
2025年10月13日(月)〜16日(木)の計4日間、米国ラスベガスでの現地開催及びオンライン配信で展開されているdbtの年次カンファレンスイベント『Coalesce 2025』。
当エントリでは、米国時間2025年10月14日(火)に行われた1つめの基調講演『Opening keynote: Rewrite』のオンライン配信視聴レポートをお届けします。
キーノートに関するXの投稿まとめも合わせて作成しました。(※海外勢はどうやらdbtのSlackで盛り上がっていた模様)
セッション概要
イベントのAgendaによるセッション概要は以下の通り。
セッションレポート
ここからはイベント本編、キーノートで発表されたトピックやニュースを元に(おおよそ時系列で)情報をまとめていきます。
dbt Fivetranとの合併を発表
冒頭の寸劇(?)の後に登場したのはdbt Labs Founder & CEOのTristan Handy氏。まずは何は無くともこのキーノートが行われた日の前日、2025/10/13にアナウンスされた特大ニュース『dbtとFivetranの合併』について触れました。

合併自体の詳細については下記dbt公式ブログをご参照ください。
この部分に関するコメント要旨は概ね以下の通り。
- データ業界は現在「統合(consolidation)と拡張(expansion)」という主要な力によって変化している。「統合」とは、顧客が技術的問題を解決するポイントソリューションではなく、ビジネス上の問題を解決する統合されたソリューションを求めていることを指す。
- 私たちの分野には現在、数十億ドルの収益を上げている大手企業が5社あり、彼らは分析コンピュートエンジンから隣接サービスを追加する「オールインワンデータプラットフォーム戦略」を共通して採用している。(例を挙げた企業はSnowflake, Databricks, Microsoft)
- dbt Labsはこれに対し、コンピュートに関するユーザーの選択をサポートする「オープンデータインフラストラクチャ戦略」を提案。
- 経験上、ほとんどの企業が単一の分析コンピュートエンジンに標準化することはなく、dbt顧客の半数が複数のデータプラットフォームで作業していることが根拠とされている。この新しい世界は、Icebergをはじめとするオープンスタンダードによって実現可能となっている。
- dbt LabsとFivetranの製品を組み合わせた戦略図では、コンピュート領域は意図的に網掛けされておらず、独自の分析コンピュートエンジンを構築する計画はないことを強調。
- 「オープン」とは、すべてのコンピュートエンジン、大規模言語モデル(LLM)、データカタログ、BIツールをサポートするインフラストラクチャを意味する。
そして続けて特別ゲストとしてFivetranのCo-Founder & CEOのGeorge Fraser氏を招き、今回の合併に関する話とユーザーの選択を維持するデータインフラストラクチャの構築について議論を重ねました。

彼ら2人のディスカッションの要旨は概ね以下の通り。
- George氏は、Fivetranの長年の製品戦略は「顧客が解約する前に700ものコネクタのバグをすべて修正すること」という、規律を要するものであったと説明。この取り組みは初期に於いては毎晩深夜までバグ修正を行っていた経験を挙げ、コネクタの維持が非常に困難であったと語る。
- George氏は、当初dbtを懐疑的に見ていましたが、後にその価値を認め、dbtを「SQLのためのRails」と表現。アナリストがより多くの複雑性を管理し、真のインフラストラクチャを構築できるようになった影響を強調。
- 両社が担うべき役割は、「囲い込み(walled gardens)に対する代替案」を提供し、エコシステム全体とのオープン性と相互接続性を重視することであるとコメント。このビジョンは、顧客の選択を尊重し、Icebergなどのオープンスタンダードに賭けるものである。
- Fivetranは3年間Data Lakeに投資しており、Iceberg DataLakeを宛先として設定した場合、FivetranがS3へのファイル格納だけでなく、メタデータ更新やコンパクションを行うデータレイクの管理者として機能していると説明。
- dbtとFivetranの合併は、長い間理にかなったアイデアであり、ChatGPTも合併相手としてdbtを推奨していたとGeorge氏は冗談を交えて明かしていた。
- 合併の背景には、AIの台頭に伴い、マルチモーダルなデータと相互運用性が強く求められるという、データスタックの新しい章への移行があると説明。
- George氏は、dbtの「魔法」はオープンでエコシステムと互換性がある場合にのみ機能するため、dbtのライセンスや製品に破壊的な変更を加える計画は「断じてない」と明確に否定。
- 一方、Fivetranのコアコネクタが非オープンソースであるのは、多数のデータソースの付随的な複雑さに対処し、安定性を保つためには有償の開発が必要なためであるとも説明。
ディスカッションの後は、dbt Labsが長年にわたりクロスプラットフォームのオープンな未来に取り組んできた方向性における史上最大の投資、dbt Fusion Engineに関する思いを語りました。

- 新しいdbt EngineであるFusionは、dbt Coreよりも解析時間が30倍高速であり、劇的に生産性を向上させ、Developer Experience(開発者体験)を大きく改善させた。
- Fusionは、大規模な組織全体でPII(個人識別情報)を追跡し、ガバナンスする機能を有しており、レイクハウスアーキテクチャに最適。
- Fusionは、書かれたSQLを特定のダイアレクトから抽象化し、データワークロードがデータストレージと同じくらいプラットフォームに依存しないものとなることを可能にする。
- FusionとIcebergの組み合わせは、オープンデータインフラストラクチャにとって理想的なレシピであるとされている。
- Fusionは、進化するデータエコシステムの未来において、AIおよびエージェントにとって完璧な補完物であると位置付けている。
Tristan氏はFusionをdbtの未来だと信じていますが、dbtを中心にキャリアを築いてきたコミュニティに対し、変化が難しいことを認めました。そしてこの変化を乗り越えるため、Tristan氏はコミュニティに対し、CoreではFusionが目指す方向へ進めなかった理由など、いくつかの"率直な声明"を述べました。

- #1. dbt CoreはFusionが目指す方向へは進めなかった
- dbt Coreは技術的に9年前のコードベースであり、2016年当時には現在の世界を予測する術がなかったため。
- Coreは素晴らしいワークフローイノベーションであり、dbtが存在する理由ですが、過去に固執するつもりはない。
- #2. dbt Coreがどこかへ行くことはない
- 現在Coreを使用している場合でも、それはなくなりません。
- dbt LabsはCoreへの投資を継続する。
- Fusionの利点は自明であると信じているものの、アップグレードには時間がかかるという現実を認識しており、アップグレードはユーザーの自由な選択とする。
- #3. 既存のdbtコードは概ねそのままFusionで動作する
- Fusionは、世の中にある文字通り何十億行ものdbtコードと可能な限り適合するように設計されている。
- メジャーバージョンアップグレードと同様にコード変更が必要な領域はありますが、それを自動化するためのツールが構築されている。
- #4. Fusionは無料で利用可能である
- dbt Coreと同様に、FusionはCLI上で無料でローカルに使用可能(支払いは不要)。
- #5. Fusionは未来への架け橋である
- データエコシステムとデータ実務家の未来は変化しており、その変化を推進している二つの力は「標準(Standards)とAI」。
- Fusionは、dbtコミュニティがこの新しい世界と結びつくための答えの大きな部分を占めている。
そしてここからは様々な登壇者が入れ替わり立ち替わりで登場し、今後のdbtプロダクトにおける興味深い新機能についてデモなどを適宜交えて紹介していきました。関連する公式ドキュメントの情報と合わせて紹介していきます。
MetricFlow、オープンソース化
Metric FlowをApache 2.0ライセンスの下で正式にオープンソース化し、dbt Labs、Snowflake、およびTableauによって共同でガバナンスされることが発表されました。

対応するPullRequest:
[Preview] Fusion in the dbt Platform

以下に示すようなFusionの機能がdbtプラットフォーム上で使えるようになります。"変更の比較"(Compare Changes)に関してはComing Soonとアナウンスがあったので比較的早めに使えるようになりそうです!楽しみですね。
- 即時コード検証(Real-time code validation)
- CTEプレビュー (CTE Preview):FusionはSQL Comprehensionを使用し、このセクションからの出力だけを吐き出すクエリを構築
- 変更の比較(Compare changes):比較ボタン押下でFusionはデータ差分(data diff)を実行し、このモデルへの変更がデータに与える正確な影響を調査
- 影響分析(Impact Analysis):変更を行った箇所起点で(影響のある)ダウンストリームのファイルをハイライト
- カラム名変更の伝播(column name propagation):カラム名を変えるとFusionはすべてのダウンストリームモデルを書き換えて、新しいカラムを参照するようにする
- クロスプラットフォームコンパイル(Cross-platform compilation)

[Preview] 状態認識オーケストレーション(State-aware Orchestration)

状態認識オーケストレーション(State-aware Orchestration)は、実際に実行する必要があるものだけを実行することで、データパイプラインの動作を根本的に書き換えるFusionを活用した機能です。
従来のdbt実行では、入力が変更されたかどうかに関係なく、DAG内のすべてのモデルが再構築される形となっていました。
そして、今回のアナウンスにて、ジョブの設定で「Fusionコスト最適化機能を有効にする」を選択することで有効にできるようになりました。(以前は、状態認識オーケストレーションを有効にするには、「ノードの強制選択」を無効にする必要がありました)

アナウンスに合わせて公開されたブログエントリはこちら。
その他、状態認識オーケストレーション(State-aware Orchestration)に関する情報は下記ドキュメントをご参照ください。
[Preview] 状態認識オーケストレーションにおける詳細設定(Tuned Configuration)

状態認識オーケストレーションの子機能的な形で追加アナウンスされた機能。状態認識型オーケストレーション自体は有効化するだけで即座にコスト削減を実現するものとされていますが、この詳細設定を使うことで、ジョブを厳密にスケジュールする代わりに、データの鮮度要件をdbtプロジェクト内で直接表現できるようになるようです。
状態認識オーケストレーションの解説記事の中でこの詳細設定に関する言及も為されています。
[Preview] 状態認識オーケストレーションにおける効率的なテスト(Efficient Testing)

この機能は、冗長なデータテストを回避し、複数のテストを単一のクエリにまとめることで、ウェアハウスコストを削減出来るというものです。この機能もTuned Configuration同様、状態認識オーケストレーションに関連するものとされています。

詳細に関しては下記ドキュメントをご参照ください。
[GA] dbt Insights
セッション終盤でアナウンスされたのは生成AI周りに関する諸機能。dbt Insightsは、Catalog(メタデータ)、Studio IDE、Canvas、Copilot、Semantic Layerと統合されており、シームレスにデータ探索やクエリの実行、AI支援ツールの活用、チーム内コラボレーションが可能なエクスペリエンスを提供する機能です。このタイミングでGA(General Availability: 一般利用可能)になりました。
機能詳細に関しては下記ドキュメントなどをご参照ください。
[GA] dbt MCP Server

各種生成AIツールとdbtプロジェクトを安全かつ構造的に接続するためのサーバー機能『dbt MCP Server』もGAとなりました。
機能詳細に関しては下記ドキュメントなどをご参照ください。
[Coming Soon] dbt Agents

ユーザーからの指示を受け取り、タスクをエンドツーエンドで実行できるようになるAIエージェント機能としてdbt Agentsというものがアナウンスされました。今回発表されたのは以下4つ。いずれもComing Soonなステータスです。
Developer Agent
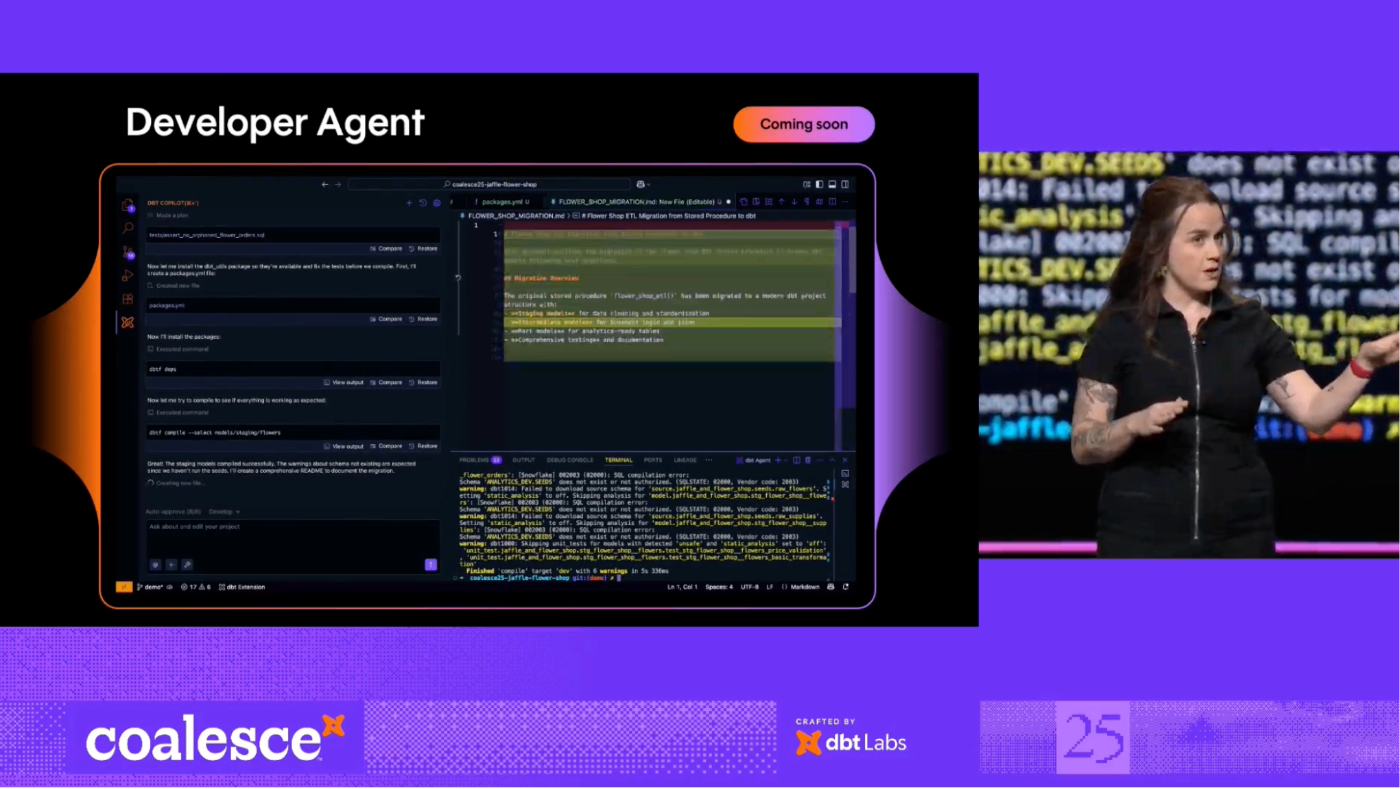
- 開発者エージェント(Developer Agent):
- SQLファイル、テスト、ドキュメントの作成、Fusionによる検証、そしてウェアハウスでの実行といった「構築」フェーズの作業を自動化し、統制された監査可能なエージェント的アクションを実現。
Observability Agent
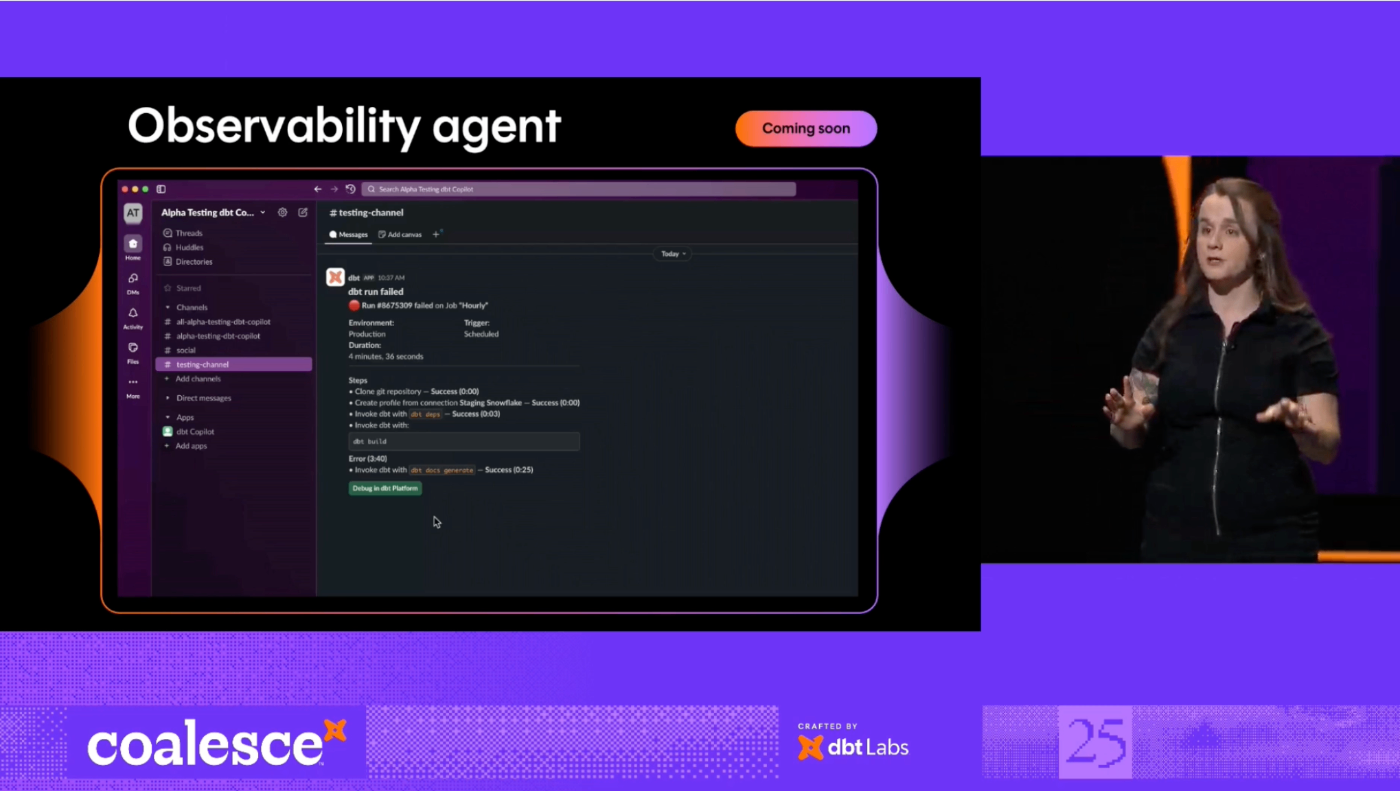
- オブザーバビリティエージェント(Observability Agent):
- 故障したパイプラインの問題点を正確に特定し、修正を迅速化することを目的とする。
- チームがパイプラインの修正や厄介なログの精査に費やす時間を削減し、より信頼性の高いパイプラインを実現。
Discovery Agent

- ディスカバリーエージェント(Discovery Agent):
- 適切なデータアセットを見つけることを支援し、カタログやドキュメントから承認されたデータセットと定義を特定。
- データが「なぜ信頼できるのか」を示し、標準的な検索以上の価値を提供することで、発見にかかる時間と手戻りを削減。
Analyst Agent
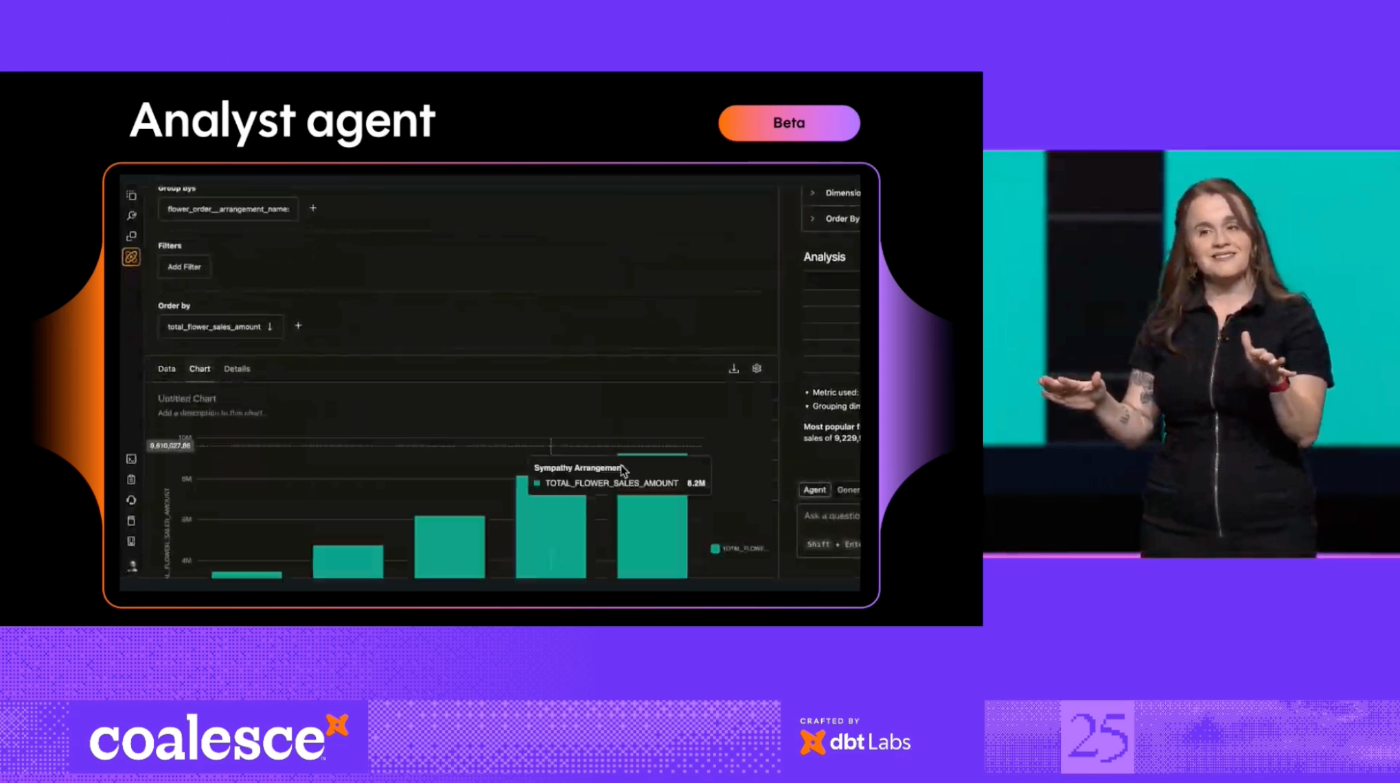
- アナリストエージェント(Analyst Agent):
- 企業内の誰もが、データに対して直接簡単な質問をすることを可能にする目的で導入。
- dbt Semantic Layerとdbtプロジェクトのコンテキストを活用し、対話型分析を構築することなく、統制された回答を得ることで、AI導入を自信を持ってスケールできるようにする。
まとめ
という訳でdbt Coalesce 2025、1つめの基調講演『Opening keynote: Rewrite』のオンライン配信視聴レポートでした。Fivetranとの合併話も含め、今後の展開が更に気になる各種機能の発表もそれなりにあって有意義なセッションだったと思います。
引き続き、この後配信予定の『Tuesday afternoon keynote: Rewrite what's possible』も観ていこうと思います!
