弊社(トラストハブ)では、バックエンドのクラウド環境に Google Cloud を使用しています。
本記事では、Google Cloud のみを使用して柔軟な障害通知を設定する方法を紹介します。
柔軟な障害通知とは
本記事における障害通知とは、障害の可能性を示すログがバックエンドのアプリケーションから出力されたとき、Slack などのツールにその旨を通知することを指します。それによって開発者が障害に対して即座に気づくことができます。
また、本記事における「柔軟な」障害通知とは以下のことを指します。
- 特定のログの数が閾値を超えたときに障害として通知できること。
- 障害とは関係ないログが障害通知に含まれてしまった場合、そのログを通知対象からすぐに外せること。
- 通知のメッセージの内容やフォーマットを自由にカスタマイズできること。
Google Cloud のみで実現したい
世の中には Datadog や Sentry など数多くのモニタリングツールがあります。しかし、弊社ではこれらのツールを、バックエンドのアプリケーションログに応じた障害通知には使用していません。
その理由として、モニタリングを含めたバックエンドのクラウド環境を Google Cloud で統一したいためです。
クラウド環境 や SaaS が分散してしまうと、管理コストが上がります。また、それらのダッシュボードへ都度アクセスするのも手間です。
弊社では、バックエンドのアプリケーションのビルド、デプロイ、実行、ロギングなど全てを Google Cloud 上で行っています。そのため、Google Cloud のダッシュボードには頻繁にアクセスします。よって、障害通知の管理も Google Cloud 上でできたほうが都合がよいという事情があります。
弊社における柔軟な障害通知の例
弊社ではアプリケーションログのうち WARNING レベルのログが3分間に10件以上発生したときにSlackに通知が流れるようにしています。

WARNINGログに応じた障害通知の例
WARNING ログというのは、Google Cloud で定義されているログレベルのひとつです。弊社では WARNING ログを以下の状況で出力するようにしています。
「すぐに対応するレベルの不具合ではないが、何かしらの理由で処理が完了しなかったとき。例えば、フロントから送られてきたリクエストの引数が間違っている場合など」
弊社におけるログレベルの使い分けにおいては以下の補足も参照くださいませ。
ログレベルについて補足
これまで述べたように弊社では Google Cloud を使っており、ログの管理も Google Cloud の Logging (Cloud Logging)を使っています。Cloud Logging のダッシュボード画面では、ログの重要度ごとにログが色分けされます[1]。

弊社においても、ログを見やすくするためにログを「構造化ログ」として出力し、ログが色分けされるようにしています。構造化ログについては以下を参照ください。
構造化ロギング | Cloud Logging | Google Cloud
Cloud Logging では9段階のログレベルが使用できます。
LogEntry | Cloud Logging | Google Cloud
弊社ではそのうち DEBUG 、INFO、WARNING、ERROR の4種類のみを使っています。9種類使っていない理由は、9種類すべてを明確に使い分けるのが難しいと感じたためです。例えば、アプリケーションの実行中に処理が継続困難な状況に陥ったとき、それに関するログをERROR として出力するか CRITICAL として出力するか迷う場面が出てくると思いました。そのため、4種類のみを使っています。

また、WARNING ログに不要なログが混じってしまった場合、それを WARNING ログから除外できるようにしています。
さらに、Slack に通知されるメッセージの内容やフォーマットを自由にカスタマイズできます。
これらを実現するための具体的な方法を次の章で説明します。
実現方法
柔軟な障害通知を実現する方法について具体的に説明します。
処理の流れは以下のようになります。最後の「Slack通知」以外は Google Cloud のサービスを示します。
Cloud Logging → Cloud Scheduler → Pub/Sub → Cloud Functions → Slack通知
少し説明を加えると以下の流れになります。
- Cloud Logging にログが流れる。
- Cloud Scheduler によって Pub/Sub が定期実行される。
- Pub/Sub 経由で Cloud Functions が実行される。
- Cloud Functions で Logging からログを取得し設定した条件を満たしていれば、任意のメッセージを持たせた障害通知をSlackに送る。また、不要なログの除外も Cloud Functions 上で行う。
以下、詳細な手順です。
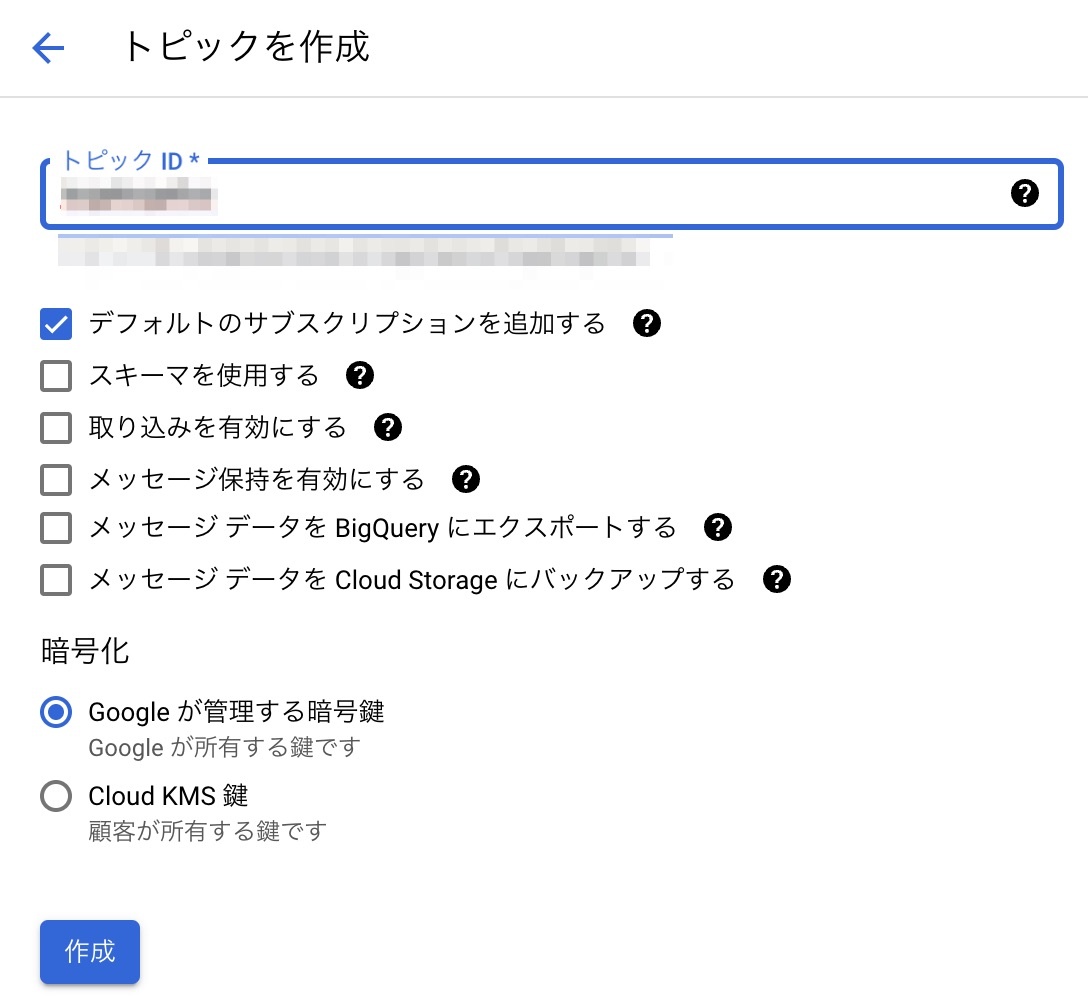
1. Pub/Sub トピックを作成する
最初に Pub/Sub トピックを作成します。
Cloud Scheduler から Cloud Functions を直接呼び出すことができないため、間に Pub/Sub を挟む必要があります。詳細は公式ドキュメントに記載されています。
Pub/Sub を使用して Cloud Functions をスケジュールする | Cloud Scheduler Documentation | Google Cloud
Google Cloud のダッシュボードから Pub/Sub ページへ移動し、新規のトピックを作成します。トピックIDには任意の文字列を入れます。それ以外はデフォルトを選択します。
2. Cloud Scheduler を作成する
Cloud Scheduler を新規に作成します。
障害通知の頻度に合わせて実行頻度を設定します。ここでは実行頻度を10分間にしているため、障害が継続して発生した場合、10分ごとに通知が送られます。

次に、実行内容を設定します。
- ターゲットタイプには Pub/Sub を選びます。
- Cloud Pub/Sub トピックのところで先ほど作ったトピックを選んでください。
- メッセージ本文は必須項目なのですが、今回は使わないので任意の値をとりあえず入れておきます。

3. Cloud Functions を作成する
Cloud Functions では以下の内容を実行します。
- Cloud Logging から任意のログを取得する。
- 閾値を超えていたら、メッセージを組み立て Slack に通知する。
- 特定のログを通知対象から除外する。
Cloud Functions を作成します。トリガーのタイプでは Cloud Pub/Sub を選択します。トピックには先ほど作ったものを選択します。

具体的な処理の内容はソースコードを見てもらったほうが早いと思います。以下、ソースコードです。ランタイムには Node.js を使用しています。
const { Logging } = require('@google-cloud/logging');
const axios = require('axios');
const SLACK_WEBHOOK_URL = process.env.SLACK_WEBHOOK_URL;
const SLACK_WEBHOOK_KEY = process.env.SLACK_WEBHOOK_API_KEY;
const PROJECT_ID = process.env.PROJECT_ID; // Google Cloud のプロジェクトID
const SERVICE_NAME = process.env.SERVICE_NAME; // ログの監視対象となるアプリケーションのサービス名。例えば Cloud Run でアプリケーションを実行している場合、その Cloud Run のインスタンス名が入る。
const logging = new Logging({ projectId: PROJECT_ID });
// 通知対象から除外する文字列のリスト
// ここにセットした文字列を含むログは通知対象から除外される
const shouldSkipLog = (message) => {
const skipPatterns = [
"unknown status",
];
return skipPatterns.some(pattern => message.includes(pattern));
};
exports.checkWarningsAndNotifySlack = async (event, context) => {
const endTime = new Date();
const startTime = new Date(endTime.getTime() - 60000 * 10); // 6,000 ms * 10 = 10分間
const filter = `resource.type="cloud_run_revision" ` +
`resource.labels.service_name="${SERVICE_NAME}" ` +
`severity="WARNING" ` +
`timestamp >= "${startTime.toISOString()}"`;
const options = {
filter: filter,
orderBy: 'timestamp desc',
pageSize: 1000,
resourceNames: [`projects/${PROJECT_ID}`]
};
const [entries] = await logging.getEntries(options);
// Warning ログの集計
const warningCounts = {};
entries.forEach(entry => {
if (!entry.metadata || !entry.metadata.textPayload) {
return;
}
const message = entry.metadata.textPayload;
if (shouldSkipLog(message)) {
console.log('Skipped log due to filter criteria');
return;
}
warningCounts[message] = (warningCounts[message] || 0) + 1;
});
// 同じ Warning ログが10回以上の場合、Slackに通知
// Slack へのメッセージ内容を自由に組み立てることができる
Object.keys(warningCounts).forEach(async (message) => {
if (warningCounts[message] >= 10) {
const logUrl = generateLogUrl(entries[0]);
const data = {
textPayload: `WARNING: 10分間に10回以上のWARNINGが発生しました。<${logUrl}|ログを見る>`,
message: message,
severity: 'WARNING',
timestamp: new Date().toISOString(),
};
await notifySlack(data);
}
});
};
// Slack への通知
async function notifySlack(data) {
const body = buildBody(data);
await axios.post(SLACK_WEBHOOK_URL, body, {
headers: {
'Authorization': `Bearer ${SLACK_WEBHOOK_KEY}`,
}
});
console.log('Message sent');
}
function generateLogUrl(entry) {
const query = encodeURIComponent(`resource.type="cloud_run_revision" resource.labels.service_name="${SERVICE_NAME}" severity="WARNING"`);
const timestamp = `timestamp=${entry.metadata.timestamp.toISOString()}`;
return `https://console.cloud.google.com/logs/query;query=${query};timestamp=${timestamp}?project=${PROJECT_ID}`;
}
const buildBody = (data) => {
return {
channel: process.env.SLACK_CHANNEL,
username: process.env.SLACK_USERNAME,
text: data.textPayload,
attachments: [
{
text: data.message,
color: "#FFA500",
},
],
};
};
これで完成です!
条件を満たしたとき、Slack に通知が来ます。

参考:Google Cloud で用意されているデフォルトの方法
Google Cloud では、ログに応じて障害通知するための仕組みが用意されています。この方法を使えば、通知の設定自体はより手軽に行えます。Cloud Functions でコードを書く必要はありません。
ログベースのアラート ポリシーの構成 | Cloud Logging | Google Cloud
しかし、この方法の場合、Slack に送られる通知メッセージの内容がわかりづらいという課題があります。
デフォルトの方法では以下のようなメッセージが Slack に送られます。

このメッセージのわかりづらい点としては、
- 書かれている文章が障害の詳細を示していない
- 例えば1文目の
Incident ~のところを読んでもどのような障害なのかわからない。
- 例えば1文目の
- エラーの詳細が載っていない
- アプリケーションから出力しているログの内容が載っていない。
- スタックトレースも載っていない。
弊社でも当初はこのデフォルトの方法を使っていたのですが、障害通知をより柔軟に設定できる方法に変更しました。
最後に
株式会社トラストハブではカード事業だけでなくtoC向けの様々なプロダクトを提供していますが、やりたいことに対してエンジニアが足りておりません。toC向けプロダクトを開発したいという方はぜひこちらからお話しさせてください!
-
なお、Google Cloud ではログの重要度のことをログレベルではなく、Log Severity と呼んでいますが、日本語で書く場合ログレベルと書いたほうが読みやすいので本記事では便宜上そう呼びます。 ↩︎

Discussion