
Snowflake社が公開、展開しているdbt Cloudとの連携実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)。直近(2025年07月)時点での環境で一通り実践してみました。
当エントリでは実施した一連の手順のうち、「6. Foundational Structure」(dbtプロジェクトの基本構造) の内容について実践と解説を行っていきます。
※実施手順の全容については下記をご参照ください。
※これまでの実践内容一覧は以下をご参照ください。
実践#6: dbtの基礎構造を把握する
プロジェクト設定の更新 - マテリアライゼーションの設定変更
プロジェクトの開発を進めていくために、作業用の新しいGitブランチを作成していきます。画面左上のバージョン管理メニューから[Create branch]を選択し、
任意の名前で[Submit]を実行。プロジェクト設定ファイルのdbt_project.ymlファイルを更新してみます。このファイルはdbtが作業しているファイルディレクトリがdbtプロジェクトであることを認識するために探すファイルです。

dbt_project.ymlファイルの内容を以下の内容に置き換えます。(プロジェクト名は個別の名称に置き換えてください。その他は丸々上書きでOK。)
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'shinyaa31_dbt_snowflake_sandbox'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'default'
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In dbt, the default materialization for a model is a view. This means, when you run
# dbt run or dbt build, all of your models will be built as a view in your data platform.
# The configuration below will override this setting for models in the example folder to
# instead be materialized as tables. Any models you add to the root of the models folder will
# continue to be built as views. These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
shinyaa31_dbt_snowflake_sandbox:
staging:
materialized: view
snowflake_warehouse: shinyaa31_sandbox_wh_staging
marts:
materialized: table
snowflake_warehouse: shinyaa31_sandbox_wh_mart
上記変更内容での重要なポイントは models:セクションの内容です。ここではフォルダ(階層)レベルでそのフォルダ内の全てのモデルに適用したい「マテリアライゼーション」(永続化)の設定を定義しています。具体的には以下の指示指定を行っています。
-
materialized:dbtがSnowflakeにコードをプッシュする前に、コンパイル時にモデルをどのように実体化するかを指示 -
snowflake_warehouse: モデルを構築する際に使用するSnowflakeウェアハウスを指定
マテリアライゼーションはdbtモデルをウェアハウスに永続化するための戦略で、テーブルとビューが最も一般的に利用されるタイプです。デフォルトでは、すべてのdbtモデルはビューとしてマテリアライズされ、他のマテリアライゼーションタイプはdbt_project.ymlファイルまたはモデル自体で設定することができます。
dbtは、dbt_project.ymlファイルのこの設定に基づき、以下の処理を行います。
-
stagingフォルダにあるすべてのモデルをビューとして実体化(デフォルトの設定であるため必要ありませんが、例示のために含まれています) -
martフォルダにあるすべてのモデルをテーブルとして実体化
dbtのマテリアライゼーションを使用する利点は、dbtモデルを実行するときに、dbtがマテリアライゼーションに関連する適切なDDLを使用して、データウェアハウスにモデルと同等のものを作成することです。
また、各dbt接続は、Snowflakeでモデルを構築する際に使用するデフォルトのウェアハウスを宣言します。ファイル内のsnowflake_warehouse設定により、dbtはshinyaa31_sandbox_wh_stagingを使用してステージングフォルダ内のすべてを構築し、shinyaa31_sandbox_wh_martを使用してmartsフォルダ内のすべてを構築します。(当エントリでの進め方はいずれのウェアハウスもスペックは最小構成(x-small)としていますが、それぞれのウェアハウスのスペックが異なるものと考えるとイメージしやすいかと思われます) この構成により、プロジェクトのさまざまな部分の計算ニーズに基づいて、ウェアハウスのサイズをスケールアップしたりスケールダウンしたりすることが出来るようになります。
マテリアライゼーションとウェアハウスだけがプロジェクトレベルで適用できるコンフィギュレーションの種類ではありません。モデル、シード、そしてテストにコンフィギュレーションを適用する方法については、こちらのドキュメントをご覧ください。
そしてマテリアライゼーションについては後続のステップでも改めて言及解説していきます。ひとまずここでは下記ドキュメントを紹介するに留めます。
フォルダ構成の把握と整理
dbtでは「ベストプラクティス」として下記のドキュメントを公開しています。
このドキュメントではプロジェクトのフォルダ構造を構築する方法について多くの推奨事項が記載されています。今回のQuickstartで実践・構築するフォルダ構造はこのガイダンスに従う形となります。
-
ソース(sources):
- TPC-Hデータセットであり、ソースYAMLファイルで定義されている
-
ステージングモデル層(models/staging):
- 対応するソースと1対1の関係を持ち、名前を変更したり、キャストを変更したり、一般的にプロジェクトの残りの部分を通して一貫して使用される軽変換を実行するための場所として機能
-
マートモデル層(models/marts):
- ビジネスプロセスやエンティティを表現するモデルで、ベースとなるデータソースから抽象化されている。ここで主要な変換を行う
ガイダンスに従って実際に構成を整えていきます。modelsフォルダ右にある三点リーダーメニューから[Create Folder]を選択。
フォルダ名にstaging/tpchと入力して[Submit]実行。
同様の手順でmarts/coreフォルダも作成します。
以下のような構成が出来上がっていればOKです。

パッケージ
dbtには「パッケージ」という概念・機能があります。dbtパッケージは基本的にdbtプロジェクトであり、自分のプロジェクトに取り込むことで、あたかも自分のプロジェクトのようにコードを使用することができます。多くのパッケージは「dbt Packages Hub」というサイトでホストされています。
パッケージを活用することで、以下のようなことが実現出来ます。
- dbtソースやモデルを作成するための再利用可能なコードを生成
- Jinjaの様々な便利なマクロ(Macro)にアクセス
- Snowflakeデータベースのデータベース制約を構築
Jinja
「Jinja」と「マクロ」というワードが出てきたのでここで簡単な紹介をしておきます。
「Jinja」はpythonic(Python風)なテンプレート言語で、(dbtでは)SQLでは通常不可能なことを行うことができます。例えば、if文やforループのような制御構造を構築したり、コードの断片を再利用可能なマクロに抽象化して、同じことを繰り返さないようにしたり(DRY)ということを実現出来たりします。(※Jinja理解のために下記で紹介している「Use Jinja to improve your SQL code」を実践してみることをおすすめします)
マクロ
「マクロ(Macro)」は他のプログラミング言語における関数のように、dbtプロジェクト全体で何度も再利用できるjinjaコードの一部です。dbtで最も重要な関数であるsourceやrefもマクロの一部です。dbtのモデルの記載でSQLの変換を繰り返しているのであれば、パッケージの中にマクロがあるはずです。マクロは自分で構築することも出来ます。
ここでdbt Cloud上でパッケージを導入する手順を試してみましょう。「dbt_utils」というパッケージは、dbtで開発を行っていく上で非常に便利な機能が揃っています。ここでは試しにこのパッケージを入れてみます。
パッケージをインストールするには、まずホームディレクトリ(dbt_project.ymlファイルと同じ階層)に新しいファイルを作成します。ファイル名はpackages.ymlとします。


ファイルの中身は以下のテキストを記載。(パッケージのバージョンは現行最新のものと合わせました)
packages:
- package: dbt-labs/dbt_utils
version: 1.3.0
パッケージをインストールするdbtのコマンド:dbt depsを実行。コマンドが成功すればパッケージ導入も成功です。
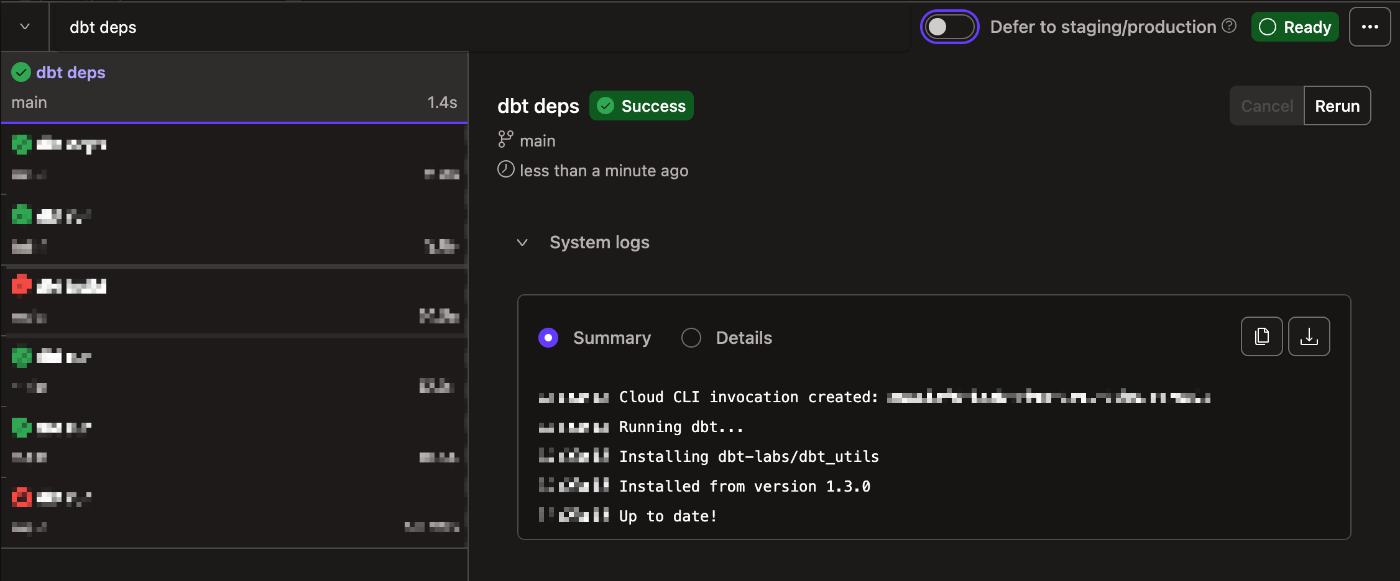
一通りの作業・内容が確認出来たのでここまでの内容をコミットし、Gitリポジトリに変更内容を反映させます。

まとめ
というわけで、Snowflake社提供のSnowflake&dbt Cloud実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)の実践編、#6「dbtプロジェクトの基本構造」の紹介でした。
次のエントリ「#7」ではソースデータに関する設定とステージング層モデルの作成を行っていきます。
参考:
