時系列データのための大規模言語モデル
近年の大規模言語モデル(LLM)の出現は、自然言語処理(NLP)においてパラダイムシフトをもたらし、ChatGPTをはじめとする様々な革新的サービスを生み出している。LLMの急速な進化は、NLPの領域を超えて、より広範なデータモダリティへのLLMの適用可能性を探る研究への発展を促している。その中で今回注目したのが、時系列データへのLLMの適用である。例えば、[Gruver+, 2023] では、GPT-3やLLaMA-2などの既存のLLMが、ダウンストリームタスクで教師あり学習した時系列モデルの性能に匹敵するか上回るレベルで、zero-shotで時系列予測ができることを報告しており、大変興味深い。本ブログでは、2024年に公開されたサーベイ論文「Large Language Models for Time Series: A Survey」を参考にLLM for Time Seriesの全体像を整理し、いくつか注目すべき論文について個別に紹介する。
はじめに
時系列データとは、時間の推移とともに観測されるデータのことで、株価・為替などの金融データや、気温・雨量などの気象データ、脳波・心電図などの医療データなど、様々な実世界の分野で広く利用されている。そのため、時系列データの分類や将来予測、クラスタリング、異常検知、欠損値の補完などのタスクを解くことを目的とする時系列分析は、幅広い分野における予測や意思決定に重要な役割を果たしている。
「Position: What Can Large Language Models Tell Us about Time Series Analysis」から引用した以下の図は、時系列分析のための4つの世代のモデルの発展を示している。
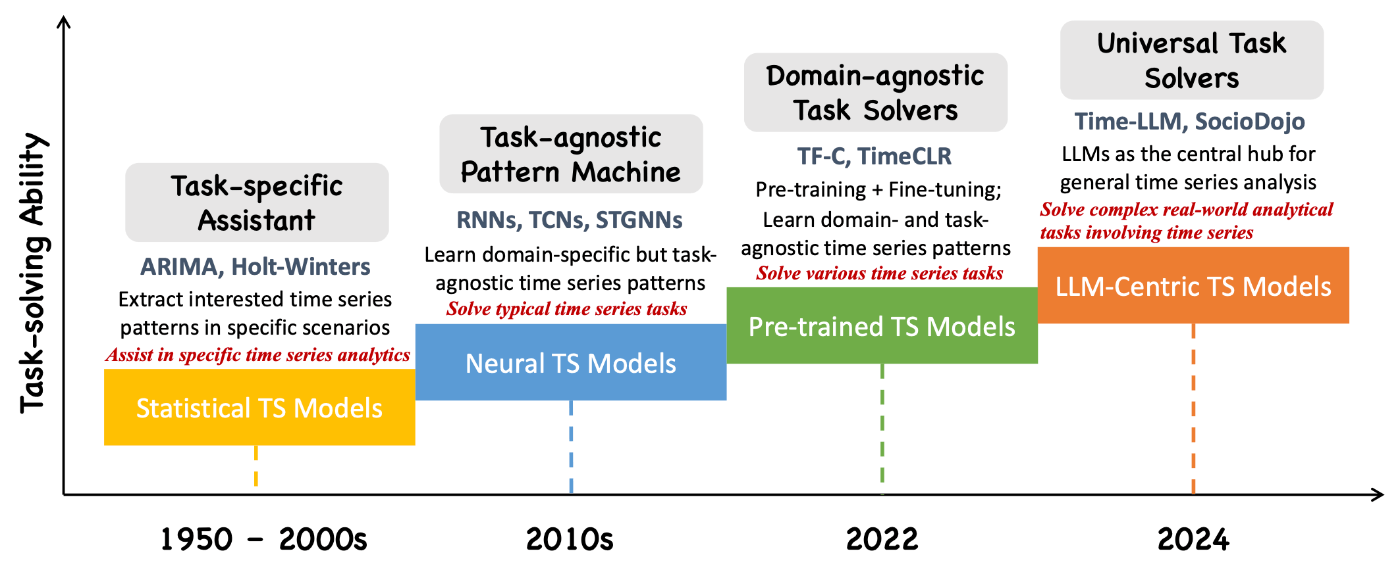
出典:[Jin+, 2024]のFigure 3
Statistical TS Models: 2000年以前の時系列分析は、ARIMAなどの統計モデルをタスクごとに設計することが主流であった。この統計モデルの設計や、モデルに入力する特徴量の設計は、特定のドメインや専門知識に大きく依存していた。
Neural TS Models: その後、リカレントニューラルネットワーク(RNN)などの深層学習モデルの時系列分析への適用が急速に進んだ。深層学習では、統計モデルや従来の機械学習手法とは異なり、手間と時間のかかる特徴量エンジニアリングを必要とせず、データ駆動で自動的に複雑な非線形関係や時間的依存関係を捉えられるため、様々な時系列分析のタスクにおいて成功を収めた。一方、深層学習モデルが高い性能を発揮するためには、膨大なラベル付きデータセットを用いた学習が必要である。しかし、一般にデータ収集やアノテーションには多くの時間やコストがかかるため、十分なラベル付きデータセットを構築することが困難な場合がある。
Pre-trained TS Models: 近年のNLPの分野では、BERTやGPTに代表されるTransformerベースの事前学習モデルが主流である。事前学習では、大規模なラベルなしデータセットから汎用的な言語表現を学習し、その後、少量のラベル付きデータセットを用いたファインチューニングにより特定のタスクに適応させる。この学習アプローチにより、データ収集やアノテーションの時間とコストが大幅に削減される。このような自然言語分野の発展に触発されて、[Yeh+, 2023] のような最近の研究では、大規模な時系列データでのモデルの事前学習を導入し、比較的少量のラベル付きデータセットで特定のタスクのためのファインチューニングを実行している。
LLM-Centric TS Models: 最後は、本ブログの主題であるLLMを用いた時系列分析(LLM for Time Series)であり、以降このアプローチについてのみを深掘りしていく。
LLM for Time Seriesの分類
サーベイ論文「Large Language Models for Time Series: A Survey」では、下図のように時系列データのための大規模言語モデルに関する既存研究を5つのカテゴリに分類している。
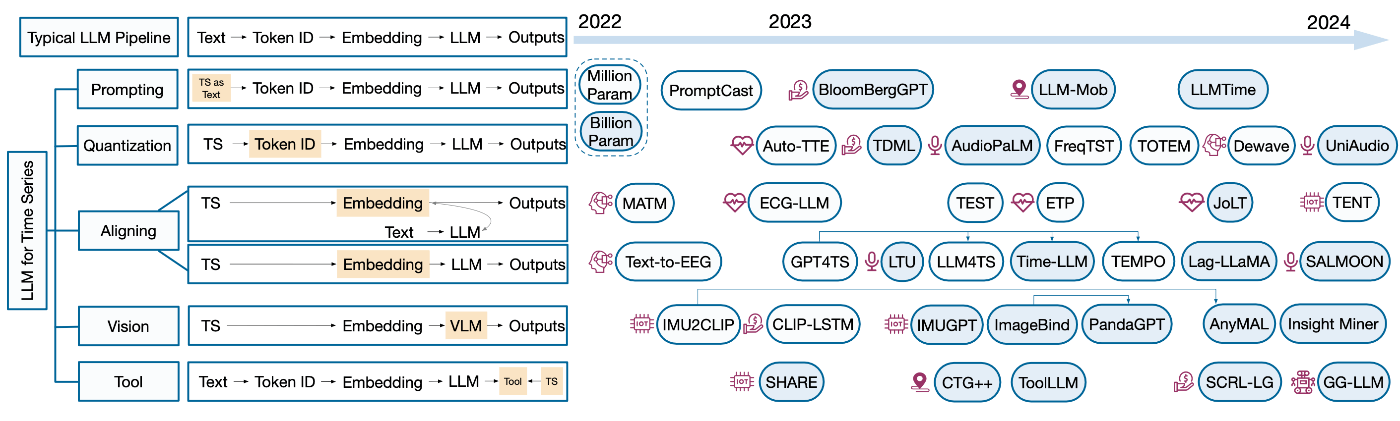
出典:[Zhang+, 2024]のFigure 2
LLMを用いた典型的なNLPパイプラインを5つのステージ「入力テキスト → トークン化 → 埋め込み → LLM → 出力」に分けて考えると、上記の分類による各カテゴリは、このパイプラインの特定のステージをターゲットにしている。以下、それぞれのカテゴリについての概要と代表的な研究を紹介する。
1. Prompting
Promptingは、数値的な時系列データをテキストデータとして取り扱い、LLMにプロンプトとして直接入力するアプローチである。[Xue+, 2023] は、時系列データをテキストプロンプトに変換し、sentence-to-sentenceの形式で時系列予測を行うPromptCast(詳細は後述)を提案した。入力プロンプトは、下の気温を予測する例のように、事前に定義されたテンプレートに従ったコンテキストと質問で構成される。

出典:[Zhang+, 2024]のTable 1から抜粋
同様のプロンプティングの方法として、TabLLMは、テーブルデータを自然言語の文字列にシリアライズして、LLMにプロンプトとして入力し、few-shotおよびzero-shotでテーブルデータの分類を行う。また、[Zhang+, 2023] では、人間の移動軌跡のデータをプロンプトとしてLLMに入力し、異常行動を検出する方法を提案した。
最近の注目すべき研究は、数値的な時系列データのトークン化の方法に着目している。LLMTime(詳細は後述)は、Byte Pair Encoding (BPE)を用いたトークン化では、異なる浮動小数点数間でトークン化に一貫性がないことを指摘しており、各数字に異なるトークンが割り当てられるように数字の間にスペースを入れることを提案した。その結果、GPT-3やLLaMA-2などの既存のLLMが、ダウンストリームタスクで学習した時系列モデルの性能に匹敵するか上回るレベルで、zero-shotで時系列予測ができることを報告した。
2. Quantization
このアプローチは、数値的な時系列データを離散インデックスに変換し、特別なトークンとして扱う。サーベイ論文では、既存研究を採用する離散化の方法に基づき分類している。その中でも、下図のように[Oord+, 2017]で提案されたVector Quantized-Variational AutoEncoder (VQ-VAE)に基づく手法がよく利用される。
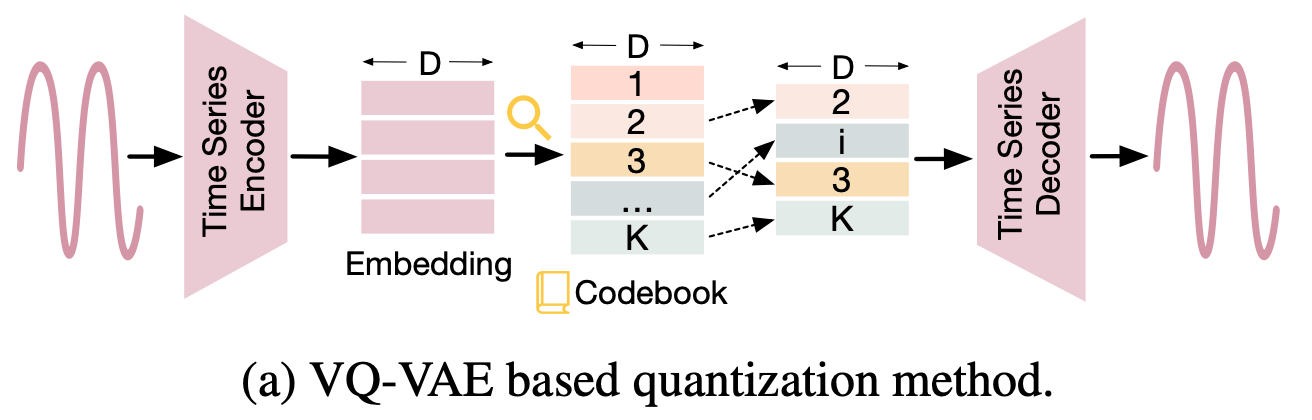
出典:[Zhang+, 2024]のFigure 3(a)
例えば、[Duan+, 2023] は、VQ-VAEを用いてElectroencephalography (EEG)波(脳波)を離散インデックスに変換する。そして、この脳波の離散表現を自然言語に翻訳するためのフレームワークであるDeWaveを提案した。このような脳のダイナミクスを自然言語に変換することは、ブレイン・コンピュータ・インターフェイス(BCI)の分野において重要なタスクである。
他の離散化の方法として、下図に示したようなk-means法によるクラスタリングを利用する手法が研究されている。このk-means法を用いたアプローチは特に音声分野の研究で利用されており、例えば、SpeechGPTやAudioLMなどがある。
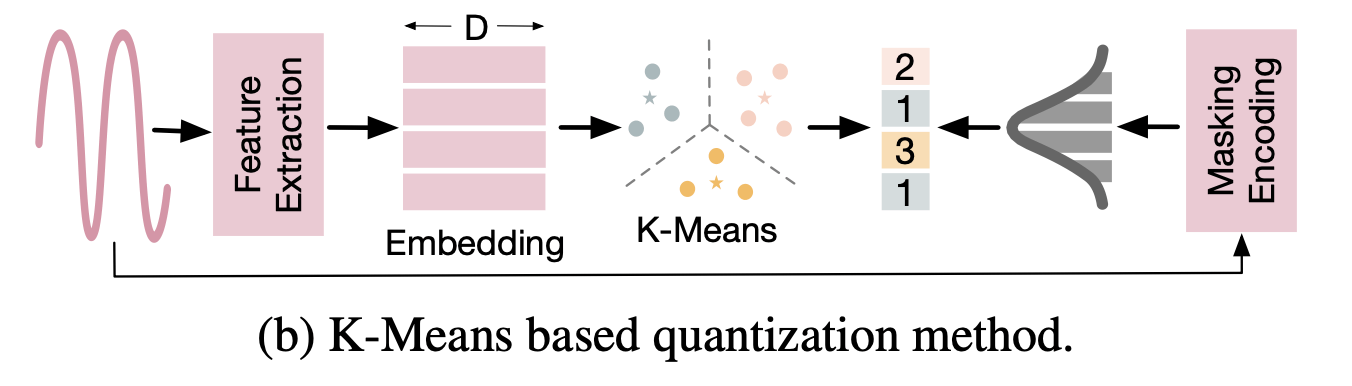
出典:[Zhang+, 2024]のFigure 3(b)
3. Aligning
このアプローチでは、時系列データ用に個別にエンコーダを学習し、エンコードされた時系列データを言語モデルの意味空間に整合させる。既存研究は、時系列データと言語空間を整合させるための戦略に基づき分類される。一つ目の方法は、下図に示したように、時系列埋め込みとテキスト埋め込みを、Contrastive Lossを最小化することによる類似性マッチングによって整合させる。
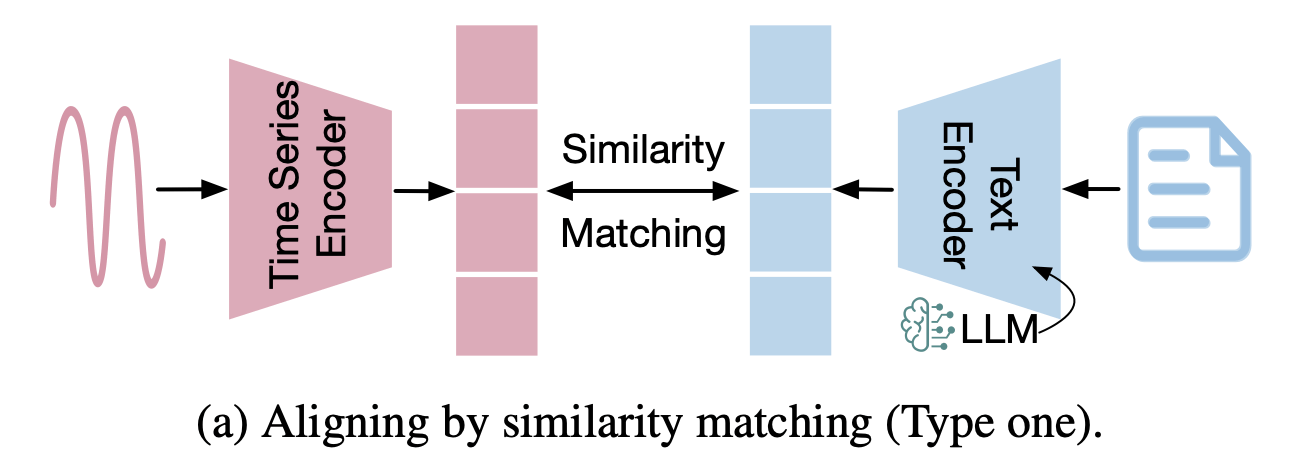
出典:[Zhang+, 2024]のFigure 4(a)
例えば、[Liu+, 2024]で提案されたETPは、心電図(ECG)シグナルとテキスト形式のレポートを整合させるために、対照学習に基づく事前学習を行っている。[Zhou+, 2023]で提案されたTENTは、対照学習を用いて統合されたセマンティック特徴空間を通して、テキスト埋め込みとIoTセンサー信号を整合させる。また、Contrastive Loss以外の損失関数を類似性マッチングの最適化のために利用した研究もある。例えば、[Han+, 2023] で提案されたMTAM(詳細は後述)は、脳波の特徴と対応する言語記述を整合せさせるために、正準相関分析やWasserstein距離を利用した。
時系列データと言語空間のモダリティ間を整合させるもう一つのアプローチは、下図に示したようにLLMを時系列埋め込み層に続くバックボーンとして直接使用する方法である。
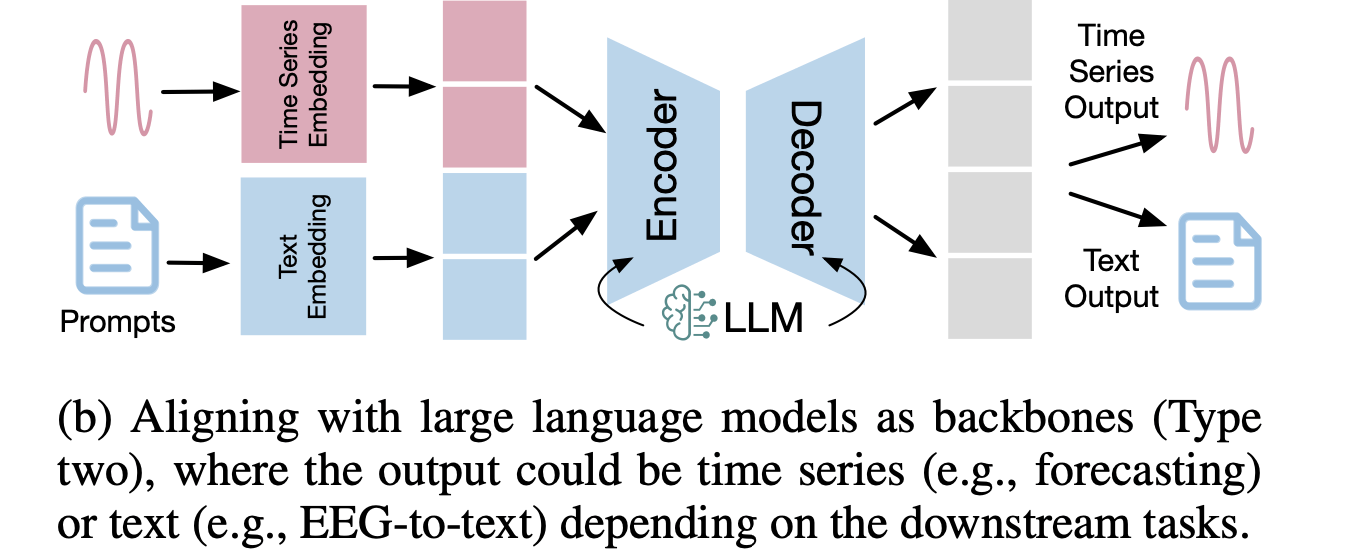
出典:[Zhang+, 2024]のFigure 4(b)
[Zhou+, 2023] は、大規模なデータで事前学習した言語モデルを時系列データ分析に適用するために、transformerブロックのself-attentionおよびfeedforward層の重みを固定した事前学習済みモデルをファインチューニングする手法を提案した(詳細は後述)。本手法は、時系列分類や異常検出を含む7つの主要な時系列分析タスクにおいて、最先端のベースラインモデルと同等か、それ以上の性能を達成したことを報告した。この研究に続くように、季節性トレンド分解(TEMPO)、2段階ファインチューニング(LLM4TS)、グラフアテンションメカニズム(GATGPT)などの要素が導入された発展的な研究が盛んに進められている。
4. Vision
このアプローチは、LLMを時系列データに適用するための橋渡し役として時系列データの視覚的な表現を活用する。特に画像は、他のデータモダリティに比べて、言語モデルとの統合に関する研究が盛んであるため、時系列データを画像で表現することで、それらの研究成果の恩恵を受けられる。例えば、[Wimmer+, 2023]では、株式市場データをテキストと株価チャートの画像にそれぞれ変換し、CLIP (Contrastive Language-Image Pretraining)ベースの視覚言語モデルを用いて株式指数の予測を行った。
5. Tool
このアプローチでは、LLMを直接時系列データの処理に使うわけでなく、時系列データに関連するタスクに役立つコードやAPIコールなどの間接的なツールを生成するためにLLMを利用する。例えば、[Qin+, 2024]は、LLMがAPIなどの外部ツールを使用して、複雑な人間の指示を遂行する能力を向上させるために、データ構築、モデル学習、評価を含む包括的なツール使用のフレームワークであるToolLLMを提案した。このフレームワークには、天気予報や株価予測などの時系列タスクのためのAPIコールが含まれている。
関連論文の個別紹介
ここからは、特に面白いと感じた論文を個別に紹介する。上記の分類のうち、Promptingの論文を2本、Aligningの論文を2本紹介する。
PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting [Xue+, 2023] (Prompting)
従来の時系列予測モデルは通常、下図(a)のように数値データを入力として受け取り、数値を出力するが、本論文では、下図(b)のように数値データを自然言語のプロンプトに変換し、言語モデルを用いて、sentence-to-sentenceの形式で時系列予測を行うPromptCastを提案した。PromptCastは、一般的な時系列予測問題を自然言語生成の形式で取り扱った先駆的な研究である。
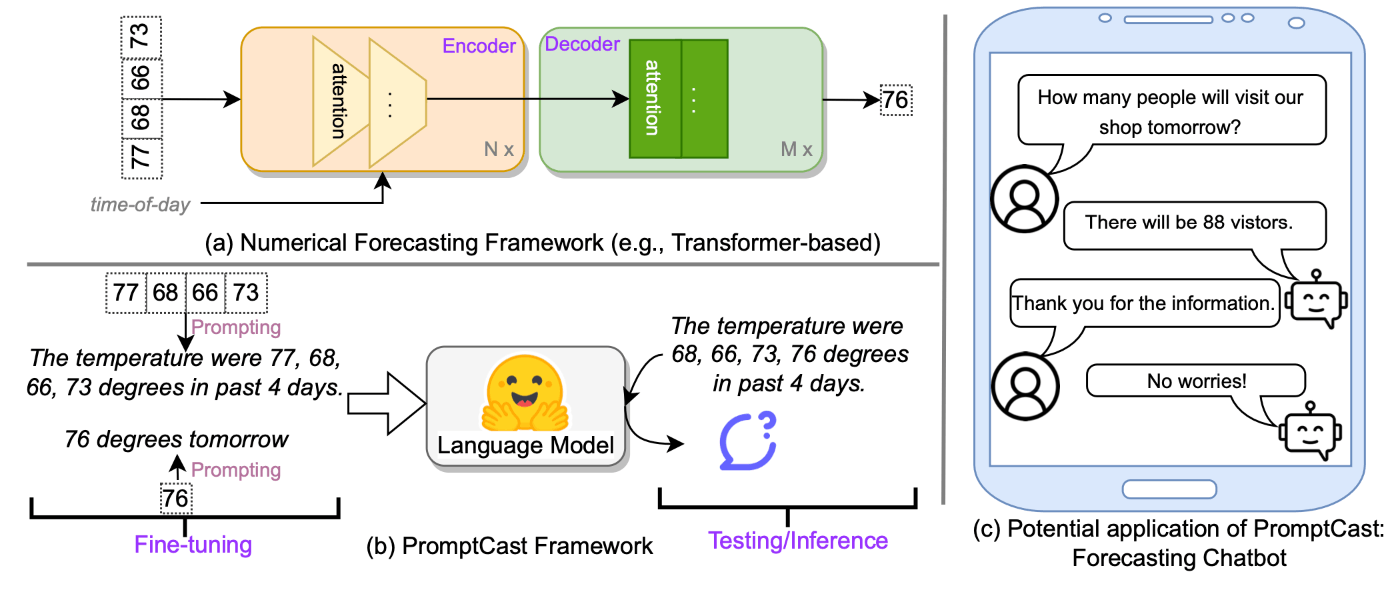
出典:[Xue+, 2023]のFigure 1
言語モデルの入力・出力プロンプトは、下表のように事前に定義されたテンプレートを用いる。具体的には、入力プロンプトは、コンテキスト部分と質問部分に分けることができ、コンテキスト部分は予測のための過去の情報を提供し、質問部分は未来に関する入力クエリとみなすことができる。出力プロンプトは、質問に対する答えとなる予測値もしくは真の正解値を含む文章になっている。

出典:[Xue+, 2023]のTable 1
本論文では、提案手法を評価するために、上述したテンプレートに従った大規模データセットであるPISA (Prompt based tIme Series forecAsting)を公開している。このデータセットは、気温予測、エネルギー消費予測、および顧客フロー予測の3つの実世界の予測シナリオが含まれている。PISAを用いたベンチマークの結果、PromptCastの設定における言語モデルは、時系列予測において従来の数値ベースの手法に匹敵する性能を達成し、特にzero-shot予測の設定で優れた汎化性能を持つことが報告された。
Large Language Models Are Zero-Shot Time Series Forecasters [Gruver+, 2023] (Prompting)
本論文は、時系列データを数値の文字列としてトークン化し、時系列予測のタスクを次トークン予測問題として捉えることで、事前学習したLLMを時系列予測に適用するLLMTimeという手法を提案した。数値をトークン化してLLMにプロンプトとして入力し、ファインチューニングせずにLLMを時系列の予測器として用いている点はPromptCastと同じであるが、LLMTimeは数値以外の追加のテキストやプロンプトエンジニアリングが必要ない点がPromptCastと異なる。下図は、LLMTimeの概要図と簡易的な実験結果を示している。
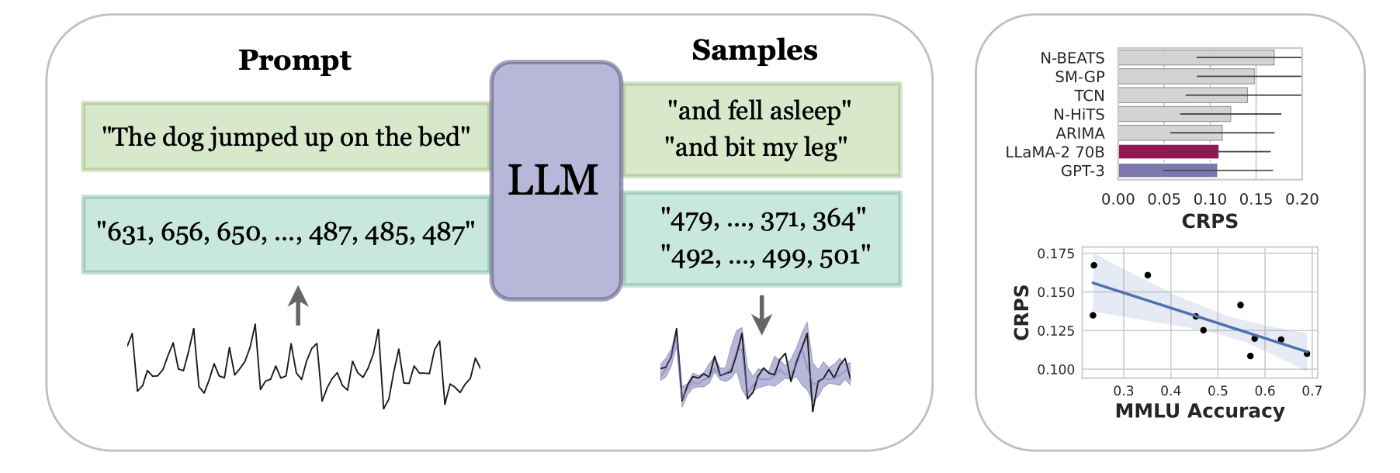
出典:[Gruver+, 2023]のFigure 1
LLMTimeの主要な特徴の一つは、時系列データを効率的に数値の文字列としてエンコードする手法を提案している点にある。本論文では、広く利用されているトークン化手法であるBPEは、学習データ中の出現頻度に基づいて数値をトークン化するため、基本的な数値演算の学習を困難にするようなチャンクに分解されてしまうことを指摘している。例えば、GPT-3のトークナイザーでは数値42235630は、[422, 35, 630]にトークン化され、1桁でも数字が変わると全く違うトークン化になる可能性がある。一方、LLaMAでは、数値は個々の数字にトークン化されるように設計されており、これによりLLMの数学的な能力が向上する。LLMTimeでは、各桁をスペースで区切って強制的に数字ごとにトークン化し、時系列の各時間ステップをカンマ(" ,")で区切る。また、固定精度の場合、小数点は冗長となるため、コンテキストの長さを節約するためにエンコード時に小数点を削除する。したがって、たとえば精度が2桁の場合、トークナイザーに渡す前に時系列を次のように前処理する。
0.123, 1.23, 12.3, 123.0 → " 1 2 , 1 2 3 , 1 2 3 0 , 1 2 3 0 0"
下図は、このエンコーディングで追加されたスペースがGPT-3にとって有用であることを示している。一方、LLaMAの場合は、その独自のトークン化により各数字とスペースにはすでにトークンが割り当てられているため、追加されたスペースは逆の効果をもたらすようである。
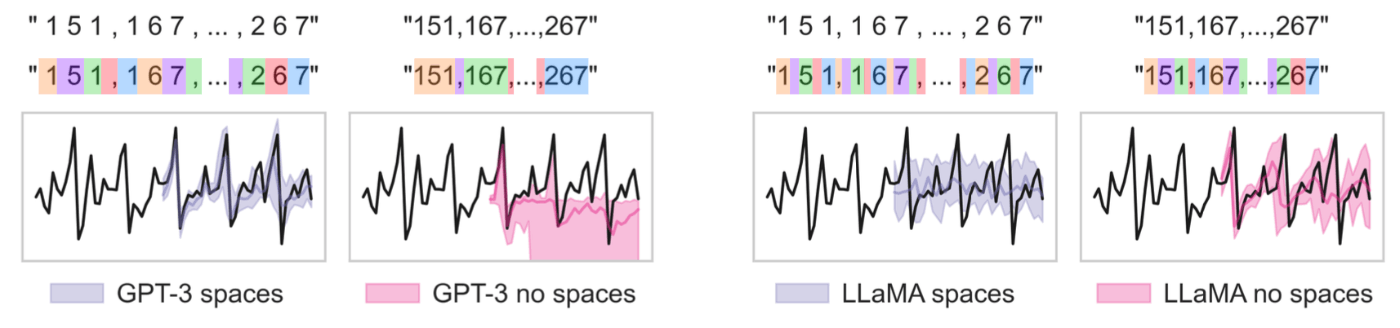
出典:[Gruver+, 2023]のFigure 2
LLMTimeのzero-shot予測の性能を評価するために、Darts、Monash、Informerの三つのベンチマークデータセットを用いた。以下の実験結果の通り、ベースモデルとしてGPT-3またはLLaMA-2 70Bを使用したLLMTimeは、いくつかのベースラインとなる時系列モデルとの比較において、zero-shotでありながら最高または2番目に優れた性能を示した。
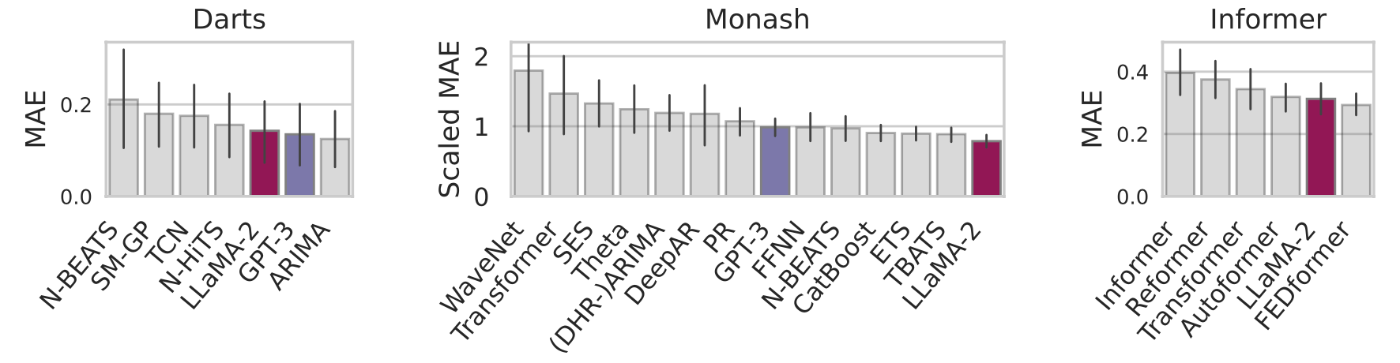
出典:[Gruver+, 2023]のFigure 4
本論文では、LLMがzero-shotで時系列の外挿に成功した要因の一つとして、LLMはシンプルで繰り返しのあるパターンを好むバイアスを持っており、これが季節性やトレンドなどの多くの時系列データが持つ特徴と一致するためであると主張している。また、一般にモデルサイズを大きくすることで、時系列の予測性能が向上することがわかったが、GPT-4はGPT-3よりも性能が低下することが報告されている。
Can Brain Signals Reveal Inner Alignment with Human Languages? [Han+, 2023] (Aligning)
脳活動は、人間の言語がどのように表現され、解釈されるかについての理解を深める上で重要な要素である。本論文は、EEG(脳波)と言語の2つのモダリティ間の関係性と依存性を探求するために、MTAM(Multimodal Transformer Alignment Model)を提案した。下図は、MTAMのモデルアーキテクチャを示している。
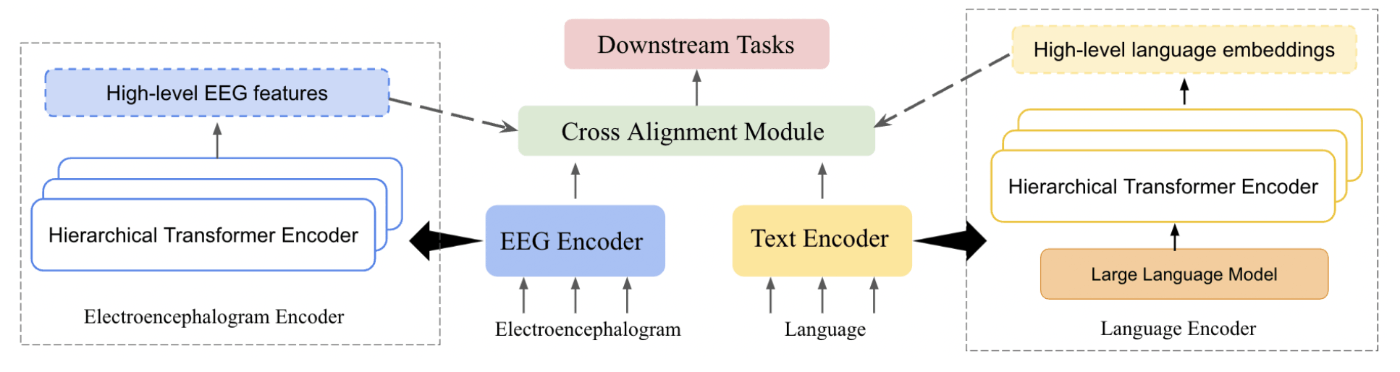
出典:[Han+, 2023]のFigure 1
まず、入力となるEEGとテキストは、それぞれ別々の階層型Transformerエンコーダーで処理される。EEGと言語のエンコーダの違いとして、言語側では事前に学習されたLLMでテキストを処理してテキスト埋め込みを抽出したのちに、階層型Transformerエンコーダーを使ってテキスト埋め込みを高レベルの特徴量に変換している。それぞれのエンコーダの出力は、Cross Alignment Moduleに入力される。このCross Alignment Moduleは、2つのモダリティ間の接続性に基づく損失関数を通じて脳波と言語との間の内部関係を探索するために設計されている。具体的には、正準相関分析とWasserstein距離が損失関数として用いられている。最後に、変換された特徴量がダウンストリームタスクに使用される。
評価のためのダウンストリームタスクとして、二つの公開データセットZuCoおよびK-EmoConを用いた感情分析と関係検出が採用された。下表に示した評価結果により、どちらのタスクにおいてもMTAMはベースラインとなる手法を上回り、特にEEGと言語それぞれ単一のモダリティを用いたモデルよりも、両方を用いたマルチモーダルなモデルの方が性能が高いことが示された。
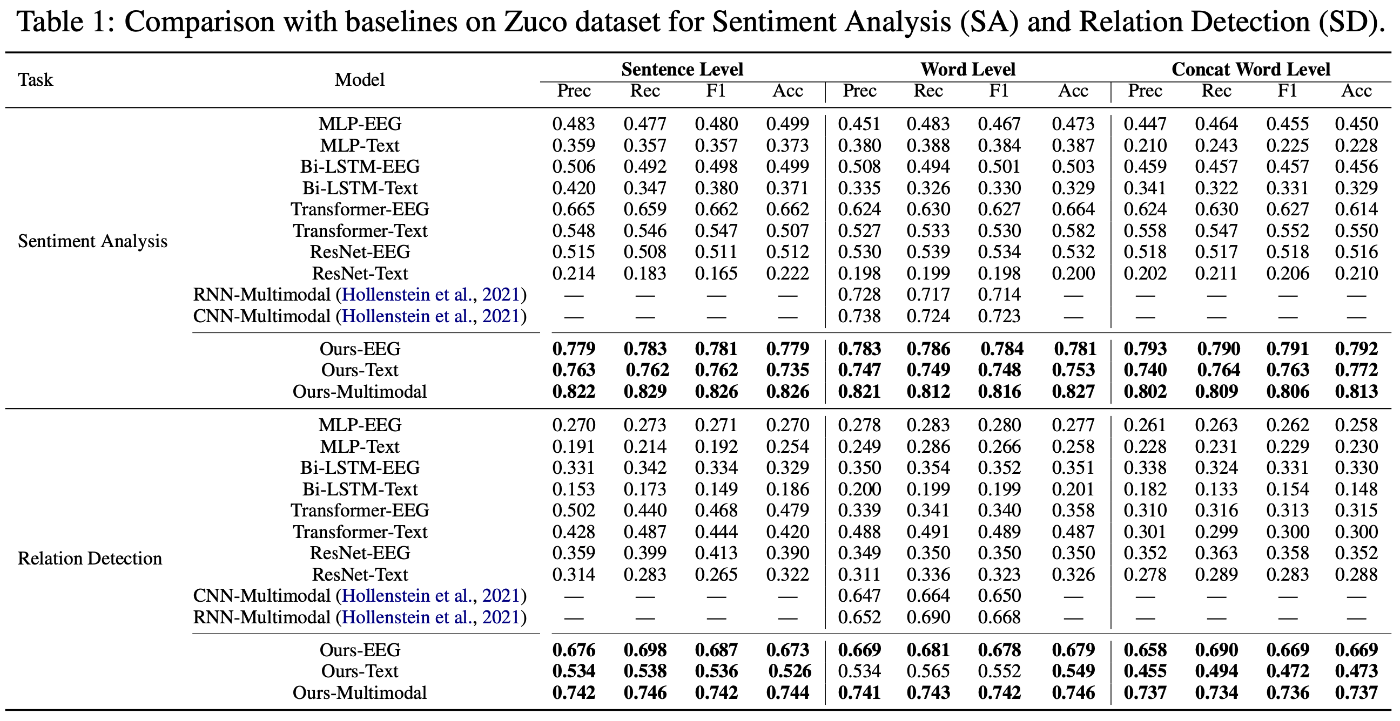
出典:[Han+, 2023]のTable 1
One Fits All:Power General Time Series Analysis by Pretrained LM [Zhou+, 2023] (Aligning)
NLPやコンピュータビジョン(CV)の分野では大規模な事前学習済みモデルが大きな成功を収めているが、時系列分析の分野では、膨大な学習データが存在しないため、事前学習済みモデルの適用はNLPやCVほど進んでいない。この課題を克服するために、本論文では、大規模なデータで事前学習された言語モデルをファインチューニングにより時系列分析に適用させる。具体的には、事前学習済みモデルのtransformerブロックのself-attentionおよびfeedforward層は、学習された知識の主要な部分を含んでいるため、これらの層の重みを固定したFrozen Pretrained Transformer (FPT)を用いる。そして、下図に示したように位置埋め込み層、正規化層、出力層のみをファインチューニングすることで、時系列タスクに適応させる。
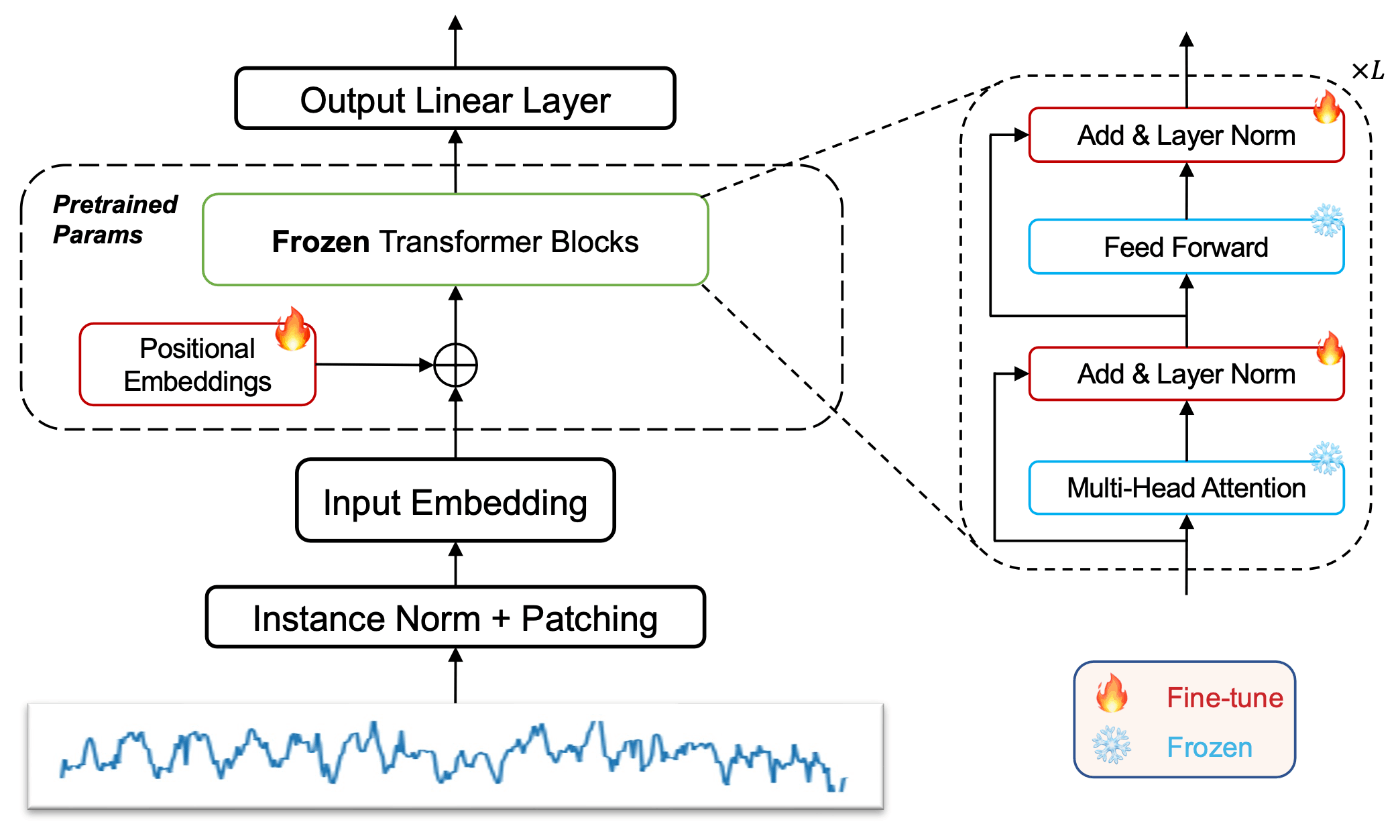
出典:[Zhou+, 2023]のFigure 2
入力する時系列データは、局所的な意味情報を抽出するために、隣接するタイムステップを集約して1つのパッチベースのトークンを形成するpatching([Nie+, 2022])という技術を用いる。その後、平均と分散を用いて入力時系列を正規化する。また、NLPのために事前学習したモデルを時系列データのモダリティに適用させるために、入力埋め込みの層を再設計・学習している。この層は入力時系列データを特定の事前学習モデルが必要とする次元へとマッピングする役割も持つ。
モデルの性能評価のために、時系列分類、異常検出、データ補完(インピュテーション)、短期/長期予測、few-shot/zero-shot予測の7つのダウンストリームタスクを用いた。提案手法では、言語モデルとしてGPT-2をバックボーンとするFPTを用い、最先端の時系列モデルを含む多様なベースラインモデルとの性能比較を行った。下図は、評価結果のサマリーである。
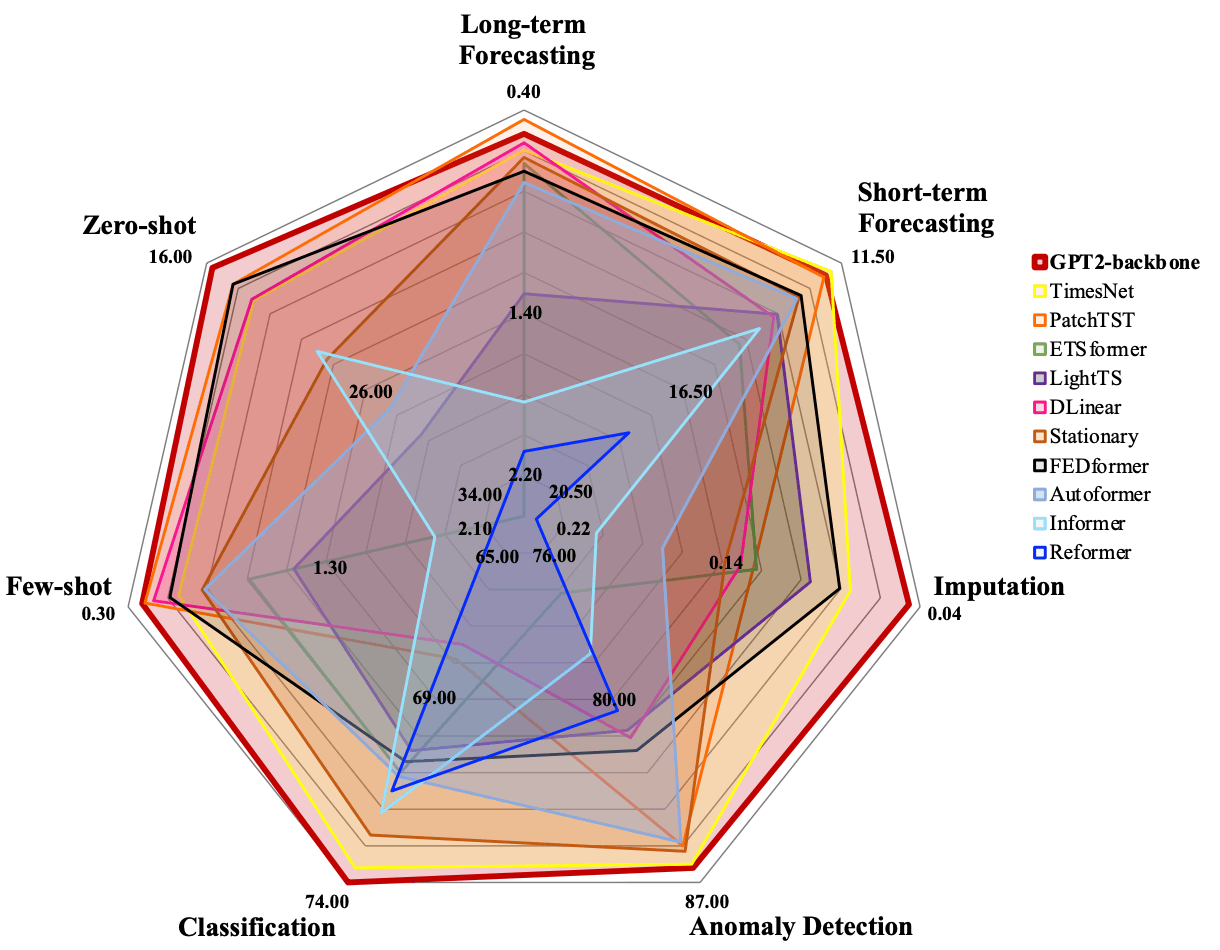
出典:[Zhou+, 2023]のFigure 1
提案手法(GPT2-backbone)は、ほとんどのタスクにおいて他のモデルを上回る性能を達成し、言語から時系列データのモダリティ間の知識転移が有効であることが確認された。また、事前学習済みモデルのモダリティ間の知識転移の一般性を理解するために、BERTベースのFPTおよび画像で事前学習したBEiTベースのFPTを用いた評価実験も行っている。結果は興味深いことに、下表に示した通り、どちらのモデルも最先端モデルの一つであるPatchTSTに匹敵し、他のモデルを上回る結果になった。特に、時系列予測において成功する知識移転のドメインは自然言語に限定されず、画像の事前学習モデルからのファインチューニングでも高い性能を実現しているのは驚きである。

出典:[Zhou+, 2023]のTable 8
各アプローチの比較
最後に、前述した既存研究の分類のうち、Prompting、Quantization、Aligningの三つのアプローチの特徴を比較しながら、自分が解きたい時系列関連のタスクに対して有効なアプローチを考える。
まず、時系列データをテキストデータとして取り扱うPropmtingは、ファインチューニングを行うことなく事前学習したLLMの能力を活用できる。そのため、手元に学習データがない場合や少ない場合に有効な選択肢となるだろう。実際に、PromptCastやLLMTimeは、few-shotやzero-shotで既存の時系列モデルに匹敵する性能で、時系列予測ができることが示された。しかし、数値を文字列として表現することは、数値データに内在する意味的価値を低下させる可能性がある。また、LLMTimeでは、LLMがシンプルさや繰り返しに対するバイアスを持っていると主張されており、単純な季節的な周期やトレンドを持つような時系列データではPropmtingによるアプローチは有効であるが、より複雑な時系列性を持つデータでは十分な性能が期待できないかもしれない。
そのため、十分な学習データを用意できる場合は、QuantizationまたはAligningベースの方法がより有効になるだろう。特に個人的に興味深い研究の方向性は、個別に紹介した最後の論文である。この研究は、すでに膨大なデータで事前学習した言語モデルや画像モデルをファインチューニングにより時系列データ解析へ適用する。これにより、膨大なデータから事前学習モデルが獲得した汎用的な知識を利用しながらも、時系列タスクのための大規模データセットの構築や、それを用いた事前学習にかかるコスト・時間を大幅に削減できるため有望である。ぜひ今後の研究動向にも注目したい。
また、Aligningは、時系列データと言語空間のモダリティ間を整合させるアプローチであるので、時系列データと言語がペアとなるようなデータを使ったタスクの有力な選択肢になると思われる。例えば、心電図シグナルとテキスト形式のレポートの二つのデータから対象者の診断カテゴリを分類するタスクを解いたETPや、対話中の脳波と自然言語の二つのデータから感情予測や関係検出のタスクを解いたMTAMがその例である。
Discussion