
dbt CloudとSnowflakeを絡めた実践入門的ドキュメント、いわゆるチュートリアル的な情報はdbt Labs社とSnowflake社の双方から公開されています。
dbt Labs側で提供されている情報(Quickstart)はこちら。
一方Snowflake側で公開している情報は下記となります。
基本的な流れはどちらのチュートリアルも同じなのですが、下記の理由から当エントリ(及び当エントリから続くシリーズ投稿)では後者のSnowflakeが展開しているチュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)の実践を進めて行きたいと思います。
- 各ステップ毎で解説している手数、実施内容(ボリューム)が多い
- 各ステップ毎のドキュメントで紹介されている関連ドキュメント、トピックの数が多い
なお、実施の際には「ドキュメントと現状の違い」も幾つか見られていたため、その辺りの差異も確認・吸収する形で進めております。また直近後述するように環境設定周りの手順はドキュメントと違えています。ご了承ください。
実践手順について
当エントリで参考としているSnowflake QuickStart『Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab』は全13パート(うち実践内容は10パート)で構成されています。
そして当エントリの実践内容について、環境設定完了以降は基本的にドキュメントに沿う形で進めているのですが環境設定周りについては以下の構成・形で進めています。ご了承ください。
| 対象ページ | QuickStart実践内容 | 本稿での実践内容 |
|---|---|---|
| 1. Overview | Quickstart全体の概要紹介 | 同左 → #1紹介パート |
| 2. Architecture and Use Case Overview | アーキテクチャ的全体像、 最終結果のイメージ紹介 |
同左 → #2紹介パート |
| 3. Let's Get Started With Snowflake | Snowflakeアカウントを作成 |
Snowflakeアカウントを作成 ・必要なユーザーやスキーマを別途用意 → #3実践内容 |
| 4. Launching dbt Cloud via Partner Connect | Snowflake Partner Connect経由でdbt Cloudプロジェクトを作成 プロジェクトのコード管理は マネージドリポジトリを活用 |
・各種用意した環境を使ってdbt Cloudプロジェクトを新規作成 ・Snowflakeアカウント ・GitHubアカウント/リポジトリ ・dbt Cloudアカウント → #4実践内容 |
| 5. IDE Walkthrough | dbt Cloud IDEの紹介と簡単な実践 | 同左 → #5実践内容 |
| 6. Foundational Structure | dbtプロジェクトの基本構造紹介 | 同左 → #6実践内容 |
| 7. Sources and Staging | ソースデータの設定と ステージング層モデルの作成 |
同左 → #7実践内容 |
| 8. Seeds and Incremental Materialization | シードと増分マテリアライゼーション | 同左 → #8実践内容 |
| 9. Transformed Models | マートモデルの作成 | 同左 → #9実践内容 |
| 10. Tests and Docs | テストとドキュメント | 同左 → #10実践内容 |
| 11. Deployment | 本番環境へのデプロイ | 同左 → #11実践内容 |
| 12. Visualizing Your Data with Snowsight Dashboards | Snowsightダッシュボード によるデータの可視化 |
同左 → #12実践内容 |
| 13. Conclusion & Next Steps | 総括 | 同左 → #13紹介パート |
ハンズオン実践に必要なもの
上記手順紹介に記載したように、当エントリで実践する際に必要となるアカウントや環境は以下の通りです。
-
Snowflakeアカウント
- 最低限トライアルアカウントであれば十分。
- 既存契約済のものがあればそれを使うのでも勿論問題ありません。
- ACCOUNTADMINが利用できる状態にあること。
-
GitHubアカウント・リポジトリ
- dbt Cloudプロジェクトのソースコード管理に用います。
- アカウント自体はあらかじめ作成、用意しておいてください。
-
dbt Cloudアカウント
- 最低限トライアルアカウントであれば十分。
- 既存契約済のものがあればそれを使うのでも勿論問題ありません。
ハンズオンの概要
ドキュメントの冒頭ではこのQuickStart実践を経て何を学べるか、どういう構造のハンズオンを進めていくかなどについて言及されています。
『何を学べるか』については以下の要点を挙げています。
- dbtとSnowflakeを使用してスケーラブルなデータ変換パイプラインを構築する方法
- dbtの主要なテスト機能を活用してステークホルダーとのデータ信頼性を確立する方法
- dbtワークフローを活用してSnowflakeの計算リソースをスケーリングする方法
- Snowflakeで軽量なチャートと可視化を構築する方法
このハンズオンでは生の小売データを可視化可能な注文モデルに変換する過程を、Snowflakeとdbtを用いて実施していきます。Snowflakeアカウントに標準で付属するTPC-Hデータセットを使用し、dbtの最も強力な機能の一部を活用して変換を行うワークフローを作成してます。完了時には、テストとドキュメントが整備された完全なdbtプロジェクト、専用開発環境と本番環境、およびdbtのGitワークフローの経験を得ることができるようになる...という感じです。

ハンズオン自体はdbt Cloudを利用する形となり、すべての手順が完了した暁には以下のようなデータリネージが出来上がります。

実践#1: Snowflakeアカウント作成・環境を用意
Snowflakeでは30日間、400ドルの使用分が無料で活用できるトライアルアカウントを作ることができます。必要事項を記入し、アカウント作成を進めてください。
アカウント作成後はユーザー名とパスワードでログインします。

なお、テーマや言語の切り替えはユーザーメニューの[設定]→[設定]から変更可能です。

実践#2: Snowflake環境で必要な要素・オブジェクトを準備する
まずはこのハンズオンで使うことになるデータの存在を確認します。Snowflakeアカウントにログイン後、作成→[SQLワークシート]を選択し、SQLワークシートを起動。

データベース一覧の中にSNOWFLAKE_SAMPLE_DATAというデータベースを確認することが出来るかと思います。dbtではここにあるテーブルを使います。

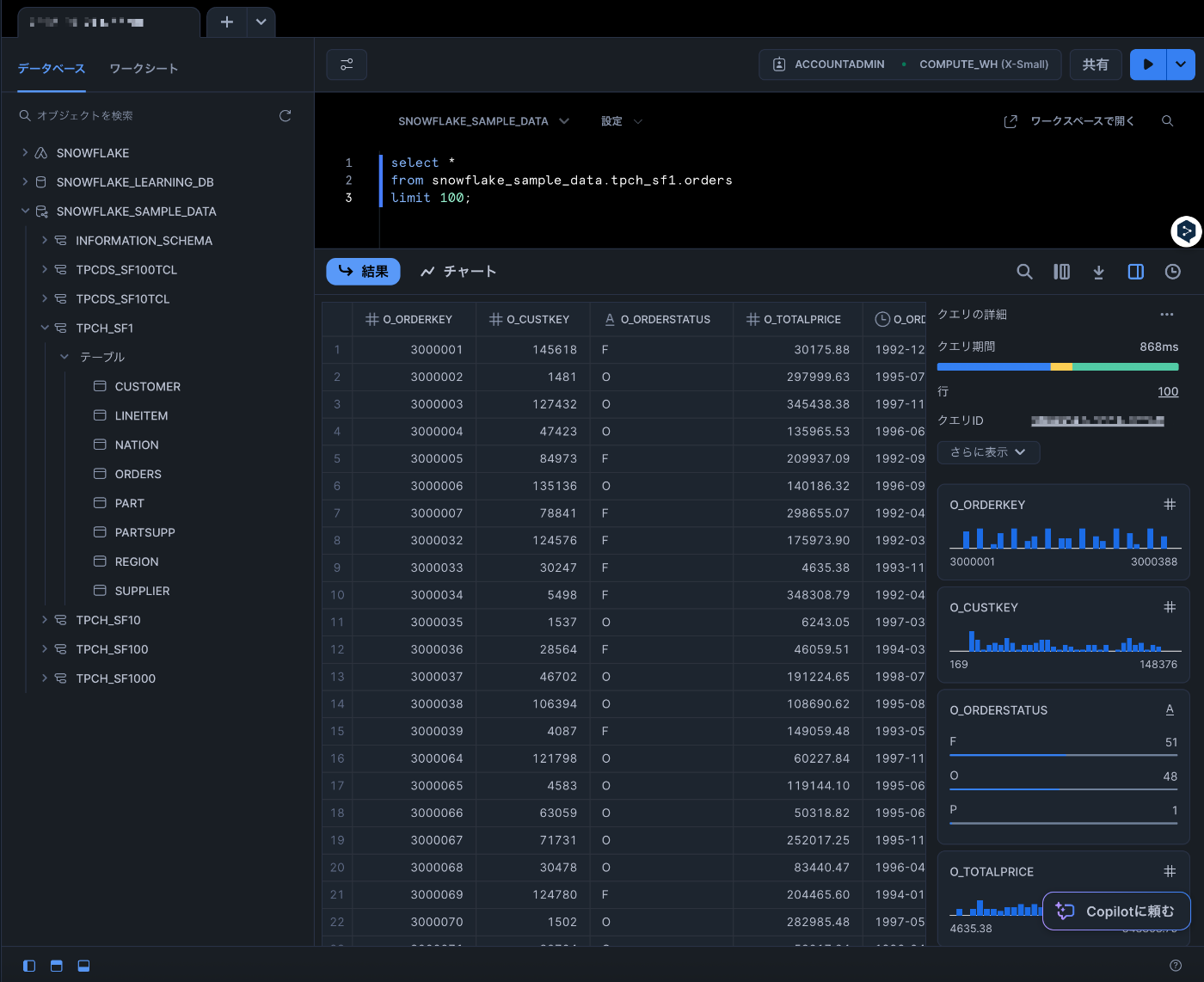
試しに対象テーブルを以下のSQLでクエリしてみます。(対象テーブル、件数的には15万件あるので件数を絞る形で...)
select *
from snowflake_sample_data.tpch_sf1.orders
limit 100;
各種詳細情報と合わせて結果が表示されればOKです。
Snowflake環境に関して必要な要素に関して情報を整理したものが以下表となります。実際案件や本番環境等で利活用する際はある程度組織やプロジェクトのルール、命名規約等も絡んで来ると思いますのでそのあたりの条件やルールなどを踏まえたうえで予め『この環境ではこういう内容、名前でセットアップしよう』というのは検討整理しておいた方が後の作業もスムーズになるかと思います。
| 項目 | 今回作成する要素(名称) |
|---|---|
| Snowflakeデータベース | shinyaa31_sandbox_db |
| Snowflakeウェアハウス | shinyaa31_sandbox_wh_staging shinyaa31_sandbox_wh_mart |
| Snowflakeシステムユーザー | ACCOUNTADMINロールを利用可能な任意のユーザー名 |
| Snowflakeシステムパスワード | ACCOUNTADMINロールを利用可能な任意のパスワード |
| Snowflakeシステムロール | ACCOUNTADMIN |
また、これらSnowflake環境を作成するタイミングで開発環境、本番環境に相当するデータベース環境の検討、確認もしておきます。今回は任意のデータベース『shinyaa31_pc_dbt_db』配下に、環境毎にスキーマを分ける形で用意する形としました。生データ格納用スキーマとしてraw_tpch_sf1も合わせて作成します。
| 環境 | スキーマ名 |
|---|---|
| 生データ格納用スキーマ:このタイミングで作成 | raw_tpch_sf1 |
| 開発用に作成する個人スキーマ:プロジェクト作成時に指定 | dbt_shinyaa31_dev |
| 本番環境用スキーマ:デプロイ時に指定 | production |
上記で定めた要素をSnowflakeコンソール経由で作成。このときに用いるロールはACCOUNTADMINとしています。ハンズオン作業をシンプルにさせるための措置ですが、実際の運用環境ではここは適切なロールを設定の上進める形としてください。
use role ACCOUNTADMIN;
/**------------------*/
/** ウェアハウス作成(1). */
/**------------------*/
/** 標準タイプ、サイズは最小のXS、自動再開ON、自動一時停止=60秒のウェアハウス(ステージング層テーブル用)を作成. */
CREATE OR REPLACE WAREHOUSE shinyaa31_sandbox_wh_staging
WITH
WAREHOUSE_TYPE = STANDARD
WAREHOUSE_SIZE='X-SMALL'
AUTO_RESUME = TRUE
AUTO_SUSPEND = 60
COMMENT = 'using staging layer / for dbt and Snowflake handson';
/**------------------*/
/** ウェアハウス作成(2). */
/**------------------*/
/** 標準タイプ、サイズは最小のXS、自動再開ON、自動一時停止=60秒のウェアハウス(マート層テーブル用)を作成. */
/** ウェアハウスは別途分けて作成しているがスペックはいずれも同じです。実務の場合はサイズその他スペックを変えるイメージ. */
CREATE OR REPLACE WAREHOUSE shinyaa31_sandbox_wh_mart
WITH
WAREHOUSE_TYPE = STANDARD
WAREHOUSE_SIZE='X-SMALL'
AUTO_RESUME = TRUE
AUTO_SUSPEND = 60
COMMENT = 'using mart layer / for dbt and Snowflake handson';
/**---------------*/
/** データベース作成. */
/**---------------*/
/** 今回は対象のデータベースは1つ(shinyaa31_sandbox_db)。
この配下に『生データ』『開発用』『本番環境用』スキーマを同居させる形を取る. */
CREATE DATABASE shinyaa31_sandbox_db;
/**------------*/
/** スキーマ作成. */
/**------------*/
/** 生データ用のスキーマだけ始めに作成しておく。
残りの『開発用』『本番環境用』はdbtプロジェクト作成・実演の過程で作成. */
CREATE SCHEMA raw_tpch_sf1;
データベースやスキーマと合わせて、生データを格納するテーブルをデータ毎作成(複製)しました。別途用意したスキーマに対するテーブルのデータ件数が一致していればOKです。
/**----------------------*/
/** 生データ格納テーブル作成. */
/**----------------------*/
/** ソース用生データの準備. */
SELECT COUNT(*) FROM snowflake_sample_data.tpch_sf1.orders; // 1500000件.
SELECT COUNT(*) FROM snowflake_sample_data.tpch_sf1.lineitem; // 6001215件
/** 任意のスキーマ配下に生データが投入された、という前提で、
ハンズオンで利用していたテーブルを上記で作成したスキーマ配下に実データ入りテーブルとして用意. */
/** ordersテーブル */
CREATE OR REPLACE TABLE shinyaa31_sandbox_db.raw_tpch_sf1.orders
AS
SELECT * FROM snowflake_sample_data.tpch_sf1.orders;
/** lineitemテーブル */
CREATE OR REPLACE TABLE shinyaa31_sandbox_db.raw_tpch_sf1.lineitem
AS
SELECT * FROM snowflake_sample_data.tpch_sf1.lineitem;
/** nationテーブルはseed機能を通じてそれぞれ(開発環境・本番環境)の環境で用意されるのでここでは作らない. */
/** 投入データ確認. */
SELECT COUNT(*) FROM shinyaa31_sandbox_db.raw_tpch_sf1.orders; // 1500000件.
SELECT COUNT(*) FROM shinyaa31_sandbox_db.raw_tpch_sf1.lineitem; // 6001215件

実践#3: GitHubアカウント・リポジトリの準備
GitHubアカウント自体の作成及び設定は上記手順を元に済ませておいてください。アカウント作成及びログイン完了後、TOP画面左上の[New]からリポジトリを作成していきます。

任意のリポジトリ名を入力して作成を行います。なお公開範囲についてはパブリックにする必要も無いのでプライベートとしました。
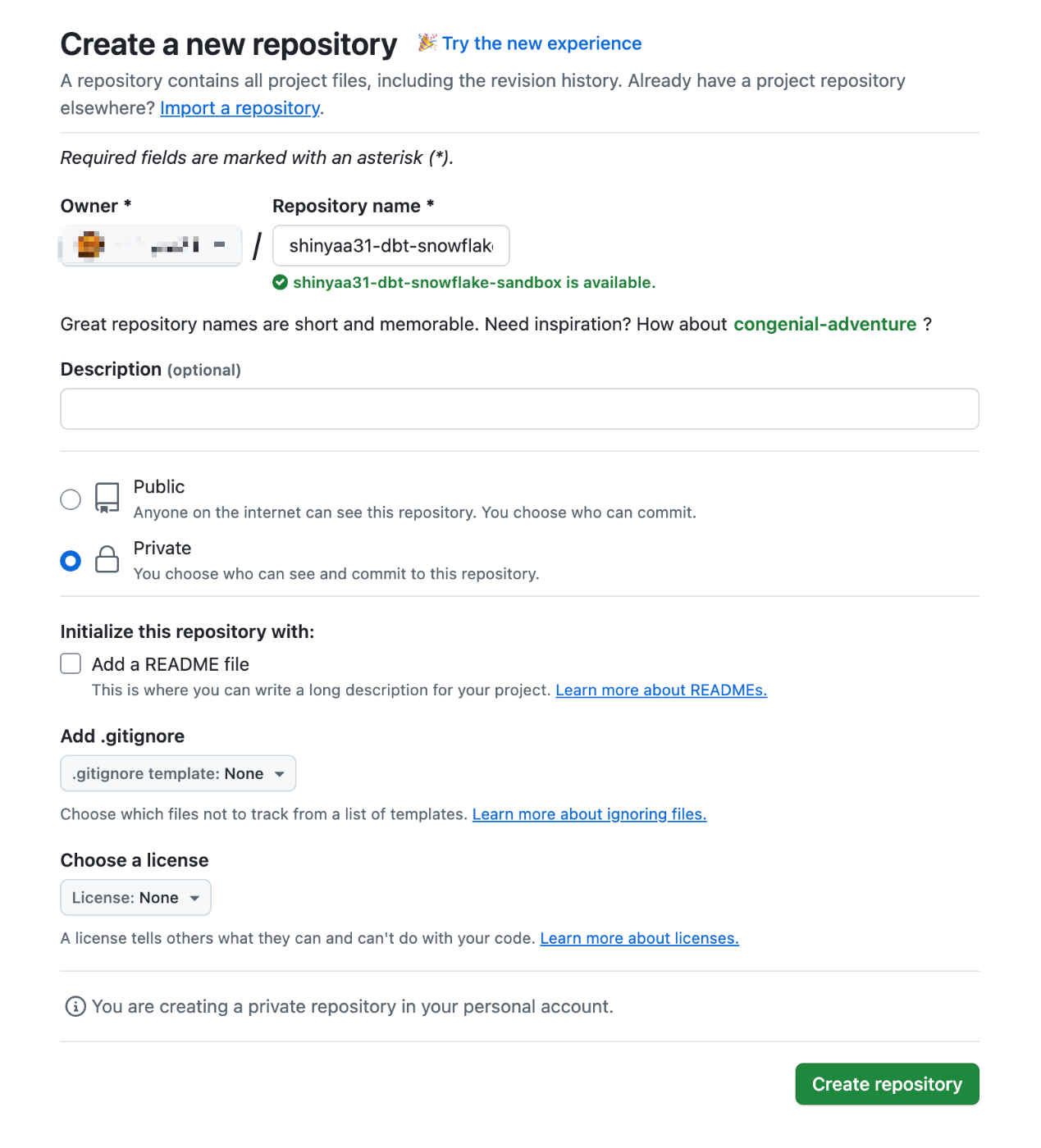
リポジトリ作成完了。この情報は後程dbt Cloudプロジェクト作成の際に連携・利用します。

実践#4: dbt Cloudアカウント及びdbtプロジェクトの作成
dbt Cloudのアカウントについても所持していない場合は新規作成します。Developerプランであれば無料、Starterプランでも任意の日数(14日間)であればトライアルとして利用可能です。
画面右上のユーザーアイコンから[Create a free account]を選択。必要事項を記入の上アカウント作成を進めます。メールアドレス経由での認証、幾つかのアンケートへの回答などを経ることでアカウントが作成されます。

dbt Cloudアカウント作成完了。遷移後の画面ではプロジェクトの作成メニューが表示されています。プロジェクト名にAnalyticsが表示されていますが、ここはこの後の手順で任意のdbtプロジェクト名を入力してプロジェクトを作成していく形となります。
dbt Cloudのテーマについては画面左下のユーザーメニューから切り替え可能です。

アカウント作成済&プロジェクト未作成の状態だと、画面左上の[Dashboard]メニューなどを選択するとプロジェクト作成の画面に遷移します。ここまで準備した情報を以てdbtプロジェクトを作成していきます。
プロジェクト名の指定
まずはプロジェクト名称。任意の値を入力します。ここではshinyaa31-dbt-sandboxとしました。[Continue]押下。

Snowflake接続設定
接続の作成。ここでは上記で準備したSnowflakeに接続するための情報を作成します。[+ Add new connection]を選択。

TypeにSnowflakeを指定、その他各種所定の値を入力します。
- Account:
- 作成したSnowflakeアカウントのアクセスURLから
snowflakecomputing.comを除いた部分を入力。xxxxxxx-yyyyyyy.snowflakecomputing.comの場合、xxxxxxx-yyyyyyyが該当する文字列となります。(ユーザーメニュー→[アカウント]→[接続対象のアカウント]の詳細表示→アカウント/サーバーURLが該当要素)
- 作成したSnowflakeアカウントのアクセスURLから
- Database:
- (前述で作成した)任意のSnowflakeデータベース名。ここでは
shinyaa31_sandbox_dbを入力。
- (前述で作成した)任意のSnowflakeデータベース名。ここでは
- Warehouse:
- (前述で作成した)任意のSnowflakeウェアハウス名。ここでは
shinyaa31_sandbox_wh_stagingを入力。
- (前述で作成した)任意のSnowflakeウェアハウス名。ここでは
- Optional Settings/Role:
- (前述で作成、指定した)任意のロール名
- ※今回は
ACCOUNTADMINを用いていますが本番環境、実運用環境下ではより適切な権限を持たせたロールを準備、活用頂くのを推奨、というのは前述の通りです。
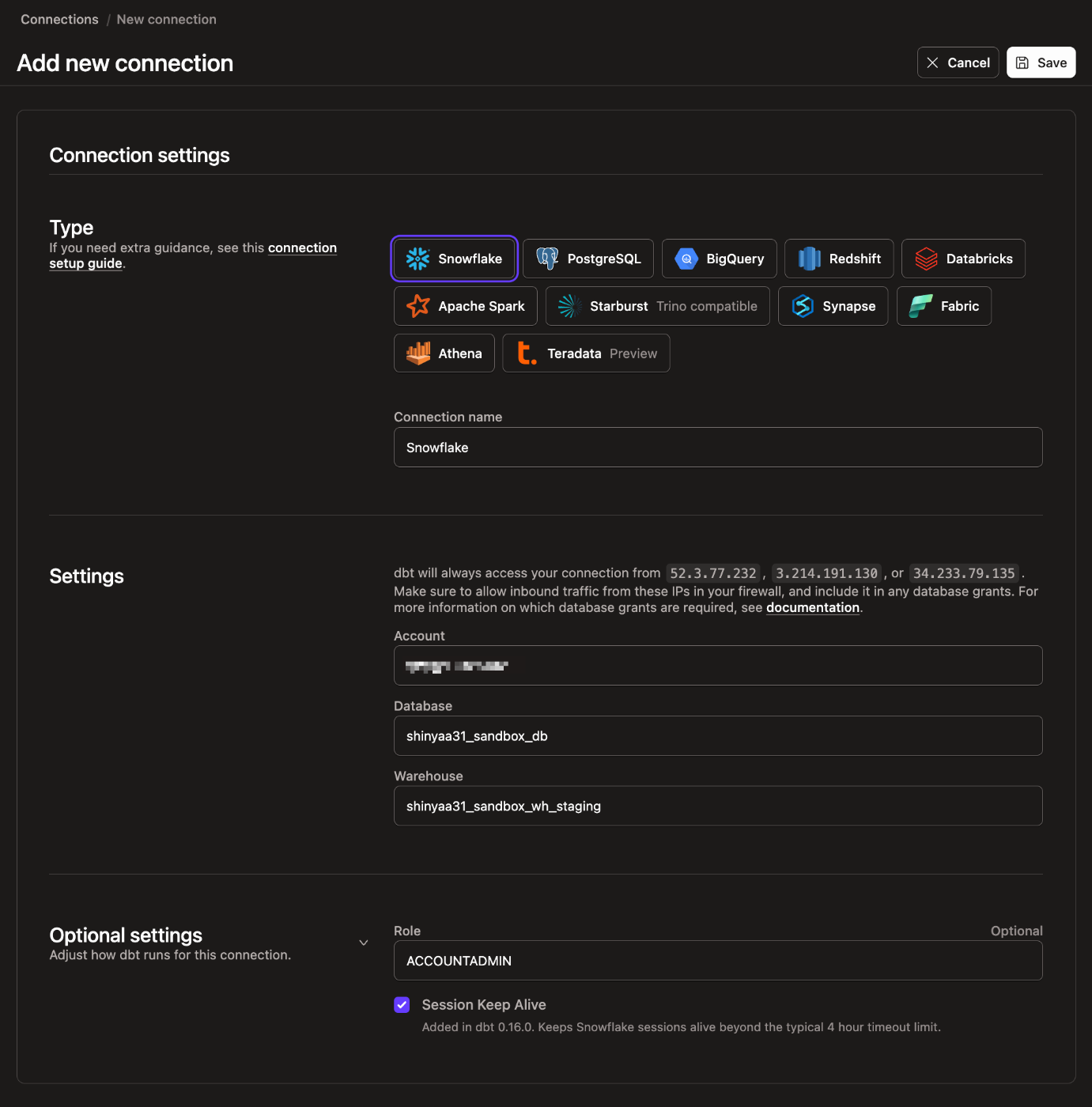
一通り値を入力したら[Test Connection]を押下。

接続が完了したことを確認して次に進みます。

GitHub接続設定
ここではGitHubを選択します。連携しているアカウントがある場合、アカウント及び配下のgitリポジトリの一覧が表示されますが、Gitアカウント側の設定で「許可したものしか使わせない」設定になっていると上述で作成したリポジトリは表示されません。なので許可設定を行います。[Connect GitHub Account]を押下。

dbt(dbt Labs)側からGitHubアカウントへの接続を行うダイアログが表示されます。[Authorize dbt Cloud]を押下。

接続許可を行うアカウントを指定。

接続許可を行うアカウント配下のリポジトリを指定。ここでは必要な分だけ接続を許可します。上記手順で作成したリポジトリを指定し[Install]を押下。

選択対象に対象のリポジトリが表示されました(ちなみにここまでのGitHubリポジトリ連携設定では途中で画面遷移が止まる、止まるというかブラウザのアクティブ状態を失うことがありました。ブラウザでdbt Cloudの画面に戻れば操作を再開することができるので、もし同じ状況の場合は慌てずに進めてみてくだださい)。対象のリポジトリを選択。
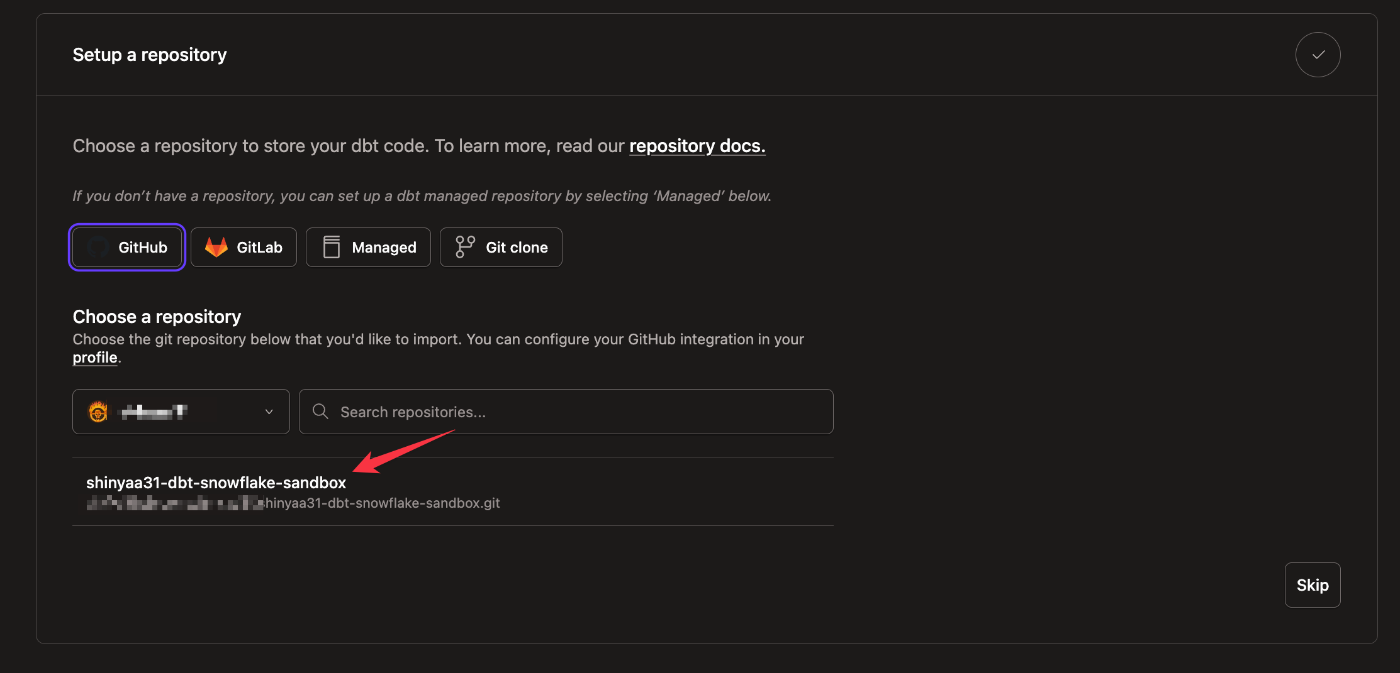
程無くしてdbtプロジェクトが作成されました!一番上のリンク『Start developing in the IDE』をクリックすると次のステップに進みます。

その他リンクの遷移先は以下の通り。
- Get started with CLI:
- dbt CloudのCLI設定画面へ遷移
- Check out the getting started tutorial
- Learn more about how to structure your dbt project
実践#5: dbt Cloud IDEウォークスルー
dbt Cloudを始めて使う人に向けた画面要素の解説、及び最低限の操作に関する案内が紹介されているパート。画面要素の解説などに関しては情報が最新のものでは無くなっているので詳細は下記ドキュメント等を参照するのが良いと思います。
また、当コーナーで幾つかコミットなどの操作について触れていますが、その辺りの操作についても後の手順で適宜言及されていますのでここでの紹介は割愛し、必要最低限の操作に絞って言及します。
前述手順、dbtプロジェクトがされた後に『Start developing in the IDE』をクリックするとしばしの時間を経て、

dbtプロジェクトの簡単なガイド、案内が表示されます。スキップしても良いんですが一応どんな紹介がなされているかを観てみましょう。プロジェクトの初期化とdbt runを実行しましょう、と言っています。



案内に従って[Initialize dbt project]を押下。

プロジェクトの初期化が完了しました。(下記キャプチャはdbt_project.ymlを開いた状態)
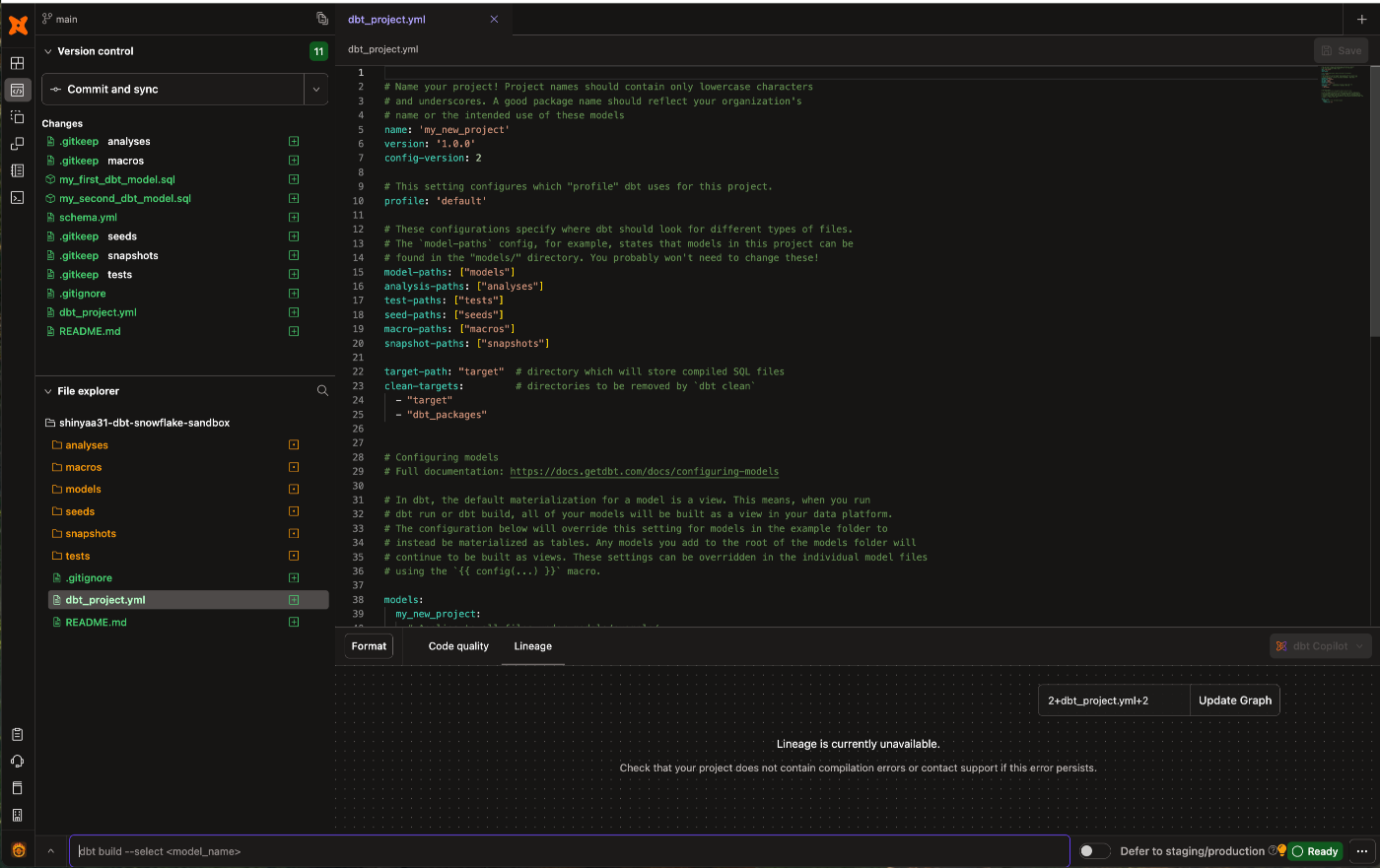
IDE最下部のコマンドライン実行ウインドウにてdbt runと入力し実行。モデル実行処理が行われます。

実行結果は履歴として表示されます。

システムログはサマリ形式、及び詳細な形式でも確認が可能です。

上述のdbt runコマンド実行によって処理されたモデル作成の結果をSnowflakeコンソールで確認してみます。所定のスキーマ配下にテーブルが2つ生成されていることが確認できました。

ここまでの作業内容をGitHubリポジトリに反映させます。画面左上のバージョン管理メニュー配下『Commit and sync』を選択。

任意のコミットメッセージを記載し、初期化ステップで作成した新しいファイルとフォルダをコミットします。この最初のコミットは、mainブランチに直接コミットされる唯一のコミットであり、今後はすべての作業を開発ブランチで行います。これにより、開発作業と本番環境のコードを分離できます。

まとめ
というわけで、Snowflake社提供のSnowflake&dbt Cloud実践チュートリアル「Accelerating Data Teams with Snowflake and dbt Cloud Hands On Lab」(Snowflakeとdbtクラウドでデータチームを加速するハンズオンラボ)の実践編、#1〜#5「実践環境の準備・導入」の紹介でした。
次のエントリ「#6」ではdbtプロジェクトの基本構造を実際に手を動かしながら見ていきます。
参考:
