Snowflake Cortex Search で RAG チャットアプリを試す
はじめに
2024年7月末に Snowflake Cortex Search がパブリックプレビューとなりました。Cortex Search を用いることで柔軟かつ楽に RAG を活用することができます。今回は Cortex Search を組み込んだ RAG チャットアプリを作ってみたいと思います。
(2025/5/1追記) Cortex Search の新機能 Boosts / Decays のリリースに伴い更に高度な検索機能を備えた RAG チャットボットアプリを紹介する記事を書きました。以下も合わせてご覧ください。
(2025/7/9追記) またCortex Search の管理 UI についての解説記事を作成しましたので、Cortex Search の管理については 「Snowflake Cortex Search の管理 UI が便利になった」についても是非チェックしてみてください。
RAG とは?
RAG (Retrieval Augmented Generation) とは日本語では検索拡張生成と呼ばれているもので、LLM に社内文章などの検索結果をコンテキストとして渡してあげることで、LLM の回答精度を向上させるプロンプトエンジニアリングの手法の一つです。
LLM の回答精度を上げる手法は色々ありますが、ファインチューニングなどに比べるとモデルの学習が不要であり、低めの労力で高い効果を得られる可能性があるため注目されている手法です。
しかし、いざ RAG を構成しようとするとベクトルデータベースの構築やベクトル検索の仕組みの構築など、手間も費用もかかってくるのが現状です。
Snowflake Cortexを使用した簡単かつ安全なRAGからLLMへの推論
Cortex Search とは?
Cortex Search は RAG を構成する際のベクトル化と検索の仕組みをマネージドで提供する Snowflake の機能です。ベクトルデータベースの構築や検索部分の構築を任せることができるため、自由度を残しつつも短時間で RAG を構成することが可能となります。
RAG でチャットアプリを作成する場合における Cortex Search のカバー範囲は以下の★が付いている箇所となります。
- チャンク分割 (SPLIT_TEXT_RECURSIVE_CHARACTER 関数 などで実現)
- ★ベクトル化
- ★ベクトルデータベース
- ★ハイブリッド検索
- チャットの回答生成 (Cortex LLM などで実現)
- チャット UI (Streamlit in Snowflake などで実現)

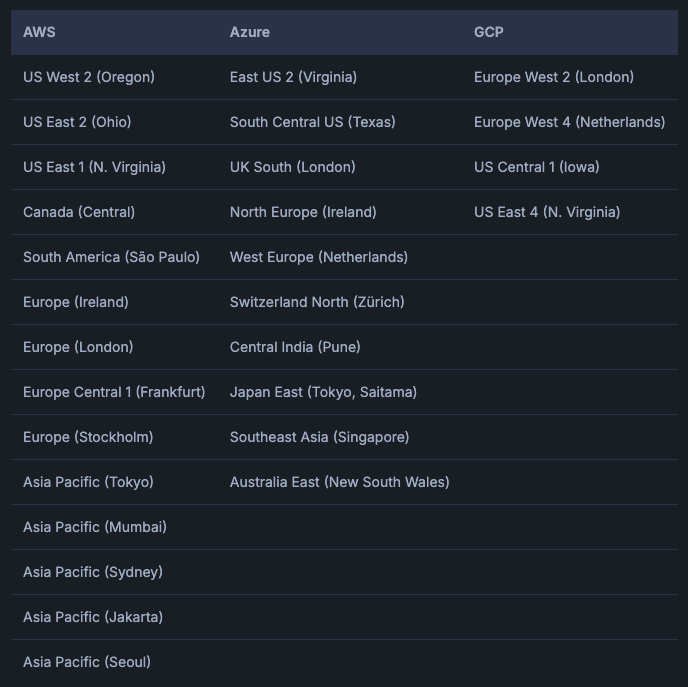
(2024/10/6 時点の対応表)
機能概要
実現したいこと
- Snowflake SQL リファレンスに基づいた RAG を構成する
- Cortex Search を使って RAG におけるベクトル化とハイブリッド検索を実装する
- ユーザーは日本語でチャットボットに Snowflake の SQL に関することを聞ける
機能一覧
- Streamlit in Snowflake から Snowflake SQL リファレンスにアクセスしてチャンクを取得
- Streamlit in Snowflake 内で Cortex Search Service の構築
- ユーザーの入力文字列からハイブリッド検索用のキーワードを Cortex LLM で抽出
- Cortex Search を用いたハイブリッド検索の結果をコンテキストにして Cortex LLM によるチャットの回答を生成
- 参考ドキュメントのリンクを表示
- ベクトル検索結果の表示
完成イメージ

このような感じで Snowflake SQL リファレンスの情報に基づいた回答を返してくれます。
前提条件
- Snowflake アカウント
- Cortex LLM と Cortex Search が利用できる Snowflake アカウント (クロスリージョン推論のリリースによりクラウドやリージョンの制約がほぼ無くなりました)
- Streamlit in Snowflake のインストールパッケージ
- python 3.8 以降
- snowflake-ml-python 1.6.0
- snowflake.core 0.10.1
- langchain 0.0.298
- bs4 4.12.3
注意事項
手順
(省略) 外部アクセス統合と Streamlit in Snowflake の作成
以下の記事を参考にして、
docs.snowflake.com
に対する外部アクセス統合を Streamlit in Snowflake のアプリケーションに設定してください。
※上記記事の 『Snowflake でネットワークルールを作成する』 から 『Streamlit オブジェクトに外部アクセス統合を紐付ける』 までを実行してください。
※『Snowflake でネットワークルールを作成する』 の value_list の値を上述したドメインに書き換えてください。
Streamlit in Snowflake のアプリを実行
作成した Streamlit in Snowflake のアプリに以下コードをコピー&ペーストで貼り付けてください。
コード内の <データベース名> <スキーマ名> <ウェアハウス名> を皆様の環境に合わせて書き換えてください。ここで指定したデータベースとスキーマ内に Cortex Search Service や関連テーブルが作成されます。また指定したウェアハウスは Cortex Search の検索やインデックスの構築、ベクトルデータベースの更新に利用されます。
import streamlit as st
from snowflake.snowpark.context import get_active_session
from snowflake.cortex import Complete as CompleteText
import requests
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
import pandas as pd
from snowflake.core import Root
# DB名とスキーマ名を変数として定義
DB_NAME = "<データベース名>"
SCHEMA_NAME = "<スキーマ名>"
WAREHOUSE = "<ウェアハウス名>"
# Snowflakeのセッションを取得
snowflake_session = get_active_session()
root = Root(snowflake_session)
# 必要なテーブルの作成
snowflake_session.sql(f"""
CREATE TABLE IF NOT EXISTS {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_chunks (
chunk STRING,
url STRING
)
""").collect()
snowflake_session.sql(f"""
CREATE TABLE IF NOT EXISTS {DB_NAME}.{SCHEMA_NAME}.cortex_search_processed_urls (
url STRING
)
""").collect()
# Cortex Search Serviceの存在確認を行う関数
def check_cortex_search_service_exists():
result = snowflake_session.sql(f"""
SHOW CORTEX SEARCH SERVICES LIKE 'cortex_search_sql_reference_service' IN {DB_NAME}.{SCHEMA_NAME}
""").collect()
return len(result) > 0
# Cortex Search Serviceの作成を行う関数
def create_cortex_search_service_if_not_exists():
if not check_cortex_search_service_exists():
snowflake_session.sql(f"""
CREATE CORTEX SEARCH SERVICE {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_service
ON chunk
ATTRIBUTES url
WAREHOUSE = {WAREHOUSE}
TARGET_LAG = '1 day'
AS (
SELECT
chunk,
url
FROM {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_chunks
)
""").collect()
# Cortex Search Serviceの作成または置換を行う関数 (主にURL処理後用)
def create_or_replace_cortex_search_service():
snowflake_session.sql(f"""
CREATE OR REPLACE CORTEX SEARCH SERVICE {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_service
ON chunk
ATTRIBUTES url
WAREHOUSE = {WAREHOUSE}
TARGET_LAG = '1 day'
AS (
SELECT
chunk,
url
FROM {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_chunks
)
""").collect()
# URLからリンクを再帰的に取得する関数
def get_links(url, base_url="https://docs.snowflake.com", visited=None, max_depth=3, current_depth=0):
if visited is None:
visited = set()
if url in visited or current_depth > max_depth:
return []
visited.add(url)
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
except requests.RequestException:
st.warning(f"Failed to fetch {url}")
return []
soup = BeautifulSoup(response.content, 'html.parser')
links = []
for a in soup.find_all('a', href=True):
href = a['href']
if href.startswith('/en/sql-reference'):
full_url = base_url + href
links.append(full_url)
if current_depth < max_depth:
links.extend(get_links(full_url, base_url, visited, max_depth, current_depth + 1))
# 重複を除去してURLを返却
return list(set(links))
# HTMLを抽出してチャンク化する関数
def html_extract_and_chunk(file_url, chunk_size, overlap):
response = requests.get(file_url)
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
for script in soup(["script", "style"]):
script.decompose()
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
# 処理済みURLを取得する関数
def get_processed_urls():
result = snowflake_session.sql(f"SELECT url FROM {DB_NAME}.{SCHEMA_NAME}.cortex_search_processed_urls").collect()
return set(row['URL'] for row in result)
# URLを処理済みとしてマークする関数
def mark_url_as_processed(url):
snowflake_session.sql(f"INSERT INTO {DB_NAME}.{SCHEMA_NAME}.cortex_search_processed_urls (url) VALUES ('{url}')").collect()
# URLを処理する関数
def process_url(url):
# HTMLをチャンク化してテーブルに保存
chunks = html_extract_and_chunk(url, 500, 100)
for chunk in chunks:
# 文字列をエスケープ
escaped_chunk = chunk.replace("'", "''").replace("\\", "\\\\")
snowflake_session.sql(f"""
INSERT INTO {DB_NAME}.{SCHEMA_NAME}.cortex_search_sql_reference_chunks (chunk, url)
VALUES ('{escaped_chunk}', '{url}')
""").collect()
# URLを処理済みとしてマーク
mark_url_as_processed(url)
# Cortex Search Serviceを作成または置換
create_or_replace_cortex_search_service()
# Cortex AIモデルを呼び出す関数
def call_cortex_ai_model(model_name, prompt, context):
prompt_text = f"""
あなたは、Snowflakeのエキスパートです。
提供されたコンテキストを参考にしながらユーザーからの質問に対して日本語で丁寧に回答してください。
情報がない場合は、その旨を伝えつつ可能な限り適切な回答をしてください。
Context: {context}
Question: {prompt}
Answer:
"""
response = CompleteText(model_name, prompt_text)
return response
# 日本語の検索クエリを英語のキーワードに変換する関数
def translate_query_to_english(prompt, model):
prompt_text = f"""
次のユーザーからの質問をRAGの検索用に数個の英語のキーワードに変換してください。
Question: {prompt}
変換した英語のキーワードをカンマ区切りのリストとして出力してください。
"""
response = CompleteText(model, prompt_text)
keywords = response.strip().split(',')
return [keyword.strip() for keyword in keywords]
# Cortex Search Serviceの作成 (存在しない場合のみ)
create_cortex_search_service_if_not_exists()
# アプリケーションのタイトル
st.title("Snowflake SQL Reference RAG")
# サイドバーの設定
st.sidebar.title("設定")
# SQLリファレンスの更新処理
if st.sidebar.button("SQLリファレンスの更新"):
base_url = "https://docs.snowflake.com/en/sql-reference"
progress_bar = st.progress(0)
status_text = st.empty()
link_text = st.empty()
processed_urls = get_processed_urls()
status_text.text("リンクを取得中...")
all_links = get_links(base_url)
new_links = [link for link in all_links if link not in processed_urls]
status_text.text(f"{len(new_links)}個の新しいリンクを取得しました。処理を開始します。")
total_links = len(new_links)
processed_count = 0
# 新しいリンクの処理
for link in new_links:
status_text.text(f"新しいURLを処理中: {link}")
try:
process_url(link)
except Exception as e:
st.error(f"Error processing URL {link}: {str(e)}")
processed_count += 1
progress_bar.progress(processed_count / total_links)
status_text.text("更新が完了しました。")
link_text.empty()
st.experimental_rerun()
# RAGチャット機能
st.header("Snowflake SQL チャットボット")
# モデル選択
model = st.sidebar.selectbox("Cortex AIのモデルを選択してください",
("deepseek-r1",
"claude-4-sonnet", "claude-3-7-sonnet", "claude-3-5-sonnet",
"mistral-large2", "mixtral-8x7b", "mistral-7b",
"llama4-maverick",
"llama3.3-70b",
"llama3.2-1b", "llama3.2-3b",
"llama3.1-8b", "llama3.1-70b", "llama3.1-405b",
"snowflake-llama-3.1-405b", "snowflake-llama-3.3-70b",
"snowflake-arctic",
"reka-flash", "reka-core",
"jamba-instruct", "jamba-1.5-mini", "jamba-1.5-large",
"gemma-7b",
"mistral-large", "llama3-8b", "llama3-70b", "llama2-70b-chat"
)
)
# チャット履歴の初期化
if 'messages' not in st.session_state:
st.session_state.messages = []
st.session_state.chat_history = ""
# チャット履歴の表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if "relevant_chunks" in message:
with st.expander("参考ドキュメント"):
seen_urls = set()
for chunk in message["relevant_chunks"]:
if chunk['url'] not in seen_urls:
st.markdown(f"- [{chunk['url']}]({chunk['url']})")
seen_urls.add(chunk['url'])
with st.expander("ベクトル検索結果"):
st.dataframe(
pd.DataFrame(message["relevant_chunks"]).rename(columns={"chunk": "チャンク", "url": "URL"})
)
# ユーザー入力とAI応答の生成
if prompt := st.chat_input("質問を入力してください"):
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.chat_history += f"User: {prompt}\n"
with st.chat_message("user"):
st.markdown(prompt)
# 日本語のクエリを英語のキーワードに変換
english_keywords = translate_query_to_english(prompt, model)
english_query = " ".join(english_keywords)
# Cortex Search サービスの指定
search_service = (
root.databases[DB_NAME]
.schemas[SCHEMA_NAME]
.cortex_search_services["cortex_search_sql_reference_service"]
)
# Cortex Searchを使用して関連するチャンクを検索
search_results = search_service.search(
query=english_query,
columns=["chunk", "url"],
limit=5
)
relevant_chunks = [{"chunk": result["chunk"], "url": result["url"]} for result in search_results.results]
# コンテキストを作成
context = "\n".join([f"{chunk['chunk']} (Source: {chunk['url']})" for chunk in relevant_chunks])
# AIモデルで応答を生成
full_prompt = st.session_state.chat_history + f"Context: {context}\nQuestion: {prompt}\nAnswer: "
response = call_cortex_ai_model(model, full_prompt, context)
# 応答を表示
with st.chat_message("assistant"):
st.markdown(response)
with st.expander("参考ドキュメント"):
seen_urls = set()
for chunk in relevant_chunks:
if chunk['url'] not in seen_urls:
st.markdown(f"- [{chunk['url']}]({chunk['url']})")
seen_urls.add(chunk['url'])
with st.expander("ベクトル検索結果"):
st.dataframe(
pd.DataFrame(relevant_chunks).rename(columns={"chunk": "チャンク", "url": "URL"})
)
# チャット履歴に追加
st.session_state.messages.append({
"role": "assistant",
"content": response,
"relevant_chunks": relevant_chunks
})
st.session_state.chat_history += f"AI: {response}\n"
# チャット履歴のクリアボタン
if st.sidebar.button("チャット履歴をクリア"):
st.session_state.messages = []
st.session_state.chat_history = ""
st.rerun()
最後に
いかがだったでしょうか?今回は敢えて Streamlit in Snowflake 内で RAG を構成する全てのコンポーネントを揃えてみましたが、想定よりもかなり短い時間で精度の高い RAG チャットアプリを作成することができました。
今回はチャットアプリのみの実装となりましたが、例えば Snowflake 内のデータ分析やデータエンジニアリング、BI など様々なシーンに Cortex Search を組み合わせることで自社のコンテキストに合わせた高度な AI の活用ができると考えられます。
また Cortex LLM のモデルの中では claude-4-sonnet mistral-large2 llama4-maverick snowflake-arctic reka-flash あたりが特に日本語性能が高いため、是非皆様の環境にあったモデルを選択していただければと思います。(個人的には総合的な性能では claude-4-sonnet が、 コスパでは llama4-maverick が一押しです)
宣伝
SNOWFLAKE DISCOVER でバーチャルハンズオンをデリバリしました!
2025/7/8-9に開催されました Snowflake のエンジニア向け大規模ウェビナー『SNOWFLAKE DISCOVER 第2弾』において『Snowflake Cortex AI で実現する次世代の VoC (顧客の声) 分析』という実践的なバーチャルハンズオンをデリバリさせていただきました。多くの業種で関連する顧客の声を Snowflake の最新機能を用いて分析する方法を体感いただけますので、是非非構造化データの分析のヒントを得たい方はご視聴いただければ幸いです!
以下リンクでご登録いただけるとオンデマンドですぐにご視聴いただくことが可能です。

SNOWFLAKE DISCOVER で登壇しました!
2025/4/24-25に開催されました Snowflake のエンジニア向け大規模ウェビナー『SNOWFLAKE DISCOVER』において『ゼロから始めるSnowflake:モダンなデータ&AIプラットフォームの構築』という一番最初のセッションで登壇しました。Snowflake の概要から最新状況まで可能な限り分かりやすく説明しておりますので是非キャッチアップにご活用いただければ嬉しいです!
以下リンクでご登録いただけるとオンデマンドですぐにご視聴いただくことが可能です。

生成AI Conf 様の Webinar で登壇しました!
『生成AI時代を支えるプラットフォーム』というテーマの Webinar で NVIDIA 様、古巣の AWS 様と共に Snowflake 社員としてデータ*AI をテーマに LTをしました!以下が動画アーカイブとなりますので是非ご視聴いただければ幸いです!
X で Snowflake の What's new の配信してます
X で Snowflake の What's new の更新情報を配信しておりますので、是非お気軽にフォローしていただければ嬉しいです。
日本語版
Snowflake の What's New Bot (日本語版)
English Version
Snowflake What's New Bot (English Version)
変更履歴
(20240822) 新規投稿
(20240823) 一部補足を追記
(20240901) ソースコードに mistral-large2 を追加
(20240926) 宣伝欄の修正、Cortex LLM のモデル llama3.2-3b llama3.2-1b jamba-1.5-large jamba-1.5-mini を追加
(20241006) Cortex Search の GA に伴い追記
(20250111) 宣伝欄の修正、Cortex LLM のモデル claude-3-5-sonnet を追加、python ライブラリの依存関係に関する注意事項を追記、ソースコードをコンテキストを引き継ぐように修正
(20250119) Cortex LLM のモデル snowflake-llama-3.3-70b snowflake-llama-3.1-405b を追加
(20250228) Cortex LLM のモデル llama3.3-70b deepseek-r1 を追加、LLM のモデルを全体的に並べ替え
(20250318) チャンク分割の選択肢について、SPLIT_TEXT_RECURSIVE_CHARACTER 関数 を追記
(20250501) Cortex Search Boosts / Decays 機能の GA に伴い新しい記事を書いたためリンクを追加しました
(20250508) 宣伝欄の修正
(20250510) Cortex LLM のモデル claude-3-7-sonnet を追加、オススメモデルの記述を修正
(20250524) Cortex LLM のモデル claude-4-sonnet llama4-maverick を追加、オススメモデルの記述を修正
(20250629) 宣伝欄の修正
(20250709) 「Snowflake Cortex Search の管理 UI が便利になった」へのリンクを追記
(20250927) 宣伝欄の修正
Discussion