MIXIのインターンに参加してきました
はじめに
2024年9月~10月中旬までの1ヶ月半の期間で、株式会社MIXIさんの「家族アルバム みてね」にてSREとして就業型インターンに参加させていただきました。技術的な学びが多くあったのはもちろんのこと、素敵なサービス・チームの中で充実した時間を過ごすことができました。せっかくなので、今回はその体験記を記していこうと思います。
インターン参加の経緯
自分は普段大学での研究以外では都内のベンチャー系企業で受託開発を行っており、そこでフロントからバックエンド、インフラまで幅広く開発を行っていました。その中でも、SREの領域に対し個人的に興味があり、より大きな組織の中で業務を経験してみたいという思いでMIXIのインターンに応募しました。
取り組んだタスクについて
MIXIでは、インターンと言っても実際のSREチームのメンバーの一員として、他の社員の方と同じようなタスクに取り組みます。主に2つのタスクに取り組んだので簡単に紹介します。
EC2インスタンスをARMベースのGravitonへと移行
みてねでは、インフラにEKSを利用しており、データプレーンはEC2で動いています。詳細な技術スタックについては以下のサイトで公開されています。
当時、コスト削減のためx86搭載のインスタンスからARMベースのGravitonインスタンスに移行する作業を行っていました。具体的には、taint/tolerationを用いてPod数の多い処理からArmノードに乗せるような形の処理を行っていました。
その際、一部の画像補正ライブラリにARM版のバイナリが提供されないことから移行作業のブロッカーになっていたという問題がありました。画像補正ライブラリは写真のプリント時に適用される場合があるもので、適用すると画像が綺麗になるというものです。そこで、画像補正ライブラリを呼び出す部分をマイクロサービスのような形で切り出して呼び出せるように修正する必要があり、その部分の実装を行いました。
流れとしてはメインサーバ内で行っていた画像補正処理を、S3を介して外部のAPIサーバで処理するよう変更する内容でした。APIサーバのKubernetesマニフェストファイルを編集して外部アクセスを可能にし、メインのシステムからはAPIリクエストを通じて画像補正処理を行えるようにしました。

このタスクは取り掛かってから本番リリースまで1ヶ月ほど時間を要し、今は実際のサービス内で稼働しています🎉
2024年10月現在、該当のS3バケットには日々かなりの数の画像がアップロードされており、規模感の大きさを実感しました。
大変だった点
個人的に大変だった点は実装したコードに対するテストコードの記述でした。普段あまりテストを書いてこなかったこともあり、テストを書く際に苦労する部分がありました。自身が追加した処理に対するテストだけではなく、他のクラスから新たに追加したメソッドを呼び出している部分が複数あり、それらの修正も必要であったため広範囲のコードを追いかける必要がありました。
また、「テストの責任範囲」 についてよく考えるようになりました。テストを書くにあたって外部へのAPI呼び出しについてはスタブやモックを使って記述することになるのですが、その際に例えば、「処理Aに関するテストは別のテストでカバーされているので書かなくても良い」といったことや、逆に「処理Bの関するテストは必ずカバーされている必要がある」といったことです。各テストにおいて適切な責務を意識しながら書くことの重要性を学びました。
さらに、みてねは画像を取り扱うサービスであるため画像に関連するテストも自ずと多くなりますが、その際見た目はほぼ同じだが僅かなカラー差で落ちるテストも存在したりと、みてねならではのテストの難しさも実感しました。
CircleCIからKubernetes Jobへの移行
残りの2週間はみてねのSREチームがCIにかかるコストを削減するために、CIをCircleCIからKubernetes Jobへの移行を行っていたため、その際に生じたタスクをこなしました。こちらは一つ目のタスクとは異なり移行時のバグ修正や実行時間を抑えるための施策を検証したりと、比較的小さな成果を積み上げる形になりました。
具体的なタスクは以下の通りです。
落ちるようになったテストの修正
Kubernetes Jobに移行した際にCircleCIでは成功していたテストで失敗してしまうものがあったため、その修正をしました。原因は、Kubernetes JobがAPIエンドポイントとしてクラスタ内DNSを叩く際にKubernetes Jobが動作するクラスタと APIサーバが動作していたクラスタが違っていたので、(当然ですが)エラーが出ていたというものでした。シンプルにKubernetes Jobの中でローカルにコンテナを用意しそのコンテナを叩くようにすることで修正できましたが、原因を見つける際にKubernetesの知識を実際の業務で活用できた点は良かったと思いました。
Jobの失敗とテストの失敗を区別して表示
テストの失敗ではなくKubernetesのJobがなんらかの理由で失敗した際の表示がうまくいっていなかった問題があったため、Kubernetes Jobの失敗を検知しその内容をマークダウンに表示するようにしました。その際、$GITHUB_ENVという環境ファイルに環境変数を定義することでワークフロージョブで取得したKubernetes Jobの状態をマークダウンファイルに渡すといった処理を行いました。
Github ActionsのジョブキャンセルをKubernetes Jobに通知
Github Actionsのワークフローをキャンセルした場合や新しいコミットが積まれた場合に古いコミットに対するテストのJobが止まらないという問題があったので、Jobを止めるように修正しました。
Github Actionsのワークフローがキャンセルされたことを検知する仕組みや、concurrencyを利用することでワークフローを一度に1つだけ実行するような制御を行うことができました。
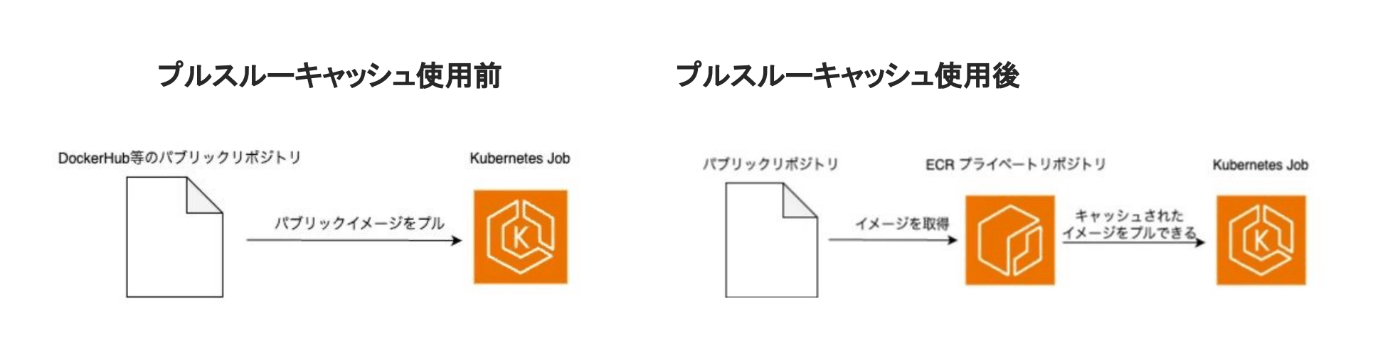
ECR Pull Through Cacheを用いたコンテナ起動の高速化施策検証
CircleCIと比較してKubernetes Jobの実行時間が安定しておらず、かつより多くの実行時間を要していたため複数の高速化施策の検証を行っていました。そのうちの一つとして、テスト時にローカルで使用するmysqlやredisといったDockerコンテナの起動をプルスルーキャッシュを用いて高速化できるかどうかを検証しました。プルスルーキャッシュは以下のように、キャッシュされたイメージをECRのプライベートリポジトリからプルできるという機能で、コンテナ起動の高速化が期待できます。
クロスアカウントで「自動作成される」リポジトリを利用する関係でルールの作成とIAMポリシーの付与だけではなく、独自のリポジトリ作成テンプレートを作り適用する必要があったことがハマりポイントでした。
なお、リポジトリ作成テンプレートは以下のような流れで適用されます。(前述のAWSドキュメントより)
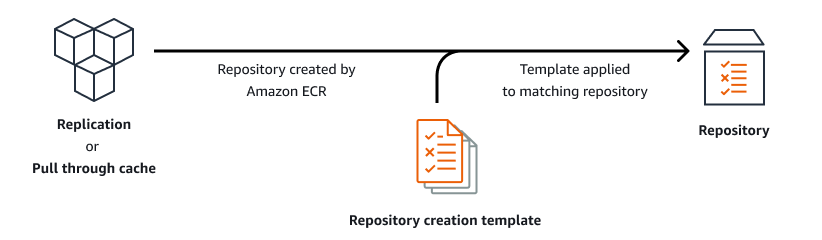
通常はデフォルトのテンプレートが適用されますが、Kubernetes Jobを作成していたAWSアカウントとプルスルーキャッシュを作成していたAWSアカウントが異なっていたため、独自のリポジトリポリシーを含んだテンプレートを作成し適用する必要がありました。ドキュメントには以下の記載があり、デフォルトのテンプレートでは何もリポジトリポリシー(IAMポリシーとはまた別)を反映しないと書かれていました。
These default settings include turning off tag immutability, using AES-256 encryption, and not applying any repository or lifecycle policies
プルスルーキャッシュを使用する準備ができたので、(キャッシュされたイメージを使うこ
とでコンテナ起動が高速化することを期待して)実際に使用してみたところ、結果は残念ながら「速くもならず遅くもならない」というものでした。(残念..)
仮説としてはDocker HubのイメージもどこかのCDNにキャッシュされているため速度的な優位性が生まれなかったのではないかというものがありました。
このことを検証するため、インターン終了後に「Docker Hubのイメージはどこにキャッシュされているのか」について簡単な調査を行いました。
検証方法はシンプルで、wiresharkを起動しながら適当なDockerイメージをpullするというものです。その結果、cloudflareからリスポンスが提供されていることが確認でき、Docker Hubのイメージはそもそもcloudflareにキャッシュされているため、プルスルーキャッシュを用いることでイメージのpullが高速化されるわけではなさそうという検証結果が納得できるものになりました。
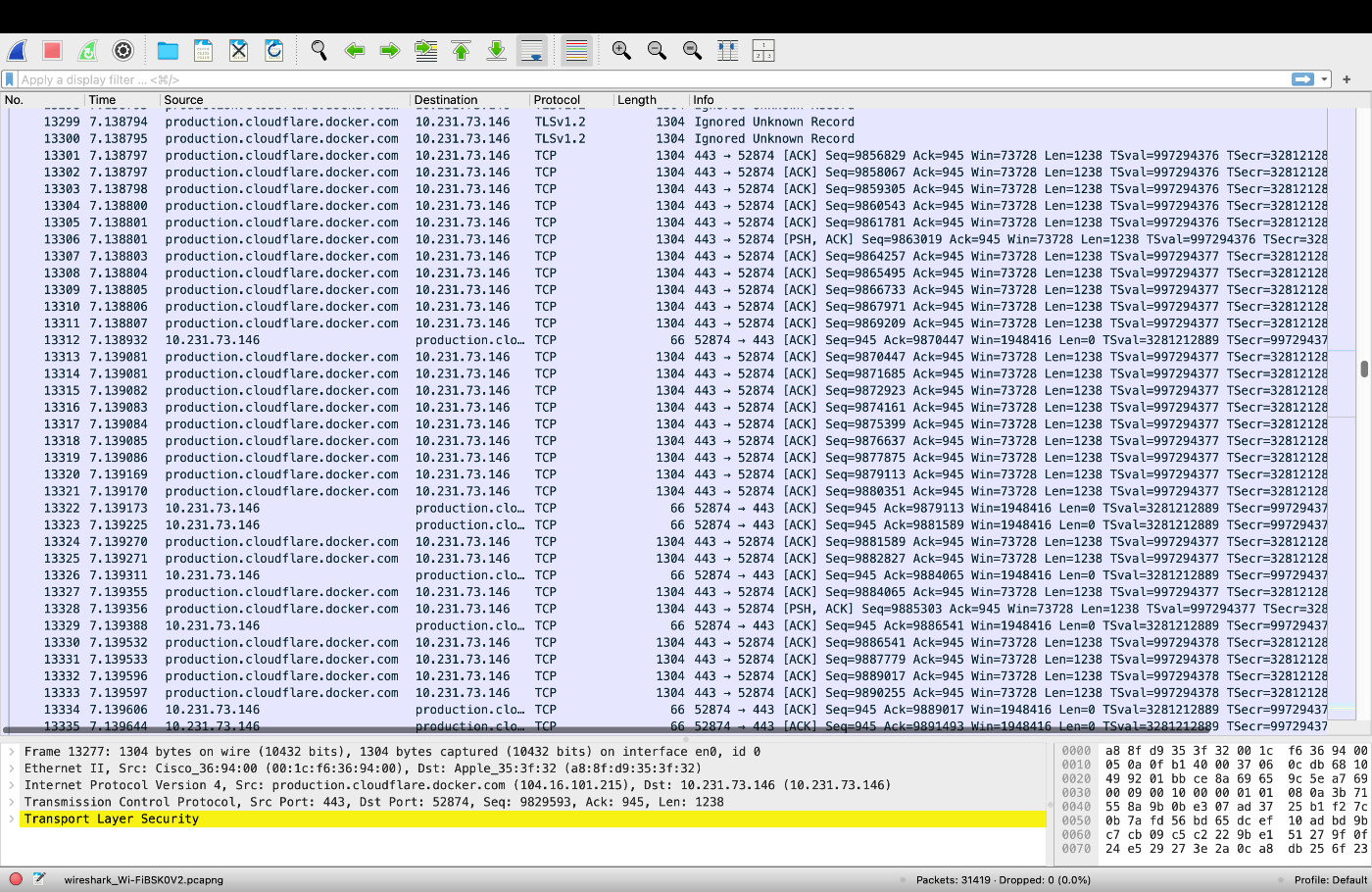
そのため、プルスルーキャッシュはパブリックなリポジトリではなくプライベートなリポジトリからイメージをpullできるというセキュリティ的な観点の方が大きそうです。
その他業務について
stg環境でのインシデント対応
他のチームからの問い合わせから、stg環境でサーバーエラーが起きていたとの報告があり、その問題の調査と対応も行いました。
Grafanaを確認した結果、サーバーが落ちてるとの問い合わせが来た時間帯とPodの数が一時的に0となってしまっていた時間帯が一致していました。また、PodがスケジューリングされていたNodeも落ちていたことがわかっていたので、スポット中断によりNodeが落ち、そのNodeにたまたま全てのPodが乗っておりPodも落ちてしまったと判断しました。stg環境では元々Podの数が少ないのでスポット中断によりPodが全て落ちてしまうことは考えられる事象でした。
そこで、Kubernetesの機能であるPod Topology Spread Constraintsを用いて各NodeごとにPodがほぼ均等に分散するよう設定を行ったことで上記事象の発生確率を下げるような処理を追加しました。この処理の追加後実際にPodが各Nodeに分散されていることを確認し、現在も使われています。
このようなKubernetesのスケジューリングは個人ではなかなか経験できないことでもあるので、取り扱うことができてよかったです。
OOM Killedの調査
webサーバのKubernetes Podにおいてメモリ不足によりOOM Killedが発生していたため、調査を行いました。基本的にはPromQLを叩いてOOM Killedにより終了したPodのログやメトリクスおよび、PodがスケジューリングされていたNodeのメトリクスを調査しました。その結果、USリージョンのNodeで動作していたPodがメモリ不足によりOOM Killedとなったことがわかりました。また、メモリのメトリクスを確認したところ、スパイクが起きた時間帯とDB再起動の時間帯が同じであったことがわかりました。過去にも同様の挙動を観測したこともありDB再起動によりコネクションプールを再構築しコネクションを再接続しようとした際にPodに割り当てられたメモリの上限に達してしまったという結論になりました。Railsアプリケーションの特性としてメモリ使用量が減少しにくいということもありPodのメモリ上限に張り付いたままの状態がしばらく続いてしまいOOM Killedとなってしまったということです。ただ、ユーザ影響はなく原因も特定できていたため特別な対応は行わず終了となりました。
これらのケースおよび他の調査を通じて、SREとして重要な考え方として以下の2点を学ことができました。
- 客観的なデータに基づいて意思決定を⾏うこと
- 1つのグラフが⽰すのは単なる事実に過ぎず、複数のグラフを組み合わせることで初めて因果関係と解決策を提⽰することができるということ
SREとして重要な考え方は他にもたくさんありますが、上記の考え方をみなさんが当たり前に実践しており、とても参考になりました。
番外編
インターンの序盤にアジャイル研修を社内のスクラムマスターの方と1対1で行っていただき、アジャイルの基礎知識をつけた上で実際にスクラムを導入しているみてねの中に入ることができたので、とても良かったです。
業務外には様々なイベントを通じて他の社員の方と交流できる機会が多くありました。フットサル大会やタコスの腕を競うタコスバトルというイベントがあったり、業務後に何度もご飯に連れて行っていただきました。また、栄養バランスの整った社食はとても美味しかったです。社食を含め、MIXIは働く環境が本当に良かった印象でした!
インターンを通じた感想
自分の所属していたみてねの社員さんの方々は、プロダクト志向の強い方が多く、皆さんが「みてね」というプロダクトをより良いものにしたいという思いを持っている印象を受けました。また、MIXIは企業理念にもあるように、コミュニケーションを非常に重要にしており、実際に働いている際もコミュニケーションを重視していることがよくわかりました。
また、個人的な課題としては、タスクを「こなす」ことに注⼒し過ぎてしまい広い視野が持てなかった印象がありました。現在のみてねのインフラの課題を発⾒し、修正案を提示する=タスクを「作る」ことができればより良かったと思っています。ただ、そのためにはより広い知識や技術⼒が必要となるのは当然なので今後もレベルアップのために頑張ろうと思いました。
最後になりますが、みてねのSREチームの方々はじめインターン期間中に関わってくださったMIXIの皆さん、本当にありがとうございました!
Discussion