次のようなプロンプト設計が典型的である。
- スコア付け
例:「以下の回答の有用性を1から5で評価してください」 - Yes/No判定
例:「この回答は事実に基づいていますか? YesまたはNoで答えてください」 - ペア比較
例:「どちらの要約がより記事の内容をよく反映していますか? 回答0または1を選んでください」
このように、LLM-as-a-Judgeは評価の形式を柔軟に設計できるため、人間のような細やかな判断を自動的にスケールさせる枠組みとして活用できる。
信頼できるLLM-as-a-Judgeの構築
改善戦略の分類
サーベイ論文では、LLM-as-a-Judgeの信頼性を高めるアプローチを3つに分類している。

出典:A Survey on LLM-as-a-JudgeのFig. 12
以下では、それぞれのアプローチを概観し、代表的な研究を紹介する。
プロンプト設計による最適化(Evaluation Prompts)
LLMを評価者として活用する際に最も直接的で効果的なのは、プロンプト設計の工夫である。特にfew-shotプロンプティングは、少数の高品質な例を与えることでモデルに評価基準を理解させ、性能を大きく向上させる手法として広く用いられている。例えば、[Fu+, 2024] では、LLMのin-context学習の能力を活用し、モデルの重み更新が不要なトレーニングフリーな方法で、多様な側面から生成されたテキストの品質を多角的に評価できるフレームワークであるGPTScoreを提案した。GPTScoreで得られる評価スコアは、LLMに「与えられたテキストを1から10でスコアをつけてください」のように直接プロンプトで指示してLLMが生成するスコアではない。GPTScoreのコアとなるアイデアは、事前学習済み生成モデルが、与えられた指示と文脈に従って、高品質な生成テキストにより高い生成確率を割り当てるというものであり、評価対象のテキストが特定の評価プロトコルに基づいて生成される条件付き生成確率によってスコアを算出する。論文中の実験では、評価LLMに与える手本となるサンプル(下図のDemonstrated Samples)が、in-context学習を通じて評価性能をさらに向上させることを実証している。
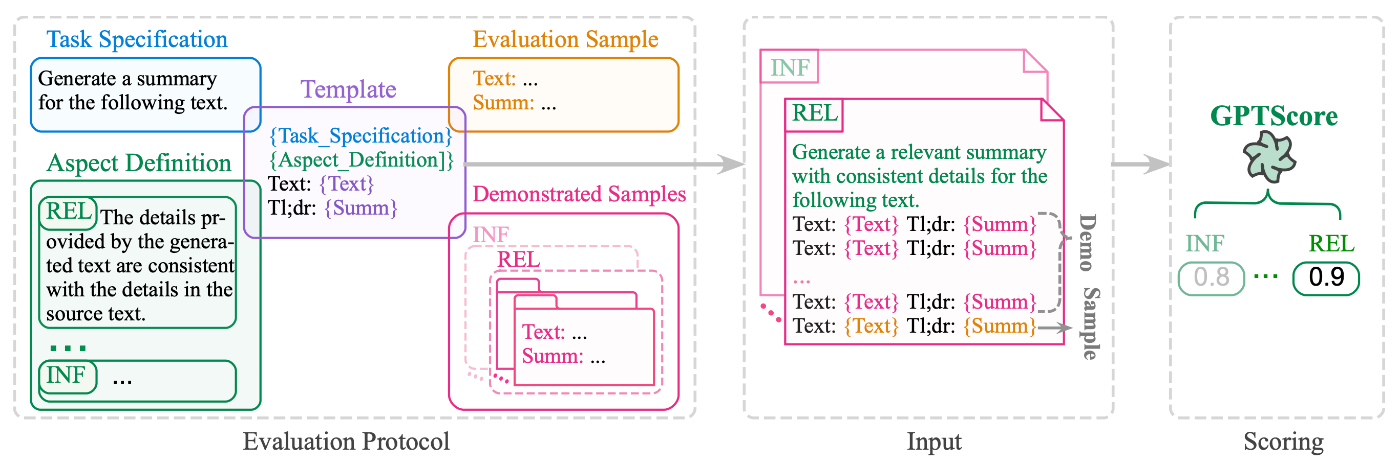
出典:[Fu+, 2024]のFigure 2
また、評価タスクの指示を洗練させることで、LLMの評価タスクに対する理解を高めるアプローチも有効である。[Liu+, 2023]で提案された評価フレームワークG-Evalは、タスクの概要と評価基準をプロンプトとしてLLMに与えるだけで、LLMが詳細な評価手順をChain-of-Thought (CoT) 形式で自動生成し、このCoTとプロンプトを用いて自然言語生成の出力を評価する仕組みである。実験では、テキスト要約と対話生成という2つのタスクにおいて、人間による評価との高い相関が示された。また本研究は、LLMが人間の作成したテキストよりもLLMが生成したテキストを不当に高く評価する傾向を指摘している点がおもしろい。

出典:[Liu+, 2023]のFigure 1
さらに、LLMがもつ固有のバイアスは、評価の公平性を損なう重大な課題であり、その抑制は重要である。LLMがもつバイアスの代表例は、位置バイアス(position bias) である。これは、LLMによる評価結果は、評価対象となる応答の提示順序に強く依存し、順序を入れ替えるだけで評価結果が変わってしまう現象を指す。[Wang+, 2024]では、GPT-4は最初に提示された応答を好む傾向があり、ChatGPTは2番目の応答を好むと報告した(下表参照)。また、この研究では、位置バイアスを定量化するために応答の順序を入れ替えて2回評価を行い、結果が食い違う割合を 「競合率」 と定義した。実験の結果、Vicuna-13BとChatGPTを比較した際、GPT-4の競合率は46.3%、ChatGPTでは82.5%に達することが確認された。さらに、この研究では、この問題を軽減するために3種類のキャリブレーションフレームワークを提案している。例えば、直感的な手法であるBalanced Position Calibration (BPC)は、2つの候補応答を両方の位置で評価し、その平均を最終スコアとすることで位置依存を打ち消す仕組みである。実験により、これらのキャリブレーションを適用するとLLM評価と人間の判断との整合性が大幅に向上することが示された。
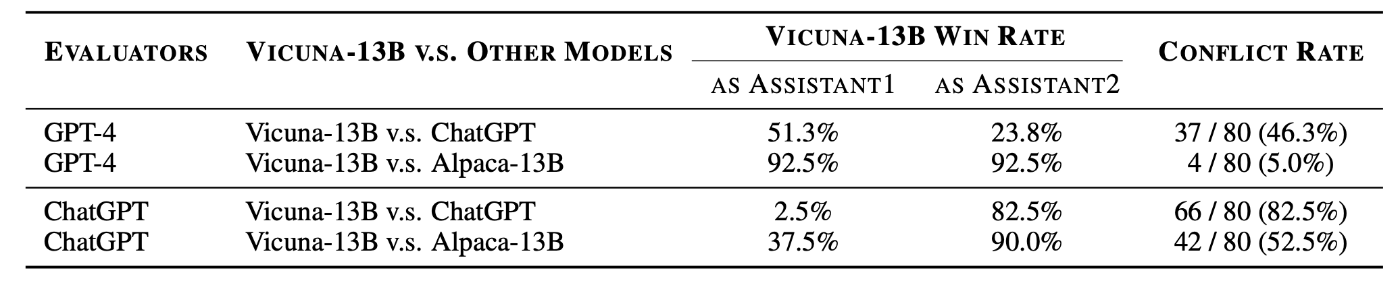
出典:[Wang+, 2024]のTable 2
モデルの改善(LLMs’ evaluation capabilities)
プロンプト設計に加えて、評価に用いるLLMそのものを改善するアプローチも盛んに研究されている。もっとも直接的な方法は、メタ評価データセットを用いたファインチューニングである。メタ評価データセットとは、評価タスクに特化した訓練データであり、入力(質問やタスク)、生成物(回答や出力)、そして人間または強力なLLMによる評価結果を組み合わせたものを指す。評価用LLMをファインチューニングする戦略では、メタ評価データセットの収集と構築が鍵となる。一般的な手法としては、公開データセットから評価問題を抽出し、それを特定のテンプレートで整形したうえで、手動のアノテーションやGPT-4のような強力なモデルによる評価結果を補完データとして追加する。
代表例な既存研究は、PandaLM [Wang+, 2024]やOffsetBias [Park+, 2024]、JudgeLM [Zhu+, 2025]が挙げられる。JudgeLMでは、まず大量のシードタスク(質問)を収集し、11種類のLLMから生成された回答を抽出、その中から回答ペアをランダムにサンプリングする。次に、タスク・回答ペアをGPT-4に入力し、教師モデルとして評価スコアと判断理由を生成することで高品質なメタ評価データセットを構築する(下図(a))。次に、このデータセットを用いてLLMをファインチューニングする(下図(b))。ファインチューニングの過程では、LLMが陥りやすい位置バイアス・知識バイアス・フォーマットバイアスを軽減するために、「スワップオーグメンテーション」「参照サポート」「参照ドロップ」といった手法が導入されている。これにより、JudgeLMはより一貫性が高く、公平で柔軟な評価者として機能することを目指している。

出典:[Zhu+, 2025]のFigure 1
JudgeLMの論文を読んでいると、GPT-4を教師モデルとしてその評価スコアを用い、知識蒸留のようにファインチューニングするのであれば、「そもそもGPT-4で直接評価すればよいのではないか」という疑問が浮かぶ。しかし論文では、GPT-4をそのまま評価に使う場合と比べて、JudgeLMを用いる利点がいくつか示されている。まず、GPT-4のようなクローズドソースのLLMをAPI経由で利用すると、モデル更新やアクセス制限によって評価の再現性が損なわれやすいが、JudgeLMはオープンソースモデルとして公開できるため、再現性が確保しやすい点が大きな利点である。次に、評価に必要なコストの面でも、GPT-4を用いるよりも大幅に低コストで大規模な評価を実行できる。さらに、JudgeLMはファインチューニング段階で位置バイアス・知識バイアス・フォーマットバイアスといった問題に対処する技術を組み込んでおり、その結果としてGPT-4をそのまま利用するよりも、偏りの少ない一貫した評価を行えることが期待される。
他のアプローチとして、モデルを一度学習させた後に、評価結果のフィードバックを利用して反復的に最適化する戦略もある。[Xu+, 2023]は、その代表例としてINSTRUCTSCORE を提案した。INSTRUCTSCOREでは、まずLLMに評価タスクを実行させ、その結果を収集する。次に、評価が失敗したケースに対して、GPT-4のような強力なLLMを用いて「どの点が誤っていたか」「正しい評価はどのように導けるか」といった形で詳細なフィードバックを生成する。このフィードバックを新たな学習データとして取り込み、モデルを再度ファインチューニングすることで、評価能力を段階的に改善していく仕組みである。このアプローチの利点は、単に大規模データで初期学習を行うのではなく、モデルが犯した具体的な誤りを矯正するプロセスを組み込める点にある。結果として、モデルはより堅牢で人間の判断に近い評価者として機能することが示されている。

出典:[Xu+, 2023]のFigure 2
出力後の最適化(Final evaluation results)
最後に、LLMの出力を事後処理によって安定化させるアプローチがある。LLMの生成にはランダム性が伴うため、同じ入力でも評価結果が揺れる場合がある。この不安定性を抑える最も一般的な方法は、複数の評価結果を統合する戦略である。もっとも単純な方法としては、同一入力に対して複数回の評価を実行し、それらを統合することでランダム性の影響を軽減する。さらに、単一モデルを繰り返し用いるだけでなく、複数のLLMを並行して評価者として活用する手法も有効であることが示されている。
例えば、[Bai+, 2023]は、オープンエンドな質問応答における基盤モデルの性能を評価するための新しいベンチマークフレームワーク 「Language-Model-as-an-Examiner」 を提案している。このフレームワークでは、LLMが「試験官」として自ら多様なドメインから質問を生成し、回答を評価する仕組みを持つ。さらに、複数の異なるLLMを相互に評価させ、その結果を投票によって集約する 「分散型ピアレビュー」 を導入し、単一モデルに依存した評価の偏りを軽減している。分散型ピアレビューでは、各モデルが順番に試験官となり、他モデルの回答を評価することで多様な観点が取り込まれ、より公平でバランスの取れた評価が実現される。

出典:[Bai+, 2023]のFigure 1
また、LLMの出力を直接最適化するアプローチとして、自己検証(self-verification) は、不安定な評価結果を取り除く手法として利用できる。これは、モデル自身に「この評価は正しいか」を再確認させ、信頼性の低い結果を排除する仕組みである。[Gekhman+, 2023]では、その一例としてTrueTeacherが提案された。TrueTeacherは、生成モデルが実際に出力した要約をLLMに評価させ、その判定結果をもとに新たな合成データを構築する方法であり、多様で現実的な誤りを含む学習データの生成を目的としている。実験では、このデータで訓練したモデルが教師役の大規模なLLMを上回る性能を示し、その有効性とロバスト性が実証されている。

出典:[Gekhman+, 2023]のFigure 1とFigure 4
さいごに
本記事では、サーベイ論文 「A Survey on LLM-as-a-Judge」 を参考に、信頼できるLLM-as-a-Judgeを構築するための研究動向を整理した。プロンプト設計の工夫によってモデルがより正確に評価タスクを理解できるようにする試み、評価専用データセットを活用してLLM自体を評価タスクに特化させるアプローチ、さらには出力結果を複数回・複数モデルで統合することで不安定性を緩和する事後処理戦略など、多層的な改善の方向性が示されている。これらは独立ではなく、組み合わせて活用することでさらに堅牢な評価フレームワークが実現できると期待されている。
Discussion