
Snowflake社が公開、展開しているdbt Cloudとの連携実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)。直近(2025年07月)時点での環境で一通り実践してみました。
当エントリでは実施した一連の手順のうち、「7. Sources and Staging」(ソースデータ設定とステージング層モデルの作成) の内容について実践と解説を行っていきます。
※実施手順の全容については下記をご参照ください。
※これまでの実践内容一覧は以下をご参照ください。
- Snowflake&dbt Cloud Quickstart 実践 #1〜#5「実践環境の準備・導入」
- Snowflake&dbt Cloud Quickstart 実践 #6「dbtプロジェクトの基本構造」
実践#7: ソースデータ設定とステージング層モデルの作成
このセクションでは、ソースとステージングモデルについて作業を進めていきます。
dbtのソース(source)を使用すると、dbt プロジェクト内でウェアハウスの生データに名前を付けて記述することができ、生データから変換されたモデルへのリネージを確立することができます。dbtでソースを定義すると、変換されたモデルだけでなく、これらのソースにも同じテストとドキュメンテーションのベストプラクティスを適用することができます。
ステージング・モデルはソース・テーブルと1対1の関係にあります。ここで、名前の変更、キャストの変更、列をより使いやすい形式に変更するなどの簡単な変換を行います。
ステージングモデルを構築することで、下流のモデリングのための明確な基盤ができ、モジュール式のDRY(Don't Repeat Yourself)モデリングが可能になります。ロジックが変更された場合、同じサブクエリで5つのモデルを更新するのではなく、1つのモデルで更新することができます。
今回のステップ用のブランチを作成し、作業を進めていきます。
ソースの作成
ここではまず、TPCH_SF1スキーマの ordersテーブルとlineitemテーブルを対象として変換処理を行いたいと思います。この2テーブルに対するソース定義を作成します。
models/staging/tpch/フォルダ配下にtpch_sources.ymlというファイルを作成、以下の内容で保存。このファイルでは、データの取得元データベース (snowflake_sample_data)、スキーマ (tpch_sf1)、ビルドと変換を行うテーブルが定義されています。各テーブル名の下には、ソースに適用した説明とテストが記載されていますが、これについては後のテストとドキュメントのセクションで詳しく説明します。
version: 2
sources:
- name: tpch
description: source tpch data
database: snowflake_sample_data
schema: tpch_sf1
tables:
- name: orders
description: main order tracking table
columns:
- name: o_orderkey
description: SF*1,500,000 are sparsely populated
tests:
- unique
- not_null
- name: lineitem
description: main lineitem table
columns:
- name: l_orderkey
description: Foreign Key to O_ORDERKEY
tests:
- relationships:
to: source('tpch', 'orders')
field: o_orderkey

ステージング層のモデルを作成
次いで、上記で定義した2つのデータソースを参照する形でステージング・モデルを作成します。ステージング・モデルと対応するソース・テーブルの間には1対1のリレーションシップがあるため、ここでは2つのステージング・モデルを構築します。
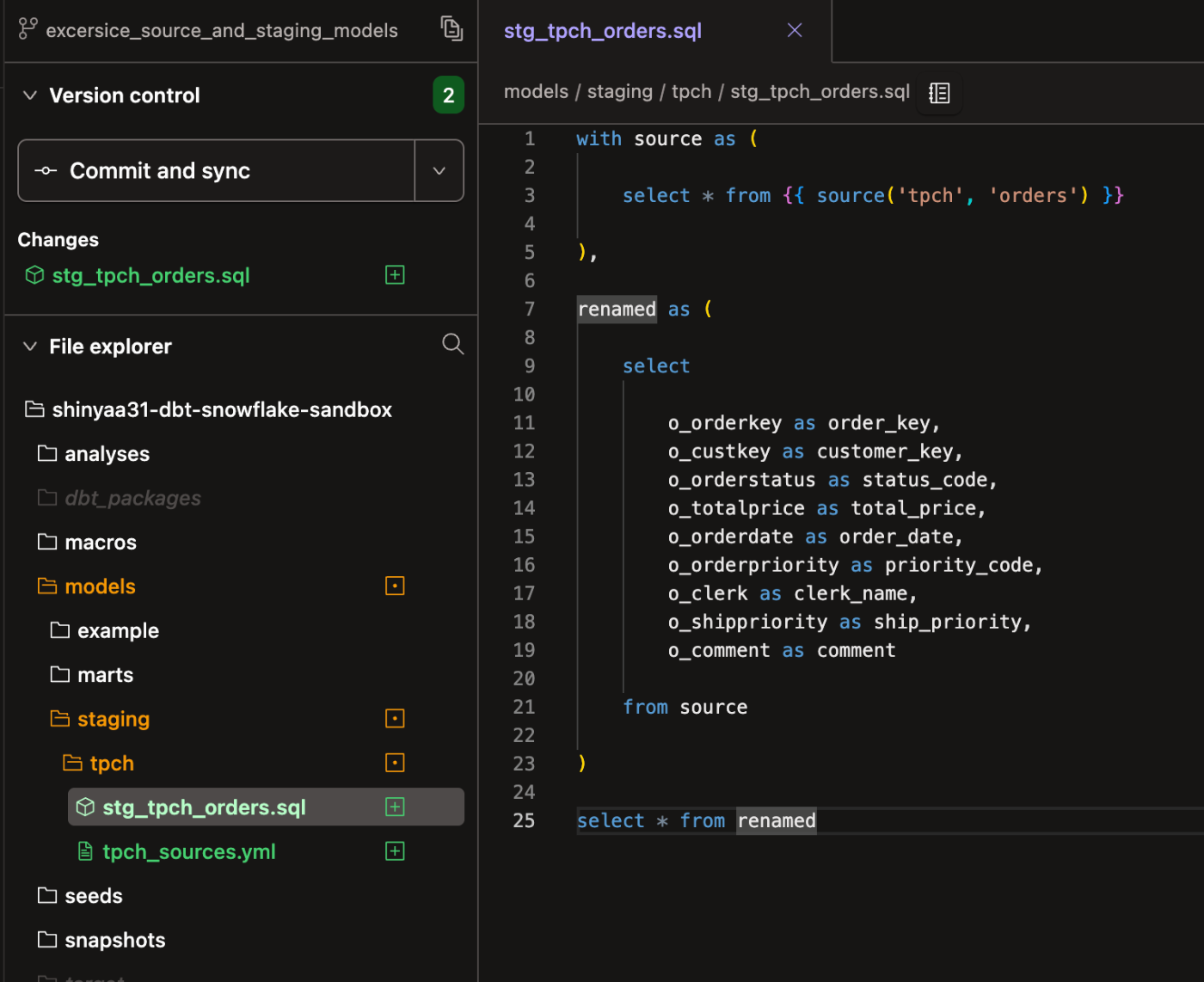
モデル:stg_tpch_orders.sqlの作成
ordersテーブルにおけるステージング層モデルをstg_tpch_orders.sqlというファイルで定義します。作成・配置するフォルダはmodels/staging/tpch/とします。
(相対パス:models/staging/tpch/stg_tpch_orders.sql)
ここで行ったことは、ソース関数を使用してソースデータをモデルに取り込み、カラムの名前を変更することだけです。
これは、このデータを参照する必要がある他のすべてのモデルの出発点として機能し、プロジェクト全体で命名が一貫した状態を維持します。
with source as (
select * from {{ source('tpch', 'orders') }}
),
renamed as (
select
o_orderkey as order_key,
o_custkey as customer_key,
o_orderstatus as status_code,
o_totalprice as total_price,
o_orderdate as order_date,
o_orderpriority as priority_code,
o_clerk as clerk_name,
o_shippriority as ship_priority,
o_comment as comment
from source
)
select * from renamed
モデル:stg_tpch_line_items.sqlの作成
2つ目のモデル(lineitem)に関しても上記同様の流れで作成します。
(相対パス:models/staging/tpch/stg_tpch_line_items.sql)
11〜14行目に記載しているdbt_utils.surrogate_keyは、マクロにリストされたカラムを使用してorder_item_keyと呼ぶハッシュ化されたサロゲートキーを作成します。このサロゲートキーを実装することで、一意なカラムを得ることができます。サロゲート・キー・マクロの動作の詳細については下記を参照してください。
with source as (
select * from {{ source('tpch', 'lineitem') }}
),
renamed as (
select
{{ dbt_utils.surrogate_key(
['l_orderkey',
'l_linenumber']) }}
as order_item_key,
l_orderkey as order_key,
l_partkey as part_key,
l_suppkey as supplier_key,
l_linenumber as line_number,
l_quantity as quantity,
l_extendedprice as extended_price,
l_discount as discount_percentage,
l_tax as tax_rate,
l_returnflag as return_flag,
l_linestatus as status_code,
l_shipdate as ship_date,
l_commitdate as commit_date,
l_receiptdate as receipt_date,
l_shipinstruct as ship_instructions,
l_shipmode as ship_mode,
l_comment as comment
from source
)
select * from renamed

ここでは、最初のステージングモデルで行ったのと同様のリネームと、dbt_utilsパッケージを使用した新しいカラムの追加を行っています。
dbt_utils.surrogate_keyは、マクロにリストされたカラムを使用してorder_item_keyと呼ぶハッシュ化されたサロゲートキーを作成します。このサロゲートキーを実装することで、一意なカラムを得ることができます。サロゲート・キー・マクロの動作の詳細については、こちらを参照してください。
ソース関数
ここで、各ステージング・モデルの最初のバイトで、生のデータ・ソースを参照するために使用しているソース関数(source function)について説明します。

ハードコードされたデータベース参照の代わりにソース関数を使用する理由はいくつかありますが、ここで注目すべき理由の1つは、ソースデータベースオブジェクトとステージングモデルの間に依存関係を作成することです。ここでソース関数を使った定義をしておくことで、後述の情報参照、またハンズオン自体の後半でデータ・リネージを見ていく際に非常に重要になります。ソースを定義し、ソース関数で参照することで、ソースの上に構築するプロジェクトの他のモデルと同様に、ソースをテストし、文書化することができます。
また、ソースがデータベースやスキーマを変更した場合、そのソースが使用される可能性のあるすべてのモデルを更新するのではなく、tpch_sources.ymlファイルを更新するだけで済むようになります。
ステージング層モデルのビルド
上記手順でステージング層のモデルの作成が出来たので、モデルを実行してみます。
コマンド:dbt runで、プロジェクト内のすべてのモデル(2つの新しいステージングモデルと既存のサンプルモデルを含む)を実行します。正常に完了し、実行結果のすべてのモデルの横に緑色のチェックマークが表示されればOKです。
あれ、dbt runコマンド実行でエラーが出ますね...
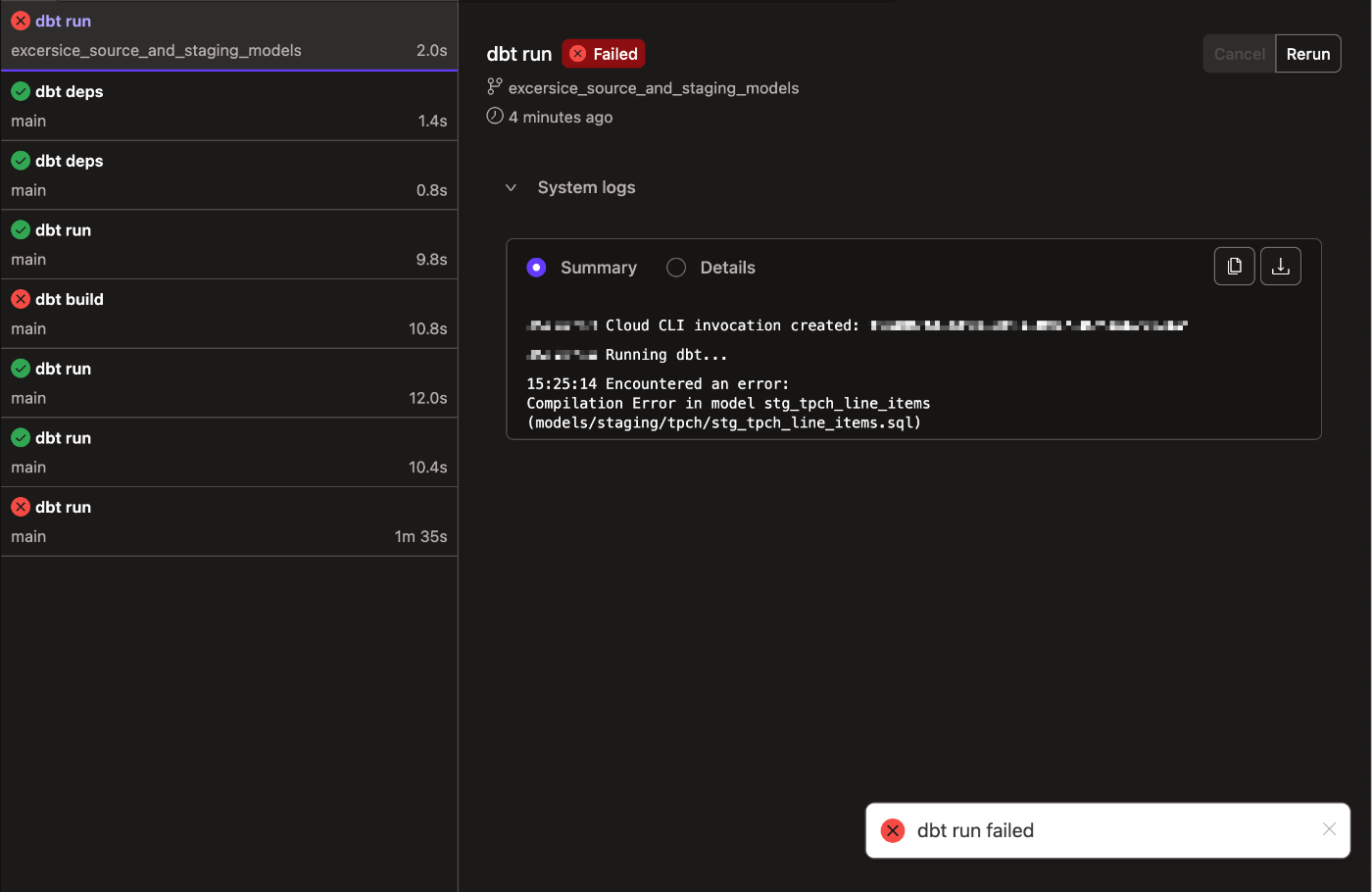
エラーログを確認してみます。追記した設定のサロゲートキーに関する部分が影響しているっぽいですね。
XX:XX:XX Encountered an error:
Compilation Error in model stg_tpch_line_items (models/staging/tpch/stg_tpch_line_items.sql)
Warning: `dbt_utils.surrogate_key` has been replaced by `dbt_utils.generate_surrogate_key`. The new macro treats null values differently to empty strings. To restore the behaviour of the original macro, add a global variable in dbt_project.yml called `surrogate_key_treat_nulls_as_empty_strings` to your dbt_project.yml file with a value of True. The shinyaa31_dbt_snowflake_sandbox.stg_tpch_line_items model triggered this warning.
> in macro default__surrogate_key (macros/sql/surrogate_key.sql)
> called by macro surrogate_key (macros/sql/surrogate_key.sql)
> called by model stg_tpch_line_items (models/staging/tpch/stg_tpch_line_items.sql)
ということで前述追加した設定(surrogate_key)をgenerate_surrogate_keyに書き換え。
(前略)
:
select
{{ dbt_utils.generate_surrogate_key(
['l_orderkey',
'l_linenumber']) }}
as order_item_key,
:
(後略)

再度実行。今度は上手く行きました。

ここで大事なことは、モデルを再実行しても出力は最初の実行後とまったく同じになるということです。これは冪等プロセス(idempotent process)の例であり、プロセスが何回実行されても、プロセスの各実行後の出力は同じであることを意味します。dbtの重要な考え方の一つは、べき等なワークフローを維持することです。
Snowflakeの環境側でデータベース要素の確認をしてみます。新しいモデルに対応する要素が作成されていることが確認出来ました。
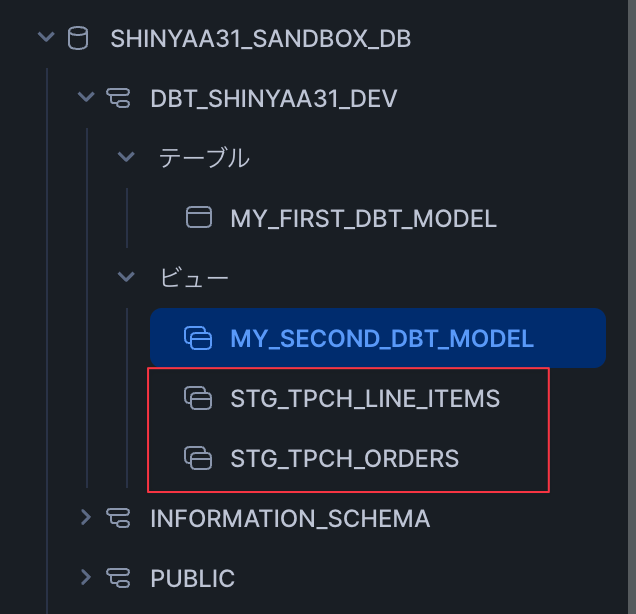
ちなみにこの時点での要素を可視化したリネージは以下のような状態であることが確認出来ます。ソースに関する情報が2つあり、それぞれのソースを参照したモデルが作成されている、という状況ですね。
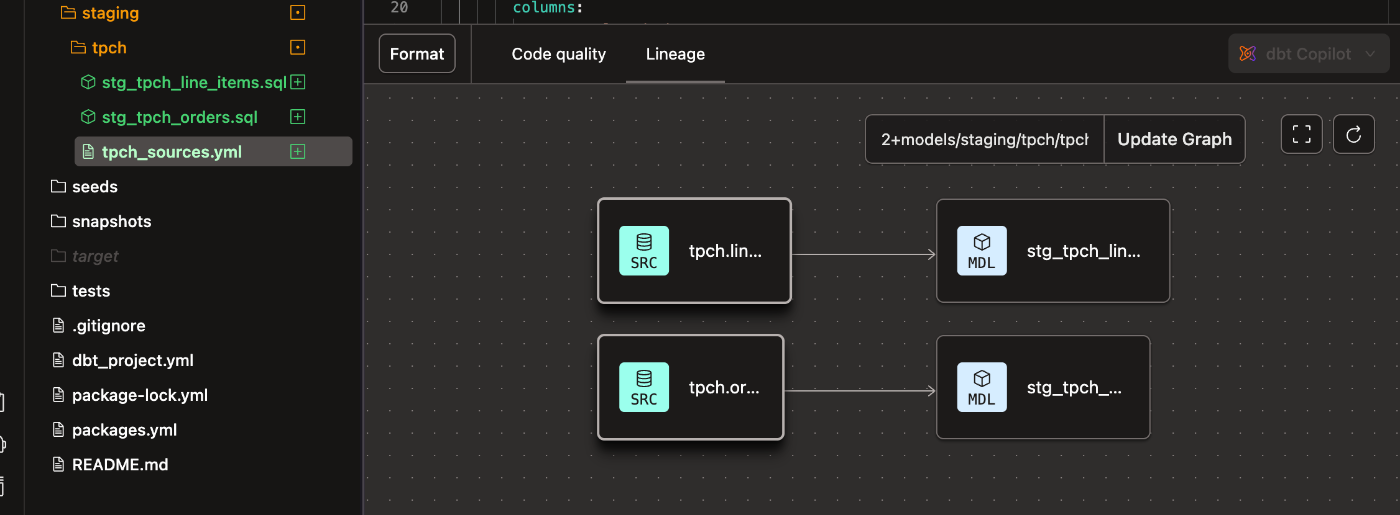
以上、当該ステップの作業完了。作業内容をコミット&プッシュで編集結果をGitリポジトリに反映しておきます。
まとめ
というわけで、Snowflake社提供のSnowflake&dbt Cloud実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)の実践編、#7「ソースデータ設定とステージング層モデルの作成」の紹介でした。
次のエントリ「#8」ではシードの利用と増分マテリアライゼーションについて実践していきます。
参考:
