
Snowflake社が公開、展開しているdbt Cloudとの連携実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)。直近(2025年07月)時点での環境で一通り実践してみました。
当エントリでは実施した一連の手順のうち、「8. Seeds and Incremental Materialization」(シードと増分マテリアライゼーション) の内容について実践と解説を行っていきます。
※実施手順の全容については下記をご参照ください。
※これまでの実践内容一覧は以下をご参照ください。
- Snowflake&dbt Cloud Quickstart 実践 #1〜#5「実践環境の準備・導入」
- Snowflake&dbt Cloud Quickstart 実践 #6「dbtプロジェクトの基本構造」
- Snowflake&dbt Cloud Quickstart 実践 #7「ソースデータ設定とステージング層モデルの作成」
実践#8: シードと増分マテリアライゼーション
このステップではdbtの機能である「シード(seed)」と「マテリアライゼーション(Materialization)」を使い、インクリメンタルなステージングモデルを作ります。
シード(seeds)について
シード(seeds) とは、dbtプロジェクト内のCSVファイルのことで、ほとんど変更のない小規模で静的なデータセットを用意・投入するケースに最適です。dbtでCSVファイルをシードとしてアップロードすることで、バージョン管理、テスト、ドキュメント作成など、他のモデルと同じベストプラクティスをCSVに適用することができます。例を挙げると、国コードのマッピングのリストや、特定のモデルから除外する従業員ユーザーIDのリストなどがあります。
ここでは、注文が行われている国名/地域を含むシードを作成し、dbt seedコマンドを使用してdbtにシードをSnowflakeに読み込ませます。
インクリメンタル(増分)モデルについて
インクリメンタルモデル(incremental model) は、最後にdbtを実行したときから変換する必要のあるデータ量を制限したい大規模なデータセットに最適です。ウェアハウスのパフォーマンスを向上させ、計算コストを削減しながら、冪等性を維持することができます。その仕組みを踏まえてモデルがSnowflakeのテーブルとして構築されます。
モデルの初回実行時には、クエリ内のすべての行を変換してテーブルが構築されます。そしてその後の実行では、dbtはタイムスタンプまたは一意キーに基づいてフィルタリングするようにdbtに指示した行のみを変換します。Snowflakeでは、ターゲットテーブル(つまり、最初の実行で構築されたテーブル)にレコードを挿入する方法として、幾つか種類・方法が提供されています。マージ(Merge)メソッドはデフォルトのメソッドであり、ここで説明するメソッドとなります。
このハンズオンで扱っている「TPC-Hデータセット」自体は変化するものではありませんが、増分マテリアライゼーション機能がどのように機能するかを示すために、モデルの1つをインクリメンタルにしていきます。以下の順番で作業を進めていきます。
- 最初にシードを構築し、他のdbtモデルと同じようにシードを参照できるようにする
- seedを参照するインクリメンタルモデルを構築し、seedの元の状態(バージョン1)を反映させるために、dbtにインクリメンタルモデルを完全に構築させる
- seedを更新し、シードの最新の状態(バージョン2)を反映するように再構築
- 最後に、バージョン2のシードでインクリメンタルモデルを再実行
- (これは、シードに加えた特定の変更のみを実行し、インクリメンタルなマテリアライゼーション戦略を完全に実証するものです)
シードを使って対象データを準備
インクリメンタルモデルの対象となるデータをシード機能を使って準備します。seedsフォルダにnations.csvというファイルを作成し、ファイルパスをseeds/nations.csvとします。
このデータは、注文に関連する国とその地域のリストです。この種のデータは、データの変更頻度が低く、他のモデルのように一貫した更新を必要としないため、シードのユースケースに最適です。
N_NATIONKEY, N_NAME, N_REGIONKEY, LAST_UPDATED_DATE
0, ALGERIA, 0, 1998-08-02
1, ARGENTINA, 1, 1998-08-02
2, BRAZIL, 1, 1998-08-02
3, CANADA, 1, 1998-08-02
4, EGYPT, 4, 1998-08-02
5, ETHIOPIA, 0, 1998-08-02
6, FRANCE, 3, 1998-08-02
7, GERMANY, 3, 1998-08-02
8, INDIA, 2, 1998-08-02
9, INDONESIA, 2, 1998-08-02
10, IRAN, 4, 1998-08-02
11, IRAQ, 4, 1998-08-02
12, JAPAN, 2, 1998-08-02
13, JORDAN, 4, 1998-08-02
14, KENYA, 0, 1998-08-02
15, MOROCCO, 0, 1998-08-02
16, MOZAMBIQUE, 0, 1998-08-02
17, PERU, 1, 1998-08-02
18, CHINA, 2, 1998-08-02
19, ROMANIA, 3, 1998-08-02
20, SAUDI ARABIA, 4, 1998-08-02
21, VIETNAM, 2, 1998-08-02
22, UNITED KINGDOM, 3, 1998-08-02
23, UNITED STATES, 1, 1998-08-02
このデータをデータウェアハウスに投入します。dbt Cloud IDE経由でコマンドdbt seedを実行。
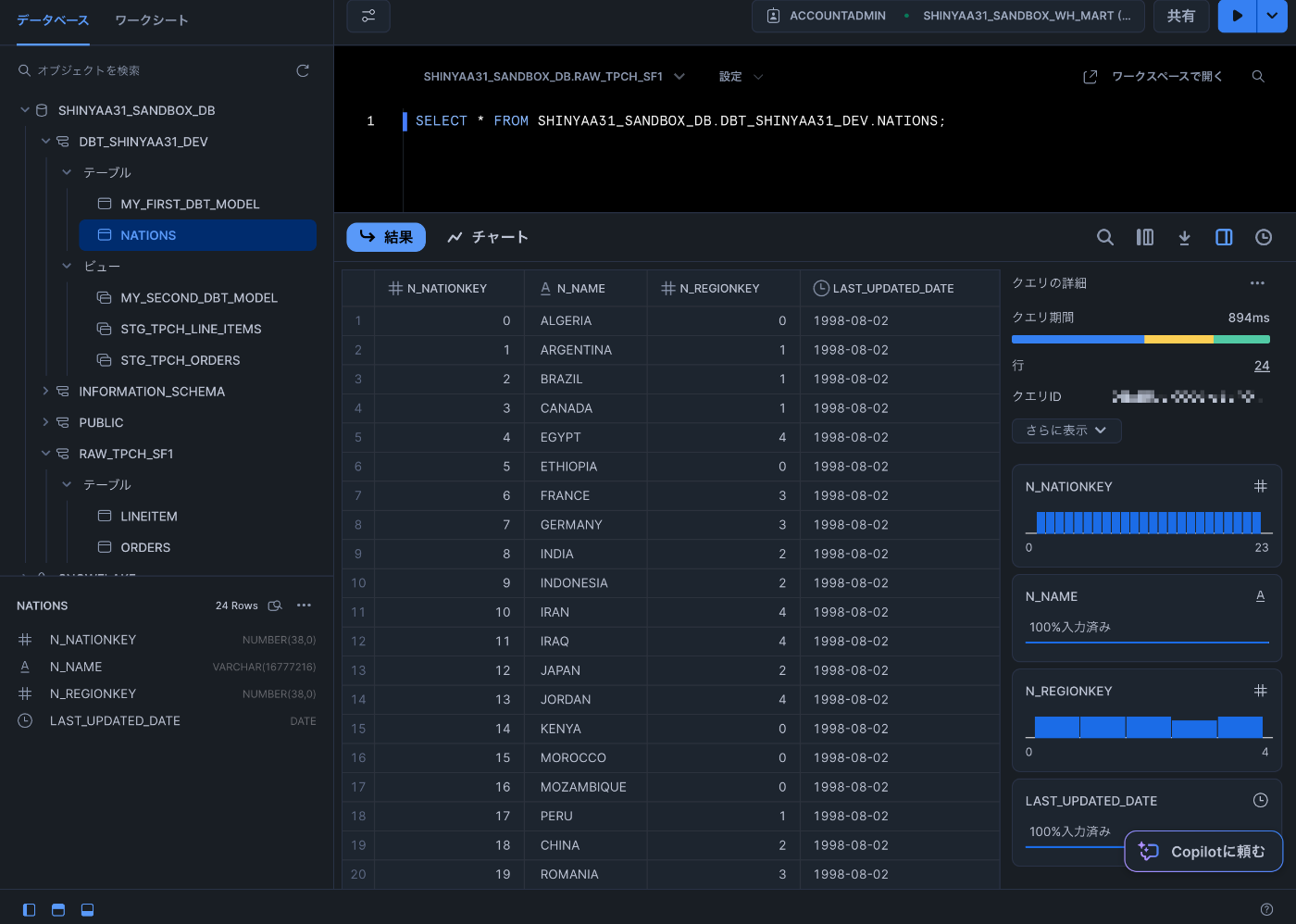
seedコマンドはSnowflakeに、CSVファイルで提供したすべてのデータでテーブルを構築するように促し、他の場所に構築するように指定していないため、デフォルトスキーマに作成するように促します。seedが正常に構築されたら、Snowflakeコンソールで内容を確認。nationsテーブルが作成され、データが投入されていることを確認します。
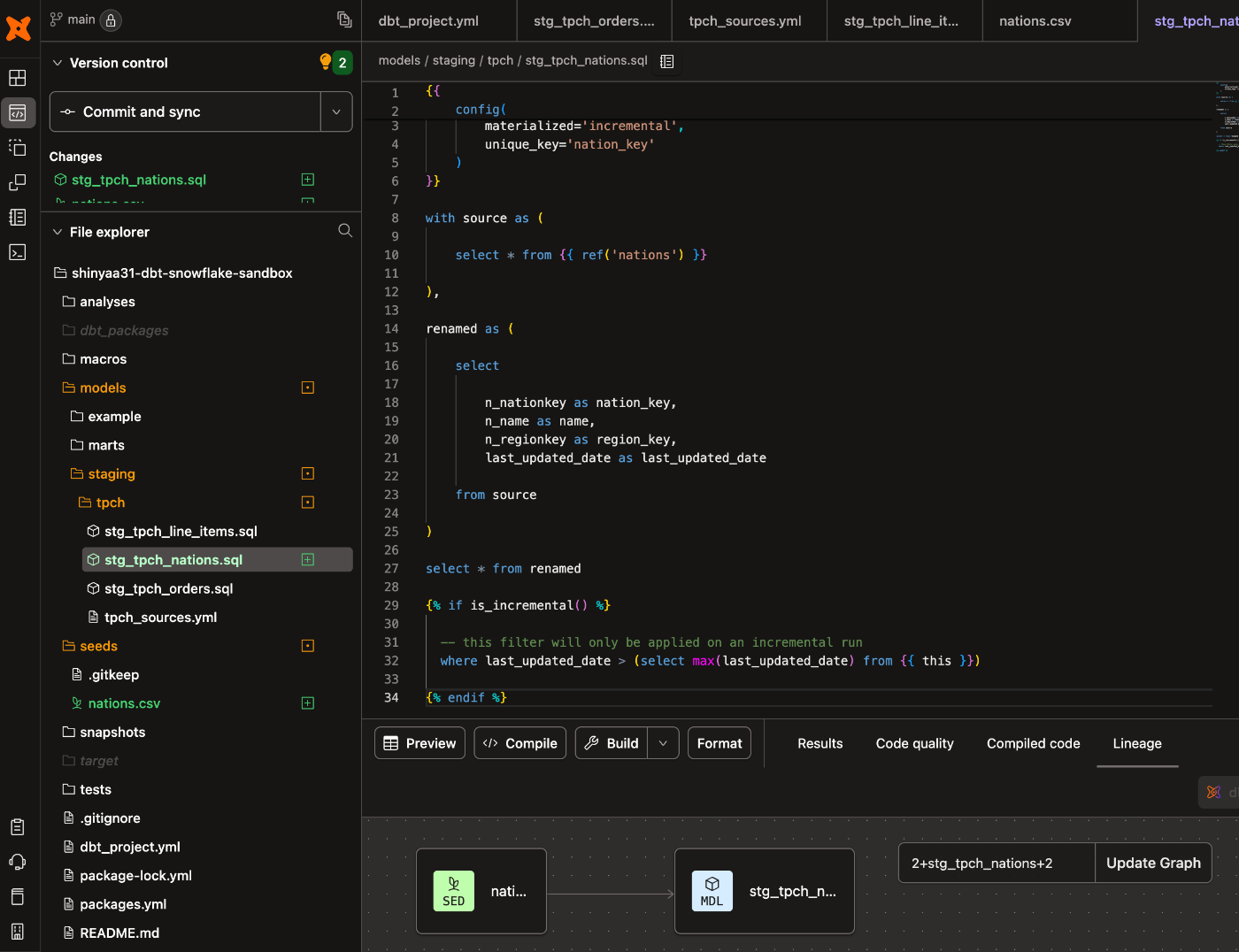
シードを参照するインクリメンタルモデルを作成
ハンズオンではこの作成したシード情報(Nation)に関して『営業チームからいくつか変更が必要だと連絡があった』『具体的には、より多くの国で販売を開始するので、region_keyカラムを更新して、現在販売している国との整合性を取りたい』という要件が発生した...という想定でこのデータを使ったモデルをインクリメンタルモデルとして作成し、dbtで既存のモデルにデータを簡単に追加・更新できることを確かめよう、という流れになっています。
ということでインクリメンタルモデル作成に移ります。models/staging/tpch/stg_tpch_nations.sqlのパスでファイルを作成。
{{
config(
materialized='incremental',
unique_key='nation_key'
)
}}
with source as (
select * from {{ ref('nations') }}
),
renamed as (
select
n_nationkey as nation_key,
n_name as name,
n_regionkey as region_key,
last_updated_date as last_updated_date
from source
)
select * from renamed
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where last_updated_date > (select max(last_updated_date) from {{ this }})
{% endif %}
上記で作成したモデルを実行してみます。dbtのコマンドでは、条件を指定して任意の条件に合致するモデルのみを実行することが出来ます。
ここでは該当するモデルのみを実行する形で dbt run --select stg_tpch_nationsと実行。引数--selectで引数の後に指定したモデルまたはパス(この場合はstg_tpch_nationsモデル)だけを実行するようにdbtに指示することが出来ます。

実行結果詳細を確認してみます。ログを見るとdbtがこのモデルをインクリメンタルとして実行していることが確認出来ます。
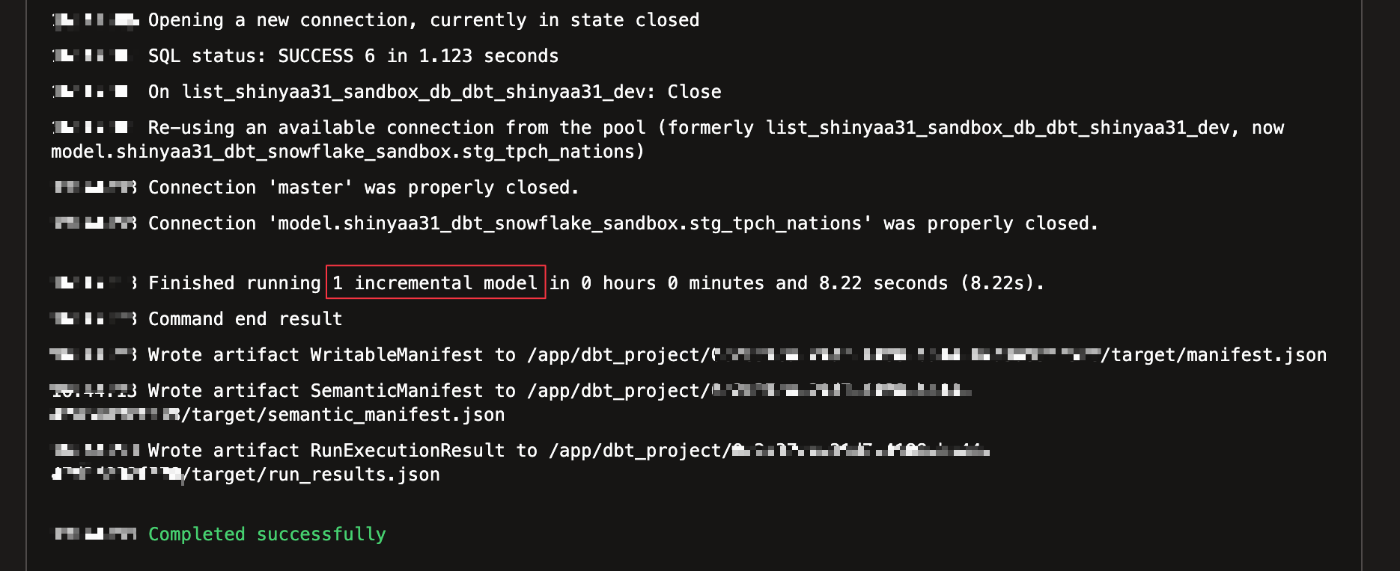
インクリメンタルモデルの実装内容を振り返ってみます。モデルの一番上にあるconfigブロックは、定義されたconfigをこのモデルだけに適用しており、インクリメンタルモデルとして実体化したいと最初に言っていることがわかります(stg_tpch_nations.sql 2行目)。
{{
config(
materialized='incremental',
unique_key='nation_key'
)
}}
しかし、DDLは通常のdbtテーブルの実体化として実行されました。これは、インクリメンタルモデルが最初に実行されるとき、Snowflakeには既存のデータベースオブジェクトが存在しないため、最初にテーブルを作成する必要があるためです。
同じ設定ブロックで、モデルのユニークキーをnation_keyとして定義しています。一意キーを定義するということは、このモデルをインクリメンタルに実行するときに、一意キーを使用して個々の行に更新があるかどうかを判断し、更新があれば、モデルの最後に新しい行を追加することに加えて、それらの行を更新することを意味します。dbtはテーブルとしてモデルを作成し、アップロードしたnationsseedからすべてを選択し、軽いリネーミングを行い、それらの値を返します。

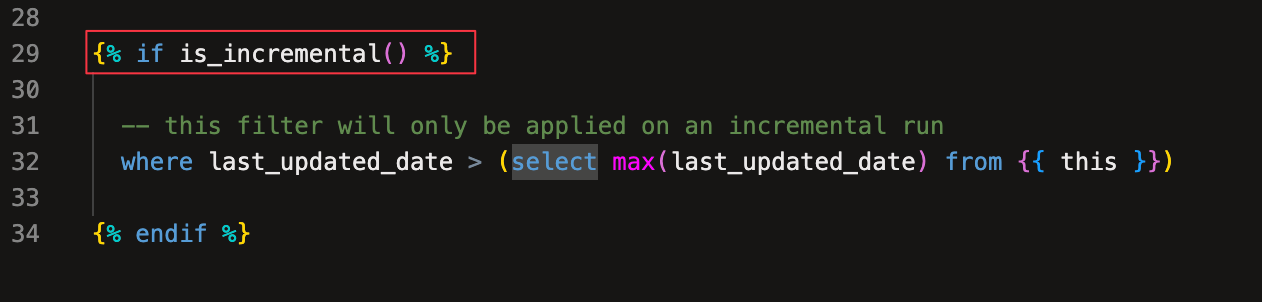
このコードでは、クエリの下部にis_incrementalマクロを使った実装も含まれています。このマクロは、特定のコア条件式に基づくモデルのインクリメンタル実行時に実行されるように設定されています。
インクリメンタルモデルの最初の実行がインクリメンタル実行でないことを考えると、is_incremental = falseであり、dbtはマクロ内で定義されたwhere句をコンパイルしません。次の実行では、is_incrementalはtrueになり、マクロはコンパイルされ、where句の動作を見ることができます。
データの更新とモデル実装結果の確認
これで、営業チームのニーズに合わせてシードを更新する準備が整いました。シード・ファイルをもう一度開き、既存の内容を削除&下記の内容を上書き更新します。このファイルには幾つかのアップデートが含まれています。
- セールスチームから北米の国々に独自のregion_keyを持たせるように要請があったことで、これはregion="5"として指定されている
- カナダとアメリカは、私たちのシードに含まれている既存の国であり、リージョンもそれに合わせて更新された
- リストに追加された新しい国もいくつかあり、それらの地域は更新され、最新のものとなっている
- すべての新しい行と更新された行の last_updated_date が、変更を反映するように更新されている
N_NATIONKEY, N_NAME, N_REGIONKEY, LAST_UPDATED_DATE
0, ALGERIA, 0, 1998-08-02
1, ARGENTINA, 1, 1998-08-02
2, BRAZIL, 1, 1998-08-02
3, CANADA, 5, 2022-05-09
4, EGYPT, 4, 1998-08-02
5, ETHIOPIA, 0, 1998-08-02
6, FRANCE, 3, 1998-08-02
7, GERMANY, 3, 1998-08-02
8, INDIA, 2, 1998-08-02
9, INDONESIA, 2, 1998-08-02
10, IRAN, 4, 1998-08-02
11, IRAQ, 4, 1998-08-02
12, JAPAN, 2, 1998-08-02
13, JORDAN, 4, 1998-08-02
14, KENYA, 0, 1998-08-02
15, MOROCCO, 0, 1998-08-02
16, MOZAMBIQUE, 0, 1998-08-02
17, PERU, 1, 1998-08-02
18, CHINA, 2, 1998-08-02
19, ROMANIA, 3, 1998-08-02
20, SAUDI ARABIA, 4, 1998-08-02
21, VIETNAM, 2, 1998-08-02
22, UNITED KINGDOM, 3, 1998-08-02
23, UNITED STATES, 5, 2022-05-09
24, MEXICO, 5, 2022-05-09
25, AUSTRALIA, 2, 2022-05-09
26, NEW ZEALAND, 2, 2022-05-09
27, SOUTH KOREA, 2, 2022-05-09
28, BELGIUM, 3, 2022-05-09
29, SWEDEN, 3, 2022-05-09
30, SPAIN, 3, 2022-05-09

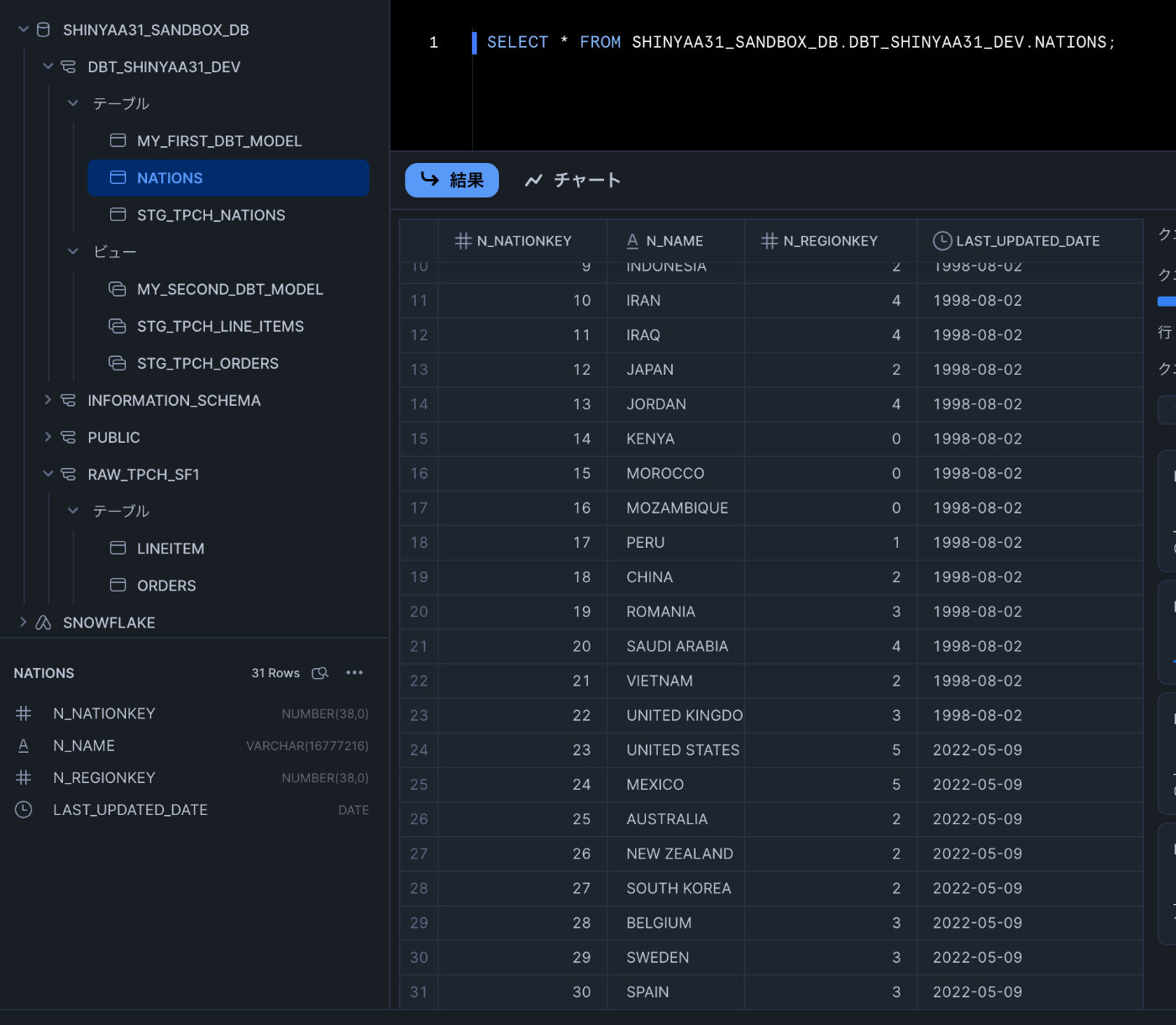
dbtコマンドdbt seedを再度実行し、Snowflake環境のデータが更新されていることを確認。SQLクエリによる実行は実はdbt Cloud IDEでも可能です。エディタ部分の[+]をクリックして新規エディタを開き、任意のSQLを実行することでSnowflake UI同様の結果確認を行えます。
当ステップ最大の焦点となるアクション:インクリメンタルモデルの挙動確認です。前回同様、対象モデルのみの実行指定でモデル実行を行います。コマンド:dbt run --select stg_tpch_nationsを実行。実行後ログ詳細を確認してみます。
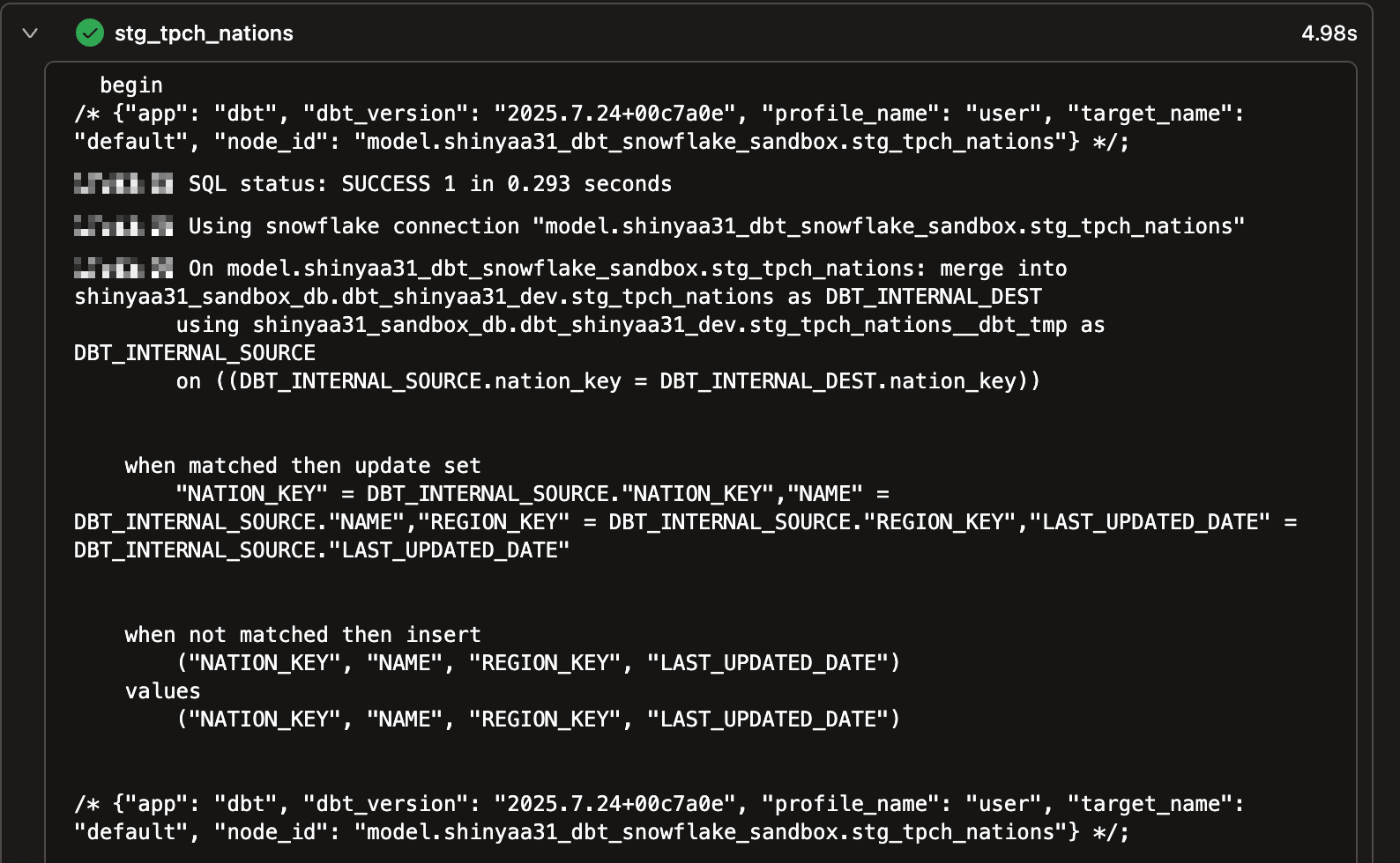
まず最初のポイントは開始時にテーブルを作成する代わりに、dbtはis_incrementalマクロのwhere句を含むモデルの内容で一時テーブルを作成するために必要なコードをコンパイルしていることです。where句はlast_updated_dateに基づいて行をフィルタリングしており、last_updated_dateがモデルの現在の結果の最大日付より大きいレコードだけを含めています。

以下のコードはnation_keyを結合する一意性制約として使用して、tempテーブルの結果を倉庫内の既存のstg_tpch_nationsテーブルに結合するマージ文です。既存のstg_tpch_nationsテーブルをターゲットテーブルとして定義し、プロセスの最初の部分で作成したtempテーブルをターゲットテーブルと結合するソーステーブルとして定義します。
更新と挿入の問題に取り組むために、dbtは更新用のmatchedClauseと挿入用のnotMatchedClauseのコードをコンパイルします。tempテーブルのnation_keyとターゲットテーブルのnation_keyが一致する全ての行に対して、matchedClauseを使用して、tempテーブルの全てのカラム値でその行を更新します。そしてtempテーブルのnation_keyがtargetテーブルにまだ存在しない全ての行に対して、notMatchedClauseがそれらの行をtargetテーブルに挿入するために使用されます。
以上でインクリメンタルモデル、及び関連するシードが出来ました。
インクリメンタルモデルは、実行のたびに結果セット全体を再構築する必要がないような非常に大きなデータセットに適用するのが最適です。また、Snowflakeでは、mergeがデフォルトで、delete+insertが代替オプションとして幾つかの標準的なインクリメンタルメソッドがあることに留意すべきです。
まとめ
というわけで、Snowflake社提供のSnowflake&dbt Cloud実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)の実践編、#8「シードと増分マテリアライゼーション」の紹介でした。
次のエントリ「#9」ではマートモデルの作成を行っていきます。
参考:
