はじめに
企業のデータ分析基盤としてSnowflakeを活用するケースは増えていますが、その多くは社内に蓄積された構造化データの分析に留まっています。
一方で、実際のビジネス意思決定では、ニュース、SNS、オープンデータなど、社外の非構造データが重要なインサイトをもたらす場面が少なくありません。
そこで今回、Snowflake IntelligenceにWeb検索機能を組み込み、Web上から取得した情報とSnowflake内のデータをあわせて要約・分析・洞察生成を行えるようなエージェントを作成しました。
本記事では、この機能を実現するための設計方針、Web情報の取得と統合の仕組みを解説していきます。
なお、この取り組みは@abe_masanoriさんの以下の記事を参考にさせていただきました。
背景
さて、皆様におかれましては、2025年夏公開の映画『国宝』をご覧になりましたでしょうか?
私は見ました。なんなら原作も読みました。感想としては、横浜流星になりてえな。なのですが
今年は『国宝』とか『鬼滅の刃』などのヒット作品が重なった影響で、映画館のポップコーン売上が例年よりも伸びている──
そんなトピックを目にして、「この現象をSnowflake上で分析できないか?」と思ったのが今回のきっかけです。
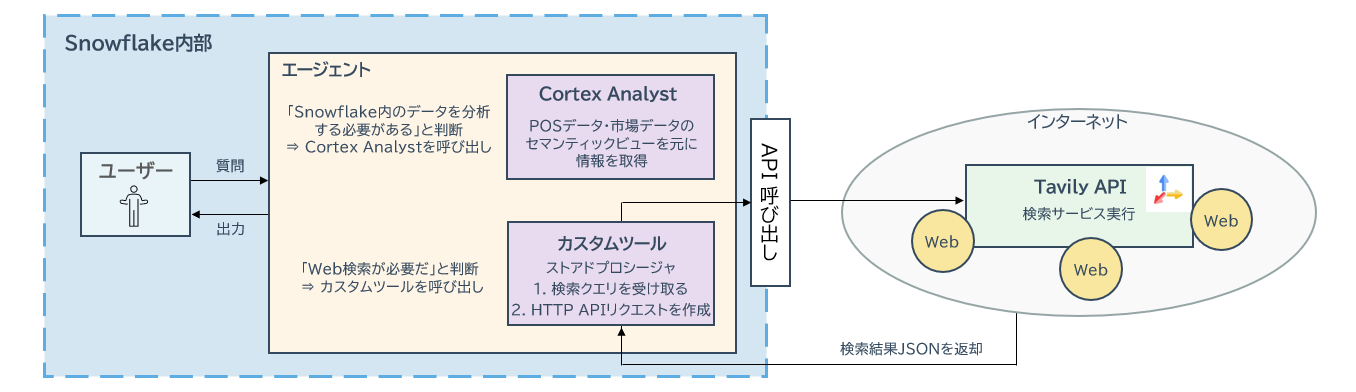
全体構成
全体構成としては以下のようになります。
ユーザーがSnowflake Intelligenceからインプット
↓
エージェントがカスタムツールのストアドプロシージャを使う
↓
ストアドプロシージャからTavilyというWeb検索サービスにAPI経由でアクセス
↓
返ってきた情報をエージェントが要約
↓
(Cortex Analystが出してきた)構造化データと組み合わせて示唆をアウトプット
Tavilyとは
Tavily は、主に 大規模言語モデル(LLM)やAIエージェント 向けに設計された「Web検索APIサービス」です。
AIが話題になってきていると同時に耳にすることも増えてきて、私もAIワークフローツールのDifyで少し使ったことがありますが、非常に簡単に設定できます。
今回はこのTavilyを使ってWeb検索をしていきますが、詳しく知りたい方は公式サイトや公式のAPIドキュメントをチェックしてみてください。
Tavilyでストアドプロシージャを作る
さてここから開発に入っていきます。
事前準備
事前準備として、エージェントやストアドプロシージャを格納するデータベースとスキーマ、およびエージェントを利用するロールを作成します。
また、Tavilyのサイトからサインアップ(ログイン)を行い、
PlatformのトップからAPIキーを取得します。
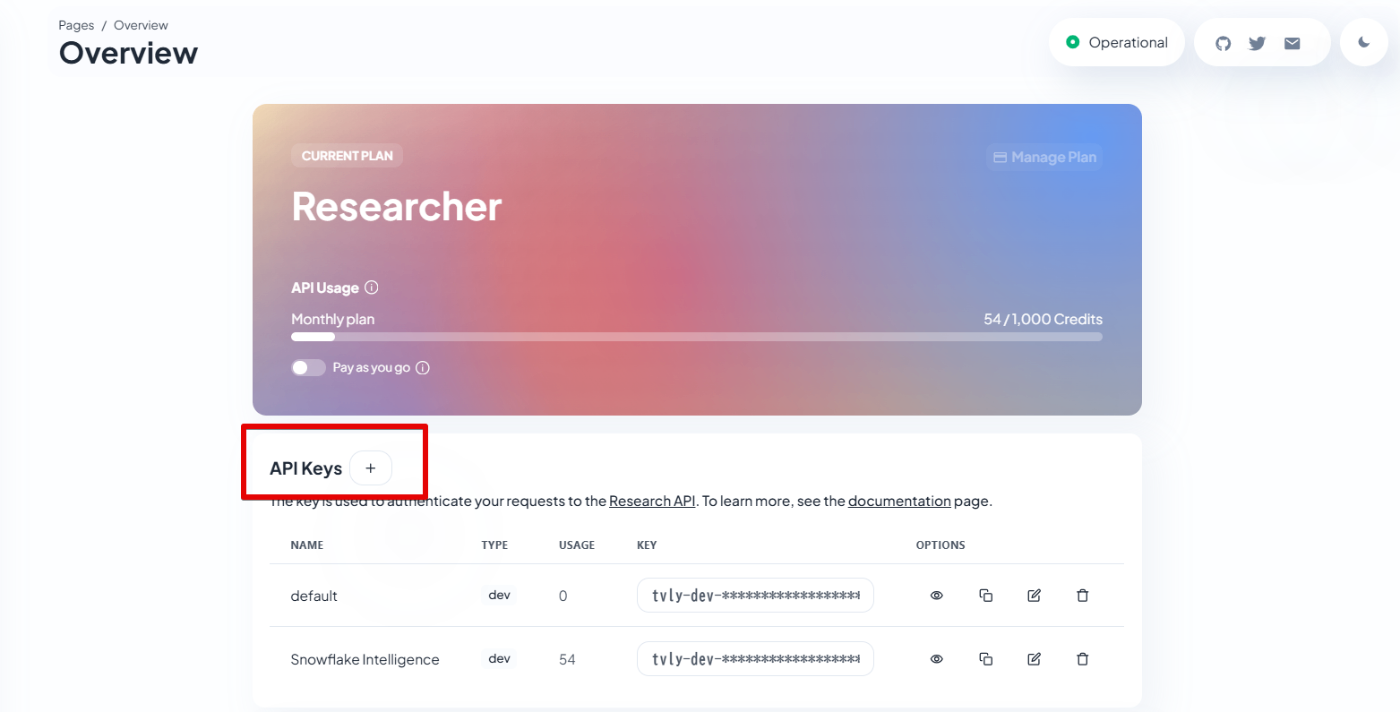
その後、以下のSQLでシークレットや外部アクセス統合を作成します。
-- Tavilyのアクセストークンを保存するシークレットの作成
use role SYSADMIN;
use schema <database>.<schema>;
create or replace secret tavily_secret
type = generic_string
secret_string = 'tvly-dev-xxxxx'
;
-- Tavilyにアクセスするためのネットワークルールの作成
create or replace network rule nr_tavily
type = HOST_PORT
mode = EGRESS
value_list = ('api.tavily.com')
;
-- 外部アクセス統合の作成(AccountAdminで行うか、権限を付与されたロールで行う)
create or replace external access integration eai_tavily
allowed_network_rules = (nr_tavily)
allowed_authentication_secrets = (tavily_secret)
enabled = TRUE
;
-- シークレットや外部アクセス統合の権限付与
grant usage on secret tavily_secret to role <your_agent_role>;
grant read on secret tavily_secret to role <your_agent_role>;
grant usage on integration eai_tavily to role <your_agent_role>;
ストアドプロシージャの作成
エージェントのカスタムツールに設定するためのストアドプロシージャを作成します。
create or replace procedure search_info_from_web(question varchar)
returns varchar
language python
runtime_version = '3.12'
packages = ('snowflake-snowpark-python', 'requests')
handler = 'search_info_from_web'
external_access_integrations = (eai_tavily)
secrets = ('tavily_token' = <database>.<schema>.tavily_secret)
as
$$
import requests
import _snowflake
def search_info_from_web(question):
# Tavilyのトークン取得と設定
tavily_token = _snowflake.get_generic_secret_string('tavily_token')
headers = {
'Authorization': f'Bearer {tavily_token}',
'Content-Type': 'application/json'
}
# 質問に有用な部分を抽出するためadvancedを指定
request_body = {
'query': question,
'search_depth': 'advanced',
'max_results': 10
}
response = requests.post(
url = 'https://api.tavily.com/search',
headers = headers,
json = request_body
)
# エージェントから呼び出す関数は文字列しか返せないため、結果(array)を文字列に変換
return str((response.json())['results'])
$$;
エージェントの作成
今回は、ポップコーンの売上を分析していきたいので、そのままPOPCORNというエージェントを作成します。
ツール
ツールは以下の2つを設定していきます。
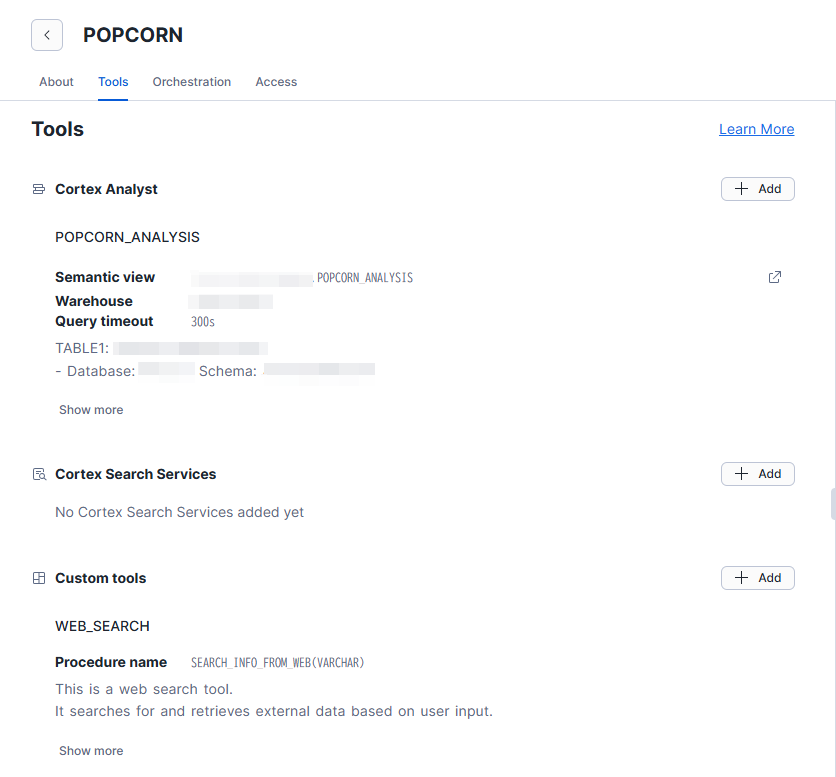
- Cortex Analyst
- POSデータや市場全体のデータを元に作ったセマンティックビューを設定
- 実際の売上を分析します
※こちらはオープンデータではございませんのでぼかしを入れます。悪しからず。
- カスタムツール
- 先ほど作ったストアドプロシージャを設定します
- 設定は以下です
| 項目 | 値 |
|---|---|
| Resource type | procedure |
| Database & Schema | <your_database>.<your_schema> |
| Custom tool identifier | <your_database>.<your_schema>.SEARCH_INFO_FROM_WEB(ストアド名) |
| Name | WEB_SEARCH(任意) |
| Warehouse | User's default |
| Query timeout | 300 |
| Description | This is a web search tool. It searches for and retrieves external data based on user input. The tool is used to provide analysis results and insights derived from the information obtained from the web. |
| Sort by | Latest added |
| Parameter | question |
| Type | string |
| Parameter Description | It searches the web for the information necessary to answer the user's question. |
| Required | Yes |
ツールの設定が完了したら、オーケストレーションも設定していきます。
オーケストレーション
指示の部分は一例ですので、必要に応じて書き換えてください。
- Model:Auto
- Orchestration instruction
– When the following terms are included in the input or when it is necessary to search and analyze external data, please use the WEB_SEARCH tool:
・原因
・要因
・xxxxx
– Use the search results as explanatory factors for the analyses obtained from POS or Market_data in your output.
- Response instructions
##1. Error Handling
If an error occurs, do not immediately switch to a different approach.
Always attempt to fix the error within the current approach at least once before changing methods.
##2. Data Exclusion Rule
Exclude all records where the sales amount is zero from any calculation or aggregation.
- Time Limit:No limit
- Token Limit:No limit
Intelligenceで検索を試してみる
ここまできたら後はIntelligenceを動かすだけです。
Web検索テスト
まずは、ちゃんと検索できるかテストをします。
『国宝』の興行収入を聞いてみます。

ちゃんと調べられていそうです。
一応答え合わせをすると、確かに執筆時点より1日前の記事で同じ内容が公開されています。
ただ、ソースを明示してくれていないので、ソースも明示できるかちょっと聞いてみます。

特別なカスタムインストラクションなしでソースを提示できるみたいです。ほんとかよ。
試しに鬼滅の興行収入を聞いてみます。

予想はしていましたが、やはりソースを出してくれませんでした。
こちらも執筆時点より1日前の記事で同じ内容が公開されていましたので、Webから調べることは成功していそうです。
ツールの設定とかでソース出したいなと思いつつ、今回は次に進みます。
ポップコーン分析
ポップコーンの昨対売上成長率を聞いてみます。
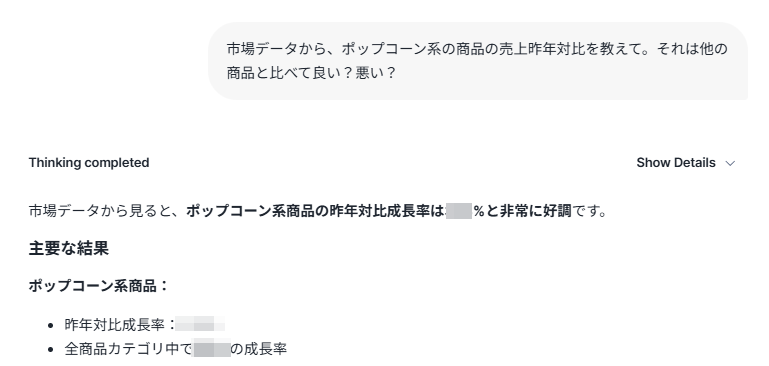
オープンデータではないため数字は隠させていただきますが、ポップコーンの売上はいいみたいです。
今回はここの確からしさではなく、この理由をWebから拾ってこれるかという取組なので、次に進みます。
ポップコーンの昨対売上が好調な理由を聞いてみます。


映画については触れてくれませんでした。。。
が、その他の切り口から定量的な数値も出しつつ要因分析をしてくれています。
Web検索がなければここの定量情報は出力できないはずです。
映画との関連について 誘導尋問 質問します。


ヒット映画との関連も数値と共に分析してくれました。
SNSでの投稿があったことや、家庭での映画鑑賞でポップコーンが定着などありますが、ソースがないので真偽が不明です。
ソースはどこなのか聞いてみます。

なるほど確かにWeb上に存在する情報でした。
(家庭でのポップコーンについてはアメリカの話だったので日本関係なかったですが)
まとめ
というわけで、今回はSnowflake IntelligenceにWeb検索機能を組み込み、
“外の情報も踏まえた分析”を試してみました。
動作としてはしっかりWebから情報を取ってこれていて、Intelligenceの出力にも定量的な裏づけが見える場面もありました。
一方で、ソースの扱いや検索精度など、まだまだチューニングの余地はありそうです。
とはいえ、Snowflakeの中で完結しながら外の世界を参照できる体験はかなり面白く、データ分析の幅が広がる手応えを感じました。
最後まで読んでいただきありがとうございました。
