弊社トラストハブは、トレーディングカードのオリジナルパックをウェブ上で引けるサービス「Cloveオリパ」を提供しています。
Clove オリパのような toC 向けサービスでは、ユーザーからのリクエストが急激に増える瞬間があります。そのようなリクエストのスパイクに耐えながら、リクエストを安定して捌くことがバックエンドでは重要になります。
本記事では、リクエストの急激なスパイクに耐えるバックエンドの設計のうち、Google Cloud Run の設定方法について紹介します。
toC 向けサービスにおけるリクエストのスパイクの要因
弊社サービスでは、リクエスト数が10分間で10倍に増えることがあります。
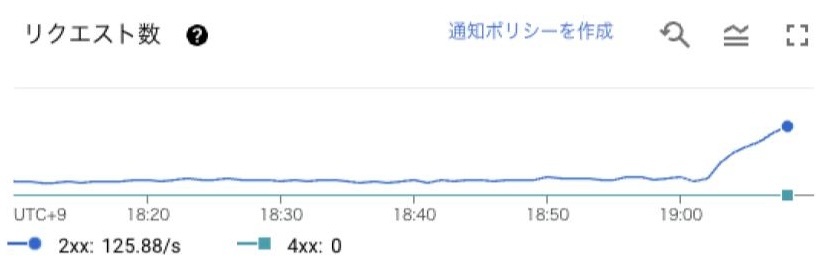
リクエスト数のグラフ。19:00以降にリクエストが急増しているのがわかる。
リクエストが急増する要因として以下のようなことが挙げられます。
- ネイティブアプリのプッシュ通知や LINE 公式アカウントでのメッセージ送信などを行ったとき
- インフルエンサーに弊社サービスを紹介してもらったとき
- クーポンの配布などのキャンペーンを行ったとき
これらの要因が発生するタイミングは自社で制御できることもありますが、偶発的なこともあります。そのため、リクエストが急増するのを事前に把握するのは困難です。
リクエストが急増するタイミングを予測するのが困難であっても、そのようなスパイクに耐えるための方法を以下で紹介します。
リクエストのスパイクに耐える方法
Google Cloud Run のオートスケールを活用する
弊社サービスのバックエンドでは、ホスティング先として、Google Cloud の Cloud Run を利用しています。
Cloud Run の特長といえば、なんといってもオートスケールです。オートスケールとは、リクエストの処理状況に応じて、Cloud Run のインスタンス数が自動的にスケールする(増える)機能です。
このオートスケールを利用すれば、リクエストが急増したときに Cloud Run のインスタンス数を自動に増やすことができ、リクエストを捌ききることができます。しかし、Cloud Run のオートスケールを十分に活用するためには次の項で述べるような課題があります。
Cloud Run のオートスケール条件が難しい
Cloud Run はリクエストの処理状況に応じて、自動的にインスタンス数を増やします。
しかし、どういった条件を満たすと自動で増えるのでしょうか?Goolge Cloud の公式ドキュメントを見ると、以下のように書かれています。
受信リクエスト、イベント、CPU 使用率のレートに加えて、スケジュールされるインスタンスの数は次の要因の影響を受けます。
- 既存インスタンスの 1 分間の平均 CPU 使用率(スケジュール設定されたインスタンスの CPU 使用率を 60% に維持するため)。
- 1 分間でのリクエストの最大同時実行数と比較した現在の同時実行数。
- インスタンスの最大数の設定
- インスタンスの最小数の設定
ref. https://cloud.google.com/run/docs/about-instance-autoscaling?hl=ja
正直、ドキュメントを読んだだけでは条件がわかりづらいです。
わかりづらい理由として、まず条件が複数あるということです。条件が複数あるため、オートスケールが発生したとき(あるいは発生しなかったとき)どの条件による影響か断定しづらいです。また、CPU 使用率は制御しづらい指標です。リクエストの内容によって、CPU を多く消費するものもあればしないものもあります。そのため、どのようなシチュエーションで60%という基準を超えるかは予測しづらいです。
また、弊社のサービスである Clove オリパの処理においては、「CPU 使用率が低く、メモリ使用率が高い」という特徴があります。Cloud Run のデフォルト設定では最大同時リクエスト数(最大同時実行数)が80になっています。しかし、Clove オリパの場合、CPU使用率が60%を超えたり同時リクエスト数が80を超えたりしてオートスケールが発生する前に、インスタンスのメモリが枯渇してしまうという課題がありました。
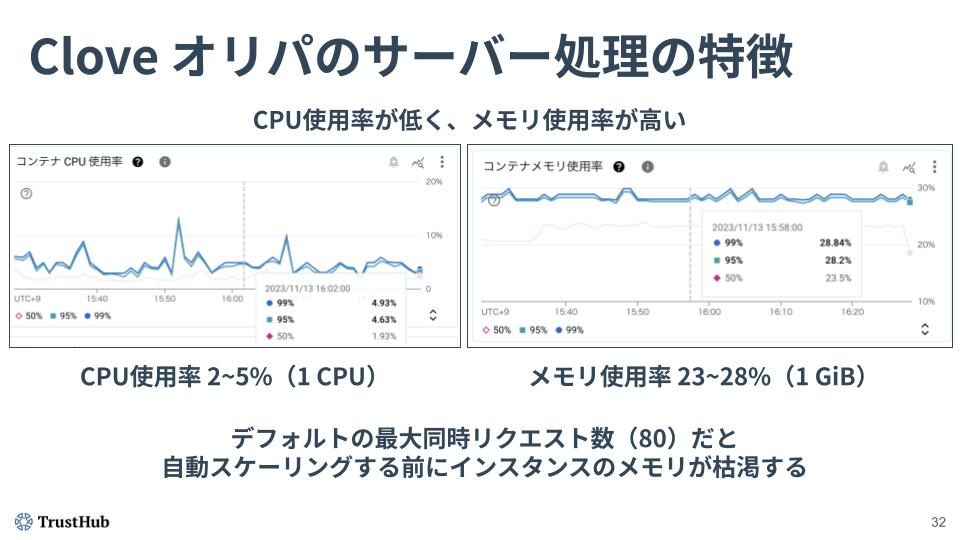
Clove オリパにおける処理の特徴とオートスケールにおける課題。
Cloud Run のオートスケールを予測可能にする
オートスケールが期待通りに発火するための Cloud Run のおすすめの設定は、「最大同時リクエスト数を1に設定する」です。
この条件にすると、オートスケールの発生を予測しやすくなります。
Cloud Run は1インスタンスにつき1リクエストしか受け付けないようになります。例えば、10台のインスタンスが稼動しているとき、10リクエストまで同時に処理でき、11リクエスト目が来たらインスタンスが新しく起動します。「現在のインスタンス数 < 同時リクエスト数」という状態になったらオートスケールするので、発火条件が非常に明確になります。
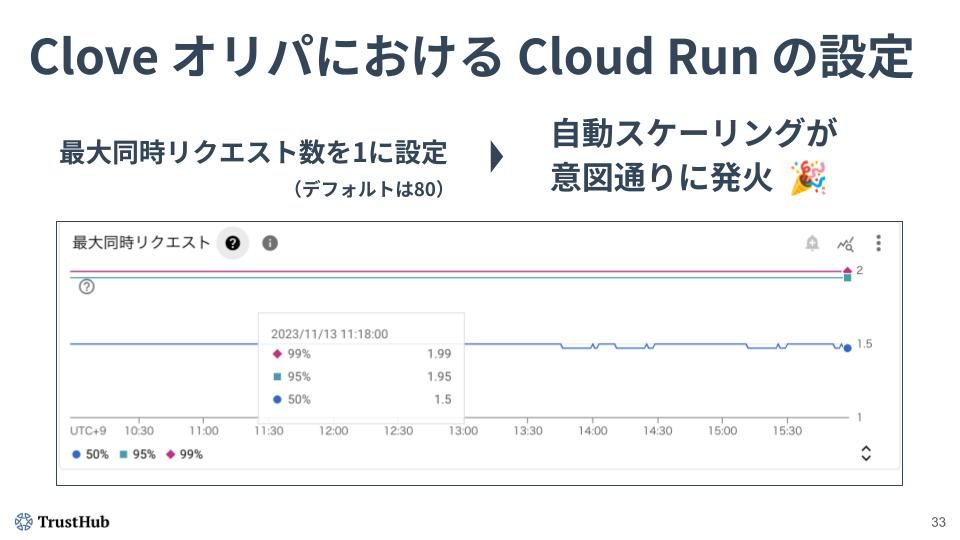
最大同時リクエスト数を1にすると、オートスケールが期待通りに発火する。
留意点
オートスケールによって新しいインスタンスが起動するとき、起動が完了するまで7-10秒程度かかります(起動時のCPUブーストを使わない場合)。そのため、あまりにもリクエストが増えると、インスタンスの起動が間に合わず、リクエストタイムアウトが発生する可能性があります。
これを防ぐには、インスタンスの待機台数を少し増やすことをおすすめします。例えば、待機インスタンスが15台あればリクエストが急増したときも既存の15台である程度捌くことができ、その間に新しいインスタンスを起動できます。また、Cloud Run の設定で「CPUを常に割り当てる」をONにしておくと、待機インスタンスはリクエストがきたときにすぐに処理を開始できます。

待機台数を増やしCPUを常に割り当てることで、オートスケールまでの時間を稼ぐ。
ただし、「CPUを常に割り当てる」を選択し待機台数を増やすとその分コストもかかりますので、その点は注意が必要です。[1]
最後に
本記事では、リクエストの急激なスパイクに耐えるための Google Cloud Run の設定方法について紹介しました。サービスが急成長したりある程度の規模になったりしてくると、安定した運用のためにこのような工夫が必要だと思います。
弊社トラストハブは、先日17億円の資金調達を実施しました。これに伴い、エンジニア採用を積極的に進めています。会社紹介スライドはこちらです。
カジュアル面談など、ご興味のある方はこちらの応募フォームから応募くださいませ。
また、10月10日(木)に、オフィス移転パーティーを開催します!
その場でレアなポケカが当たるかも?!な企画をご用意してお待ちしております。こちらもぜひ、以下のリンクよりご参加ください。
トラストハブ オフィス移転記念 〜遅れてやってきた縁日パーティー〜
-
Cloud Run の料金体系は以下に記載されています。 https://cloud.google.com/run/pricing
インスタンス台数が多くても1インスタンスあたりのvCPU数やメモリサイズを小さくすることでコストを抑えることができます。 ↩︎

Discussion